Foundation VAEs for 3D CT Reconstruction, Augmentation, and Generation
Pith reviewed 2026-06-28 22:47 UTC · model grok-4.3
The pith
A single foundation VAE pretrained on natural images and videos reconstructs 3D CT volumes, suppresses noise, and supports generation while keeping its encoder and decoder frozen.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
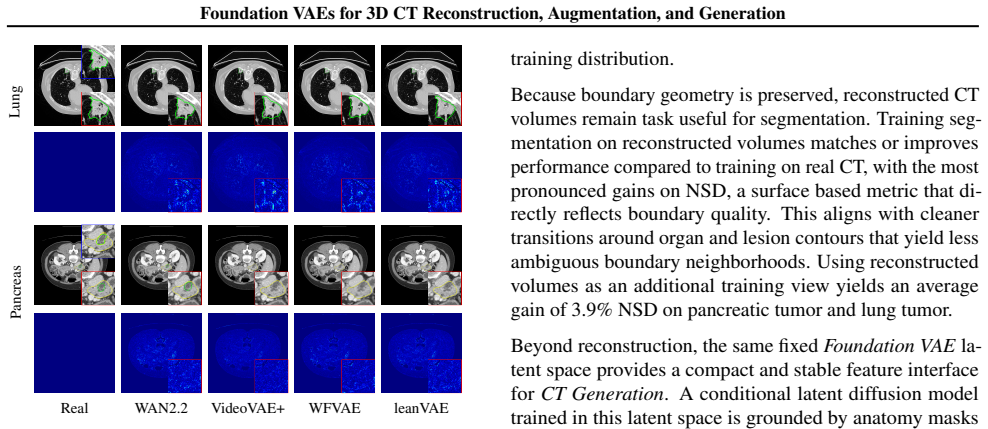
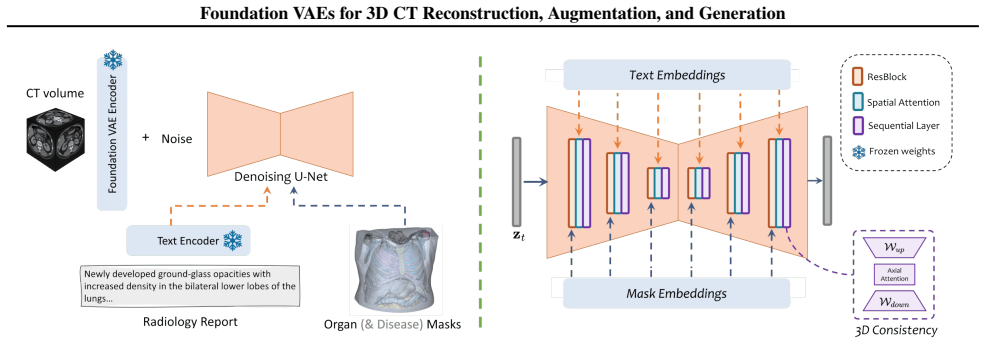
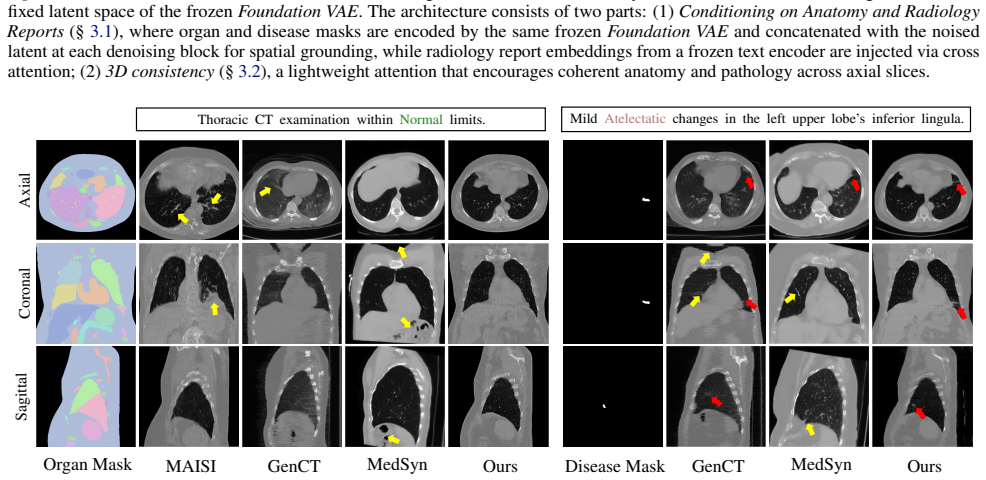
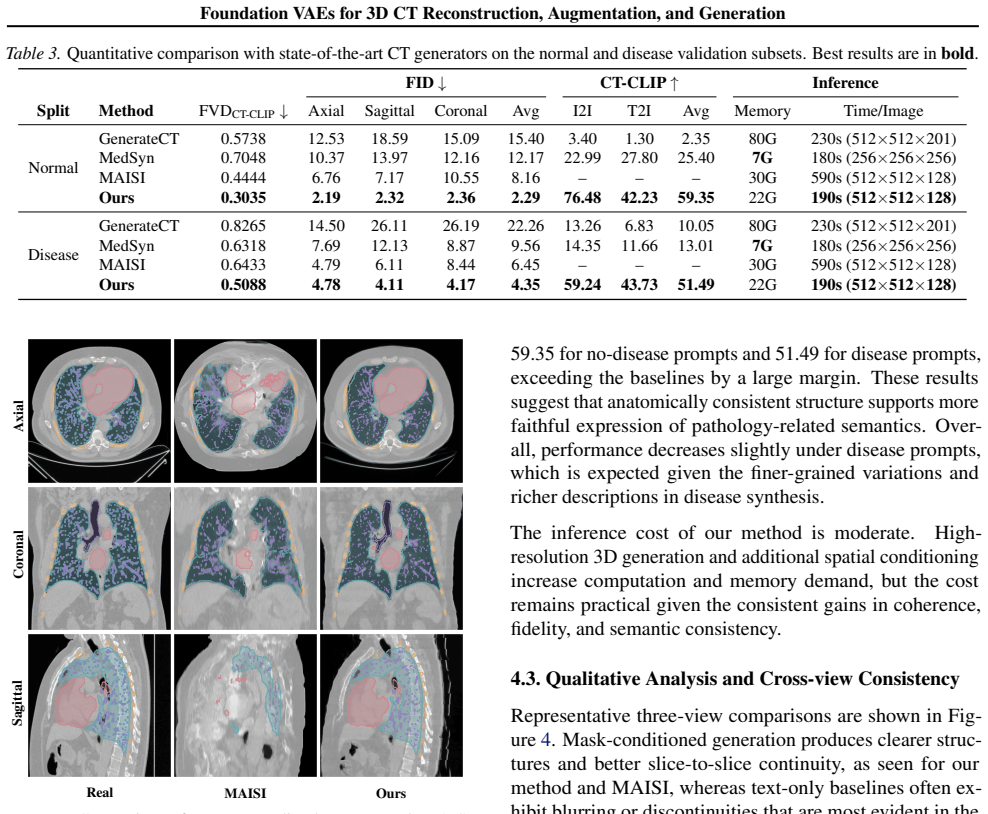
A single Foundation VAE, pretrained at scale on natural images and videos, can serve as a unified interface for CT Reconstruction, Augmentation, and Generation. With both encoder and decoder frozen, the Foundation VAE reconstructs CT volumes with preserved anatomy while suppressing acquisition noise; training segmentation models on these reconstructions improves surface accuracy by 3.9% NSD on average for pancreatic tumor and lung tumor. Within the same Foundation VAE latent space, a conditional latent diffusion model achieves 3.9% lower average FVD with 36.2% higher CT CLIP score, and improves multi-disease generation faithfulness across 18 types by 2.76% AUC.
What carries the argument
The frozen foundation VAE whose latent space, learned from natural images and videos, maps 3D CT volumes for reconstruction and hosts a conditional diffusion model for generation.
If this is right
- Reconstruction from the frozen VAE preserves anatomy and reduces acquisition noise, raising average NSD by 3.9 percent on pancreatic and lung tumor segmentation.
- A conditional latent diffusion model placed in the same space lowers average FVD by 3.9 percent and raises CT CLIP score by 36.2 percent.
- Multi-disease generation across 18 conditions gains 2.76 percent AUC in faithfulness.
Where Pith is reading between the lines
- The same frozen VAE could be tested on other 3D medical volumes such as MRI without retraining the core model.
- Clinical pipelines might insert the reconstruction step before any downstream task to reduce the effect of scanner variability.
- Generation quality could be further probed by measuring how well synthetic volumes support rare-disease classification.
Load-bearing premise
Latent representations learned from natural images and videos transfer to 3D CT volumes well enough to preserve clinically relevant anatomy without any changes to the VAE.
What would settle it
A test set of CT volumes from varied scanners and diseases where the frozen VAE reconstructions lose key anatomical landmarks or fail to improve downstream segmentation accuracy.
Figures

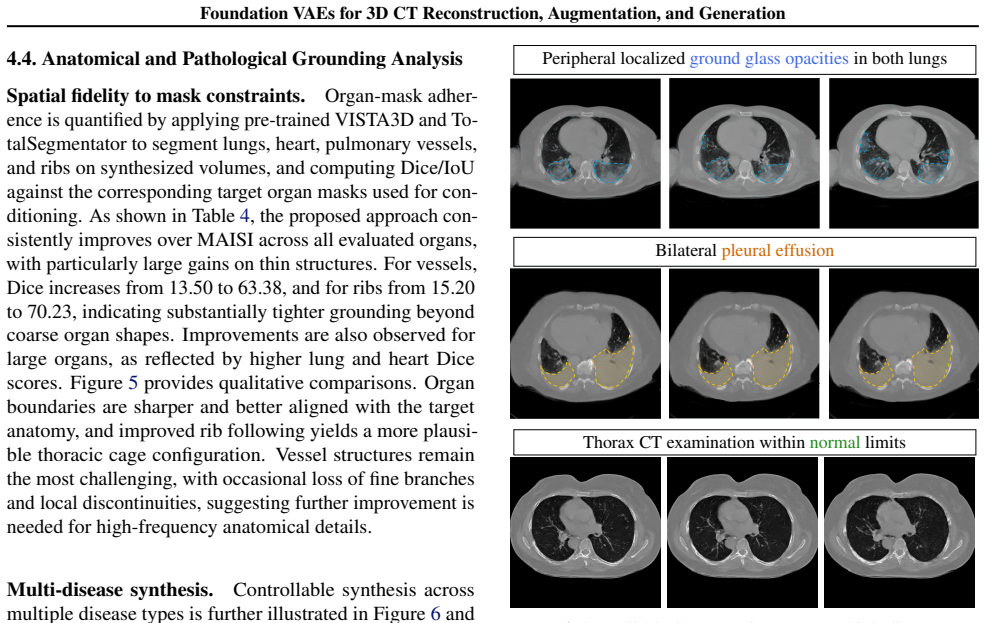
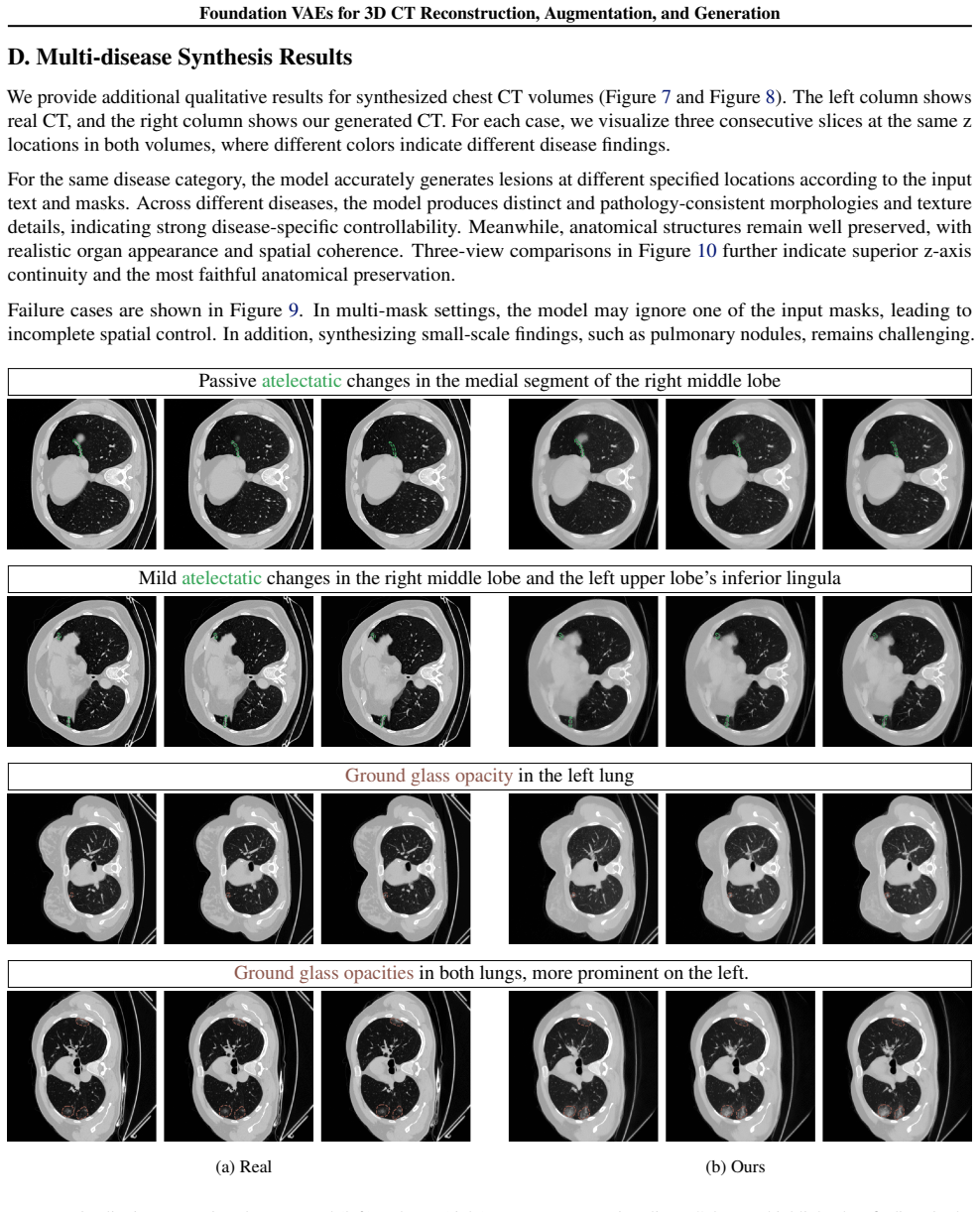
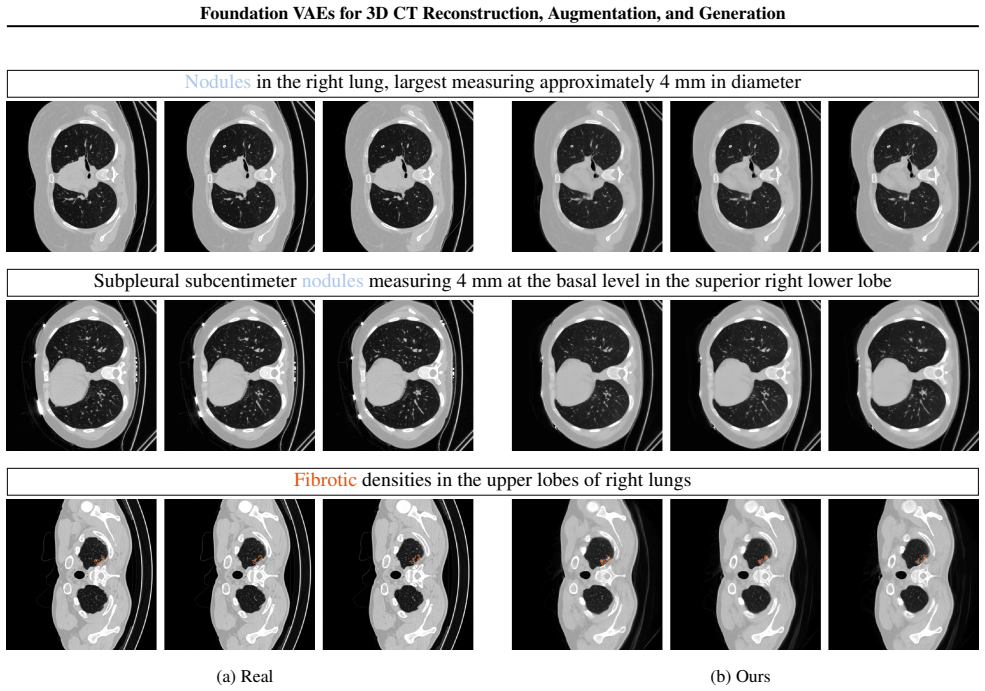
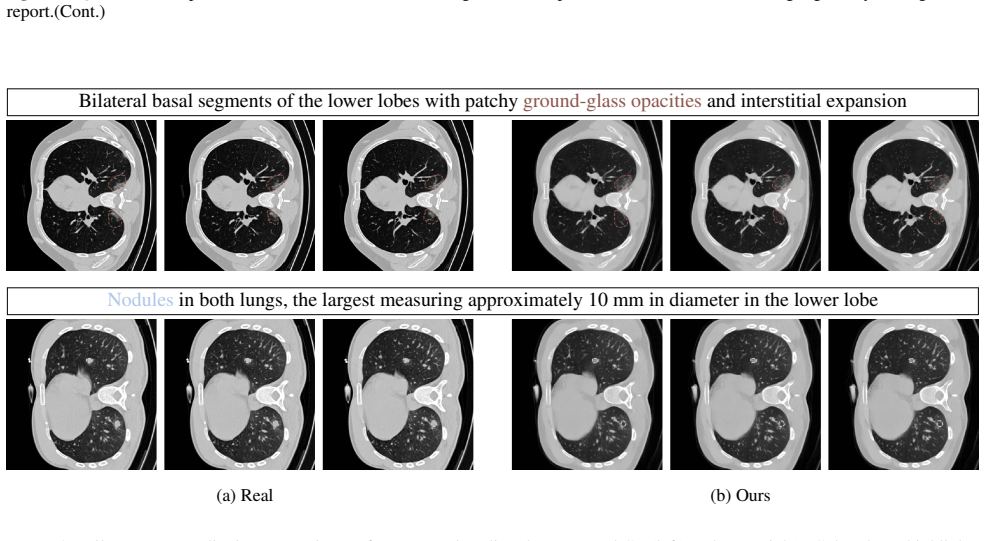
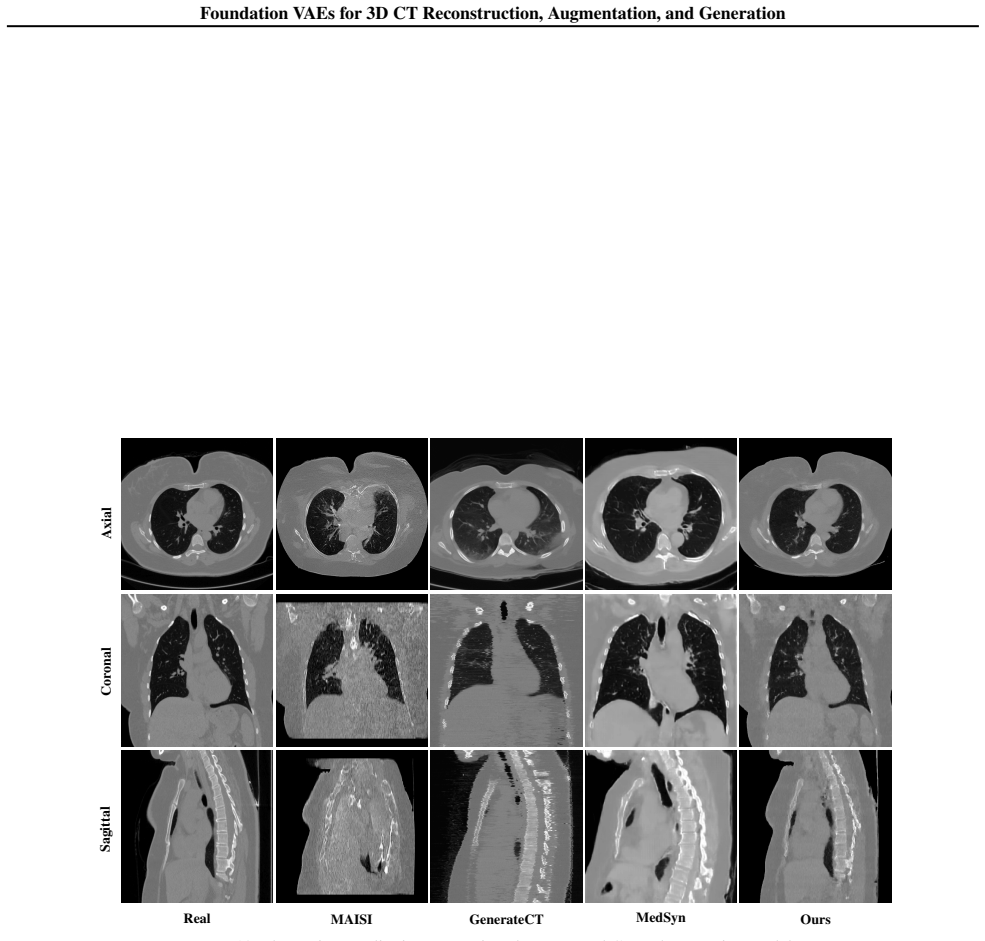
read the original abstract
Variational autoencoders (VAEs) compress high resolution CT volumes into compact latents while preserving clinically relevant structure. However, training CT-specific VAEs from scratch or heavily fine-tuning them incurs substantial computational and engineering cost, and often degrades under heterogeneous scanners, protocols, and diseases. This paper makes a progressive stride toward training-free medical VAEs by leveraging a critical observation: a single Foundation VAE, pretrained at scale on natural images and videos, can serve as a unified interface for CT Reconstruction, Augmentation, and Generation. With both encoder and decoder frozen, the Foundation VAE reconstructs CT volumes with preserved anatomy while suppressing acquisition noise; training segmentation models on these reconstructions improves surface accuracy by 3.9% NSD on average for pancreatic tumor and lung tumor. Within the same Foundation VAE latent space, a conditional latent diffusion model achieves 3.9% lower average FVD with 36.2% higher CT CLIP score, and improves multi-disease generation faithfulness across 18 types by 2.76% AUC. These results demonstrate Foundation VAEs as a practical interface for scalable CT representation reuse and faithful CT generation. Our code and demo are available at https://github.com/qic999/Foundation-VAE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that a single Foundation VAE pretrained at scale on natural images and videos can serve as a unified frozen interface for 3D CT reconstruction (preserving anatomy while suppressing noise), augmentation, and generation. With encoder and decoder frozen, it reports average improvements of 3.9% NSD on pancreatic/lung tumor segmentation, 3.9% lower FVD, 36.2% higher CT CLIP score, and 2.76% AUC on multi-disease generation across 18 types; code and demo are released.
Significance. If the frozen transfer holds, the result would enable substantial reuse of large-scale natural-image/video VAEs for medical CT tasks, lowering the cost of domain-specific VAE training and supporting scalable representation learning. Explicit release of code and demo strengthens reproducibility.
major comments (2)
- [Abstract] Abstract: the central claim that frozen natural-image/video VAE latents preserve clinically relevant anatomy in CT volumes (different intensity scale, noise statistics, 3D structure) is load-bearing, yet the abstract provides no error bars, baseline details, dataset descriptions, or verification that gains arise from the transferred latents rather than generic denoising/preprocessing.
- [Methods/Experiments] The weakest assumption (transfer of latents without any adaptation or fine-tuning) is not secured by an ablation that isolates the VAE mapping from intensity normalization or simple denoising; downstream metric gains could be explained by preprocessing alone.
minor comments (1)
- [Abstract] Abstract: the phrase 'progressive stride toward training-free medical VAEs' is slightly overstated given that a conditional latent diffusion model is still trained on the frozen latents.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to strengthen the presentation and experimental validation.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that frozen natural-image/video VAE latents preserve clinically relevant anatomy in CT volumes (different intensity scale, noise statistics, 3D structure) is load-bearing, yet the abstract provides no error bars, baseline details, dataset descriptions, or verification that gains arise from the transferred latents rather than generic denoising/preprocessing.
Authors: We agree that the abstract is concise and would benefit from additional supporting details. In the revised version we will expand it to report error bars on the key metrics (NSD, FVD, CT CLIP score, AUC), name the primary datasets and baselines, and add a clause noting that the experiments section verifies the contribution of the transferred latents beyond standard preprocessing. revision: yes
-
Referee: [Methods/Experiments] The weakest assumption (transfer of latents without any adaptation or fine-tuning) is not secured by an ablation that isolates the VAE mapping from intensity normalization or simple denoising; downstream metric gains could be explained by preprocessing alone.
Authors: This is a fair observation. The manuscript already compares against standard intensity-normalization and denoising pipelines and shows additional gains when the frozen foundation VAE is used, but it does not contain a dedicated ablation that applies only those preprocessing steps without the VAE. We will add this targeted ablation in the revision to isolate the VAE mapping more clearly. revision: yes
Circularity Check
No circularity; empirical transfer results with no self-referential derivations
full rationale
The paper's central claim rests on empirical evaluation of a frozen pretrained VAE transferred to CT volumes, reporting downstream metrics such as NSD, FVD, and AUC on segmentation and generation tasks. No equations, parameter fits, or uniqueness theorems are invoked that reduce the output to the input by construction. No self-citations serve as load-bearing premises for the transfer assumption, and the work is self-contained against external benchmarks via reported comparisons.
Axiom & Free-Parameter Ledger
free parameters (1)
- conditional latent diffusion model parameters
axioms (1)
- domain assumption Pretrained VAE latent space from natural images and videos captures clinically relevant CT structure
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2403.17834 (2024)
Ai, D., Lin, S., Wu, J., Zhu, J., Liu, T., Xu, L., Hu, X., Xie, Y ., Zhang, J., Zhou, Y ., Liu, Y ., and Li, X. Ct-rate: A large-scale dataset of chest ct volumes with paired radiol- ogy reports.arXiv preprint arXiv:2403.17834,
-
[2]
E., Zhang, X., Zhu, M., Alabbad, M
Baharoon, M., Luo, L., Moritz, M., Kumar, A., Kim, S. E., Zhang, X., Zhu, M., Alabbad, M. H., Alhazmi, M. S., Mistry, N. P., et al. Rexgroundingct: A 3d chest ct dataset for segmentation of findings from free-text reports.arXiv preprint arXiv:2507.22030,
-
[3]
MONAI: An open-source framework for deep learning in healthcare
Cardoso, M. J., Li, W., Brown, R., Ma, N., Kerfoot, E., Wang, Y ., Murrey, B., Myronenko, A., Zhao, C., Yang, D., et al. Monai: An open-source framework for deep learning in healthcare.arXiv preprint arXiv:2211.02701,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Towards generalizable tumor synthesis
Chen, Q., Chen, X., Song, H., Xiong, Z., Yuille, A., Wei, C., and Zhou, Z. Towards generalizable tumor synthesis. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 11147–11158, 2024a. Chen, Q., Lai, Y ., Chen, X., Hu, Q., Yuille, A., and Zhou, Z. Analyzing tumors by synthesis.Generative Machine Learning Models in Me...
-
[5]
URL https://arXiv.org/abs/ 2409.11169. arXiv:2409.11169v2. Guo, P., Zhao, C., Yang, D., He, Y ., Nath, V ., Xu, Z., Bassi, P. R., Zhou, Z., Simon, B. D., Harmon, S. A., et al. Text2ct: Towards 3d ct volume generation from free- text descriptions using diffusion model.arXiv preprint arXiv:2505.04522, 2025a. Guo, P., Zhao, C., Yang, D., Xu, Z., Nath, V ., T...
-
[6]
URL https: //arxiv.org/abs/2510.20639. He, Y ., Guo, P., Tang, Y ., Myronenko, A., Nath, V ., Xu, Z., Yang, D., Zhao, C., Simon, B., Belue, M., et al. Vista3d: A unified segmentation foundation model for 3d medical imaging. InProceedings of the Computer Vision and Pattern Recognition Conference, pp. 20863–20873,
-
[7]
Kingma, D. P. and Welling, M. Auto-encoding variational bayes.arXiv preprint arXiv:1312.6114,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Li, X., Shuai, Y ., Liu, C., Chen, Q., Wu, Q., Guo, P., Yang, D., Zhao, C., Bassi, P. R., Xu, D., et al. Text-driven tumor synthesis.arXiv preprint arXiv:2412.18589,
-
[9]
Varma, M., Kumar, A., van der Sluijs, R., Ostmeier, S., Blankemeier, L., Chambon, P., Bluethgen, C., Prince, J., Langlotz, C., and Chaudhari, A. Medvae: Effi- cient automated interpretation of medical images with large-scale generalizable autoencoders.arXiv preprint arXiv:2502.14753, 2025a. Varma, M., Kumar, A., van der Sluijs, R., Ostmeier, S., Blankemei...
-
[10]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan, T., Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.-W., Chen, D., Yu, F., Zhao, H., Yang, J., et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Freetumor: Ad- vance tumor segmentation via large-scale tumor synthesis
Wu, L., Zhuang, J., Ni, X., and Chen, H. Freetumor: Ad- vance tumor segmentation via large-scale tumor synthesis. arXiv preprint arXiv:2406.01264,
-
[12]
Large motion video autoencoding with cross-modal video vae.arXiv preprint arXiv:2412.17805,
Xing, Y ., Fei, Y ., He, Y ., Chen, J., Xie, J., Chi, X., and Chen, Q. Large motion video autoencoding with cross-modal video vae.arXiv preprint arXiv:2412.17805,
-
[13]
arXiv:2310.03559v? Zhao, S., Zhang, Y ., Cun, X., Yang, S., Niu, M., Li, X., Hu, W., and Shan, Y
URL https://arxiv.org/abs/ 2310.03559. arXiv:2310.03559v? Zhao, S., Zhang, Y ., Cun, X., Yang, S., Niu, M., Li, X., Hu, W., and Shan, Y . Cv-vae: A compatible video vae for latent generative video models.Advances in Neural Information Processing Systems, 37:12847–12871,
-
[14]
Relative Latent Size
andW AN2.2(Wan et al., 2025): video autoencoders released with the Wan video model family, used as latent encoders and decoders for large scale video generation. •VideoV AE+(Xing et al., 2024): a cross modal video V AE designed for large motion video autoencoding. • IVV AE(Wu et al., 2025): an improved video V AE that strengthens spatiotemporal reconstruc...
2025
-
[15]
The diseased subset is defined by its overlap with ReXGround- ingCT (Baharoon et al., 2025)
is our primary dataset. The diseased subset is defined by its overlap with ReXGround- ingCT (Baharoon et al., 2025). The train/test split is re-defined because the original ReXGroundingCT split leaves some disease categories unrepresented in the test set; a strict patient-level split is enforced to prevent any leakage. In total, the generation task compri...
2025
-
[16]
The synthetic training data use the same text prompts, organ masks, and disease masks
For the downstream classification task, we further sample 500 training volumes from the generative model training set. The synthetic training data use the same text prompts, organ masks, and disease masks. We also sample 200 validation volumes from the original CT-RATE dataset, as disease masks are not required for classification. All models are implement...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.