MultiAct: Text-to-Motion Generation from Composite Text via Tailored Attention Guidance
Pith reviewed 2026-06-28 23:12 UTC · model grok-4.3
The pith
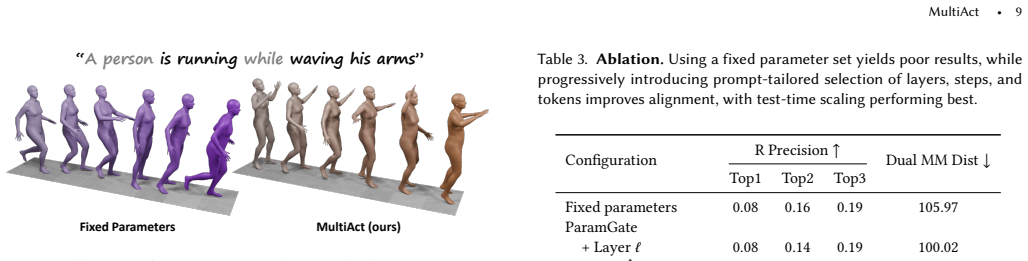
MultiAct generates motions from composite text prompts by amplifying cross-attention scores for neglected action components at inference time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
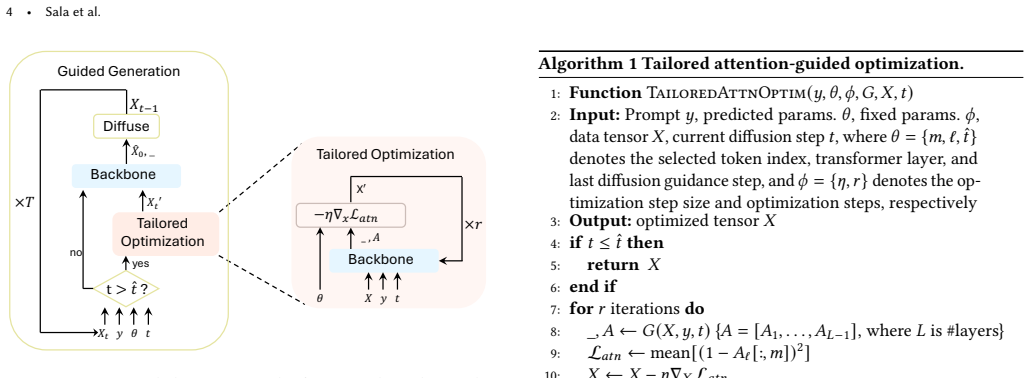
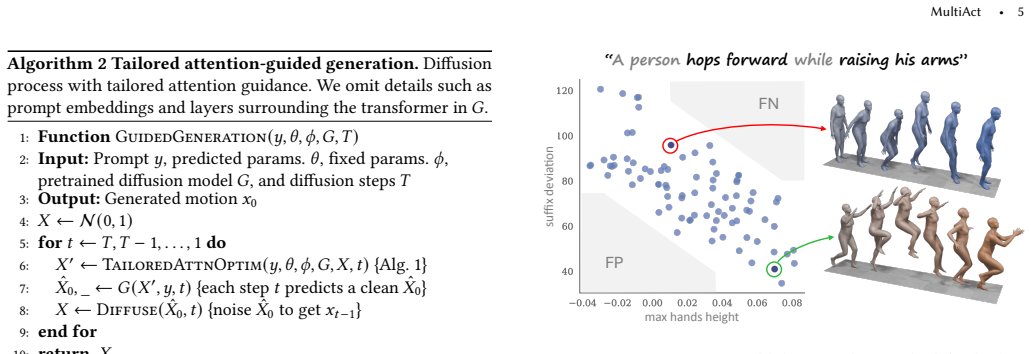
MultiAct is an unpaired inference-time framework that operates on pretrained motion generators without retraining or architectural changes. It counteracts semantic collapse in composite prompts by adaptively amplifying cross-attention scores associated with underrepresented prompt components and uses a lightweight auxiliary decision scheme to select the most effective attention-strengthening parametrization.
What carries the argument
Adaptive amplification of cross-attention scores for underrepresented prompt tokens, selected by a prompt-specific auxiliary decision scheme.
If this is right
- Existing text-to-motion generators achieve higher semantic coverage on prompts with simultaneous actions.
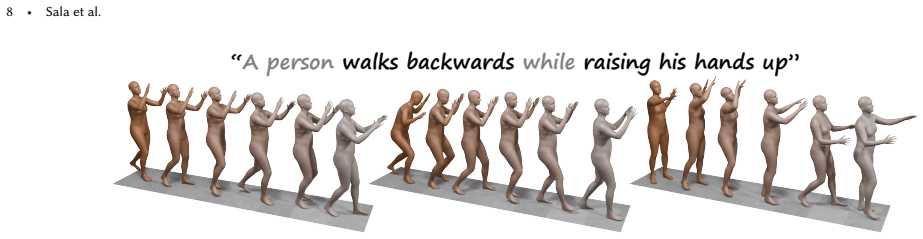
- Motion realism is preserved while adding the missing action components.
- The framework applies to any pretrained model at inference time with no retraining.
- Prompt-specific choices of tokens and layers can be automated by the auxiliary scheme.
Where Pith is reading between the lines
- The same attention modulation idea could be tested on text-to-image models that also drop secondary objects from complex scenes.
- If the auxiliary scheme generalizes, prompt engineering for motion synthesis could become simpler.
- Evaluating the method on prompts with temporally conflicting actions would test whether amplification can resolve contradictions.
Load-bearing premise
Adaptively boosting cross-attention for selected tokens will bring in all prompt actions without creating motion artifacts or lowering quality, and the auxiliary scheme will pick effective settings for any prompt.
What would settle it
A benchmark run on composite prompts where MultiAct either omits described actions or produces less realistic output than an unmodified baseline model.
Figures






read the original abstract
Text-to-motion generation has progressed rapidly in recent years, offering an expressive interface for animation and human-computer interaction. However, current models remain brittle when handling prompts that describe multiple actions occurring at the same time. Rather than realizing all components of a composite description, models frequently prioritize a single dominant action and neglect the rest, leading to incomplete or ambiguous motion. We present MultiAct, an unpaired, inference-time framework for compositional text-to-motion synthesis that operates directly on pretrained motion generators without retraining or architectural modification. Our method counteracts semantic collapse by adaptively amplifying cross-attention scores associated with underrepresented prompt components. We note that effective modulation depends on prompt-specific choices, such as which tokens and layers to target, and introduce a lightweight auxiliary decision scheme that determines the most effective attention-strengthening parametrization. Extensive quantitative and qualitative evaluations demonstrate that MultiAct consistently outperforms existing baselines on composite prompts, achieving improved semantic coverage while preserving motion realism. Project page: https://natsala13.github.io/multiact.github.io.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents MultiAct, an unpaired inference-time framework for compositional text-to-motion synthesis. It operates externally on pretrained generators by adaptively amplifying cross-attention scores for underrepresented components of composite prompts, using a lightweight auxiliary decision scheme to select prompt-specific tokens, layers, and amplification parameters. The central claim is that this yields consistent outperformance over baselines on composite prompts, with improved semantic coverage while preserving motion realism.
Significance. If the empirical claims hold, the contribution would be significant for addressing semantic collapse in multi-action text-to-motion models without retraining or architectural changes. The external, inference-only design is a practical strength that could extend to other pretrained generators, and the focus on attention modulation offers a targeted way to improve coverage of composite descriptions in animation and HCI applications.
major comments (2)
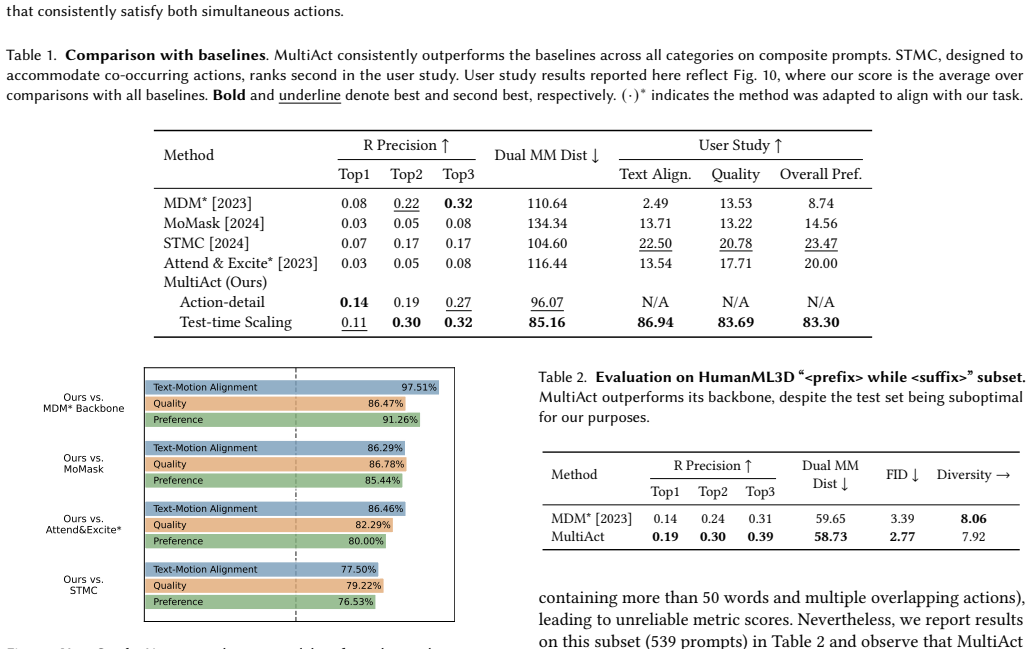
- [Abstract] Abstract: the claim of consistent outperformance on composite prompts is asserted without any reported metrics, baselines, or quantitative results, which is load-bearing for the central empirical claim; the full paper must supply these to substantiate the assertion.
- [Method] Method (auxiliary decision scheme): the reliability of the lightweight auxiliary scheme for selecting effective prompt-specific parametrizations (tokens/layers/strength) for arbitrary composites is not validated in detail; without evidence that it avoids overfitting to evaluated cases or introducing artifacts on novel prompts, the generalization of the outperformance claim remains at risk.
minor comments (1)
- The project page URL is provided, which supports access to qualitative results.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment point-by-point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of consistent outperformance on composite prompts is asserted without any reported metrics, baselines, or quantitative results, which is load-bearing for the central empirical claim; the full paper must supply these to substantiate the assertion.
Authors: The abstract summarizes the findings at a high level without specific numbers, following standard conventions for brevity. The full manuscript substantiates the claim with detailed quantitative evaluations, including metrics, baseline comparisons, and results on composite prompts, as reported in the Experiments section. revision: no
-
Referee: [Method] Method (auxiliary decision scheme): the reliability of the lightweight auxiliary scheme for selecting effective prompt-specific parametrizations (tokens/layers/strength) for arbitrary composites is not validated in detail; without evidence that it avoids overfitting to evaluated cases or introducing artifacts on novel prompts, the generalization of the outperformance claim remains at risk.
Authors: The auxiliary decision scheme is validated through the extensive quantitative and qualitative evaluations on diverse composite prompts, including novel cases, presented in the paper. These results demonstrate consistent outperformance and motion quality without artifacts, supporting generalization. The Method section details the scheme's design for prompt-specific robustness. revision: no
Circularity Check
No significant circularity detected
full rationale
The paper frames MultiAct as an unpaired inference-time method operating externally on pretrained generators without retraining. The described mechanism (adaptive cross-attention amplification guided by a lightweight auxiliary decision scheme) and the performance claims rest on independent quantitative/qualitative evaluations rather than any self-definitional equations, fitted inputs renamed as predictions, or load-bearing self-citations. No uniqueness theorems, ansatzes, or renamings of known results are invoked in the provided text. The derivation chain is therefore self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Motionlcm: Real-time controllable motion generation via latent consistency 10•Sala et al. model. InEuropean Conference on Computer Vision. Springer, Springer International Publishing, Berlin/Heidelberg, Germany, 390–408. Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Langua...
-
[2]
InSIGGRAPH Asia 2024 Conference Papers
Consolidating attention features for multi-view image editing. InSIGGRAPH Asia 2024 Conference Papers. ACM, New York, NY, USA, 1–12. Or Patashnik, Daniel Garibi, Idan Azuri, Hadar Averbuch-Elor, and Daniel Cohen-Or
2024
-
[3]
In: 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW)
Localizing Object-Level Shape Variations with Text-to-Image Diffusion Models. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). Springer International Publishing, Berlin/Heidelberg, Germany, 23051–23061. Mathis Petrovich, Michael J. Black, and Gül Varol. 2021. Action-Conditioned 3D Human Motion Synthesis with Transformer VA...
-
[4]
Maskcontrol: Spatio-temporal control for masked motion synthesis. InProceed- ings of the IEEE/CVF International Conference on Computer Vision (ICCV). Springer International Publishing, Berlin/Heidelberg, Germany, 9955–9965. Ekkasit Pinyoanuntapong, Muhammad Usama Saleem, Pu Wang, Minwoo Lee, Srijan Das, and Chen Chen. 2024a. Bamm: Bidirectional autoregres...
-
[5]
Which motion is of higher quality? You may consider: - Does the motion look natural and appear like something a real person might do? - Does the motion look jittery or not smooth? - Does the character's contact with the ground look solid and correct? Motion A Much Better Motion A Slightly Better Similar Motion B Slightly Better Motion B Much Better
-
[6]
- Does it follow all of them? Motion A Much Better Motion A Slightly Better Similar Motion B Slightly Better Motion B Much Better
Which motion better reflects the text description? You may consider: - How accurately does each motion match the specific verbs used in the text description? Action details are semantic constraints, such as adverbs, direction and manner. - Does it follow all of them? Motion A Much Better Motion A Slightly Better Similar Motion B Slightly Better Motion B M...
-
[7]
12.A screenshot of our user study.Note that each human figure in the screenshot is played as a video
Overall, which motion do you prefer? - Which motion do you find more appealing? Motion A Same Motion B Video 1 of 14 Next Motion Pair → Fig. 12.A screenshot of our user study.Note that each human figure in the screenshot is played as a video
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.