The Flip Side of RLHF: On-Policy Feedback for Reward Model Self-Supervised Improvement
Pith reviewed 2026-06-28 22:43 UTC · model grok-4.3
The pith
Value-anchored on-policy feedback enables self-supervised improvement of reward models without new human annotations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
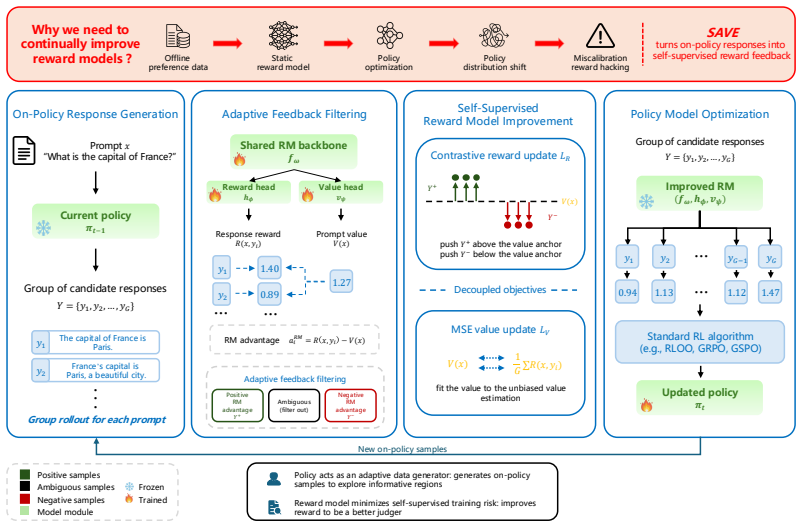
SAVE naturally converts the reward-graded on-policy responses into supervision with a prompt-specific value head as an adaptive anchor. It computes RM advantages and filters ambiguous samples to update the RM via a contrastive objective. The effectiveness of SAVE for enhancing RM training is strongly validated through rigorous empirical evaluation across six diverse benchmarks. It achieves outperforming results across all datasets while maintaining consistent improvements across three RL algorithms (GRPO, RLOO, GSPO) and different policy backbones.
What carries the argument
The SAVE framework that uses a prompt-specific value head to anchor on-policy responses and generate contrastive supervision for reward model updates.
If this is right
- Reward models show gains on all six tested benchmarks.
- Improvements hold when the same reward model is used inside GRPO, RLOO, and GSPO training loops.
- The gains appear across multiple policy backbones.
- The method reduces dependence on fresh human or judge-model preference labels as the policy changes.
Where Pith is reading between the lines
- The loop could support repeated rounds of policy and reward model co-evolution without external data collection.
- If value estimates stay reliable at larger scales, the approach might lower the total annotation budget required for sustained alignment.
- A direct test would be to measure how well the updated reward model ranks responses that the value function itself would have favored.
- The filtering step for ambiguous samples may be the component most sensitive to the quality of the initial value head.
Load-bearing premise
The value function with a prompt-specific value head supplies sufficiently accurate and non-circular grading signals for on-policy responses that can become reliable contrastive supervision.
What would settle it
An experiment in which reward models trained with SAVE produce no measurable gain or a drop in final policy performance on held-out tasks compared with a frozen baseline reward model.
Figures

read the original abstract
Building strong reward models (RMs) for language model alignment is bottlenecked by the cost and difficulty of acquiring diverse and reliable preference data from human annotation or judge models. It is dramatically worse as the policy evolves beyond the static RM training. Therefore, we propose SAVE (Self-supervised reward model improvement via Value-Anchored On-policy feedback), a framework that grades on-policy responses as feedback by using the value function for on-policy RM training. SAVE naturally converts the reward-graded on-policy responses into supervision with a prompt-specific value head as an adaptive anchor. It computes RM advantages and filters ambiguous samples to update the RM via a contrastive objective. The effectiveness of SAVE for enhancing RM training is strongly validated through rigorous empirical evaluation across six diverse benchmarks. It achieves outperforming results across all datasets while maintaining consistent improvements across three RL algorithms (GRPO, RLOO, GSPO) and different policy backbones.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SAVE (Self-supervised reward model improvement via Value-Anchored On-policy feedback), a framework that uses a prompt-specific value head to grade on-policy responses generated under the current policy, converts these into contrastive supervision signals for the reward model via RM advantages and ambiguous-sample filtering, and demonstrates empirical gains across six benchmarks when integrated with GRPO, RLOO, and GSPO algorithms on multiple policy backbones.
Significance. If the value-anchored signals prove non-circular and stable as the policy shifts, the method could meaningfully reduce dependence on static human or judge-model preference data for RM training in evolving RLHF loops, offering a practical route to on-policy RM adaptation.
major comments (2)
- [Abstract] Abstract: the description of the value function as supplying 'reliable' anchors for contrastive RM updates does not specify whether the prompt-specific value head is trained jointly with the RM or held fixed from a prior stage; without this, the grading signal remains downstream of the RM being updated and the non-circularity claim cannot be evaluated.
- [Abstract] Abstract (and implied method section): no independent verification (e.g., correlation with held-out human labels or off-policy value estimates) is reported to confirm that value estimates remain accurate once the policy moves beyond the initial RM distribution; if value estimates degrade or inherit RM errors, the contrastive updates become self-reinforcing rather than self-supervised.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below with clarifications from the method and proposed revisions to improve transparency around the value head procedure and value estimate stability.
read point-by-point responses
-
Referee: [Abstract] Abstract: the description of the value function as supplying 'reliable' anchors for contrastive RM updates does not specify whether the prompt-specific value head is trained jointly with the RM or held fixed from a prior stage; without this, the grading signal remains downstream of the RM being updated and the non-circularity claim cannot be evaluated.
Authors: The prompt-specific value head is initialized from the base RM and updated jointly during SAVE training, but is held fixed as an adaptive per-prompt anchor when computing RM advantages and filtering samples within each iteration. This is described in the method section. We will revise the abstract to explicitly state the joint training with per-iteration anchoring to allow evaluation of non-circularity. revision: yes
-
Referee: [Abstract] Abstract (and implied method section): no independent verification (e.g., correlation with held-out human labels or off-policy value estimates) is reported to confirm that value estimates remain accurate once the policy moves beyond the initial RM distribution; if value estimates degrade or inherit RM errors, the contrastive updates become self-reinforcing rather than self-supervised.
Authors: We acknowledge that explicit verification of value estimate stability (e.g., correlations with held-out labels or off-policy estimates) is not reported. While the consistent empirical gains across six benchmarks and three RL algorithms provide indirect support for the approach, we agree this does not fully address potential self-reinforcement. We will add an analysis section with such verifications in the revision. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper describes SAVE as using a value function with prompt-specific head to grade on-policy responses and generate contrastive supervision for the RM. No equations are exhibited in the abstract or provided text that reduce the grading signal or RM update to the RM outputs by construction (e.g., no explicit statement that value estimates equal RM-derived quantities or that the contrastive loss is a direct function of the fitted RM parameters). The method is presented as converting reward-graded responses into supervision, with empirical validation across six benchmarks, three RL algorithms, and multiple backbones supplying independent content. No self-citation load-bearing steps, uniqueness theorems, or ansatz smuggling are quoted. This is the expected non-finding for an empirically driven proposal whose central mechanism is not shown to be definitionally equivalent to its inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Value function provides reliable grading for on-policy responses usable as RM supervision
Reference graph
Works this paper leans on
-
[1]
Process Reinforcement through Implicit Rewards
Process reinforcement through implicit re- wards.CoRR, abs/2502.01456. Yann Dubois, Balázs Galambosi, Percy Liang, and Tat- sunori B Hashimoto. 2024. Length-controlled al- pacaeval: A simple way to debias automatic evalua- tors.arXiv preprint arXiv:2404.04475. Evan Frick, Tianle Li, Connor Chen, Wei-Lin Chi- ang, Anastasios Nikolas Angelopoulos, Jiantao J...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
In The Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28,
How to evaluate reward models for RLHF. In The Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28,
2025
-
[3]
REINFORCE++: Stabilizing Critic-Free Policy Optimization with Global Advantage Normalization
OpenReview.net. Leo Gao, John Schulman, and Jacob Hilton. 2023. Scal- ing laws for reward model overoptimization. InIn- ternational Conference on Machine Learning, pages 10835–10866. PMLR. Charles A. E. Goodhart. 1984. Problems of monetary management: The UK experience.Monetary Theory and Practice, pages 91–121. Jian Hu. 2025. REINFORCE++: A simple and ef...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Training language models to follow instruc- tions with human feedback. InAdvances in Neural Information Processing Systems 35: Annual Confer- ence on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022. John Schulman, Philipp Moritz, Sergey Levine, Michael I. Jordan, and Pieter Abbeel. 2016. High-...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[5]
Group Sequence Policy Optimization
Self-rewarding language models. InForty- first International Conference on Machine Learning, ICML 2024. Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, Jingren Zhou, and Jun- yang Lin. 2025. Group sequence policy optimization. arXiv preprint arXiv:2507.18071. 11 A Proof of Lemma 1 Formal ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.