Fighting Numerical Hallucinations via Data-centric Compilation for Online Financial QA
Pith reviewed 2026-06-28 21:10 UTC · model grok-4.3
The pith
A data-centric compilation framework combats numerical hallucinations in financial QA by synthesizing adversarial data and compiling queries into verifiable executable programs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
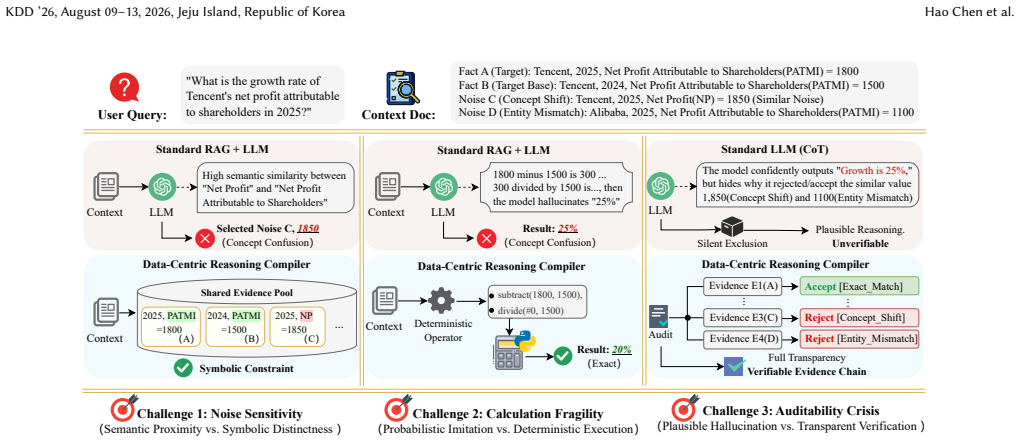
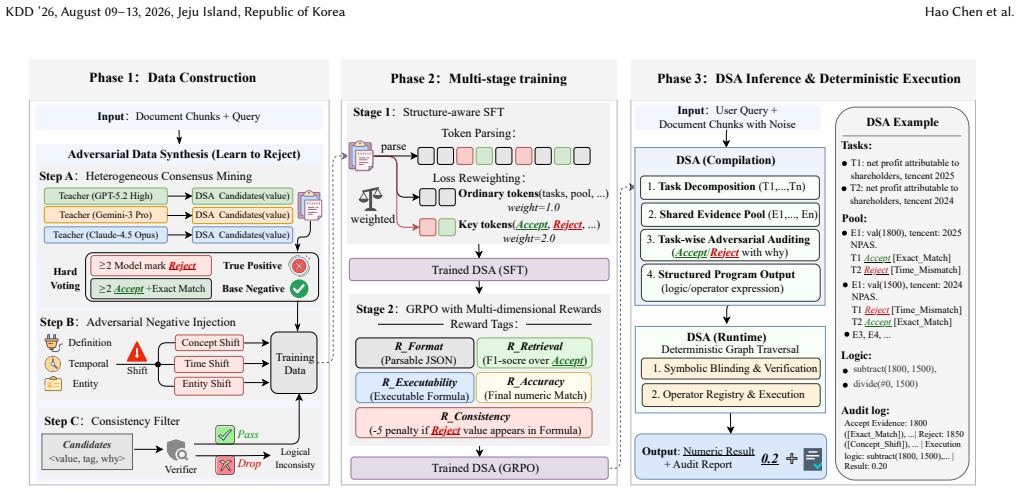
The Data-centric Reasoning Compiler (DCRC) works through adversarial data construction that injects controlled noise, multi-stage training of a Data-centric Structuring Agent capable of explicit evidence auditing and program synthesis, and a compile-and-execute inference step that converts user queries plus retrieved documents into verifiable reasoning programs, thereby ensuring faithful numerical reasoning by design.
What carries the argument
The Data-centric Structuring Agent (DSA) that performs explicit evidence auditing and synthesizes executable reasoning programs from queries and documents.
If this is right
- Training on adversarial data with controlled noise reduces sensitivity to retrieval errors.
- Converting reasoning into executable programs overcomes calculation fragility in LLMs.
- Explicit program synthesis provides an auditable trace that addresses the auditability crisis.
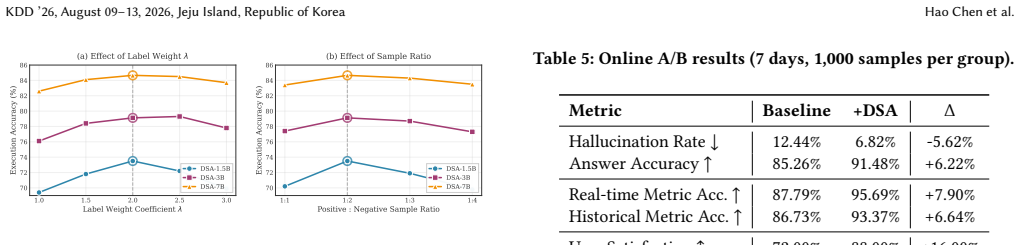
- The same pipeline shows gains on offline benchmarks and in a live online financial QA deployment.
Where Pith is reading between the lines
- The same data-synthesis-plus-compilation pattern could be tested on non-financial domains that require precise numerical or logical steps.
- Success would imply that robustness gains can come from curated training distributions rather than solely from larger generator models.
- One could measure whether the DSA's program synthesis scales to queries needing more than two or three arithmetic operations.
Load-bearing premise
The synthesized adversarial examples and the trained DSA will generalize to real user queries and retrieved documents while always producing correct executable programs.
What would settle it
A deployed query where the DSA outputs an executable program that yields an incorrect numerical result despite the retrieved documents containing the correct supporting figures.
Figures

read the original abstract
Large Language Models (LLMs) have significantly advanced online data services, particularly in the domain of financial question answering (FinQA). However, such systems remain susceptible to numerical reasoning hallucinations, which critically undermine reliability in high-stakes financial applications. Although retrieval-augmented generation (RAG) has been widely adopted to ground responses in external knowledge, it introduces three persistent challenges: noise sensitivity, calculation fragility, and an auditability crisis. Existing model-centric approaches, which primarily focus on optimizing either the retriever or generator in isolation, still struggle to address these issues in an integrated manner. In this work, we pioneer a data-centric paradigm and propose a novel framework, the Data-centric Reasoning Compiler (DCRC). The framework operates through three cohesive phases: (1) adversarial data construction, which synthesizes training examples with controlled noise to teach robustness; (2) multi-stage training that cultivates a Data-centric Structuring Agent (DSA) capable of explicit evidence auditing and program synthesis; and (3) a compile-and-execute inference process, where the DSA transforms user queries and retrieved documents into verifiable, executable reasoning programs. This data-driven framework ensures faithful numerical reasoning by design. We conduct extensive experiments on established offline benchmarks and further validate our framework through deployment in a real-world online financial QA system.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents the Data-centric Reasoning Compiler (DCRC), a data-centric framework designed to mitigate numerical hallucinations in LLMs for financial question answering. The framework is built around three phases: (1) adversarial data construction that synthesizes examples with controlled noise to promote robustness, (2) multi-stage training of a Data-centric Structuring Agent (DSA) that performs explicit evidence auditing and synthesizes executable programs, and (3) a compile-and-execute inference process that converts user queries and retrieved documents into verifiable reasoning programs. The authors assert that this approach ensures faithful numerical reasoning by design and provide validation through experiments on established offline benchmarks as well as a real-world online financial QA system deployment.
Significance. If the results hold, the significance is high as it offers an integrated solution to the challenges of noise sensitivity, calculation fragility, and auditability in RAG-based systems for high-stakes domains. The data-centric paradigm, with its emphasis on synthesized adversarial data and program synthesis, provides a structured alternative to model-centric optimizations. The real-world deployment directly tests the generalization of the DSA, addressing the primary empirical risk in the approach.
minor comments (3)
- [Abstract] The abstract would be strengthened by including specific performance metrics or improvements from the experiments to better support the claims of effectiveness.
- Ensure all acronyms (e.g., RAG, FinQA, DSA, DCRC) are defined at first use in the main text.
- [Method] The multi-stage training process for the DSA could benefit from a diagram or pseudocode to clarify the stages and their objectives.
Simulated Author's Rebuttal
We thank the referee for the positive summary, high significance assessment, and recommendation of minor revision. We are pleased that the data-centric approach and real-world deployment are viewed favorably.
Circularity Check
No significant circularity detected
full rationale
The paper describes a three-phase data-centric framework (adversarial synthesis, DSA training, compile-and-execute) whose central claim of ensuring faithful reasoning 'by design' follows directly from the explicit construction steps without any equations, fitted parameters renamed as predictions, or load-bearing self-citations. No derivation chain reduces to its own inputs; the approach is presented as an empirical pipeline validated on benchmarks and deployment, making it self-contained against the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Floren- cia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. 2023. Gpt-4 technical report.arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Mubashara Akhtar, Abhilash Shankarampeta, Vivek Gupta, Arpit Patil, Oana Cocarascu, and Elena Simperl. 2023. Exploring the Numerical Reasoning Capabili- ties of Language Models: A Comprehensive Analysis on Tabular Data. InFindings of the Association for Computational Linguistics: EMNLP 2023. 15391–15405
2023
-
[3]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. 2023. Qwen technical report.arXiv preprint arXiv:2309.16609(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Wenhu Chen, Xueguang Ma, Xinyi Wang, and William W. Cohen. 2023. Program of Thoughts Prompting: Disentangling Computation from Reasoning for Numer- ical Reasoning Tasks. arXiv:2211.12588 [cs.CL] https://arxiv.org/abs/2211.12588
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Zhiyu Chen, Wenhu Chen, Charese Smiley, Sameena Shah, Iana Borova, Dylan Langdon, Reema Moussa, Matt Beane, Ting-Hao Huang, Bryan R Routledge, et al
-
[6]
InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing
Finqa: A dataset of numerical reasoning over financial data. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 3697–3711
2021
-
[7]
Zhiyu Chen, Shiyang Li, Charese Smiley, Zhiqiang Ma, Sameena Shah, and William Yang Wang. 2022. ConvFinQA: Exploring the Chain of Numerical Reasoning in Conversational Finance Question Answering. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 6279– 6292
2022
-
[8]
Sorouralsadat Fatemi and Yuheng Hu. 2024. Enhancing Financial Question Answering with a Multi-Agent Reflection Framework. InProceedings of the 5th ACM International Conference on AI in Finance(Brooklyn, NY, USA)(ICAIF ’24). Association for Computing Machinery, 530–537
2024
-
[9]
Boda Feng, Hui Gao, Peng Zhang, and Jing Zhang. 2024. CBR-Ren: A Case-Based Reasoning Driven Retriever-Generator Model for&Hybrid Long-Form Numerical Reasoning. Springer-Verlag, Berlin, Heidelberg, 111–126. doi:10.1007/978-3-031- 63646-2_8
-
[10]
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yixin Dai, Jiawei Sun, Haofen Wang, and Haofen Wang. 2023. Retrieval-augmented generation for large language models: A survey.arXiv preprint arXiv:2312.10997 2, 1 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al . 2025. DeepSeek-R1 in- centivizes reasoning in LLMs through reinforcement learning.Nature645, 8081 (2025), 633–638
2025
- [12]
-
[13]
Subhendu Khatuya, Shashwat Naidu, Pawan Goyal, and Niloy Ganguly. 2025. Program of Thoughts for Financial Reasoning: Leveraging Dynamic In-Context Examples and Generative Retrieval. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. Suzhou, China, 31006–31018
2025
-
[14]
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. 2022. Large language models are zero-shot reasoners.Advances in neural information processing systems35 (2022), 22199–22213
2022
-
[15]
Hanyu Lai, Xiao Liu, Hao Yu, Yifan Xu, Iat Long Iong, Shuntian Yao, Aohan Zeng, Zhengxiao Du, Yuxiao Dong, and Jie Tang. 2025. WebGLM: Towards an Efficient and Reliable Web-Enhanced Question-Answering System.ACM Trans. Inf. Syst. 43, 5, Article 122 (July 2025), 43 pages
2025
-
[16]
Haoyang Li, Xuejia Chen, Zhanchao Xu, Darian Li, Nicole Hu, Fei Teng, Yiming Li, Luyu Qiu, Chen Jason Zhang, Li Qing, and Lei Chen. 2025. Exposing Numer- acy Gaps: A Benchmark to Evaluate Fundamental Numerical Abilities in Large Language Models. InFindings of the Association for Computational Linguistics: ACL 2025. 20004–20026
2025
-
[17]
Xin Lin, Zhenya Huang, Zhiqiang Zhang, Jun Zhou, and Enhong Chen. 2025. Ex- plore What LLM Does Not Know in Complex Question Answering. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 24585–24594
2025
-
[18]
Langming Liu, Shilei Liu, Yujin Yuan, Yizhen Zhang, Bencheng Yan, Zhiyuan Zeng, Zihao Wang, Jiaqi Liu, Di Wang, Wenbo Su, et al. 2025. UQABench: Evalu- ating User Embedding for Prompting LLMs in Personalized Question Answering. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2. 5652–5661
2025
- [19]
-
[20]
Cheng Niu, Yuanhao Wu, Juno Zhu, Siliang Xu, KaShun Shum, Randy Zhong, Juntong Song, and Tong Zhang. 2024. RAGTruth: A Hallucination Corpus for De- veloping Trustworthy Retrieval-Augmented Language Models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 10862–10878
2024
-
[21]
Karmvir Singh Phogat, Chetan Harsha, Sridhar Dasaratha, Shashishekar Ra- makrishna, and Sai Akhil Puranam. 2023. Zero-Shot Question Answering over Financial Documents using Large Language Models.CoRRabs/2311.14722 (2023). https://doi.org/10.48550/arXiv.2311.14722
-
[22]
Karmvir Singh Phogat, Sai Akhil Puranam, Sridhar Dasaratha, Chetan Harsha, and Shashishekar Ramakrishna. 2024. Fine-tuning Smaller Language Models for Question Answering over Financial Documents. InFindings of the Association for Computational Linguistics: EMNLP 2024, Miami, Florida, USA, November 12-16,
2024
-
[23]
Association for Computational Linguistics, 10528–10548
-
[24]
Aske Plaat, Annie Wong, Suzan Verberne, Joost Broekens, Niki Van Stein, and Thomas Bäck. 2025. Multi-Step Reasoning with Large Language Models, a Survey. ACM Comput. Surv.58, 6, Article 160 (Dec. 2025), 35 pages
2025
-
[25]
Jiashuo Sun, Hang Zhang, Chen Lin, Xiangdong Su, Yeyun Gong, and Jian Guo
-
[26]
APOLLO: An Optimized Training Approach for Long-form Numerical Rea- soning. InProceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), Nicoletta Calzolari, Min-Yen Kan, Veronique Hoste, Alessandro Lenci, Sakriani Sakti, and Nianwen Xue (Eds.). 1370–1382
2024
-
[27]
Xing Tang, Hao Chen, Shiwei Li, Fuyuan Lyu, Weijie Shi, Lingjie Li, Dugang Liu, Weihong Luo, Xiku Du, and Xiuqiang He. 2026. Data-Driven Function Calling Improvements in Large Language Model for Online Financial QA. InProceedings of the ACM Web Conference 2026 (WWW ’26). Association for Computing Machinery, 7821–7832
2026
-
[28]
Zichen Tang, Haihong E, Ziyan Ma, Haoyang He, Jiacheng Liu, Zhongjun Yang, Zihua Rong, Rongjin Li, Kun Ji, Qing Huang, Xinyang Hu, Yang Liu, and Qianhe Zheng. 2025. FinanceReasoning: Benchmarking Financial Numerical Reasoning More Credible, Comprehensive and Challenging. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguis...
2025
-
[29]
Zichen Tang, Jiacheng Liu, Zhongjun Yang, Rongjin Li, Zihua Rong, Haoyang He, Zhuodi Hao, Xinyang Hu, Kun Ji, Ziyan Ma, et al . 2025. Finmmr: make financial numerical reasoning more multimodal, comprehensive, and challenging. InProceedings of the IEEE/CVF International Conference on Computer Vision. 3245– 3257
2025
-
[30]
Kimi Team, Angang Du, Bofei Gao, Bowei Xing, Changjiu Jiang, Cheng Chen, Cheng Li, Chenjun Xiao, Chenzhuang Du, Chonghua Liao, et al. 2025. Kimi k1. 5: Scaling reinforcement learning with llms.arXiv preprint arXiv:2501.12599(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Dingzirui Wang, Longxu Dou, Xuanliang Zhang, Qingfu Zhu, and Wanxiang Che. 2024. Enhancing Numerical Reasoning with the Guidance of Reliable Reasoning Processes. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 10812–10828
2024
-
[32]
Chi, Quoc V
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, and Denny Zhou. 2022. Chain-of-thought prompting elicits reasoning in large language models. InProceedings of the 36th International Conference on Neural Information Processing Systems. Article 1800, 14 pages
2022
-
[33]
Qianqian Xie, Weiguang Han, Zhengyu Chen, Ruoyu Xiang, Xiao Zhang, Yueru He, Mengxi Xiao, Dong Li, Yongfu Dai, Duanyu Feng, et al . 2024. Finben: A holistic financial benchmark for large language models.Advances in Neural Information Processing Systems37 (2024), 95716–95743
2024
- [34]
-
[35]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. 2025. Qwen3 technical report.arXiv preprint arXiv:2505.09388(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [36]
-
[37]
2025.FAITH: A Framework for Assessing Intrinsic Tabular Hallucinations in Finance
Mengao Zhang, Jiayu Fu, Tanya Warrier, Yuwen Wang, Tianhui Tan, and Ke-wei Huang. 2025.FAITH: A Framework for Assessing Intrinsic Tabular Hallucinations in Finance. 159–167
2025
-
[38]
tasks": {
Fengbin Zhu, Wenqiang Lei, Youcheng Huang, Chao Wang, Shuo Zhang, Jiancheng Lv, Fuli Feng, and Tat-Seng Chua. 2021. TAT-QA: A Question Answer- ing Benchmark on a Hybrid of Tabular and Textual Content in Finance. InACL. Association for Computational Linguistics. KDD ’26, August 09–13, 2026, Jeju Island, Republic of Korea Hao Chen et al. A Prompt used in Me...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.