Revisiting Zeroth-Order Hessian Approximation: A Single-Step Policy Optimization Lens
Pith reviewed 2026-06-28 23:29 UTC · model grok-4.3
The pith
Zeroth-order Hessian estimators equal the Hessian of a smoothed single-step policy optimization objective.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
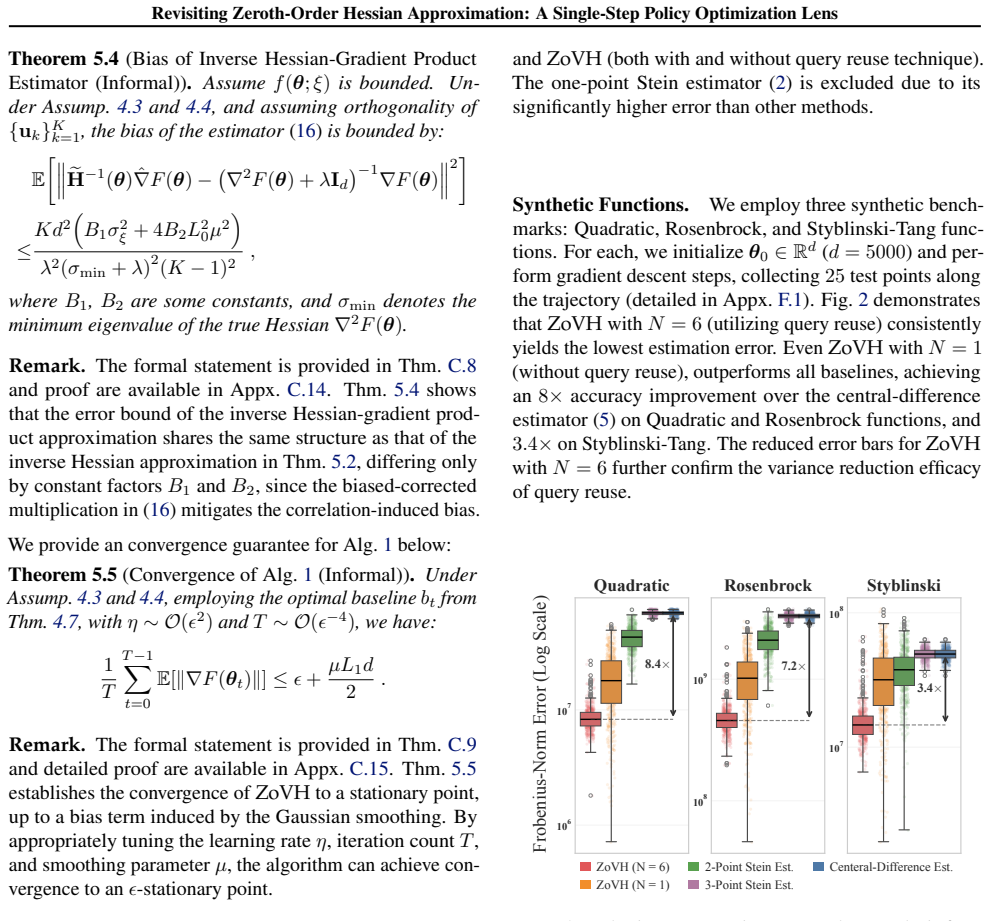
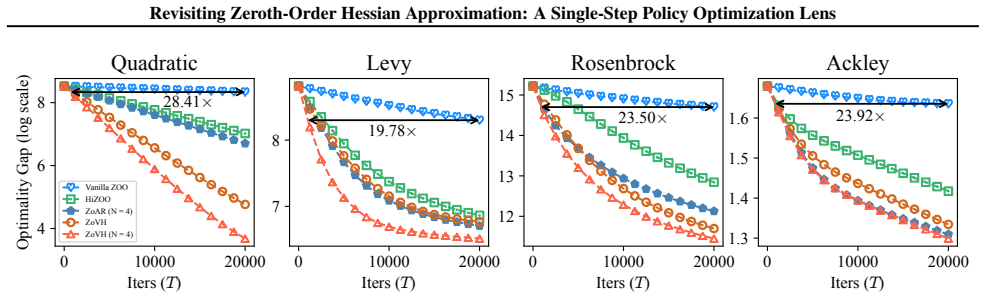
By viewing zeroth-order Hessian estimation through the lens of single-step policy optimization, the paper shows that general ZO Hessian estimators are exactly the Hessian of a smoothed PO objective, with distinct classical estimators arising as specific baseline choices. This unification directly yields the ZoVH estimators, which incorporate an optimal baseline that minimizes variance and a query-reuse mechanism that improves sample efficiency while preserving unbiasedness.
What carries the argument
Single-step policy optimization lens that equates general ZO Hessian estimators to the Hessian of a smoothed PO objective via baseline selection.
If this is right
- The ZoVH suite supplies unbiased estimators for the full Hessian matrix, its regularized inverse, and the bias-corrected inverse-Hessian-gradient product.
- An optimal baseline is derived that provably minimizes variance for the Hessian estimator.
- Query reuse incorporates past function evaluations to improve sample efficiency at no extra cost.
- Error bounds for the full ZoVH suite and convergence guarantees for the curvature-aware ZO algorithm follow from the analysis.
Where Pith is reading between the lines
- The baseline-selection unification could let variance-reduction methods developed for policy optimization transfer directly to other derivative-free curvature estimators.
- Query reuse may extend beyond Hessian estimation to first-order ZO gradients or higher-order terms without increasing query budget.
- In bilevel optimization settings the reduced-variance inverse-Hessian products could lower the total number of black-box evaluations needed for inner-loop solutions.
Load-bearing premise
A smoothed policy optimization objective can be defined whose Hessian exactly matches the general form of zeroth-order Hessian estimators.
What would settle it
Direct substitution of a classical randomized perturbation estimator into the smoothed PO objective to check whether its Hessian matches the estimator exactly.
Figures
read the original abstract
Accurate Zeroth-Order (ZO) Hessian estimation is a cornerstone of derivative-free methods, essential for tasks such as bilevel optimization, Bayesian inference, and uncertainty quantification. However, obtaining a complete suite of low-variance estimators for the Hessian and its inverse in high-dimensional settings remains a significant challenge. To address this, we propose a unified framework that reinterprets ZO Hessian approximation through the lens of single-step Policy Optimization (PO). This perspective establishes a theoretical equivalence between general ZO Hessian estimators and the Hessian of a smoothed PO objective, unifying distinct classical randomized estimators as specific instances of baseline selection. Building on this foundation, we introduce ZoVH, a comprehensive suite of variance-reduced estimators for the full Hessian matrix, its regularized inverse, and the bias-corrected inverse Hessian-gradient product. ZoVH leverages two key techniques: (1) a unique optimal baseline derived to provably minimize variance, and (2) a query reuse strategy that incorporates historical function queries to enhance sample efficiency without inflating costs. Our rigorous theoretical analysis confirms the unbiasedness of the Hessian estimator, validates the variance optimality of our baseline, provides error bounds for the entire ZoVH suite, and establishes convergence guarantees for the resulting curvature-aware ZO algorithm. Extensive empirical results validate our theoretical findings, demonstrating that ZoVH achieves superior estimation accuracy and convergence performance in real-world applications. Code is available at https://github.com/Qjbtiger/ZoVH
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that reinterpreting zeroth-order Hessian approximation through single-step policy optimization yields a theoretical equivalence between general ZO Hessian estimators and the Hessian of a smoothed PO objective. This unifies classical randomized estimators as instances of baseline selection. Building on the equivalence, the authors introduce the ZoVH suite of variance-reduced estimators for the full Hessian, its regularized inverse, and the bias-corrected inverse-Hessian-gradient product, employing an optimal baseline and query reuse. Theoretical analysis asserts unbiasedness of the Hessian estimator, variance optimality of the baseline, error bounds for the suite, and convergence guarantees for the resulting curvature-aware ZO algorithm, with empirical results supporting superior accuracy and performance.
Significance. If the equivalence and derivations hold without hidden restrictions, the work provides a unifying lens for ZO Hessian estimation that could systematically generate improved low-variance estimators, benefiting bilevel optimization, Bayesian inference, and uncertainty quantification. Code availability at the cited GitHub repository is a clear strength for reproducibility. The perspective is novel within the field but its impact hinges on verification of the load-bearing equivalence step.
major comments (2)
- [unified framework section] Unified framework (abstract and main derivation): the claim that the Hessian of the smoothed single-step PO objective exactly reproduces the general form of randomized ZO Hessian estimators requires an explicit, step-by-step derivation showing alignment of the perturbation expectation with the ZO formula without introducing bias terms or restricting the underlying function/policy class. This equivalence is the load-bearing step enabling unification and all subsequent ZoVH derivations.
- [theoretical analysis] Theoretical analysis section: the proofs of unbiasedness for the Hessian estimator and variance optimality of the derived baseline must be checked against the precise definitions of the estimators and the smoothing parameter to confirm they hold generally rather than only under specific parameterizations.
minor comments (1)
- [abstract] Abstract: the phrase 'query reuse strategy that incorporates historical function queries to enhance sample efficiency without inflating costs' would benefit from a brief parenthetical clarifying whether this reuses queries already counted in the ZO budget or requires additional evaluations.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential of the unifying perspective. We address each major comment below with clarifications drawn directly from the manuscript.
read point-by-point responses
-
Referee: [unified framework section] Unified framework (abstract and main derivation): the claim that the Hessian of the smoothed single-step PO objective exactly reproduces the general form of randomized ZO Hessian estimators requires an explicit, step-by-step derivation showing alignment of the perturbation expectation with the ZO formula without introducing bias terms or restricting the underlying function/policy class. This equivalence is the load-bearing step enabling unification and all subsequent ZoVH derivations.
Authors: Section 3 derives the Hessian of the smoothed single-step PO objective by computing the second derivative under the perturbation distribution and taking the expectation. This expectation aligns exactly with the general randomized ZO Hessian estimator form, with no additional bias terms introduced and without restricting the function class beyond standard twice-differentiability. The alignment is shown by matching the resulting expression term-by-term to the classical ZO formula. To increase explicitness, we will expand this derivation in the revision with numbered intermediate steps that isolate the perturbation expectation. revision: yes
-
Referee: [theoretical analysis] Theoretical analysis section: the proofs of unbiasedness for the Hessian estimator and variance optimality of the derived baseline must be checked against the precise definitions of the estimators and the smoothing parameter to confirm they hold generally rather than only under specific parameterizations.
Authors: Appendices A and B derive unbiasedness and variance optimality directly from the estimator definitions and the general smoothing parameter. Unbiasedness follows from linearity of expectation applied to the baseline-adjusted perturbation terms; variance optimality is obtained by solving the quadratic minimization over the baseline without further restrictions on the smoothing parameter. The proofs hold under the same general conditions stated in the main text. revision: no
Circularity Check
No significant circularity; equivalence is derived, not tautological
full rationale
The paper's central step reinterprets ZO Hessian estimators as the Hessian of a constructed smoothed single-step PO objective, unifying classical estimators via baseline choice. This is presented as a theoretical perspective with subsequent derivations of ZoVH estimators, variance bounds, and convergence results that do not reduce to self-fitted quantities or self-citation chains. No equations in the provided abstract or description equate a prediction directly to an input fit by construction, nor import uniqueness via overlapping-author citations. The framework remains self-contained against external benchmarks with independent analysis of unbiasedness and optimality.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A smoothed policy optimization objective exists whose Hessian is equivalent to general zeroth-order Hessian estimators
Reference graph
Works this paper leans on
- [1]
-
[2]
Zeroth-order optimization is secretly single-step policy optimization
Qiu, J., Xie, Z., Yan, X., Yang, Y ., and Shu, Y . Zeroth-order optimization is secretly single-step policy optimization. arxiv:2506.14460,
-
[3]
SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems
Association for Computational Linguistics. Wang, A., Pruksachatkun, Y ., Nangia, N., Singh, A., Michael, J., Hill, F., Levy, O., and Bowman, S. R. Su- perGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems. arxiv.1905.00537,
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[4]
OPT: Open Pre-trained Transformer Language Models
Zhang, S., Roller, S., Goyal, N., Artetxe, M., Chen, M., Chen, S., Dewan, C., Diab, M., Li, X., Lin, X. V ., Mi- haylov, T., Ott, M., Shleifer, S., Shuster, K., Simig, D., Koura, P. S., Sridhar, A., Wang, T., and Zettlemoyer, L. OPT: Open Pre-trained Transformer Language Models. arxiv.2205.01068,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
arXiv preprint arXiv:2406.16793 , year=
Zhang, Y ., Chen, C., Li, Z., Ding, T., Wu, C., Kingma, D. P., Ye, Y ., Luo, Z.-Q., and Sun, R. Adam-mini: Use fewer learning rates to gain more. arxiv:2406.16793,
-
[6]
11 Revisiting Zeroth-Order Hessian Approximation: A Single-Step Policy Optimization Lens A. Related Works Derivative-Free Hessian Approximation.Early efforts on derivative-free Hessian approximation date back to coordinate- wise perturbation schemes that form second-order updates by probing each coordinate direction, which typically requires on the order ...
1971
-
[7]
and in curvature-aware ZO fine-tuning of large language models (Zhao et al., 2025). Variance-Reduced Zeroth-Order Optimization.Zeroth-Order Optimization (ZOO) aims to minimize black-box objec- tives using only function evaluations, and has been extensively studied due to its broad applicability when derivatives are unavailable. A classical line of work co...
2025
-
[8]
Proof of Lem
(47) C.2. Proof of Lem. 3.1 Proof. We first derive the first derivative of the single-step policy optimization objective(7) by applying the Policy Gradient Thm. (Sutton et al., 1999): ∇Fµ(θ) =E x∼πθ(x) [∇lnπ θ(x)Eξ[f(x;ξ)]].(48) Taking the second derivative, we have: ∇2Fµ(θ) =∇ Z πθ(x)∇lnπ θ(x)Eξ[f(x;ξ)]dx (a) = Z ∇πθ(x)(∇lnπ θ(x))⊤ +π θ(x)∇2 lnπ θ(x) Eξ[...
1999
-
[9]
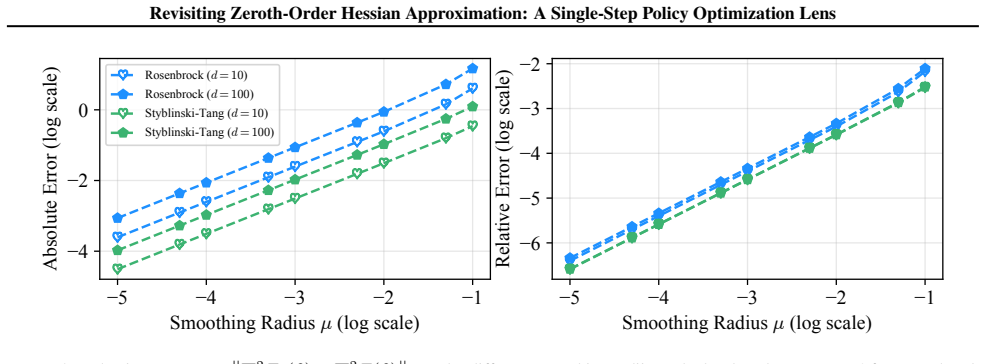
The log-log slopes are 1.04 for Rosenbrock and 1.01 for Styblinski-Tang
−5 −4 −3 −2 −1 Smoothing Radius ¹ (log scale) −6 −5 −4 −3 −2Relative Error (log scale) Figure 4.Frobenius norm error ∇2Fµ(θ)− ∇ 2F(θ) F under different smoothing radii µ. The log-log slopes are 1.04 for Rosenbrock and 1.01 for Styblinski-Tang. The errors are averaged over 3 independent runs. Since the standard deviations are small, we omit the error bars ...
2007
-
[10]
However, conventional ZO Hessian approximations often suffer from high variance, which can hamper convergence during fine-tuning
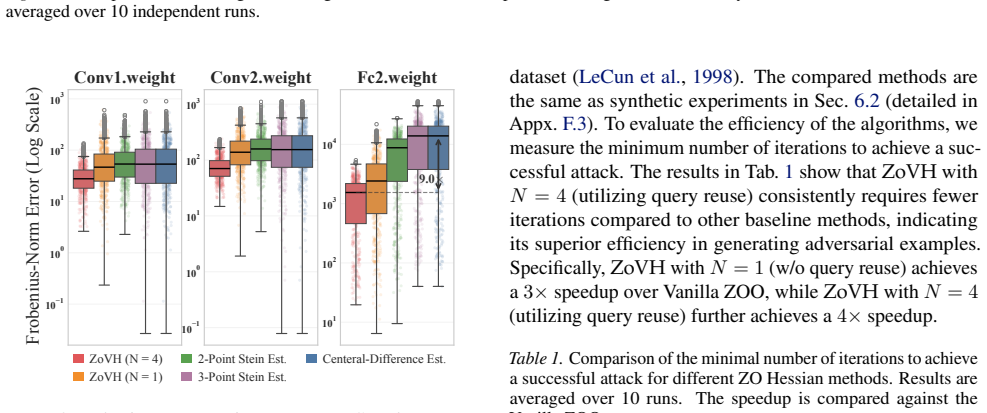
and curvature-aware techniques (Zhao et al., 2025). However, conventional ZO Hessian approximations often suffer from high variance, which can hamper convergence during fine-tuning. ZoVH addresses this limitation by reducing variance through a provably averaged baseline and the reuse of historical query information. In this section, we apply ZoVH to curva...
2025
-
[11]
All experiments are averaged over 5625 test points Hessian errors (3 independent runs with 1875test points collected along each optimization trajectory)
for digit classification. All experiments are averaged over 5625 test points Hessian errors (3 independent runs with 1875test points collected along each optimization trajectory). F.2. Synthetic Function Optimization Baselines.We compareZoVHwith several representative ZO optimization methods as baselines: •Vanilla ZOO (Nesterov & Spokoiny, 2017). This is ...
2017
-
[12]
When the scaling factor is set to1, HiZOO reduces to ZOHA
as a separate baseline because HiZOO already covers this case. When the scaling factor is set to1, HiZOO reduces to ZOHA. •ZoAR(Qiu et al., 2025). This is a variance-reduced ZO optimization method that incorporates averaged baseline and query reuse techniques to improve gradient estimation. Hyperparameter Settings.All experiments are conducted in d= 10000...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.