Physics-Informed Coarsening for Multigrid Graph Neural Surrogates
Pith reviewed 2026-06-28 23:14 UTC · model grok-4.3
The pith
A residual-based coarsening method in multigrid graph neural networks improves accuracy and long-term stability when modeling deformable solids.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
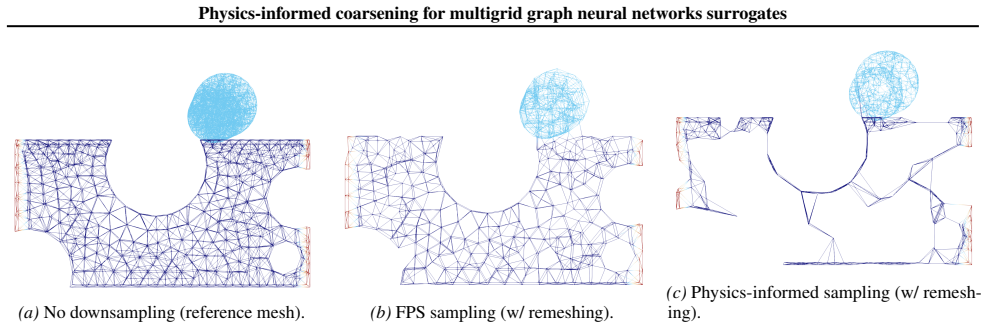
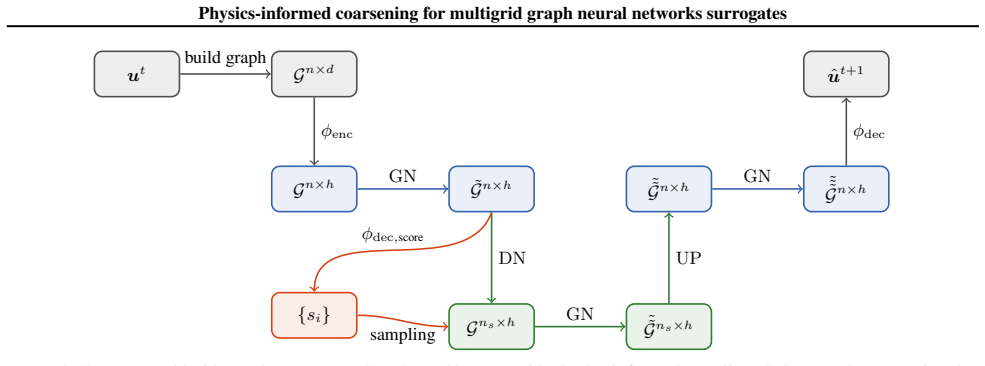
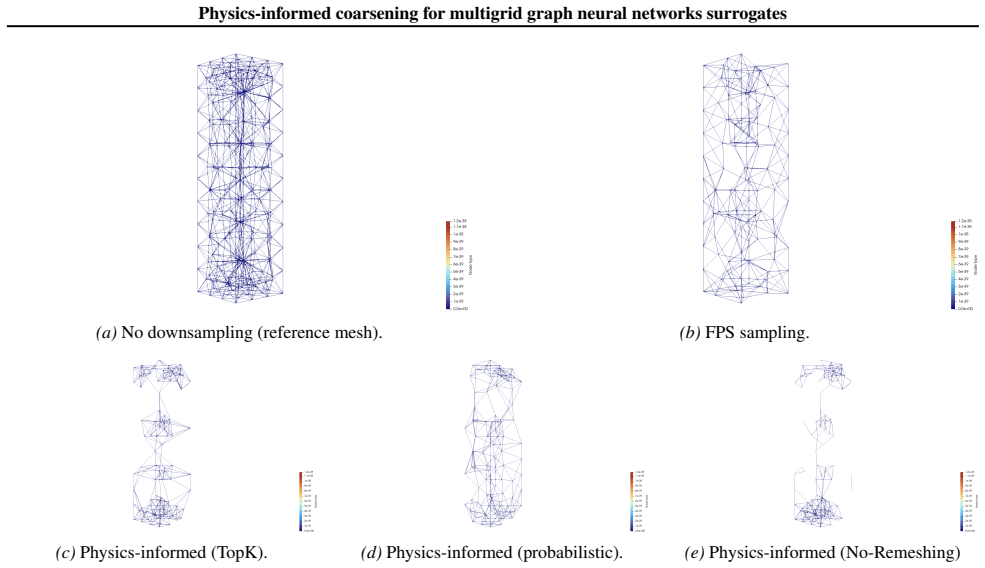
Coupling an encoder-processor-decoder backbone with physics-informed coarsening, which scores nodes by a residual-based measure of local physical activity and retains regions of high strain or stress concentration, preserves long-range interactions through hierarchical message passing and yields consistent gains in accuracy and rollout stability on datasets spanning linear, nonlinear, and transient solid-mechanics regimes.
What carries the argument
Physics-informed coarsening strategy that scores nodes using a residual-based measure of local physical activity to preferentially retain high strain or stress concentration regions.
If this is right
- Accuracy improves consistently across linear, nonlinear, and transient solid-mechanics datasets.
- Long rollouts remain stable because critical mechanical features are retained at multiple scales.
- Hierarchical message passing maintains long-range interactions even after coarsening.
- Computational capacity is allocated where local physical activity is highest rather than uniformly.
Where Pith is reading between the lines
- The same residual-driven retention rule could be tested on other physics domains where activity concentrates in small subregions.
- Combining the coarsening with adaptive time-stepping might further reduce error accumulation in long transients.
- The approach suggests that graph reduction for physics surrogates benefits from using the governing equations themselves rather than mesh geometry alone.
Load-bearing premise
Scoring nodes by residual-based local physical activity reliably identifies and prioritizes regions of high strain or stress concentration for retention.
What would settle it
A direct comparison on a test problem where residual peaks do not align with strain concentrations, showing that the physics-informed coarsened model loses accuracy or stability relative to a geometric coarsening baseline.
Figures

read the original abstract
Learning-based surrogates for partial differential equations have recently matched the accuracy of classical solvers while achieving orders-of-magnitude speedups, predominantly in fluid settings and structured geometries. In contrast, robust surrogates for deformable solids remain underexplored, despite the presence of nonlinear elasticity, plasticity, and transient behavior that challenge standard architectures. We introduce a multigrid graph neural network for solid mechanics that couples an encoder-processor-decoder backbone with a physics-informed coarsening strategy. Instead of downsampling via geometric heuristics, our method scores nodes using a residual-based measure of local physical activity and preferentially retains regions of high strain or stress concentration, allocating multiscale capacity where it is most needed. This preserves long-range interactions through hierarchical message passing while improving stability over long rollouts. We evaluate on multiple datasets covering linear, nonlinear, and transient regimes, and observe consistent gains in accuracy and rollout stability compared to standard sampling baselines. Our results highlight the importance of physics-informed coarsening for scalable surrogate modeling in solid mechanics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a multigrid graph neural network surrogate for solid mechanics problems that augments an encoder-processor-decoder architecture with a physics-informed coarsening operator. Nodes are scored by a residual-based measure of local physical activity; high-scoring nodes (intended to correspond to regions of high strain or stress concentration) are preferentially retained while lower-scoring nodes are coarsened. The resulting hierarchical message passing is claimed to preserve long-range interactions and yield improved rollout stability relative to geometric downsampling baselines. Experiments are reported on multiple datasets spanning linear elasticity, nonlinear elasticity, and transient regimes, with consistent gains in accuracy and stability.
Significance. If the residual-to-strain correspondence and the resulting stability gains are substantiated, the work would supply a concrete mechanism for allocating multiscale capacity in GNN surrogates for deformable solids, an area where geometric coarsening has been the default. The approach directly targets the mismatch between uniform graph sampling and the spatially localized nature of plasticity and stress concentrations, which could improve long-horizon prediction reliability in engineering applications.
major comments (2)
- [§3.2] §3.2 (Physics-Informed Coarsening): The central mechanism asserts that the residual-based node score reliably identifies and retains regions of high strain or stress concentration. No quantitative validation—such as Pearson correlation between the residual score and ground-truth von Mises stress or strain magnitude, or overlap metrics with high-strain subdomains—is provided. This correspondence is load-bearing for the claim that multiscale capacity is allocated where needed and for the reported stability advantage over geometric baselines.
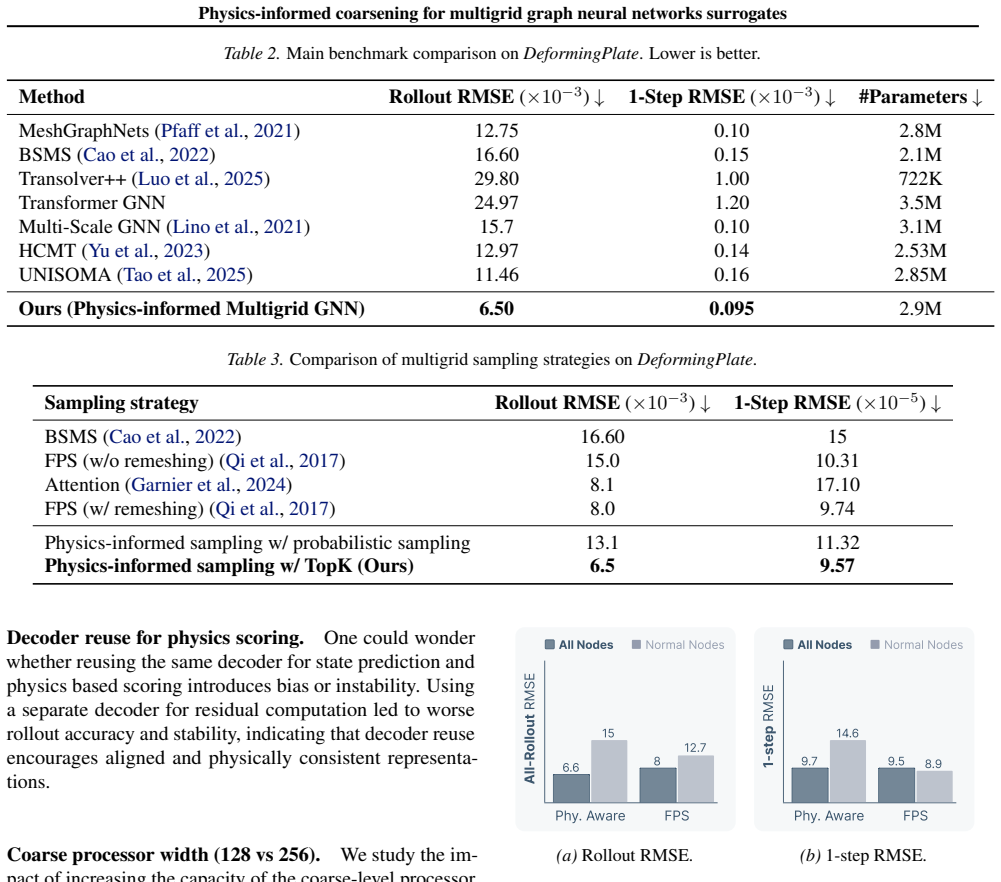
- [§4.3, Table 2] §4.3 and Table 2: The ablation that isolates the contribution of residual-based versus geometric coarsening reports only aggregate rollout error; it does not include a control that replaces the residual score with a random or uniform score while keeping the same hierarchy depth. Without this control, it remains unclear whether the observed gains derive from the physics-informed scoring or simply from any non-uniform hierarchical structure.
minor comments (2)
- [Eq. (7)] Notation for the residual score (Eq. 7) mixes node-wise and edge-wise quantities without an explicit definition of the aggregation operator; a one-line clarification would remove ambiguity.
- [Figure 4] Figure 4 caption states “error bars omitted for clarity” but the main text never reports whether variance across random seeds was measured; adding a brief statement on reproducibility would strengthen the experimental section.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Physics-Informed Coarsening): The central mechanism asserts that the residual-based node score reliably identifies and retains regions of high strain or stress concentration. No quantitative validation—such as Pearson correlation between the residual score and ground-truth von Mises stress or strain magnitude, or overlap metrics with high-strain subdomains—is provided. This correspondence is load-bearing for the claim that multiscale capacity is allocated where needed and for the reported stability advantage over geometric baselines.
Authors: We agree that direct quantitative validation of the residual-to-strain correspondence would strengthen the central claim. In the revised manuscript we will add Pearson correlation coefficients between the residual-based scores and ground-truth von Mises stress and strain magnitudes, together with overlap metrics against high-strain subdomains, computed on the held-out test sets for all regimes. These statistics will be reported in §3.2 and the associated supplementary figures. revision: yes
-
Referee: [§4.3, Table 2] §4.3 and Table 2: The ablation that isolates the contribution of residual-based versus geometric coarsening reports only aggregate rollout error; it does not include a control that replaces the residual score with a random or uniform score while keeping the same hierarchy depth. Without this control, it remains unclear whether the observed gains derive from the physics-informed scoring or simply from any non-uniform hierarchical structure.
Authors: We concur that a random-scoring control at fixed hierarchy depth would better isolate the contribution of the physics-informed component. In the revised manuscript we will augment the ablation study in §4.3 and Table 2 with an additional baseline that assigns node scores uniformly at random while preserving the same coarsening ratios and hierarchy depth; rollout error metrics for this control will be reported alongside the existing geometric and residual-based results. revision: yes
Circularity Check
No circularity: new coarsening strategy presented without self-referential reductions
full rationale
The paper introduces a multigrid GNN with a physics-informed coarsening strategy that scores nodes via residual-based local activity and retains high-strain regions. No equations, predictions, or first-principles derivations are supplied in the abstract or description that reduce by construction to fitted inputs, self-definitions, or self-citation chains. The central claim is a methodological proposal rather than a derived result forced by prior author work or renaming. The derivation chain is self-contained as an architectural choice.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Cao, Q., Goswami, S., and Karniadakis, G
doi: 10.2307/2006422. Cao, Q., Goswami, S., and Karniadakis, G. E. Laplace neural operator for solving differential equations.Nature Machine Intelligence, 6(6):631–640,
-
[2]
Efficient Learning of Mesh-Based Physical Simulation with BSMS-GNN
doi: 10.1038/s42256-024-00844-4. URL https: //doi.org/10.1038/s42256-024-00844-4. Cao, Y ., Chai, M., Li, M., and Jiang, C. Efficient learning of mesh-based physical simulation with bsms-gnn.arXiv preprint arXiv:2210.02573,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1038/s42256-024-00844-4
-
[3]
Chen, J., Viquerat, J., and Hachem, E. U-net architectures for fast prediction of incompressible laminar flows.arXiv preprint arXiv:1910.13532,
-
[4]
doi: 10.1017/jfm.2021.398. Cover, T. and Hart, P. Nearest neighbor pattern classification. IEEE transactions on information theory, 13(1):21–27,
-
[5]
Multiscale meshgraphnets.arXiv preprint arXiv:2210.00612,
Fortunato, M., Pfaff, T., Wirnsberger, P., Pritzel, A., and Battaglia, P. Multiscale meshgraphnets.arXiv preprint arXiv:2210.00612,
-
[6]
Garnier, P., Viquerat, J., and Hachem, E. Multi-grid graph neural networks with self-attention for computational mechanics.arXiv preprint arXiv:2409.11899,
-
[7]
Training transformers for mesh-based simulations.arXiv preprint arXiv:2508.18051,
Garnier, P., Lannelongue, V ., Viquerat, J., and Hachem, E. Training transformers for mesh-based simulations.arXiv preprint arXiv:2508.18051,
-
[8]
URL https://arxiv. org/abs/2303.15681. Han, X., Gao, H., Pfaff, T., Wang, J.-X., and Liu, L.-P. Predicting physics in mesh-reduced space with temporal attention.arXiv preprint arXiv:2201.09113,
-
[9]
Fourier Neural Operator for Parametric Partial Differential Equations
URL https://arxiv.org/ abs/2010.08895. Li, Z., Kovachki, N., Azizzadenesheli, K., Liu, B., Bhat- tacharya, K., Stuart, A., and Anandkumar, A. Fourier neural operator with learned deformations for pdes on general geometries.Journal of Machine Learning Re- search, 24(388):1–26,
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[10]
URL https://doi.org/ 10.1145/3623264.3624441
1145/3623264.3624441. URL https://doi.org/ 10.1145/3623264.3624441. Lin, F., Shi, J., Luo, S., Zhao, Q., Rao, W., and Chen, L. Up-sampling-only and adaptive mesh-based gnn for simulating physical systems,
-
[11]
Lino, M., Cantwell, C., Bharath, A
URL https:// arxiv.org/abs/2409.04740. Lino, M., Cantwell, C., Bharath, A. A., and Fotiadis, S. Simulating continuum mechanics with multi-scale graph neural networks.arXiv preprint arXiv:2106.04900,
-
[12]
URLhttps://arxiv.org/abs/2106.04900. Loshchilov, I. and Hutter, F. Decoupled weight decay reg- ularization. InInternational Conference on Learning Representations (ICLR),
-
[13]
Decoupled Weight Decay Regularization
URL https://arxiv. org/abs/1711.05101. 10 Physics-informed coarsening for multigrid graph neural networks surrogates Lucchetti, A., Cadini, F., Giglio, M., and Lomazzi, L. Graph network-based structural simulator: Graph neu- ral networks for structural dynamics.arXiv preprint arXiv:2510.25683,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Luo, H., Wu, H., Zhou, H., Xing, L., Di, Y ., Wang, J., and Long, M. Transolver++: An accurate neural solver for pdes on million-scale geometries.arXiv preprint arXiv:2502.02414,
-
[15]
doi: 10.48550/arXiv.2010. 03409. URL https://arxiv.org/abs/2010. 03409. arXiv preprint arXiv:2010.03409, v4,
-
[16]
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A
URL https://arxiv.org/abs/ 2506.06021. Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., and Polosukhin, I. Atten- tion is all you need. InAdvances in Neural Information Processing Systems (NeurIPS), volume 30,
-
[17]
Yu, Y .-Y ., Choi, J., Cho, W., Lee, K., Kim, N., Chang, K., Woo, C.-S., Kim, I., Lee, S.-W., Yang, J.-Y ., et al. Learning flexible body collision dynamics with hierarchical contact mesh transformer.arXiv preprint arXiv:2312.12467,
-
[18]
10 8 1282.98×10 −2 1.00×10 −5 For the additional HCMT and UNISOMA baselines, we followed the configurations reported in the original papers whenever possible. For HCMT (Yu et al., 2023), we used theDeformingPlatesetting with a total of L=L C +L H = 15 transformer blocks, split into LC = 10 contact mesh transformer blocks and LH = 5 hierarchical mesh trans...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.