PINNs Failure Modes are Overfitting
Pith reviewed 2026-06-28 23:53 UTC · model grok-4.3
The pith
Failure modes in Physics-Informed Neural Networks result from overfitting to collocation points.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
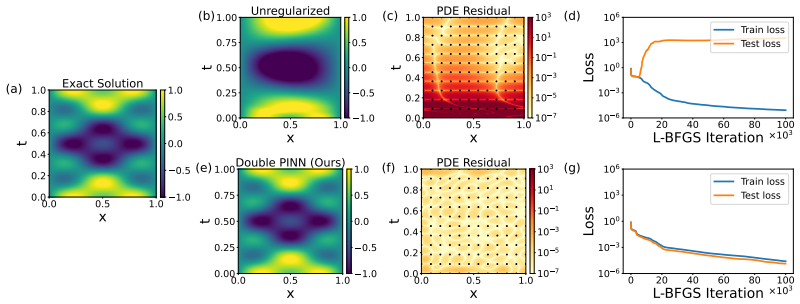
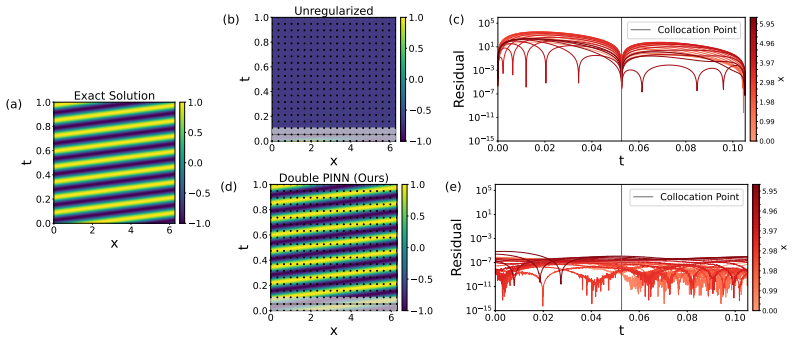
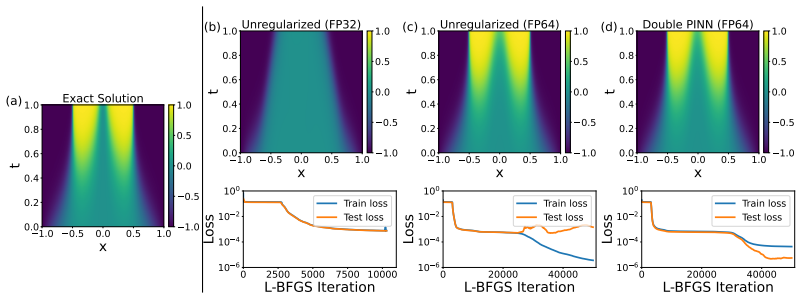
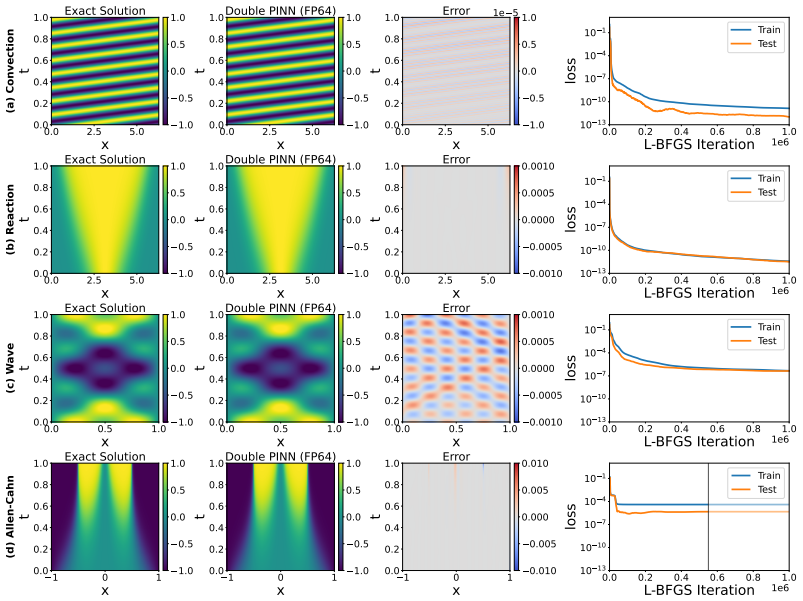
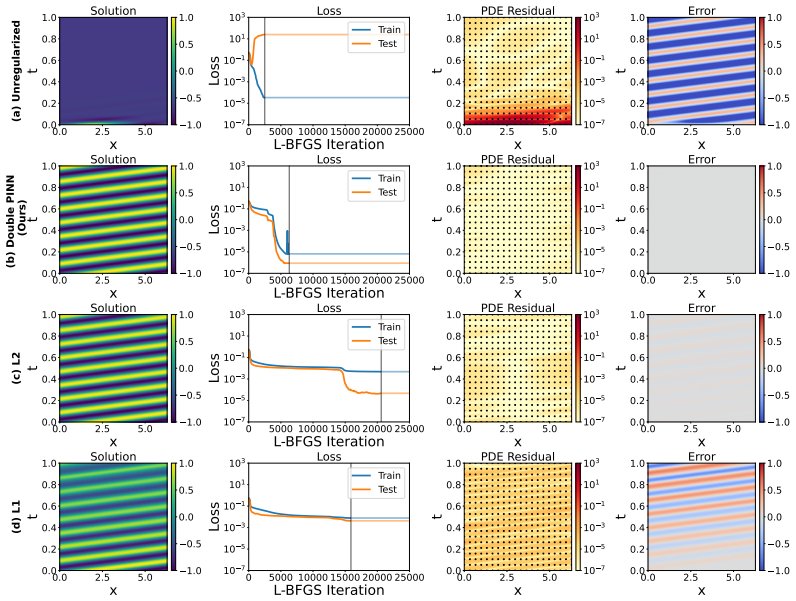
By directly visualizing the residual, failure modes are the result of overfitting: the loss is minimized on the collocation points, but not elsewhere. Applying regularization causes the failure modes to vanish. Extending double backpropagation over the full set of residuals achieves state-of-the-art performance on four standard failure mode equations with up to 23× fewer collocation points and a vanilla architecture.
What carries the argument
Visualization of the residual field over the full domain, which reveals minimization only at collocation points.
Load-bearing premise
The mismatch between low residual at collocation points and high residual elsewhere is the direct cause of convergence to incorrect solutions.
What would settle it
Train a PINN on a known failure-mode equation, apply regularization, and check whether the residual becomes uniformly low everywhere and the solution matches the correct one; if an incorrect solution persists despite uniform low residual, the overfitting claim is challenged.
Figures


read the original abstract
Physics-Informed Neural Networks (PINNs) are a common class of machine learning-based partial differential equation (PDE) solvers which train a network to represent a solution by minimizing a residual loss that encodes the PDE. Despite their successes, they are known to fail on certain simple equations, converging to an incorrect solution despite low loss. These failure modes have garnered significant attention in the literature over the past several years, motivating both architectural and optimization based solutions. By directly visualizing the residual, we show that failure modes are the result of overfitting: the loss is minimized on the collocation points, but not elsewhere. Applying regularization causes the failure modes to vanish. Finally, we extend double backpropagation over the full set of residuals, and use it to achieve state-of-the-art performance on four standard failure mode equations with up to $23\times$ fewer collocation points and a vanilla architecture.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that PINN failure modes on simple PDEs—convergence to incorrect solutions despite low training loss—are caused by overfitting, where the PDE residual is minimized only at collocation points but remains high elsewhere. This is supported by direct residual visualizations; applying regularization eliminates the mismatch and the failures. The authors further extend double backpropagation to the full residual set and report state-of-the-art results on four standard benchmark equations, using up to 23× fewer collocation points with a vanilla network architecture.
Significance. If the interpretation is substantiated, the work supplies a concrete mechanistic account of a well-known PINN pathology together with a lightweight regularization fix and an efficient double-backprop variant. The reported gains in accuracy and data efficiency on established test cases would be of direct practical value to the PINN literature.
major comments (2)
- [Abstract and visualization/results sections] The central claim equates the observed low residual on collocation points and high residual elsewhere with 'overfitting' that directly produces incorrect convergence. Visualization and the fact that regularization removes both the mismatch and the failure are presented as evidence, yet no ablation isolates this mechanism from alternatives (e.g., optimizer reaching a poor local minimum due to loss-landscape stiffness or gradient pathologies). This causal link is load-bearing for the title and abstract conclusions.
- [Method / experimental results on the four benchmark equations] The double-backpropagation extension is reported to achieve SOTA performance, but the manuscript does not detail how the 'full set of residuals' is constructed, which terms receive the second derivative, or how this differs quantitatively from prior double-backprop uses in PINNs. Without these specifics the performance claims cannot be fully evaluated.
minor comments (2)
- [Figures] Figure captions and axis labels for the residual visualizations should explicitly state the PDE, collocation-point density, and network architecture used in each panel to allow direct replication.
- [Abstract and results tables] The abstract states 'up to 23× fewer collocation points'; the corresponding table or text should report the exact counts and the baseline methods against which the factor is measured.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract and visualization/results sections] The central claim equates the observed low residual on collocation points and high residual elsewhere with 'overfitting' that directly produces incorrect convergence. Visualization and the fact that regularization removes both the mismatch and the failure are presented as evidence, yet no ablation isolates this mechanism from alternatives (e.g., optimizer reaching a poor local minimum due to loss-landscape stiffness or gradient pathologies). This causal link is load-bearing for the title and abstract conclusions.
Authors: The direct visualization of the PDE residual across the entire domain explicitly demonstrates that the loss is minimized exclusively at collocation points while remaining high elsewhere; this constitutes overfitting by definition in the context of the residual loss. Regularization eliminates both the spatial mismatch and the incorrect convergence, providing supporting evidence for causality. While alternative mechanisms such as loss-landscape stiffness cannot be ruled out in every possible scenario, the presented visualizations and regularization results isolate the overfitting effect as the operative mechanism here. We will add a dedicated discussion paragraph addressing potential alternative explanations in the revised manuscript. revision: partial
-
Referee: [Method / experimental results on the four benchmark equations] The double-backpropagation extension is reported to achieve SOTA performance, but the manuscript does not detail how the 'full set of residuals' is constructed, which terms receive the second derivative, or how this differs quantitatively from prior double-backprop uses in PINNs. Without these specifics the performance claims cannot be fully evaluated.
Authors: We agree that the current manuscript lacks sufficient implementation details. In the revised version we will expand the Methods section to specify (i) how the full residual set is assembled from the PDE operator, (ii) precisely which residual terms receive the second-derivative computation, and (iii) a quantitative comparison (in terms of additional gradient operations and memory) to earlier double-backpropagation usages in the PINN literature. revision: yes
Circularity Check
No circularity; claims rest on direct residual visualization and regularization experiments
full rationale
The paper's central argument equates observed low residual at collocation points (high elsewhere) with overfitting as the cause of failure modes, supported by visualizations and the empirical effect of regularization (plus an extension of double backpropagation). No derivation reduces a claimed prediction or result to its own fitted inputs by construction, no self-citation is invoked as a load-bearing uniqueness theorem, and no ansatz or renaming is smuggled in. The derivation chain is observational and experimental rather than self-referential, making the result self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A hybrid neural network-first principles approach to process modeling.AIChE J., 38(10):1499–1511, 1992
Dimitris C Psichogios and Lyle H Ungar. A hybrid neural network-first principles approach to process modeling.AIChE J., 38(10):1499–1511, 1992
1992
-
[2]
Solving high-dimensional partial differential equations using deep learning.Proc
Jiequn Han, Arnulf Jentzen, and Weinan E. Solving high-dimensional partial differential equations using deep learning.Proc. Natl. Acad. Sci. U.S.A., 115(34):8505–8510, 2018
2018
-
[3]
Artificial neural networks for solving ordinary and partial differential equations.IEEE Trans
Isaac E Lagaris, Aristidis Likas, and Dimitrios I Fotiadis. Artificial neural networks for solving ordinary and partial differential equations.IEEE Trans. Neural Netw. Learn. Syst., 9(5):987–1000, 1998
1998
-
[4]
The deep ritz method: a deep learning-based numerical algorithm for solving variational problems.Commun
Weinan E and Bing Yu. The deep ritz method: a deep learning-based numerical algorithm for solving variational problems.Commun. Math. Stat., 6(1):1–12, 2018
2018
-
[5]
Neural Operator: Graph Kernel Network for Partial Differential Equations
Zongyi Li, Nikola Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Neural operator: Graph kernel network for partial differential equations. arXiv preprint arXiv:2003.03485, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2003
-
[6]
Fourier neural operator for parametric partial differential equations
Zongyi Li, Nikola Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Fourier neural operator for parametric partial differential equations. In International Conference on Learning Representations, 2020
2020
-
[7]
Universal approximation to nonlinear operators by neural networks with arbitrary activation functions and its application to dynamical systems.IEEE Trans
Tianping Chen and Hong Chen. Universal approximation to nonlinear operators by neural networks with arbitrary activation functions and its application to dynamical systems.IEEE Trans. Neural Netw. Learn. Syst., 6(4):911–917, 1995
1995
-
[8]
Physics-informed neural operator for learning partial differential equations.ACM/IMS J
Zongyi Li, Hongkai Zheng, Nikola Kovachki, David Jin, Haoxuan Chen, Burigede Liu, Kamyar Aziz- zadenesheli, and Anima Anandkumar. Physics-informed neural operator for learning partial differential equations.ACM/IMS J. Data Sci., 1(3):1–27, 2024
2024
-
[9]
Functional multi-layer perceptron: a non-linear tool for functional data analysis.Neural Netw., 18(1):45–60, 2005
Fabrice Rossi and Brieuc Conan-Guez. Functional multi-layer perceptron: a non-linear tool for functional data analysis.Neural Netw., 18(1):45–60, 2005
2005
-
[10]
Learning nonlinear operators via deeponet based on the universal approximation theorem of operators.Nat
Lu Lu, Pengzhan Jin, Guofei Pang, Zhongqiang Zhang, and George Em Karniadakis. Learning nonlinear operators via deeponet based on the universal approximation theorem of operators.Nat. Mach. Intell., 3(3): 218–229, 2021
2021
-
[11]
Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations.J
Maziar Raissi, Paris Perdikaris, and George E Karniadakis. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations.J. Comput. Phys., 378:686–707, 2019
2019
-
[12]
Characterizing possible failure modes in physics-informed neural networks
Aditi Krishnapriyan, Amir Gholami, Shandian Zhe, Robert Kirby, and Michael W Mahoney. Characterizing possible failure modes in physics-informed neural networks. InAdvances in Neural Information Processing Systems, volume 34, pages 26548–26560, 2021
2021
-
[13]
When and why pinns fail to train: A neural tangent kernel perspective.J
Sifan Wang, Xinling Yu, and Paris Perdikaris. When and why pinns fail to train: A neural tangent kernel perspective.J. Comput. Phys., 449:110768, 2022
2022
-
[14]
A unified hard- constraint framework for solving geometrically complex pdes
Songming Liu, Hao Zhongkai, Chengyang Ying, Hang Su, Jun Zhu, and Ze Cheng. A unified hard- constraint framework for solving geometrically complex pdes. InAdvances in Neural Information Processing Systems, volume 35, pages 20287–20299, 2022
2022
-
[15]
Haixu Wu, Yuezhou Ma, Hang Zhou, Huikun Weng, Jianmin Wang, and Mingsheng Long. Propinn: Demystifying propagation failures in physics-informed neural networks.arXiv preprint arXiv:2502.00803, 2025
-
[16]
Mitigating propagation failures in physics-informed neural networks using retain-resample-release (r3) sampling
Arka Daw, Jie Bu, Sifan Wang, Paris Perdikaris, and Anuj Karpatne. Mitigating propagation failures in physics-informed neural networks using retain-resample-release (r3) sampling. InInternational Conference on Machine Learning, pages 7264–7302. PMLR, 2023
2023
-
[17]
Respecting causality for training physics-informed neural networks.Comput
Sifan Wang, Shyam Sankaran, and Paris Perdikaris. Respecting causality for training physics-informed neural networks.Comput. Methods Appl. Mech. Eng., 421:116813, 2024. 10
2024
-
[18]
Challenges in training pinns: A loss landscape perspective
Pratik Rathore, Weimu Lei, Zachary Frangella, Lu Lu, and Madeleine Udell. Challenges in training pinns: A loss landscape perspective. InInternational Conference on Machine Learning, pages 42159–42191. PMLR, 2024
2024
-
[19]
Preconditioning for physics-informed neural networks.arXiv preprint arXiv:2402.00531, 2024
Songming Liu, Chang Su, Jiachen Yao, Zhongkai Hao, Hang Su, Youjia Wu, and Jun Zhu. Preconditioning for physics-informed neural networks.arXiv preprint arXiv:2402.00531, 2024
-
[20]
Fp64 is all you need: Rethinking failure modes in physics-informed neural networks
Chenhui Xu, Dancheng Liu, Amir Nassereldine, and Jinjun Xiong. Fp64 is all you need: Rethinking failure modes in physics-informed neural networks. InAdvances in Neural Information Processing Systems, volume 38, pages 142949–142970, 2025
2025
-
[21]
Aditya Prakash
Zhiyuan Zhao, Xueying Ding, and B. Aditya Prakash. PINNsformer: A transformer-based framework for physics-informed neural networks. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[22]
Sub-sequential physics-informed learning with state space model
Chenhui Xu, Dancheng Liu, Yuting Hu, Jiajie Li, Ruiyang Qin, Qingxiao Zheng, and Jinjun Xiong. Sub-sequential physics-informed learning with state space model. InInternational Conference on Machine Learning, pages 69507–69525. PMLR, 2025
2025
-
[23]
Improving generalization performance using double backpropagation
Harris Drucker and Yann Le Cun. Improving generalization performance using double backpropagation. IEEE Trans. Neural Netw., 3(6):991–997, 1992
1992
-
[24]
Dgm: A deep learning algorithm for solving partial differential equations.J
Justin Sirignano and Konstantinos Spiliopoulos. Dgm: A deep learning algorithm for solving partial differential equations.J. Comput. Phys., 375:1339–1364, 2018
2018
-
[25]
Deep learning-based numerical methods for high-dimensional parabolic partial differential equations and backward stochastic differential equations.Commun
Jiequn Han, Arnulf Jentzen, et al. Deep learning-based numerical methods for high-dimensional parabolic partial differential equations and backward stochastic differential equations.Commun. Math. Stat., 5(4): 349–380, 2017
2017
-
[26]
Neural-network-based approximations for solving partial differential equations.Commun
M W M Gamini Dissanayake and Nhan Phan-Thien. Neural-network-based approximations for solving partial differential equations.Commun. Numer. Methods Eng., 10(3):195–201, 1994
1994
-
[27]
On the eigenvector bias of fourier feature networks: From regression to solving multi-scale pdes with physics-informed neural networks.Comput
Sifan Wang, Hanwen Wang, and Paris Perdikaris. On the eigenvector bias of fourier feature networks: From regression to solving multi-scale pdes with physics-informed neural networks.Comput. Methods Appl. Mech. Eng., 384:113938, 2021
2021
-
[28]
Self-adaptive physics-informed neural networks.J
Levi D McClenny and Ulisses M Braga-Neto. Self-adaptive physics-informed neural networks.J. Comput. Phys., 474:111722, 2023
2023
-
[29]
PINNACLE: PINN adaptive collocation and experimental points selection
Gregory Kang Ruey Lau, Apivich Hemachandra, See-Kiong Ng, and Bryan Kian Hsiang Low. PINNACLE: PINN adaptive collocation and experimental points selection. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[30]
Solving differential equations with constrained learning
Viggo Moro and Luiz Chamon. Solving differential equations with constrained learning. InInternational Conference on Learning Representations, volume 2025, pages 44906–44948, 2025
2025
-
[31]
Jerry Liu, Yasa Baig, Denise Hui Jean Lee, Rajat Vadiraj Dwaraknath, Atri Rudra, and Chris Ré. Bwler: Barycentric weight layer elucidates a precision-conditioning tradeoff for pinns.arXiv preprint arXiv:2506.23024, 2025
-
[32]
Dual cone gradient descent for training physics-informed neural networks
Youngsik Hwang and Dong-Young Lim. Dual cone gradient descent for training physics-informed neural networks. InAdvances in Neural Information Processing Systems, volume 37, pages 98563–98595, 2024
2024
-
[33]
MIT press Cambridge, 2016
Ian Goodfellow, Yoshua Bengio, Aaron Courville, and Yoshua Bengio.Deep learning, volume 1. MIT press Cambridge, 2016
2016
-
[34]
MIT press, 2022
Kevin P Murphy.Probabilistic machine learning: an introduction. MIT press, 2022
2022
-
[35]
A simple weight decay can improve generalization
Anders Krogh and John Hertz. A simple weight decay can improve generalization. InAdvances in Neural Information Processing Systems, volume 4, 1991
1991
-
[36]
Regression shrinkage and selection via the lasso.J
Robert Tibshirani. Regression shrinkage and selection via the lasso.J. R. Stat. Soc. Ser. B Stat. Methodol., 58(1):267–288, 1996
1996
-
[37]
Sobolev training for neural networks
Wojciech M Czarnecki, Simon Osindero, Max Jaderberg, Grzegorz Swirszcz, and Razvan Pascanu. Sobolev training for neural networks. InAdvances in Neural Information Processing Systems, volume 30, 2017
2017
-
[38]
Understanding and mitigating gradient flow pathologies in physics-informed neural networks.SIAM J
Sifan Wang, Yujun Teng, and Paris Perdikaris. Understanding and mitigating gradient flow pathologies in physics-informed neural networks.SIAM J. Sci. Comput., 43(5):A3055–A3081, 2021. 11
2021
-
[39]
Gradient-enhanced physics-informed neural networks for forward and inverse pde problems.Comput
Jeremy Yu, Lu Lu, Xuhui Meng, and George Em Karniadakis. Gradient-enhanced physics-informed neural networks for forward and inverse pde problems.Comput. Methods Appl. Mech. Eng., 393:114823, 2022
2022
-
[40]
Sobolev training for physics-informed neural networks.Commun
Hwijae Son, Jin Woo Jang, Woo Jin Han, and Hyung Ju Hwang. Sobolev training for physics-informed neural networks.Commun. Math. Sci., 21(6):1679–1705, 2023
2023
-
[41]
Understanding the difficulty of training deep feedforward neural networks
Xavier Glorot and Yoshua Bengio. Understanding the difficulty of training deep feedforward neural networks. InProceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, pages 249–256. JMLR Workshop and Conference Proceedings, 2010
2010
-
[42]
On the limited memory bfgs method for large scale optimization.Math
Dong C Liu and Jorge Nocedal. On the limited memory bfgs method for large scale optimization.Math. Program., 45(1):503–528, 1989
1989
-
[43]
JAX: composable transformations of Python+NumPy programs, 2018
James Bradbury, Roy Frostig, Peter Hawkins, Matthew James Johnson, Yash Katariya, Chris Leary, Dougal Maclaurin, George Necula, Adam Paszke, Jake VanderPlas, Skye Wanderman-Milne, and Qiao Zhang. JAX: composable transformations of Python+NumPy programs, 2018. URL http://github.com/jax-ml/ jax
2018
-
[44]
Flax: A neural network library and ecosystem for JAX, 2024
Jonathan Heek, Anselm Levskaya, Avital Oliver, Marvin Ritter, Bertrand Rondepierre, Andreas Steiner, and Marc van Zee. Flax: A neural network library and ecosystem for JAX, 2024. URL http://github. com/google/flax
2024
-
[45]
The DeepMind JAX Ecosystem, 2020
DeepMind, Igor Babuschkin, Kate Baumli, Alison Bell, Surya Bhupatiraju, Jake Bruce, Peter Buchlovsky, David Budden, Trevor Cai, Aidan Clark, Ivo Danihelka, Antoine Dedieu, Claudio Fantacci, Jonathan Godwin, Chris Jones, Ross Hemsley, Tom Hennigan, Matteo Hessel, Shaobo Hou, Steven Kapturowski, Thomas Keck, Iurii Kemaev, Michael King, Markus Kunesch, Lena ...
2020
-
[46]
Jason Ansel, Edward Yang, Horace He, Natalia Gimelshein, Animesh Jain, Michael V oznesensky, Bin Bao, Peter Bell, David Berard, Evgeni Burovski, Geeta Chauhan, Anjali Chourdia, Will Constable, Alban Desmaison, Zachary DeVito, Elias Ellison, Will Feng, Jiong Gong, Michael Gschwind, Brian Hirsh, Sherlock Huang, Kshiteej Kalambarkar, Laurent Kirsch, Michael ...
-
[47]
Press, Saul A
William H. Press, Saul A. Teukolsky, William T. Vetterling, and Brian P. Flannery.Numerical Recipes in C: The Art of Scientific Computing. Cambridge University Press, Cambridge, 2nd edition, 1992. 12 A Experimental Setup Here the experimental setup is discussed, along with the training procedure. For the most part, we follow the standard vanilla descripti...
1992
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.