SwanVoice: Expressive Long-Form Zero-Shot Speech Synthesis for Both Monologue and Dialogue
Pith reviewed 2026-06-28 21:03 UTC · model grok-4.3
The pith
SwanVoice generates expressive long-form speech for both monologues and multi-speaker dialogues with higher richness and hierarchy than baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
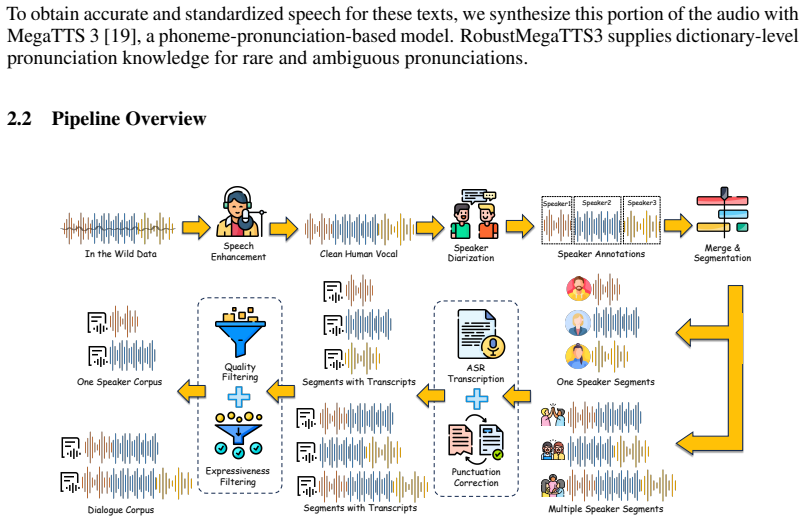
SwanVoice combines a 25 Hz VAE, raw-text conditioning that includes pause-aware symbols and pinyin substitution, and a flow-matching DiT equipped with speaker-turn conditioning. Training begins with monologue speech, advances through mixed and real dialogue data, and concludes with DiffusionNFT post-training that applies phone-level and speaker-similarity rewards. On the SwanBench-Speech benchmark this produces higher richness and hierarchy scores than all evaluated open-source baselines across both monologue and dialogue tasks.
What carries the argument
The flow-matching DiT with speaker-turn conditioning together with DiffusionNFT post-training rewards, which jointly support controllable speaker switching while preserving expressive coherence.
If this is right
- Multi-speaker dialogue can be synthesized in a single forward pass without separate turn generation and stitching.
- Acoustic consistency and affective continuity are maintained across speaker turns within the same model.
- The same architecture preserves monologue quality while extending to dialogue settings.
- Zero-shot inference works for variable numbers of speakers from one to four.
Where Pith is reading between the lines
- The pause-aware alignment and pinyin substitution steps in data preparation could be reused to improve other long-form TTS pipelines.
- If content accuracy improves, the model could serve as a drop-in component for generating consistent audio in multi-agent simulation environments.
- The staged training progression from monologue to dialogue data offers a template for adding conversational capabilities to existing single-speaker TTS systems.
Load-bearing premise
The SwanBench-Speech benchmark and its richness and hierarchy metrics accurately capture expressive coherence and affective continuity across speaker turns rather than reflecting artifacts from data construction or the reward signals.
What would settle it
An independent listening test in which listeners rate affective continuity and perceived richness on matched dialogue samples from SwanVoice and the strongest baseline, showing no statistically significant preference for SwanVoice, would undermine the central performance claim.
Figures

read the original abstract
Zero-shot text-to-speech (TTS) has improved substantially for single-speaker synthesis, yet expressive long-form multi-speaker dialogue remains difficult. A common workaround is to synthesize each turn with a monologue TTS model and stitch the outputs together. This adds inference cost and often breaks acoustic consistency, conversational coherence, and affective continuity across turns. Recent dialogue TTS systems have begun to address this setting, but they still struggle to keep expressive coherence, controllable speaker switching, and monologue quality at the same time. We present SwanData-Speech and SwanVoice. SwanData-Speech builds monologue and dialogue corpora from in-the-wild audio, using Swan Forced Aligner for pause-aware word-level alignment and RobustMegaTTS3 for pronunciation-hard cases. Built on these data, SwanVoice is a zero-shot TTS model for 1--4 speakers, combining a 25 Hz VAE, raw-text conditioning with pause-aware symbols and pinyin substitution, and a flow-matching DiT with speaker-turn conditioning. Training starts from monologue speech, moves through mixed and real dialogue data, and then uses DiffusionNFT post-training with phone-level and speaker-similarity rewards. On SwanBench-Speech, SwanVoice obtains higher richness and hierarchy scores than all evaluated open-source baselines in both monologue and dialogue settings, while content accuracy remains the main limitation. Audio demos are available at https://swanaigc.github.io//#swanvoice.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SwanData-Speech, a corpus of monologue and dialogue speech extracted from in-the-wild audio via Swan Forced Aligner and RobustMegaTTS3, and SwanVoice, a zero-shot TTS system for 1-4 speakers that combines a 25 Hz VAE, raw-text conditioning with pause symbols and pinyin, and a flow-matching DiT with speaker-turn conditioning. Training proceeds via a monologue-to-mixed-to-dialogue curriculum followed by DiffusionNFT post-training using phone-level and speaker-similarity rewards. The central empirical claim is that SwanVoice obtains higher richness and hierarchy scores than open-source baselines on the custom SwanBench-Speech benchmark in both monologue and dialogue settings, while content accuracy remains the primary limitation.
Significance. If the richness and hierarchy metrics validly capture expressive coherence and affective continuity across turns, the curriculum-plus-reward approach would constitute a concrete advance over stitching-based dialogue synthesis. The data-construction pipeline and speaker-turn conditioning are technically interesting strengths. However, the absence of disclosed validation for the benchmark and metrics substantially reduces the immediate significance of the reported gains.
major comments (3)
- [Evaluation / SwanBench-Speech] SwanBench-Speech section: No statement establishes that the benchmark is constructed from sources disjoint from SwanData-Speech, nor is any external validation or human correlation study provided for the richness and hierarchy metrics with respect to affective continuity or cross-turn coherence. This directly undermines the central superiority claim over baselines.
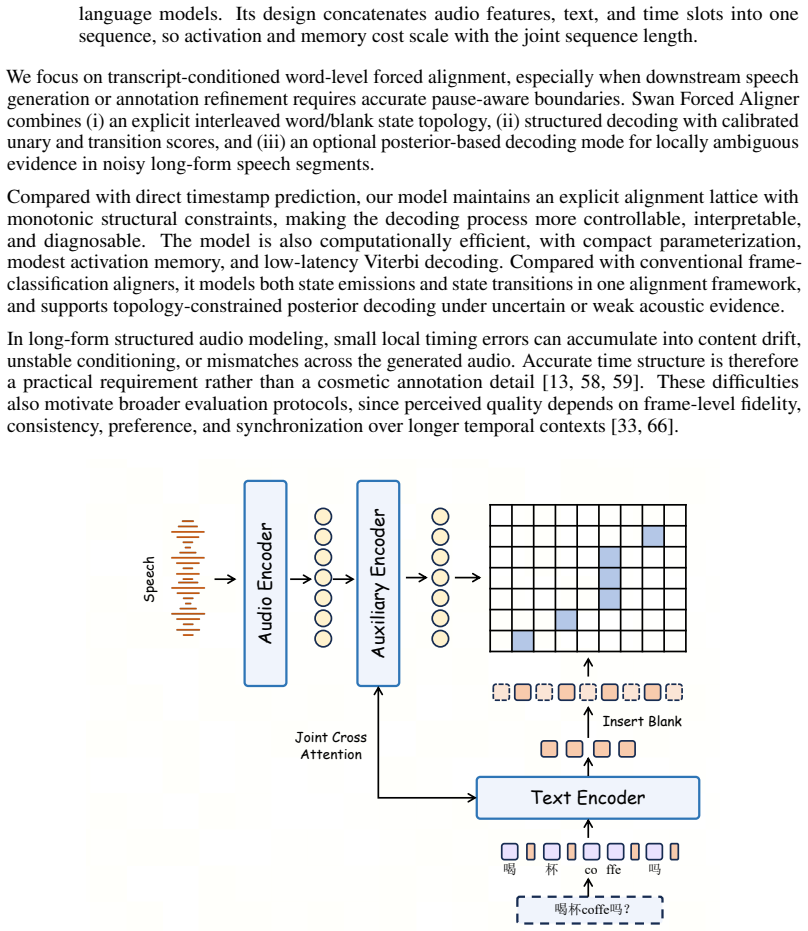
- [§3.3] §3.3 (DiffusionNFT post-training): The phone-level and speaker-similarity rewards are introduced, yet no ablation isolating their effect on dialogue richness/hierarchy scores versus the curriculum alone is reported, leaving the contribution of the post-training stage to the headline result unquantified.
- [Experiments] Experiments section: Content accuracy is identified as the main limitation, but no numerical values, comparison tables, or statistical tests are supplied for this metric, preventing assessment of whether the richness/hierarchy gains come at an acceptable cost to intelligibility.
minor comments (2)
- The audio demo link is provided but no accompanying human listening test protocol or inter-rater agreement statistics are described to corroborate the automatic metrics.
- [Model architecture] Notation for speaker-turn conditioning in the DiT is introduced without an explicit equation or diagram showing how turn embeddings are injected relative to the flow-matching objective.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and will make revisions to strengthen the presentation of the evaluation, ablations, and results.
read point-by-point responses
-
Referee: [Evaluation / SwanBench-Speech] SwanBench-Speech section: No statement establishes that the benchmark is constructed from sources disjoint from SwanData-Speech, nor is any external validation or human correlation study provided for the richness and hierarchy metrics with respect to affective continuity or cross-turn coherence. This directly undermines the central superiority claim over baselines.
Authors: We agree that an explicit statement on the construction of SwanBench-Speech is needed. The benchmark was built from sources held out from SwanData-Speech; we will add a clear description of the data sources and their separation in the revised section. For the metrics, we will expand the description of richness and hierarchy to better articulate their relation to affective continuity and cross-turn coherence. While no dedicated external human correlation study is reported, the metrics were designed with these aspects in mind based on internal validation; we will include additional details on their formulation to support the claims. revision: yes
-
Referee: [§3.3] §3.3 (DiffusionNFT post-training): The phone-level and speaker-similarity rewards are introduced, yet no ablation isolating their effect on dialogue richness/hierarchy scores versus the curriculum alone is reported, leaving the contribution of the post-training stage to the headline result unquantified.
Authors: The referee is correct that the contribution of the DiffusionNFT stage is not isolated via ablation. We will add an ablation study in the revised manuscript that compares results with and without the post-training stage on the dialogue richness and hierarchy metrics to quantify its effect beyond the curriculum. revision: yes
-
Referee: [Experiments] Experiments section: Content accuracy is identified as the main limitation, but no numerical values, comparison tables, or statistical tests are supplied for this metric, preventing assessment of whether the richness/hierarchy gains come at an acceptable cost to intelligibility.
Authors: We acknowledge the absence of specific numerical results for content accuracy. We will incorporate numerical values, baseline comparisons, and relevant tables or statistical details for this metric in the Experiments section of the revision to allow proper evaluation of any trade-offs. revision: yes
Circularity Check
No significant circularity; evaluation rests on external benchmark comparison without reduction to fitted parameters or self-citation chains.
full rationale
The paper describes construction of SwanData-Speech via aligner and prior TTS model, followed by curriculum training and DiffusionNFT post-training on a flow-matching DiT, then reports benchmark scores on SwanBench-Speech against open-source baselines. No equations, fitted parameters, or predictions are shown to reduce by construction to inputs (e.g., no self-definitional metrics or predictions forced by training fits). Self-citations, if present, are not load-bearing for the central claim, which remains an empirical comparison on author-defined data. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Deep speech 2: End-to-end speech recognition in english and mandarin
Amodei, D., Ananthanarayanan, S., Anubhai, R., Bai, J., Battenberg, E., Case, C., Casper, J., Catanzaro, B., Cheng, Q., Chen, G., et al. Deep speech 2: End-to-end speech recognition in english and mandarin. InInternational conference on machine learning, pp. 173–182. PMLR, 2016
2016
-
[2]
An, K., Chen, Q., Deng, C., Du, Z., Gao, C., Gao, Z., Gu, Y ., He, T., Hu, H., Hu, K., et al. Funaudiollm: V oice understanding and generation foundation models for natural interaction between humans and llms.arXiv preprint arXiv:2407.04051, 2024
-
[3]
Seed-TTS: A Family of High-Quality Versatile Speech Generation Models
Anastassiou, P., Chen, J., Chen, J., Chen, Y ., Chen, Z., Chen, Z., Cong, J., Deng, L., Ding, C., Gao, L., et al. Seed-tts: A family of high-quality versatile speech generation models.arXiv preprint arXiv:2406.02430, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Ultimate vocal remover
Anjok07 and aufr33. Ultimate vocal remover. https://github.com/Anjok07/ ultimatevocalremovergui, 2020
2020
-
[5]
Bain, M., Huh, J., Han, T., and Zisserman, A. Whisperx: Time-accurate speech transcription of long-form audio.arXiv preprint arXiv:2303.00747, 2023
-
[6]
Wavlm: Large-scale self-supervised pre-training for full stack speech processing
Chen, S., Wang, C., Chen, Z., Wu, Y ., Liu, S., Chen, Z., Li, J., Kanda, N., Yoshioka, T., Xiao, X., et al. Wavlm: Large-scale self-supervised pre-training for full stack speech processing. IEEE Journal of Selected Topics in Signal Processing, 16(6):1505–1518, 2022
2022
-
[7]
F5-TTS: A Fairytaler that Fakes Fluent and Faithful Speech with Flow Matching
Chen, Y ., Niu, Z., Ma, Z., Deng, K., Wang, C., Zhao, J., Yu, K., and Chen, X. F5-tts: A fairytaler that fakes fluent and faithful speech with flow matching.arXiv preprint arXiv:2410.06885, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
3d-speaker-toolkit: An open-source toolkit for multimodal speaker verification and diarization
Chen, Y ., Zheng, S., Wang, H., Cheng, L., Zhu, T., Huang, R., Deng, C., Chen, Q., Zhang, S., Wang, W., et al. 3d-speaker-toolkit: An open-source toolkit for multimodal speaker verification and diarization. InICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 1–5. IEEE, 2025
2025
-
[9]
Glm-tts technical report.arXiv preprint arXiv:2512.14291, 2025
Cui, J., Yang, Z., Li, N., Tian, J., Ma, X., Zhang, Y ., Chen, G., Yang, R., Cheng, Y ., Zhou, Y ., et al. Glm-tts technical report.arXiv preprint arXiv:2512.14291, 2025
-
[10]
CosyVoice 2: Scalable Streaming Speech Synthesis with Large Language Models
Du, Z., Wang, Y ., Chen, Q., Shi, X., Lv, X., Zhao, T., Gao, Z., Yang, Y ., Gao, C., Wang, H., et al. Cosyvoice 2: Scalable streaming speech synthesis with large language models.arXiv preprint arXiv:2412.10117, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
CosyVoice 3: Towards In-the-wild Speech Generation via Scaling-up and Post-training
Du, Z., Gao, C., Wang, Y ., Yu, F., Zhao, T., Wang, H., Lv, X., Wang, H., Ni, C., Shi, X., et al. Cosyvoice 3: Towards in-the-wild speech generation via scaling-up and post-training.arXiv preprint arXiv:2505.17589, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Guo, H.-H., Liu, K., Shen, F.-Y ., Wu, Y .-C., Xie, F.-L., Xie, K., and Xu, K.-T. Fireredtts: A foundation text-to-speech framework for industry-level generative speech applications.arXiv preprint arXiv:2409.03283, 2024
-
[13]
MRSAudio: A large-scale multimodal recorded spatial audio dataset with refined annotations
Guo, W., Pan, C., Zhu, Z., Hu, X., Zhang, Y ., Tang, L., Yang, R., Wang, H., Zhang, Z., Wang, Y ., Chen, Y ., Xu, H., Xu, K., Fan, P., Chen, Z., Yu, Y ., Huang, Q., Wu, F., and Zhao, Z. MRSAudio: A large-scale multimodal recorded spatial audio dataset with refined annotations. InAdvances in Neural Information Processing Systems, 2025
2025
-
[14]
Techsinger: Technique controllable multilingual singing voice synthesis via flow matching
Guo, W., Zhang, Y ., Pan, C., Huang, R., Tang, L., Li, R., Hong, Z., Wang, Y ., and Zhao, Z. Techsinger: Technique controllable multilingual singing voice synthesis via flow matching. arXiv preprint arXiv:2502.12572, 2025
-
[15]
STARS: A unified framework for singing transcription, alignment, and refined style annotation
Guo, W., Zhang, Y ., Pan, C., Zhu, Z., Li, R., Chen, Z., Xu, W., Wu, F., and Zhao, Z. STARS: A unified framework for singing transcription, alignment, and refined style annotation. InFindings of the Association for Computational Linguistics: ACL 2025, pp. 15081–15093, 2025
2025
-
[16]
Hu, K., Puvvada, K., Rastorgueva, E., Chen, Z., Huang, H., Ding, S., Dhawan, K., Xu, H., Balam, J., and Ginsburg, B. Word level timestamp generation for automatic speech recognition and translation.arXiv preprint arXiv:2505.15646, 2025. 11
-
[17]
Jang, W., Lim, D., Yoon, J., Kim, B., and Kim, J. Univnet: A neural vocoder with multi- resolution spectrogram discriminators for high-fidelity waveform generation.arXiv preprint arXiv:2106.07889, 2021
-
[18]
Wavtokenizer: an efficient acoustic discrete codec tokenizer for audio language modeling,
Ji, S., Jiang, Z., Wang, W., Chen, Y ., Fang, M., Zuo, J., Yang, Q., Cheng, X., Wang, Z., Li, R., et al. Wavtokenizer: an efficient acoustic discrete codec tokenizer for audio language modeling. arXiv preprint arXiv:2408.16532, 2024
-
[19]
Jiang, Z., Ren, Y ., Li, R., Ji, S., Zhang, B., Ye, Z., Zhang, C., Jionghao, B., Yang, X., Zuo, J., et al. Megatts 3: Sparse alignment enhanced latent diffusion transformer for zero-shot speech synthesis.arXiv preprint arXiv:2502.18924, 2025
-
[20]
Naturalspeech 3: Zero-shot speech synthesis with factorized codec and diffusion models
Ju, Z., Wang, Y ., Shen, K., Tan, X., Xin, D., Yang, D., Liu, E., Leng, Y ., Song, K., Tang, S., Wu, Z., Qin, T., Li, X., Ye, W., Zhang, S., Bian, J., He, L., Li, J., and sheng zhao. Naturalspeech 3: Zero-shot speech synthesis with factorized codec and diffusion models. InProc. International Conference on Machine Learning (ICML), 2024
2024
-
[21]
Mooncast: High-quality zero-shot podcast generation.arXiv preprint arXiv:2503.14345, 2025
Ju, Z., Yang, D., Yu, J., Shen, K., Leng, Y ., Wang, Z., Tan, X., Zhou, X., Qin, T., and Li, X. Mooncast: High-quality zero-shot podcast generation.arXiv preprint arXiv:2503.14345, 2025
-
[22]
Hifi-gan: Generative adversarial networks for efficient and high fidelity speech synthesis.Advances in neural information processing systems, 33:17022–17033, 2020
Kong, J., Kim, J., and Bae, J. Hifi-gan: Generative adversarial networks for efficient and high fidelity speech synthesis.Advances in neural information processing systems, 33:17022–17033, 2020
2020
-
[23]
Kumar, A., Tan, K., Ni, Z., Manocha, P., Zhang, X., Henderson, E., and Xu, B. Torchaudio- squim: Reference-less speech quality and intelligibility measures in torchaudio. InICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 1–5, 2023. doi: 10.1109/ICASSP49357.2023.10096680. URL https://doi.org/10. 110...
-
[24]
Robust singing voice transcrip- tion serves synthesis.arXiv preprint arXiv:2405.09940, 2024
Li, R., Zhang, Y ., Wang, Y ., Hong, Z., Huang, R., and Zhao, Z. Robust singing voice transcrip- tion serves synthesis.arXiv preprint arXiv:2405.09940, 2024
-
[25]
Indextts 2.5 technical report.arXiv preprint arXiv:2601.03888, 2026
Li, Y ., Zhou, X., Wang, J., Wang, L., Wu, Y ., Zhou, S., Zhou, Y ., and Shu, J. Indextts 2.5 technical report.arXiv preprint arXiv:2601.03888, 2026
-
[26]
Liao, S., Wang, Y ., Li, T., Cheng, Y ., Zhang, R., Zhou, R., and Xing, Y . Fish-speech: Leveraging large language models for advanced multilingual text-to-speech synthesis.arXiv preprint arXiv:2411.01156, 2024
-
[27]
Flow-GRPO: Training Flow Matching Models via Online RL
Liu, J., Liu, G., Liang, J., Li, Y ., Liu, J., Wang, X., Wan, P., Zhang, D., and Ouyang, W. Flow-grpo: Training flow matching models via online rl.arXiv preprint arXiv:2505.05470, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
emotion2vec: Self- supervised pre-training for speech emotion representation
Ma, Z., Zheng, Z., Ye, J., Li, J., Gao, Z., Zhang, S., and Chen, X. emotion2vec: Self- supervised pre-training for speech emotion representation. InFindings of the Association for Computational Linguistics: ACL 2024, pp. 15747–15760, Bangkok, Thailand, August 2024. Association for Computational Linguistics. doi: 10.18653/v1/2024.findings-acl.931. URL http...
-
[29]
Y ., Wang, Z., and Paul Smolley, S
Mao, X., Li, Q., Xie, H., Lau, R. Y ., Wang, Z., and Paul Smolley, S. Least squares generative adversarial networks. InProceedings of the IEEE International Conference on Computer Vision, pp. 2794–2802, 2017
2017
-
[30]
Montreal forced aligner: Trainable text-speech alignment using kaldi
McAuliffe, M., Socolof, M., Mihuc, S., Wagner, M., and Sonderegger, M. Montreal forced aligner: Trainable text-speech alignment using kaldi. InProc. Interspeech, volume 2017, pp. 498–502, 2017
2017
-
[31]
Minixhofer, C., Klejch, O., and Bell, P. Ttsds2: resources and benchmark for evaluating human-quality text to speech systems.arXiv preprint arXiv:2506.19441, 2025
-
[32]
Mu, B., Shi, X., Wang, X., Liu, H., Xu, J., and Xie, L. Llm-forcedaligner: A non-autoregressive and accurate llm-based forced aligner for multilingual and long-form speech.arXiv preprint arXiv:2601.18220, 2026. 12
-
[33]
Pan, C., Guo, W., Zhang, Y ., Zhu, Z., Chen, Z., Wang, H., and Zhao, Z. A multimodal evaluation framework for spatial audio playback systems: From localization to listener preference. In Proceedings of the 33rd ACM International Conference on Multimedia, pp. 7006–7015, 2025. doi: 10.1145/3746027.3755571
-
[34]
Comprehensive benchmarking of long-form speech generation in diverse scenarios, 2026
Pan, C., Yang, R., Wang, H., Zhou, Z., He, X., Guo, W., Jiang, Z., Li, R., Zhang, Y ., Wen, C., Lei, K., Yin, X., Lu, J., Zhu, Z., and Zhao, Z. Comprehensive benchmarking of long-form speech generation in diverse scenarios, 2026
2026
-
[35]
and Xie, S
Peebles, W. and Xie, S. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision, pp. 4195–4205, 2023
2023
-
[36]
Vibevoice technical report.arXiv preprint arXiv:2508.19205,
Peng, Z., Yu, J., Wang, W., Chang, Y ., Sun, Y ., Dong, L., Zhu, Y ., Xu, W., Bao, H., Wang, Z., Huang, S., Xia, Y ., and Wei, F. Vibevoice technical report.arXiv preprint arXiv:2508.19205,
-
[37]
Vibevoice technical report.arXiv preprint arXiv:2508.19205,
doi: 10.48550/arXiv.2508.19205. URLhttps://arxiv.org/abs/2508.19205
-
[38]
Nemo forced aligner and its application to word alignment for subtitle generation
Rastorgueva, E., Lavrukhin, V ., and Ginsburg, B. Nemo forced aligner and its application to word alignment for subtitle generation. InInterspeech, pp. 5257–5258, 2023
2023
-
[39]
Reddy, C. K. A., Gopal, V ., and Cutler, R. Dnsmos: A non-intrusive perceptual objective speech quality metric to evaluate noise suppressors. InICASSP 2021 - 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 6493–6497, 2021. doi: 10.1109/ICASSP39728.2021.9414878. URL https://doi.org/10.1109/ICASSP39728. 2021.9414878
-
[40]
Rix, A. W., Beerends, J. G., Hollier, M. P., and Hekstra, A. P. Perceptual evaluation of speech quality (pesq)-a new method for speech quality assessment of telephone networks and codecs. In2001 IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), volume 2, pp. 749–752, 2001. doi: 10.1109/ICASSP.2001.941023. URL https: //doi...
-
[41]
High-resolution image synthesis with latent diffusion models
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., and Ommer, B. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 10684–10695, 2022
2022
-
[42]
Achieving timestamp prediction while recognizing with non-autoregressive end-to-end asr model
Shi, X., Chen, Y ., Zhang, S., and Yan, Z. Achieving timestamp prediction while recognizing with non-autoregressive end-to-end asr model. InNational Conference on Man-Machine Speech Communication, pp. 89–100. Springer, 2022
2022
-
[43]
and Harwath, D
Strgar, L. and Harwath, D. Phoneme segmentation using self-supervised speech models. In 2022 IEEE Spoken Language Technology Workshop (SLT), pp. 1067–1073. IEEE, 2023
2022
-
[44]
Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers
Wang, C., Chen, S., Wu, Y ., Zhang, Z., Zhou, L., Liu, S., Chen, Z., Liu, Y ., Wang, H., Li, J., et al. Neural codec language models are zero-shot text to speech synthesizers.arXiv preprint arXiv:2301.02111, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[45]
Wang, H., Zheng, S., Chen, Y ., Cheng, L., and Chen, Q. Cam++: A fast and efficient network for speaker verification using context-aware masking.arXiv preprint arXiv:2303.00332, 2023
-
[46]
Spark-TTS: An Efficient LLM-Based Text-to-Speech Model with Single-Stream Decoupled Speech Tokens
Wang, X., Jiang, M., Ma, Z., Zhang, Z., Liu, S., Li, L., Liang, Z., Zheng, Q., Wang, R., Feng, X., et al. Spark-tts: An efficient llm-based text-to-speech model with single-stream decoupled speech tokens.arXiv preprint arXiv:2503.01710, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
Maskgct: Zero-shot text-to-speech with masked generative codec transformer,
Wang, Y ., Zhan, H., Liu, L., Zeng, R., Guo, H., Zheng, J., Zhang, Q., Zhang, X., Zhang, S., and Wu, Z. Maskgct: Zero-shot text-to-speech with masked generative codec transformer.arXiv preprint arXiv:2409.00750, 2024
-
[48]
Soulx-podcast: Towards realistic long-form podcasts with dialectal and paralinguistic diversity
Xie, H., Lin, H., Cao, W., Guo, D., Tian, W., Wu, J., Wen, H., Shang, R., Liu, H., Jiang, Z., et al. Soulx-podcast: Towards realistic long-form podcasts with dialectal and paralinguistic diversity. arXiv preprint arXiv:2510.23541, 2025
-
[49]
Xie, K., Shen, F., Li, J., Xie, F., Tang, X., and Hu, Y . Fireredtts-2: Towards long conversational speech generation for podcast and chatbot.arXiv preprint arXiv:2509.02020, 2025. 13
-
[50]
Xu, J., Guo, Z., Hu, H., Chu, Y ., Wang, X., He, J., Wang, Y ., Shi, X., He, T., Zhu, X., et al. Qwen3-omni technical report.arXiv preprint arXiv:2509.17765, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[51]
E., Fu, S.-W., Fuh, C.-S., Tsao, Y ., and Wang, H.-M
Zezario, R. E., Fu, S.-W., Fuh, C.-S., Tsao, Y ., and Wang, H.-M. Stoi-net: A deep learning based non-intrusive speech intelligibility assessment model. InAsia-Pacific Signal and Information Processing Association Annual Summit and Conference, APSIPA 2020, Auckland, New Zealand, December 7–10, 2020, pp. 482–486. IEEE, 2020. URL https://ieeexplore.ieee.org...
-
[52]
and Sennrich, R
Zhang, B. and Sennrich, R. Root mean square layer normalization.Advances in Neural Information Processing Systems, 32, 2019
2019
-
[53]
Zhang, X., Wang, C., Liao, H., Li, Z., Wang, Y ., Wang, L., Jia, D., Chen, Y ., Li, X., Chen, Z., et al. Speechjudge: Towards human-level judgment for speech naturalness.arXiv preprint arXiv:2511.07931, 2025
-
[54]
Stylesinger: Style transfer for out-of-domain singing voice synthesis
Zhang, Y ., Huang, R., Li, R., He, J., Xia, Y ., Chen, F., Duan, X., Huai, B., and Zhao, Z. Stylesinger: Style transfer for out-of-domain singing voice synthesis. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pp. 19597–19605, 2024
2024
-
[55]
Tcsinger: Zero- shot singing voice synthesis with style transfer and multi-level style control
Zhang, Y ., Jiang, Z., Li, R., Pan, C., He, J., Huang, R., Wang, C., and Zhao, Z. Tcsinger: Zero- shot singing voice synthesis with style transfer and multi-level style control. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pp. 1960–1975, 2024
2024
-
[56]
Gtsinger: A global multi-technique singing corpus with realistic music scores for all singing tasks.Advances in Neural Information Processing Systems (NeurIPS), 2024
Zhang, Y ., Pan, C., Guo, W., Li, R., Zhu, Z., Wang, J., Xu, W., Lu, J., Hong, Z., Wang, C., et al. Gtsinger: A global multi-technique singing corpus with realistic music scores for all singing tasks.Advances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[57]
TCSinger 2: Customizable multilingual zero-shot singing voice synthesis
Zhang, Y ., Guo, W., Pan, C., Yao, D., Zhu, Z., Jiang, Z., Wang, Y ., Jin, T., and Zhao, Z. TCSinger 2: Customizable multilingual zero-shot singing voice synthesis. In Che, W., Nabende, J., Shutova, E., and Pilehvar, M. T. (eds.),Proc. Annual Meeting of the Association for Compu- tational Linguistics (ACL), pp. 13280–13294, Vienna, Austria, 2025
2025
-
[58]
Zhang, Y ., Guo, W., Pan, C., Zhu, Z., Jin, T., and Zhao, Z. Isdrama: Immersive spatial drama generation through multimodal prompting.arXiv preprint arXiv:2504.20630, 2025
-
[59]
Versatile framework for song generation with prompt-based control
Zhang, Y ., Guo, W., Pan, C., Zhu, Z., Li, R., Lu, J., Huang, R., Zhang, R., Hong, Z., Jiang, Z., and Zhao, Z. Versatile framework for song generation with prompt-based control. InFindings of the Association for Computational Linguistics: EMNLP 2025, pp. 195–219, 2025
2025
-
[60]
Conan: A chunkwise online network for zero-shot adaptive voice conversion
Zhang, Y ., Tian, B., and Duan, Z. Conan: A chunkwise online network for zero-shot adaptive voice conversion. InProceedings of the IEEE Automatic Speech Recognition and Understanding Workshop, 2025
2025
-
[61]
Zhao, X., Xu, Z., Cheng, Q., Fei, Z., Jin, L., Wang, Y ., Chen, H., Jiang, Y ., Gao, Q., Chen, K., et al. Moss-speech: Towards true speech-to-speech models without text guidance.arXiv preprint arXiv:2510.00499, 2025
-
[62]
DiffusionNFT: Online Diffusion Reinforcement with Forward Process
Zheng, K., Chen, H., Ye, H., Wang, H., Zhang, Q., Jiang, K., Su, H., Ermon, S., Zhu, J., and Liu, M.-Y . Diffusionnft: Online diffusion reinforcement with forward process.arXiv preprint arXiv:2509.16117, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[63]
Zhou, S., Zhou, Y ., He, Y ., Zhou, X., Wang, J., Deng, W., and Shu, J. Indextts2: A breakthrough in emotionally expressive and duration-controlled auto-regressive zero-shot text-to-speech. arXiv preprint arXiv:2506.21619, 2025
-
[64]
ZipVoice-Dialog: Non-Autoregressive Spoken Dialogue Generation with Flow Matching
Zhu, H., Kang, W., Guo, L., Yao, Z., Kuang, F., Zhuang, W., Li, Z., Han, Z., Zhang, D., Zhang, X., et al. Zipvoice-dialog: Non-autoregressive spoken dialogue generation with flow matching. arXiv preprint arXiv:2507.09318, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[65]
Zhu, H., Kang, W., Yao, Z., Guo, L., Kuang, F., Li, Z., Zhuang, W., Lin, L., and Povey, D. Zipvoice: Fast and high-quality zero-shot text-to-speech with flow matching.arXiv preprint arXiv:2506.13053, 2025. 14
-
[66]
Phone-to-audio alignment without text: A semi-supervised approach
Zhu, J., Zhang, C., and Jurgens, D. Phone-to-audio alignment without text: A semi-supervised approach. InICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 8167–8171. IEEE, 2022
2022
-
[67]
ASAudio: A survey of advanced spatial audio research
Zhu, Z., Zhang, Y ., Guo, W., Pan, C., and Zhao, Z. ASAudio: A survey of advanced spatial audio research. InProceedings of the 14th International Joint Conference on Natural Lan- guage Processing and the 4th Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics, 2025. 15 Appendices SwanV oice: Expressive Long-Form Zero-Sh...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.