Zero Collapse: A Failure Mode of Policy Gradient Methods in Discontinuous Reward Environments
Pith reviewed 2026-06-29 00:01 UTC · model grok-4.3
The pith
Policy gradient methods can overshoot into flat zero-reward regions in discontinuous auction settings and become trapped there.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
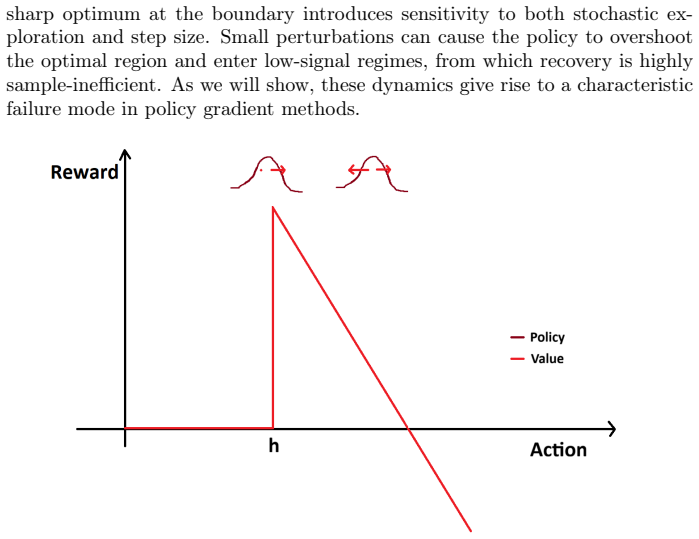
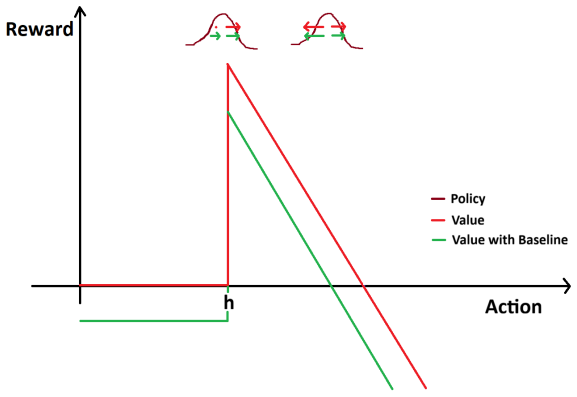
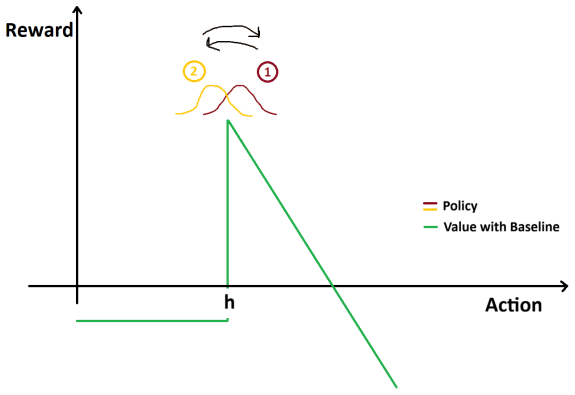
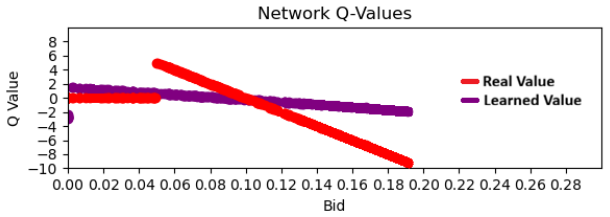
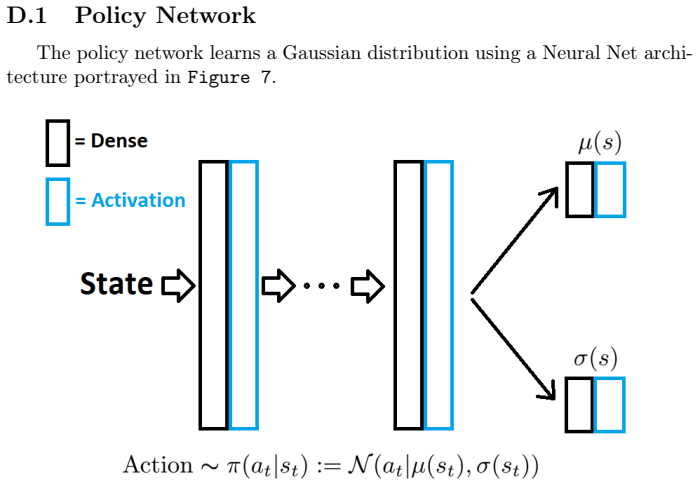
In discontinuous reward environments such as first-price auctions, policy gradient methods suffer zero collapse: stochastic updates cause policies to overshoot high-reward thresholds and enter flat zero-reward zones, from which recovery is sample-inefficient due to vanishing gradient signals. Actor-critic variants accelerate this trapping through biased value estimates.
What carries the argument
Zero collapse, the movement of a policy into flat zero-reward regions where gradient information vanishes because of the discontinuous, cliff-like reward structure.
If this is right
- Actor-critic methods are more prone to zero collapse than pure policy-gradient methods because biased value estimates accelerate movement into zero regions.
- Larger policy stochasticity or larger step sizes increase the probability of overshooting into zero-reward zones.
- Careful initialization near high-reward thresholds and certain network architecture choices reduce the chance of entering and remaining in zero regions.
- A formal RL framework for auction environments captures the structural properties that produce these flat zero-reward landscapes.
Where Pith is reading between the lines
- The same trapping mechanism could appear in any RL task whose reward is zero below a sharp threshold, such as certain safety-constrained control problems.
- Methods that estimate action values directly rather than through policy gradients might sidestep zero collapse by retaining signal even when the current policy yields zero reward.
- Hybrid exploration strategies that temporarily increase variance when the observed reward drops to zero could be tested as a practical countermeasure beyond the initialization fixes proposed.
Load-bearing premise
The reward function contains flat zero-reward regions separated by sharp boundaries, and the absence of gradient information inside those regions is what makes recovery sample-inefficient.
What would settle it
An experiment in which an agent started inside a zero-reward region reaches optimal bidding performance with roughly the same number of samples as an agent started near the high-reward threshold would falsify the claim that zero collapse traps agents.
Figures


read the original abstract
Bidding in repeated auctions is a central challenge for reinforcement learning (RL), combining continuous control with the strategic complexities of digital advertising. While policy gradient and value-based methods seem well-suited for these settings, they often struggle with the discontinuous, "cliff-like" nature of auction reward landscapes. In a first-price auction, for example, a bidder receives zero reward until they cross a specific threshold, after which the reward decreases as the bid increases. This creates a landscape of flat, zero-reward regions separated by sharp boundaries. We identify a fundamental failure mode in this setting termed "zero collapse." We show that stochastic exploration and gradient-based updates can cause policies to overshoot optimal high-reward regions and enter flat, zero-reward regimes. Once there, the lack of an informative gradient signal makes recovery extremely sample-inefficient, effectively trapping the agent. We find that actor-critic methods are particularly susceptible, as biased value estimates can accelerate this movement toward unstable regions. Our contributions include: (1) a mechanistic explanation of how discontinuous rewards lead to vanishing signals and zero collapse; (2) an analysis of the interaction between policy stochasticity and step size; and (3) an empirical demonstration of this phenomenon across REINFORCE and actor-critic variants. We propose practical mitigation strategies involving initialization and architectural choices to improve stability. Finally, we introduce a formal RL framework for auction environments highlighting their unique structural properties.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to identify a 'zero collapse' failure mode in policy gradient methods (REINFORCE and actor-critic variants) for RL in discontinuous-reward environments such as first-price auctions. Stochastic exploration and gradient updates can drive policies from high-reward regions across sharp boundaries into flat zero-reward regimes; once there, the absence of an informative gradient signal renders recovery sample-inefficient, trapping the agent. Actor-critic methods are said to be especially vulnerable due to biased value estimates. Contributions include a mechanistic explanation of vanishing signals, analysis of policy stochasticity and step-size interactions, empirical demonstrations, mitigation strategies via initialization and architecture, and a formal RL framework for auction environments.
Significance. If the central mechanism is rigorously established, the work would be significant for RL applications in auction bidding and other discontinuous-reward domains, offering both a diagnostic for observed instabilities and practical mitigations. The formal auction framework is a constructive contribution. However, the abstract supplies no derivations, equations, or quantitative experimental details, so the strength of the result cannot yet be assessed.
major comments (2)
- [Abstract / mechanistic explanation (contribution 1)] The core claim that flat zero-reward regimes produce a 'lack of an informative gradient signal' rendering recovery 'extremely sample-inefficient' requires an auxiliary argument that the policy-gradient estimator is effectively zero (or that its variance swamps any tail-sample signal). For any stochastic policy whose support overlaps the discontinuity (e.g., Gaussian bid distribution with mean below threshold but positive variance), the expectation E[∇log π(a) R(a)] receives nonzero contributions from the positive-reward tail; this bias is not identically zero. The manuscript must supply either a variance bound or explicit gradient-norm measurements showing the signal is negligible, otherwise the trapping argument does not follow from the stated mechanism.
- [Empirical demonstration (contribution 3)] The empirical demonstration is described only at the level of 'across REINFORCE and actor-critic variants' with no reported metrics, environment parameters, sample budgets, or statistical controls. Without these, it is impossible to evaluate whether the observed trapping is quantitatively more severe than standard exploration difficulties or whether the proposed mitigations produce statistically reliable improvement.
minor comments (1)
- [Abstract] The abstract states that 'biased value estimates can accelerate this movement' for actor-critic methods but does not specify the bias direction or the value-function approximation used; a concrete example or equation would clarify the interaction.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract / mechanistic explanation (contribution 1)] The core claim that flat zero-reward regimes produce a 'lack of an informative gradient signal' rendering recovery 'extremely sample-inefficient' requires an auxiliary argument that the policy-gradient estimator is effectively zero (or that its variance swamps any tail-sample signal). For any stochastic policy whose support overlaps the discontinuity (e.g., Gaussian bid distribution with mean below threshold but positive variance), the expectation E[∇log π(a) R(a)] receives nonzero contributions from the positive-reward tail; this bias is not identically zero. The manuscript must supply either a variance bound or explicit gradient-norm measurements showing the signal is negligible, otherwise the trapping argument does not follow from the stated mechanism.
Authors: We agree that an auxiliary argument is needed to establish negligibility rather than exact zero. While the tail contribution is nonzero in expectation, it is typically overwhelmed by estimator variance for policies with moderate stochasticity. In the revision we will add a variance bound on the policy-gradient estimator when the mean lies in the zero-reward region and will report explicit gradient-norm measurements from the experiments demonstrating that the effective signal is orders of magnitude smaller than in the high-reward region. revision: yes
-
Referee: [Empirical demonstration (contribution 3)] The empirical demonstration is described only at the level of 'across REINFORCE and actor-critic variants' with no reported metrics, environment parameters, sample budgets, or statistical controls. Without these, it is impossible to evaluate whether the observed trapping is quantitatively more severe than standard exploration difficulties or whether the proposed mitigations produce statistically reliable improvement.
Authors: We acknowledge that the current presentation of the experiments lacks sufficient quantitative detail for full evaluation. In the revised manuscript we will expand the empirical section to report all metrics, environment parameters, sample budgets, and statistical controls (including standard errors over multiple random seeds) and will add explicit comparisons showing that the observed trapping exceeds typical exploration difficulties. revision: yes
Circularity Check
No circularity; derivation is observational and empirical
full rationale
The paper identifies 'zero collapse' via mechanistic description and empirical demonstration across REINFORCE and actor-critic methods. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The central claim rests on the structural properties of discontinuous auction rewards and observed trapping behavior, which are externally falsifiable and not reduced to self-definition or prior author results by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Asynchronous methods for deep reinforcement learn- ing.International Conference on Machine Learning, 2016
Volodymyr Mnih et al. Asynchronous methods for deep reinforcement learn- ing.International Conference on Machine Learning, 2016
2016
-
[2]
Curiosity- driven exploration by self-supervised prediction
Deepak Pathak, Pulkit Agrawal, Alexei Efros, and Trevor Darrell. Curiosity- driven exploration by self-supervised prediction. InICML, 2017
2017
-
[3]
Trust region policy optimization.International Conference on Ma- chine Learning, 2015
John Schulman, Sergey Levine, Philipp Moritz, Michael Jordan, and Pieter Abbeel. Trust region policy optimization.International Conference on Ma- chine Learning, 2015
2015
-
[4]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[5]
Sutton and Andrew G
Richard S. Sutton and Andrew G. Barto.Reinforcement Learning: An In- troduction. MIT Press, 2 edition, 2018
2018
-
[6]
Sutton, David McAllester, Satinder Singh, and Yishay Mansour
Richard S. Sutton, David McAllester, Satinder Singh, and Yishay Mansour. Policy gradient methods for reinforcement learning with function approxi- mation.Advances in Neural Information Processing Systems, 12, 2000
2000
-
[7]
Williams
Ronald J. Williams. Simple statistical gradient-following algorithms for con- nectionist reinforcement learning.Machine Learning, 8(3–4):229–256, 1992
1992
-
[8]
Optimalreal-time bidding for display advertising
WeinanZhang, ShuaiYuan, JunWang, andXuehuaShen. Optimalreal-time bidding for display advertising. InProceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2014. 21
2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.