Bandwidth Allocation with Device Partitioning for Federated Learning over Industrial IoT networks
Pith reviewed 2026-06-28 23:14 UTC · model grok-4.3
The pith
A device partitioning policy for bandwidth allocation in federated learning over IIoT networks strictly reduces training time compared to any non-partitioning scheme.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
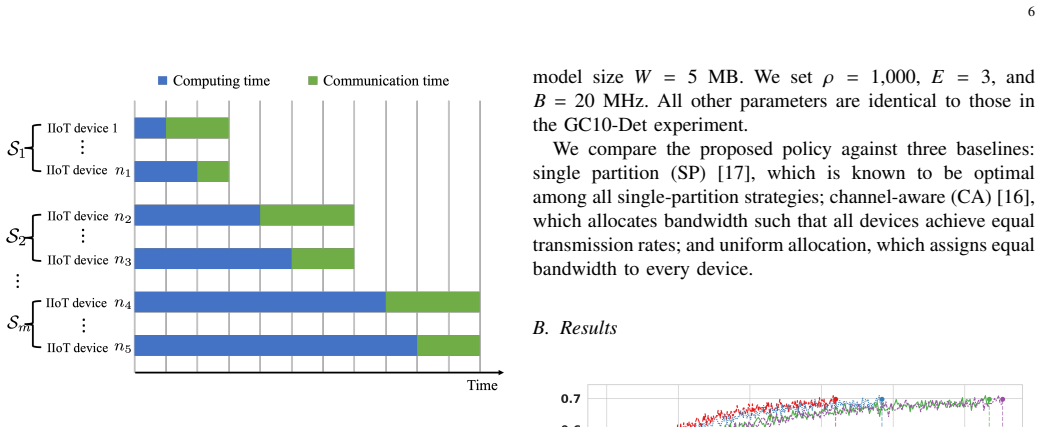
By partitioning the participating devices into ordered subsets and sequentially granting each subset exclusive access to the full bandwidth, the policy achieves a strictly lower training time than any scheme without partitioning, irrespective of the scheduling algorithm, and also minimizes uplink energy consumption.
What carries the argument
The partitioning-based bandwidth allocation policy that orders device subsets for sequential exclusive full-bandwidth access.
If this is right
- The policy reduces total training time strictly compared to simultaneous allocation.
- Uplink energy consumption decreases due to shorter per-device transmission times.
- Training time approaches the theoretical lower bound on round time.
- The time reduction holds across different underlying scheduling algorithms.
Where Pith is reading between the lines
- The same partitioning logic could apply to other wireless federated learning settings that exhibit device heterogeneity.
- Shorter rounds might allow more total training iterations within a fixed wall-clock budget and thereby affect final model accuracy.
- Hardware deployments could test whether subset switching introduces unmodeled interference that offsets the predicted gains.
Load-bearing premise
Device computing capabilities are sufficiently heterogeneous and sequential exclusive full-bandwidth access incurs no additional overhead or interference beyond the modeled transmission times.
What would settle it
An experiment or simulation with all devices having identical computing capabilities in which the partitioning policy shows no reduction in training time compared to simultaneous allocation.
Figures
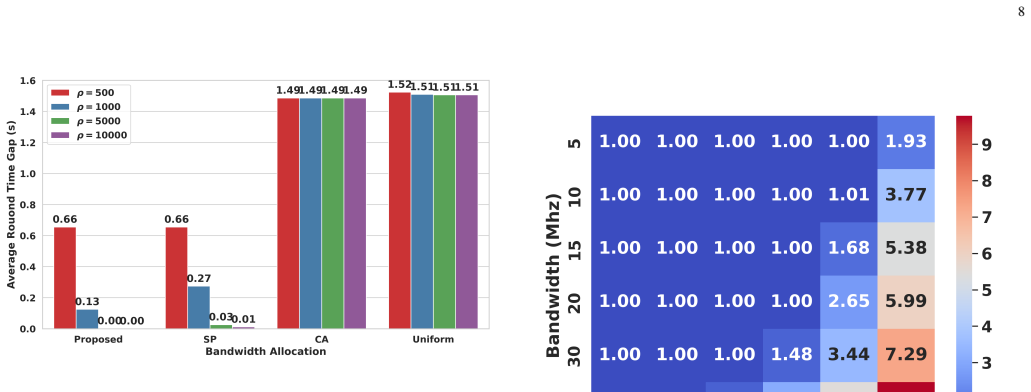

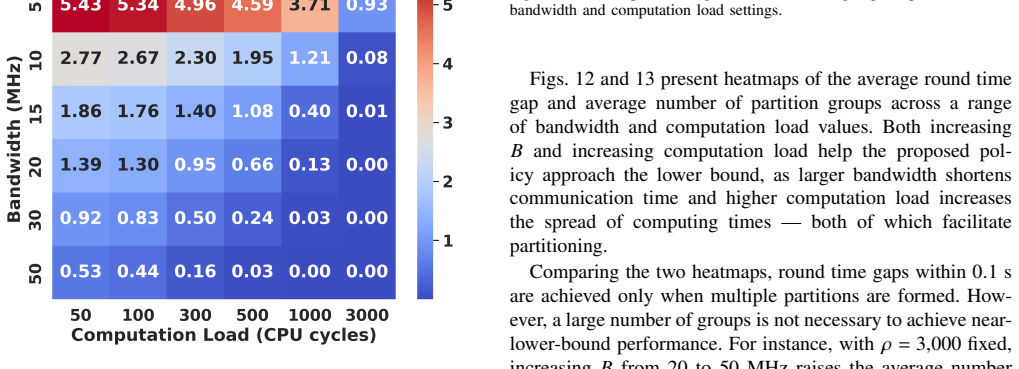
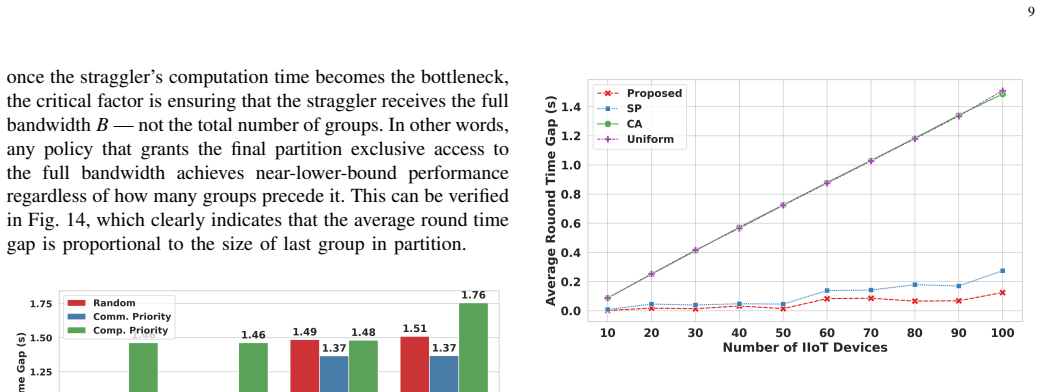

read the original abstract
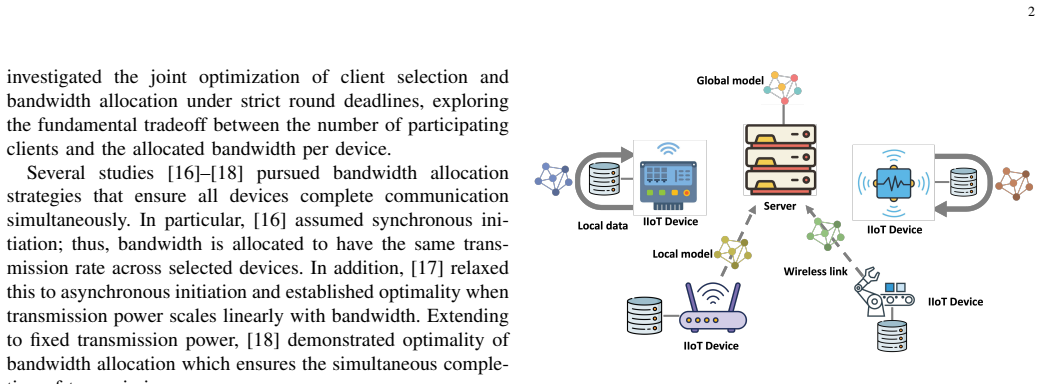
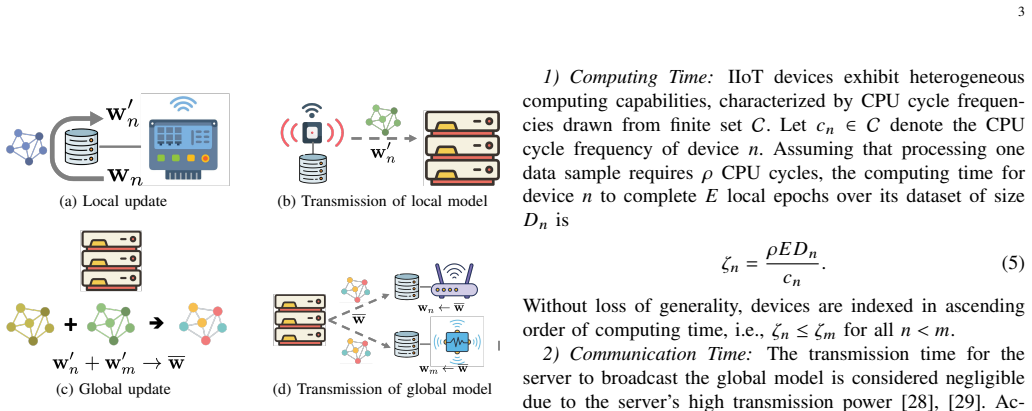
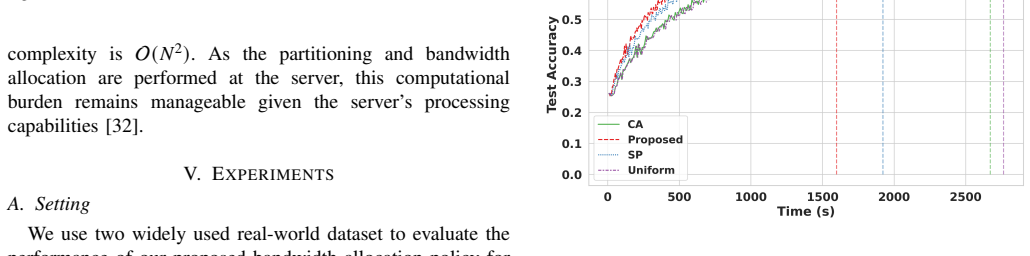
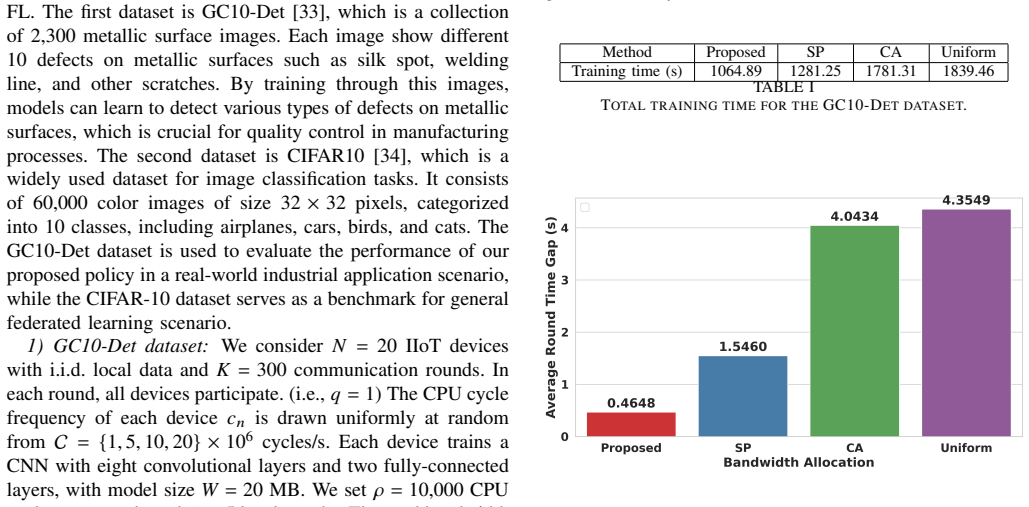
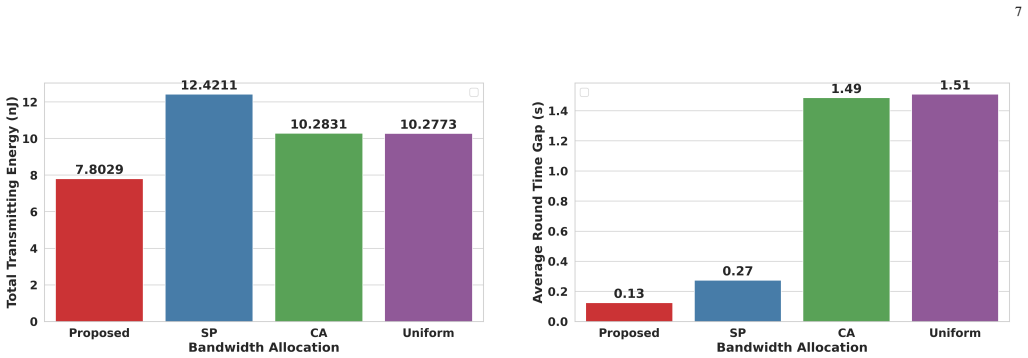
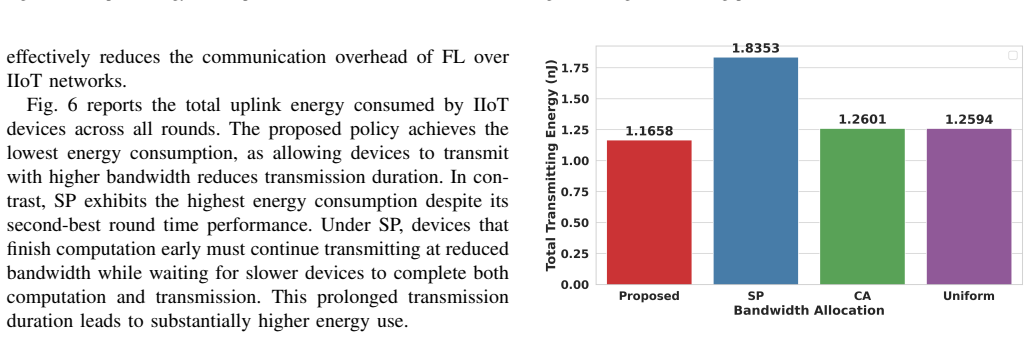
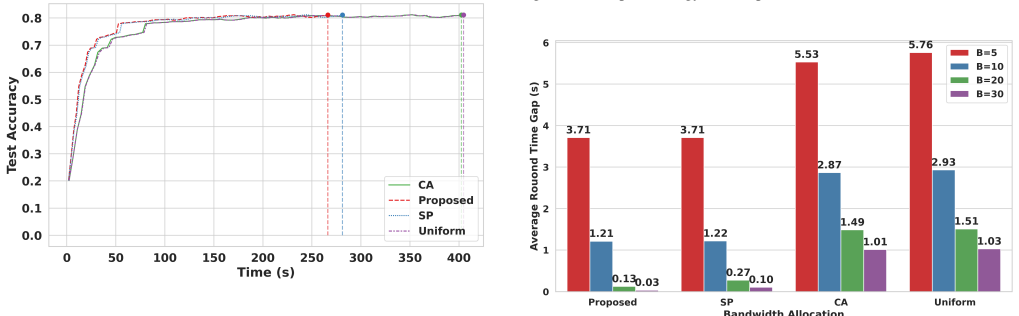
We consider a federated learning (FL) system in which Industrial Internet-of-Things (IIoT) devices collaboratively train a global model over wireless channels without sharing local data. In such systems, communication time is a primary bottleneck that constrains overall training efficiency. Unlike conventional networks that prioritize individual quality-of-service requirements, FL systems collectively aim to converge to an optimal global model as efficiently as possible, which calls for a fundamentally different approach to bandwidth allocation. In this paper, we propose a novel bandwidth allocation policy that exploits the heterogeneity of device computing capabilities to minimize total training time. Rather than distributing bandwidth among all selected devices simultaneously, the proposed policy partitions the participating devices into ordered subsets and sequentially grants each subset exclusive access to the full bandwidth. We formally prove that this partitioning-based policy achieves a strictly lower training time than any bandwidth allocation scheme without partitioning, irrespective of the underlying scheduling algorithm. Furthermore, by reducing per-device transmission duration, the proposed policy also minimizes uplink energy consumption, which is particularly beneficial for battery-constrained IIoT devices. Extensive experiments on real-world datasets - including GC10-Det, an industrial surface defect benchmark, and CIFAR-10, a standard image classification benchmark - demonstrate that the proposed policy consistently reduces training time and energy consumption compared to existing bandwidth allocation schemes, approaching the theoretical lower bound on round time.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a bandwidth allocation policy for federated learning in IIoT networks that partitions devices into ordered subsets and grants each subset sequential exclusive full-bandwidth access. It formally proves that this policy yields strictly lower training time than any non-partitioning bandwidth allocation, irrespective of the scheduler, while also reducing uplink energy; experiments on GC10-Det and CIFAR-10 are reported to show consistent gains approaching a theoretical lower bound on round time.
Significance. If the central proof holds under its modeling assumptions, the result supplies a simple, scheduler-agnostic policy that exploits compute heterogeneity to reduce FL round times and energy use in resource-constrained IIoT settings, with direct relevance to practical deployment.
major comments (2)
- [Abstract / formal proof] Abstract (and the formal proof referenced therein): the claim of a 'strictly lower training time ... irrespective of the underlying scheduling algorithm' is unqualified. In the homogeneous case of equal compute speeds and equal data sizes the round time under partitioning equals the simultaneous case (t1 + t2 = 2t when each device receives half the bandwidth), so the strict inequality fails without an explicit heterogeneity assumption.
- [System model / policy definition] Model description (implied in the partitioning policy and comparison): sequential exclusive full-bandwidth grants are modeled as incurring only the transmission durations already accounted for, with no switching, guard-interval, or interference overhead. Any positive overhead term would erase the claimed advantage over simultaneous allocation.
minor comments (1)
- [Abstract] The abstract states that the policy 'approaches the theoretical lower bound on round time' but neither defines that bound nor indicates where its derivation appears.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract claim and modeling assumptions. We address each point below and will revise the manuscript accordingly to strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract / formal proof] Abstract (and the formal proof referenced therein): the claim of a 'strictly lower training time ... irrespective of the underlying scheduling algorithm' is unqualified. In the homogeneous case of equal compute speeds and equal data sizes the round time under partitioning equals the simultaneous case (t1 + t2 = 2t when each device receives half the bandwidth), so the strict inequality fails without an explicit heterogeneity assumption.
Authors: We agree that the strict inequality requires device heterogeneity in compute speeds (as stated in the system model and introduction). The proof in Section III-B derives the strict reduction only when compute times differ; equality holds in the homogeneous case. We will revise the abstract and the theorem statement to explicitly qualify the result as holding under heterogeneous compute capabilities, while retaining the scheduler-agnostic aspect. revision: yes
-
Referee: [System model / policy definition] Model description (implied in the partitioning policy and comparison): sequential exclusive full-bandwidth grants are modeled as incurring only the transmission durations already accounted for, with no switching, guard-interval, or interference overhead. Any positive overhead term would erase the claimed advantage over simultaneous allocation.
Authors: The analysis is conducted under an idealized model with zero overhead for mode switching or guard intervals, which is standard for isolating the bandwidth allocation effect. Under this model the advantage holds. We acknowledge that positive overheads would narrow or eliminate the gain in practice and will add a paragraph in the discussion section noting this modeling assumption and its implications for real deployments. revision: partial
Circularity Check
No significant circularity; formal proof is independent
full rationale
The paper's strongest claim is a formal mathematical proof that the device-partitioning bandwidth policy yields strictly lower round time than any non-partitioning allocation, irrespective of scheduling. No equations, definitions, or citations in the abstract or described structure reduce this result to a fitted parameter, self-definition, or self-citation chain. The proof is presented as a standalone derivation resting on the model of transmission times and device heterogeneity; it does not rename known results or smuggle ansatzes via prior self-work. The derivation is therefore self-contained and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Participating devices exhibit heterogeneous computing capabilities that can be exploited for time minimization.
- domain assumption Sequential exclusive full-bandwidth access is feasible without unmodeled overheads or interference.
Reference graph
Works this paper leans on
-
[1]
Artificial intelligence-driven mechanism for edge computing-based industrial ap- plications,
A. H. Sodhro, S. Pirbhulal, and V . H. C. de Albuquerque, “Artificial intelligence-driven mechanism for edge computing-based industrial ap- plications,”IEEE Transactions on Industrial Informatics, vol. 15, no. 7, pp. 4235–4243, 2019
2019
-
[2]
Federated learning for industrial internet of things in future industries,
D. C. Nguyen, M. Ding, P. N. Pathirana, A. Seneviratne, J. Li, D. Niyato, and H. V . Poor, “Federated learning for industrial internet of things in future industries,”IEEE Wireless Communications, vol. 28, no. 6, pp. 192–199, 2021
2021
-
[3]
Communication-efficient federated learning for digital twin edge net- works in industrial iot,
Y . Lu, X. Huang, K. Zhang, S. Maharjan, and Y . Zhang, “Communication-efficient federated learning for digital twin edge net- works in industrial iot,”IEEE Transactions on Industrial Informatics, vol. 17, no. 8, pp. 5709–5718, 2021
2021
-
[4]
Model compression for communication efficient federated learning,
S. M. Shah and V . K. Lau, “Model compression for communication efficient federated learning,”IEEE Transactions on Neural Networks and Learning Systems, vol. 34, no. 9, 2021
2021
-
[5]
CMFL: Mitigating communication overhead for federated learning,
W. Luping, W. Wei, and L. Bo, “CMFL: Mitigating communication overhead for federated learning,” inIEEE 39th international conference on distributed computing systems (ICDCS), 2019, pp. 954–964
2019
-
[6]
Accelerating federated learn- ing via momentum gradient descent,
W. Liu, L. Chen, Y . Chen, and W. Zhang, “Accelerating federated learn- ing via momentum gradient descent,”IEEE Transactions on Parallel and Distributed Systems, vol. 31, no. 8, 2020
2020
-
[7]
Fast-convergent federated learning with adaptive weighting,
H. Wu and P. Wang, “Fast-convergent federated learning with adaptive weighting,”IEEE Transactions on Cognitive Communications and Net- working, vol. 7, no. 4, 2021
2021
-
[8]
Computationally efficient bandwidth allocation and power control for ofdma,
D. Kivanc, G. Li, and H. Liu, “Computationally efficient bandwidth allocation and power control for ofdma,”IEEE transactions on wireless communications, vol. 2, no. 6, pp. 1150–1158, 2003
2003
-
[9]
Bandwidth partitioning in decentralized wireless networks,
N. Jindal, J. G. Andrews, and S. Weber, “Bandwidth partitioning in decentralized wireless networks,”IEEE Transactions on Wireless Communications, vol. 7, no. 12, pp. 5408–5419, 2008
2008
-
[10]
Resource allocation in wireless powered iot networks,
X. Liu, Z. Qin, Y . Gao, and J. A. McCann, “Resource allocation in wireless powered iot networks,”IEEE Internet of Things Journal, vol. 6, no. 3, pp. 4935–4945, 2019
2019
-
[11]
Resource allocation for latency-aware federated learning in industrial internet of things,
W. Gao, Z. Zhao, G. Min, Q. Ni, and Y . Jiang, “Resource allocation for latency-aware federated learning in industrial internet of things,”IEEE Transactions on Industrial Informatics, vol. 17, no. 12, pp. 8505–8513, 2021
2021
-
[12]
Client selection and bandwidth allocation in wireless federated learning networks: A long-term perspective,
J. Xu and H. Wang, “Client selection and bandwidth allocation in wireless federated learning networks: A long-term perspective,”IEEE Transactions on Wireless Communications, vol. 20, no. 2, pp. 1188– 1200, 2020
2020
-
[13]
Joint client selection and bandwidth allocation algorithm for federated learning,
H. Ko, J. Lee, S. Seo, S. Pack, and V . C. Leung, “Joint client selection and bandwidth allocation algorithm for federated learning,” IEEE Transactions on Mobile Computing, vol. 22, no. 6, 2021
2021
-
[14]
Client selection with band- width allocation in federated learning,
J. Kuang, M. Yang, H. Zhu, and H. Qian, “Client selection with band- width allocation in federated learning,” inIEEE Global Communications Conference (GLOBECOM), 2021, pp. 01–06
2021
-
[15]
System optimization of federated learning networks with a constrained latency,
Z. Zhao, J. Xia, L. Fan, X. Lei, G. K. Karagiannidis, and A. Nallanathan, “System optimization of federated learning networks with a constrained latency,”IEEE Transactions on Vehicular Technology, vol. 71, no. 1, 2021
2021
-
[16]
Scheduling for cellular federated edge learning with importance and channel aware- ness,
J. Ren, Y . He, D. Wen, G. Yu, K. Huang, and D. Guo, “Scheduling for cellular federated edge learning with importance and channel aware- ness,”IEEE Transactions on Wireless Communications, vol. 19, no. 11, 2020
2020
-
[17]
Device scheduling with fast convergence for wireless federated learning,
W. Shi, S. Zhou, and Z. Niu, “Device scheduling with fast convergence for wireless federated learning,” inIEEE International Conference on Communications (ICC), 2020, pp. 1–6
2020
-
[18]
Joint device scheduling and resource allocation for latency constrained wireless federated learn- ing,
W. Shi, S. Zhou, Z. Niu, M. Jiang, and L. Geng, “Joint device scheduling and resource allocation for latency constrained wireless federated learn- ing,”IEEE Transactions on Wireless Communications, vol. 20, no. 1, 2020
2020
-
[19]
Drl-based joint resource allocation and device orchestration for hierarchical federated learning in noma-enabled industrial iot,
T. Zhao, F. Li, and L. He, “Drl-based joint resource allocation and device orchestration for hierarchical federated learning in noma-enabled industrial iot,”IEEE Transactions on Industrial Informatics, vol. 19, no. 6, pp. 7468–7479, 2023
2023
-
[20]
Federated Learning with Non-IID Data
Y . Zhao, M. Li, L. Lai, N. Suda, D. Civin, and V . Chandra, “Federated learning with non-iid data,”arXiv preprint arXiv:1806.00582, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[21]
Federated optimization in heterogeneous networks,
T. Li, A. K. Sahu, M. Zaheer, M. Sanjabi, A. Talwalkar, and V . Smith, “Federated optimization in heterogeneous networks,”Proceedings of Machine learning and systems, vol. 2, pp. 429–450, 2020
2020
-
[22]
Robust and communication-efficient federated learning from non-iid data,
F. Sattler, S. Wiedemann, K.-R. M ¨uller, and W. Samek, “Robust and communication-efficient federated learning from non-iid data,”IEEE Transactions on Neural Networks and Learning Systems, vol. 31, no. 9, 2019
2019
-
[23]
Ternary compression for communication-efficient federated learning,
J. Xu, W. Du, Y . Jin, W. He, and R. Cheng, “Ternary compression for communication-efficient federated learning,”IEEE Transactions on Neural Networks and Learning Systems, vol. 33, no. 3, 2020
2020
-
[24]
Expanding the Reach of Federated Learning by Reducing Client Resource Requirements
S. Caldas, J. Kone ˇcny, H. B. McMahan, and A. Talwalkar, “Expanding the reach of federated learning by reducing client resource require- ments,”arXiv preprint arXiv:1812.07210, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[25]
Federated dropout—a simple ap- proach for enabling federated learning on resource constrained devices,
D. Wen, K.-J. Jeon, and K. Huang, “Federated dropout—a simple ap- proach for enabling federated learning on resource constrained devices,” IEEE wireless communications letters, vol. 11, no. 5, pp. 923–927, 2022
2022
-
[26]
On the convergence of fedavg on non-iid data,
X. Li, K. Huang, W. Yang, S. Wang, and Z. Zhang, “On the convergence of fedavg on non-iid data,”arXiv preprint arXiv:1907.02189, 2019
-
[27]
Towards understanding biased client selection in federated learning,
Y . J. Cho, J. Wang, and G. Joshi, “Towards understanding biased client selection in federated learning,” inInternational Conference on Artificial Intelligence and Statistics, 2022, pp. 10 351–10 375
2022
-
[28]
Energy efficient federated learning over wireless communication networks,
Z. Yang, M. Chen, W. Saad, C. S. Hong, and M. Shikh-Bahaei, “Energy efficient federated learning over wireless communication networks,” IEEE Transactions on Wireless Communications, vol. 20, no. 3, 2020
2020
-
[29]
Min-max cost optimization for efficient hierarchical federated learning in wireless edge networks,
J. Feng, L. Liu, Q. Pei, and K. Li, “Min-max cost optimization for efficient hierarchical federated learning in wireless edge networks,”IEEE Transactions on Parallel and Distributed Systems, vol. 33, no. 11, 2021
2021
-
[30]
Joint device selection and power control for wireless federated learning,
W. Guo, R. Li, C. Huang, X. Qin, K. Shen, and W. Zhang, “Joint device selection and power control for wireless federated learning,”IEEE Journal on Selected Areas in Communications, vol. 40, no. 8, 2022
2022
-
[31]
Wireless federated learning over resource-constrained networks: Digital versus analog transmissions,
J. Yao, W. Xu, Z. Yang, X. You, M. Bennis, and H. V . Poor, “Wireless federated learning over resource-constrained networks: Digital versus analog transmissions,”IEEE Transactions on Wireless Communications, vol. 23, no. 10, pp. 14 020–14 036, 2024
2024
-
[32]
Base station sleeping and resource allocation in renewable energy powered cellular networks,
J. Gong, J. S. Thompson, S. Zhou, and Z. Niu, “Base station sleeping and resource allocation in renewable energy powered cellular networks,” IEEE Transactions on Communications, vol. 62, no. 11, 2014
2014
-
[33]
Deep metallic surface defect detection: The new benchmark and detection network,
X. Lv, F. Duan, J.-j. Jiang, X. Fu, and L. Gan, “Deep metallic surface defect detection: The new benchmark and detection network,”Sensors, vol. 20, no. 6, p. 1562, 2020
2020
-
[34]
Learning multiple layers of features from tiny images,
A. Krizhevsky, G. Hintonet al., “Learning multiple layers of features from tiny images,” 2009
2009
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.