SlotMemory: Object-Centric KV Memory for Streaming Long-Video Generation
Pith reviewed 2026-06-28 22:42 UTC · model grok-4.3
The pith
Decomposing the transformer's key-value manifold into discrete semantic slots enables entity-level persistence for streaming long-video generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By decomposing the transformer's key-value manifold into discrete, reusable semantic slots and utilizing these slots as routing addresses to index and store high-fidelity key-value tokens, SlotMemory enables entity-level persistence and prompt-aware retrieval across long horizons in streaming video diffusion, yielding state-of-the-art quality of 81.61 and a 22.8 percent relative improvement in dynamic consistency on 60-second interactive narratives.
What carries the argument
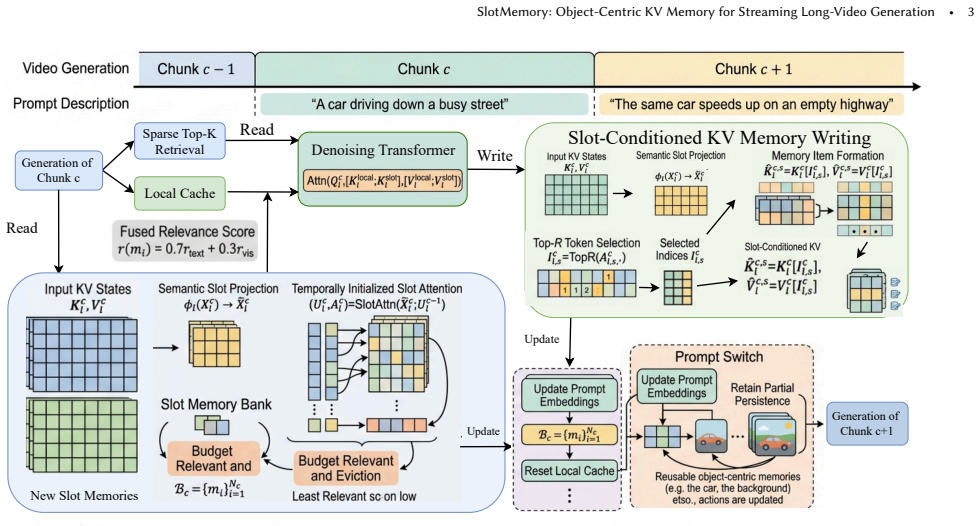
SlotMemory, the object-centric Key-Value memory mechanism that decomposes the transformer's key-value manifold into discrete reusable semantic slots used as routing addresses for token storage and retrieval.
If this is right
- Entity-level persistence holds across frames where objects exit and re-enter the scene.
- Prompt-aware retrieval occurs automatically during interactive prompt transitions without extra mechanisms.
- Dynamic consistency improves by 22.8 percent relative to the strongest existing streaming baseline.
- Overall quality reaches 81.61 on 60-second narratives using the Wan2.1-T2V-1.3B backbone.
- Structured semantic representation outperforms raw temporal capacity as the core requirement for long-form synthesis.
Where Pith is reading between the lines
- The slot decomposition may extend to other transformer-based generative tasks that require tracking distinct entities over time.
- If slots remain stable under varying diffusion noise schedules, the approach could reduce the need for explicit object tracking modules in video pipelines.
- Prompt transitions might become more reliable in multi-turn interactive settings because retrieval is indexed by semantic identity rather than recency.
Load-bearing premise
Decomposing the transformer's key-value manifold into discrete reusable semantic slots will produce entity-level persistence and prompt-aware retrieval without introducing new forms of inconsistency or requiring additional supervision.
What would settle it
If 60-second interactive video generations produced with SlotMemory still exhibit measurable identity drift or semantic inconsistency matching the levels of temporal-centric baselines, the claim that semantic slots suffice for entity-level persistence would be falsified.
Figures






read the original abstract
Streaming video generation models typically rely on temporal-centric memory, which organizes historical context as raw frames, chunk segments, or unclustered tokens. This organization frequently leads to identity drift and semantic inconsistency when entities exit the frame or during interactive prompt transitions. To address these limitations, we propose SlotMemory, an object-centric Key-Value memory mechanism for streaming video diffusion. Our approach shifts the memory abstraction from "when" an event occurred to "what" is being represented by decomposing the transformer's key-value manifold into discrete, reusable semantic slots. By utilizing these slots as routing addresses to index and store high-fidelity key-value tokens, we enable entity-level persistence and prompt-aware retrieval across long horizons. Evaluated on 60-second interactive narratives using the Wan2.1-T2V-1.3B backbone, SlotMemory achieves a state-of-the-art quality score of 81.61 and a 22.8 percent relative improvement in dynamic consistency over the strongest existing streaming baseline. Our results demonstrate that structured semantic representation, rather than raw temporal capacity, is the essential primitive for persistent long-form video synthesis. Our codes and checkpoints are available at https://tj12323.github.io/SlotMemory/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SlotMemory, an object-centric KV memory for streaming video diffusion models. It decomposes the transformer's key-value manifold into discrete reusable semantic slots to enable entity-level persistence and prompt-aware retrieval, addressing identity drift in long videos. Using the Wan2.1-T2V-1.3B backbone on 60-second interactive narratives, it reports a quality score of 81.61 and a 22.8% relative improvement in dynamic consistency over the strongest streaming baseline, concluding that structured semantic representation, rather than raw temporal capacity, is essential for persistent long-form video synthesis. Code and checkpoints are released.
Significance. If the quantitative claims hold under rigorous controls, the work provides evidence that shifting memory abstraction from temporal to semantic slots can improve consistency in streaming generation without extra supervision. The public release of code and checkpoints strengthens reproducibility and allows direct verification of the slot routing and storage mechanisms.
major comments (2)
- [Experiments] Experiments section: the reported 22.8% dynamic consistency gain and 81.61 quality score lack a complete description of the evaluation protocol, including exact metric definitions, baseline implementations, number of runs, and statistical significance testing. Without these, it is impossible to determine whether the gains arise from the slot decomposition itself or from unstated differences in capacity, auxiliary losses, or post-processing.
- [Method] Method section: the slot formation process, routing addresses, and training objective are described at a high level but do not specify whether slot assignment relies on any learned components beyond the base diffusion loss. This leaves open the possibility that the comparison to temporal-centric baselines is confounded by implicit supervision or capacity increases.
minor comments (1)
- [Abstract] The abstract states 'state-of-the-art quality score of 81.61' without naming the underlying metric or its range.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and commit to revisions that strengthen the manuscript's clarity and rigor.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the reported 22.8% dynamic consistency gain and 81.61 quality score lack a complete description of the evaluation protocol, including exact metric definitions, baseline implementations, number of runs, and statistical significance testing. Without these, it is impossible to determine whether the gains arise from the slot decomposition itself or from unstated differences in capacity, auxiliary losses, or post-processing.
Authors: We agree that the evaluation protocol requires fuller specification. In the revised manuscript we will expand the Experiments section with: (i) precise definitions and computation details for the quality score and dynamic consistency metric, (ii) exact baseline implementations including any capacity or auxiliary-loss matching, (iii) the number of independent runs (five), and (iv) statistical significance results (paired t-tests with p-values). These additions will confirm that reported gains derive from the slot decomposition rather than confounding factors. revision: yes
-
Referee: [Method] Method section: the slot formation process, routing addresses, and training objective are described at a high level but do not specify whether slot assignment relies on any learned components beyond the base diffusion loss. This leaves open the possibility that the comparison to temporal-centric baselines is confounded by implicit supervision or capacity increases.
Authors: Slot assignment and routing in SlotMemory emerge directly from the base diffusion loss and the transformer's attention mechanism; no auxiliary learned components or supervision are introduced. To remove ambiguity we will revise the Method section with explicit statements, additional equations, and pseudocode confirming that slot formation uses only the standard diffusion objective and that baseline comparisons control for capacity. This will demonstrate the absence of confounding factors. revision: yes
Circularity Check
No significant circularity detected
full rationale
The provided abstract and context describe a proposed architectural mechanism (object-centric KV slots for streaming video) and report empirical metrics on a backbone model, but contain no equations, fitted parameters presented as predictions, self-citations invoked as load-bearing uniqueness theorems, or ansatzes smuggled via prior work. No derivation chain is exhibited that reduces any claimed result to its inputs by construction. The central claim rests on the empirical evaluation rather than a self-referential definition or renamed known result.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
DIM-WAM: World-Action Modeling with Diverse Historical Event Memory
DiM-WAM is a memory-augmented world-action model that integrates multi-scale historical events and global task progress to improve long-horizon robot manipulation performance.
Reference graph
Works this paper leans on
-
[1]
InSIGGRAPH Asia 2024 Conference Papers
Lumiere: A space-time diffusion model for video generation. InSIGGRAPH Asia 2024 Conference Papers. 1–11. Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram Voleti, Adam Letts, et al
2024
-
[2]
Karan Dalal, Daniel Koceja, Jiarui Xu, Yue Zhao, Shihao Han, Ka Chun Cheung, Jan Kautz, Yejin Choi, Yu Sun, and Xiaolong Wang
Unsupervised 3D scene representation learning via movable object inference.Transactions on Machine Learning Research(2024). Karan Dalal, Daniel Koceja, Jiarui Xu, Yue Zhao, Shihao Han, Ka Chun Cheung, Jan Kautz, Yejin Choi, Yu Sun, and Xiaolong Wang
2024
-
[3]
Martin Engelcke, Adam R Kosiorek, Oiwi Parker Jones, and Ingmar Posner
Savi++: Towards end-to-end object- centric learning from real-world videos.Advances in Neural Information Processing Systems35 (2022), 28940–28954. Martin Engelcke, Adam R Kosiorek, Oiwi Parker Jones, and Ingmar Posner
2022
-
[4]
Long-Context Autoregressive Video Modeling with Next-Frame Prediction. arXiv:2503.19325 [cs.CV] https: //arxiv.org/abs/2503.19325 Yuwei Guo, Ceyuan Yang, Anyi Rao, Zhengyang Liang, Yaohui Wang, Yu Qiao, Maneesh Agrawala, Dahua Lin, and Bo Dai
-
[5]
InProceedings of the Computer Vision and Pattern Recognition Conference
Streamingt2v: Consistent, dynamic, and extendable long video generation from text. InProceedings of the Computer Vision and Pattern Recognition Conference. 2568–2577. Jonathan Ho, William Chan, Chitwan Saharia, Jay Whang, Ruiqi Gao, Alexey Gritsenko, Diederik P Kingma, Ben Poole, Mohammad Norouzi, David J Fleet, et al . 2022a. Imagen video: High definitio...
2022
-
[6]
Self forcing: Bridging the train-test gap in autoregressive video diffusion.Advances in Neural Information Processing Systems38 (2026), 167283–167308. Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, Yaohui Wang, Xinyuan Chen, Limin Wang, Dahua Lin, Yu Qiao, and Ziwei Liu
2026
-
[7]
VBench++: Comprehensive and Versatile Benchmark Suite for Video Generative Models.IEEE Transactions on Pattern Analysis and Machine Intelligence(2025). doi:10.1109/TPAM I.2025.3633890 Allan Jabri, Sjoerd van Steenkiste, Emiel Hoogeboom, Mehdi SM Sajjadi, and Thomas Kipf
-
[8]
Thomas Kipf, Gamaleldin F Elsayed, Aravindh Mahendran, Austin Stone, Sara Sabour, Georg Heigold, Rico Jonschkowski, Alexey Dosovitskiy, and Klaus Greff
Fifo-diffusion: Gen- erating infinite videos from text without training.Advances in Neural Information Processing Systems37 (2024), 89834–89868. Thomas Kipf, Gamaleldin F Elsayed, Aravindh Mahendran, Austin Stone, Sara Sabour, Georg Heigold, Rico Jonschkowski, Alexey Dosovitskiy, and Klaus Greff
2024
-
[9]
Avinash Kori, Francesco Locatello, Ainkaran Santhirasekaram, Francesca Toni, Ben Glocker, and Fabio De Sousa Ribeiro
42559–42603. Avinash Kori, Francesco Locatello, Ainkaran Santhirasekaram, Francesca Toni, Ben Glocker, and Fabio De Sousa Ribeiro. 2024b. Identifiable object-centric representation learning via probabilistic slot attention.Advances in Neural Information Processing Systems37 (2024), 93300–93335. Francesco Locatello, Dirk Weissenborn, Thomas Unterthiner, Ar...
2024
-
[10]
Riccardo Majellaro, Jonathan Collu, Aske Plaat, and Thomas M
Object- centric learning with slot attention.Advances in neural information processing systems33 (2020), 11525–11538. Riccardo Majellaro, Jonathan Collu, Aske Plaat, and Thomas M. Moerland
2020
-
[11]
https://openreview.net/forum?id=r8UFp9olQ0 Anna Manasyan, Maximilian Seitzer, Filip Radovic, Georg Martius, and Andrii Zada- ianchuk
Ex- plicitly Disentangled Representations in Object-Centric Learning.Transactions on Machine Learning Research(2025). https://openreview.net/forum?id=r8UFp9olQ0 Anna Manasyan, Maximilian Seitzer, Filip Radovic, Georg Martius, and Andrii Zada- ianchuk
2025
-
[12]
InternVideo: General Video Foundation Models via Generative and Discriminative Learning. arXiv:2212.03191 [cs.CV] https://arxiv.org/abs/2212.03191 Jay Zhangjie Wu, Yixiao Ge, Xintao Wang, Stan Weixian Lei, Yuchao Gu, Yufei Shi, Wynne Hsu, Ying Shan, Xiaohu Qie, and Mike Zheng Shou
-
[13]
InProceedings of the SIGGRAPH Asia 2025 Con- ference Papers
Context as memory: Scene-consistent interactive long video generation with memory retrieval. InProceedings of the SIGGRAPH Asia 2025 Con- ference Papers. 1–11. Lvmin Zhang, Shengqu Cai, Muyang Li, Gordon Wetzstein, and Maneesh Agrawala. 2025a. Frame Context Packing and Drift Prevention in Next-Frame-Prediction Video Diffusion Models. InThe Thirty-ninth An...
2025
-
[14]
10•Dou et al
4009–4028. 10•Dou et al. Fig. 6.Failure Cases of SlotMemory: Attribute Leakage and Scene Regression Artifacts. Fig. 7.Qualitative comparison on an interactive script. Fig. 8.More qualitative results on an interactive script. SlotMemory: Object-Centric KV Memory for Streaming Long-Video Generation•11 A Additional Implementation Details A.1 Training Recipe ...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.