HQ-JEPA: Hybrid Quantum Joint-Embedding Predictive Architecture for Cross-Modal Remote Sensing Representation Learning
Pith reviewed 2026-06-28 23:17 UTC · model grok-4.3
The pith
HQ-JEPA adds a quantum fidelity loss to JEPA-style masked prediction to align features from paired Sentinel radar and optical images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
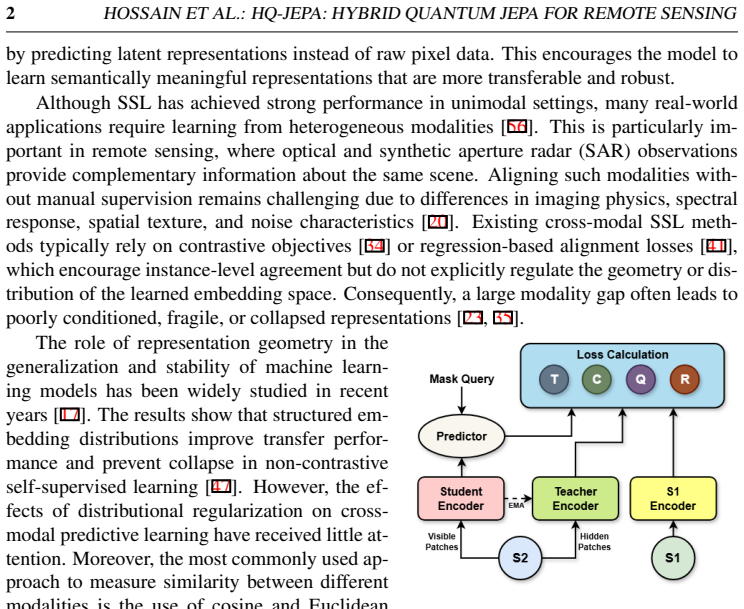
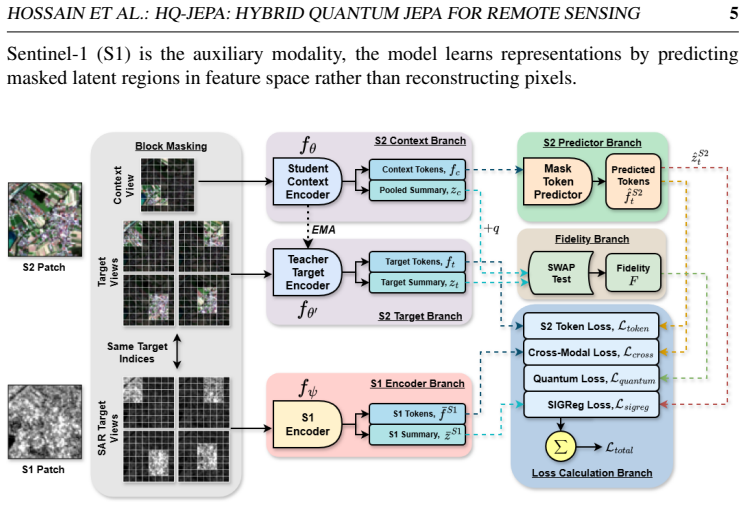
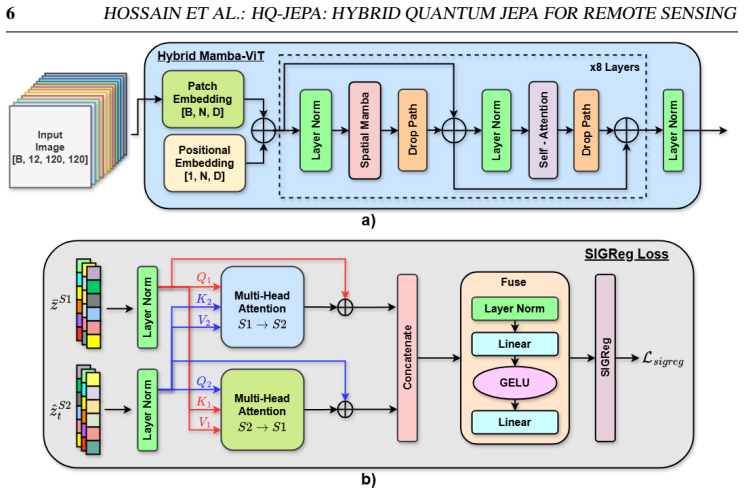
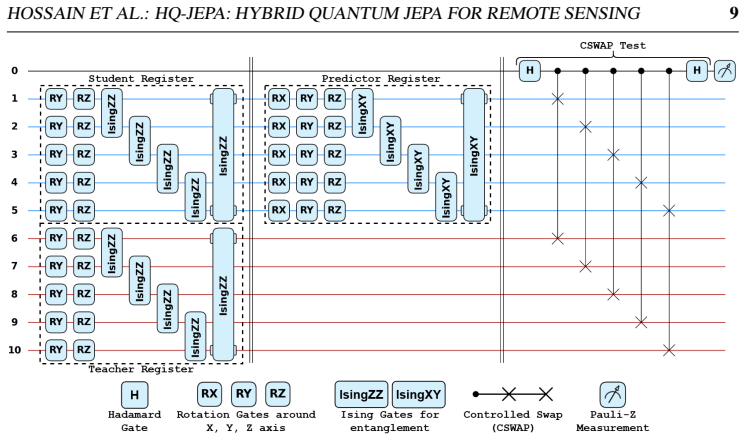
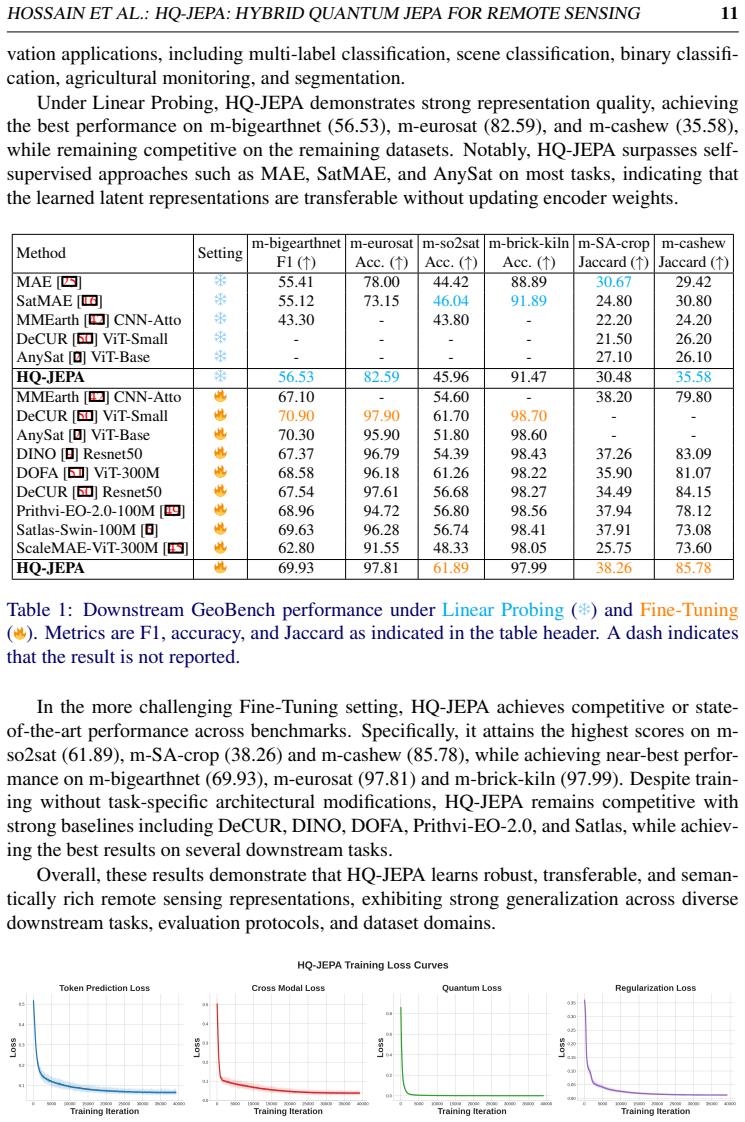
HQ-JEPA extends JEPA-style masked latent prediction to paired Sentinel-1 and Sentinel-2 imagery by predicting masked target representations from visible context regions while aligning heterogeneous modality features in a shared embedding space. Four objectives are combined: latent token prediction, cross-modal token alignment, SIGReg-based Gaussian regularization, and a differentiable SWAP-test-based Fidelity Quantum Similarity loss. The resulting encoder, when evaluated on GeoBench classification and segmentation tasks, achieves competitive and often superior performance over strong self-supervised and remote sensing foundation-model baselines.
What carries the argument
The differentiable SWAP-test-based Fidelity Quantum Similarity (FQS) loss, which supplies quantum state-overlap similarity as an additional regularization signal in the fused latent space.
If this is right
- Masked latent prediction in a shared embedding space produces semantic representations without requiring pixel-level reconstruction of Sentinel imagery.
- Cross-modal token alignment regularizes the latent space so that radar and optical features become comparable for downstream tasks.
- Gaussian regularization in the fused space further stabilizes the joint embedding learned from paired modalities.
- The pretrained encoder transfers to both linear probing and full fine-tuning on classification and segmentation benchmarks.
Where Pith is reading between the lines
- The same combination of predictive and quantum regularization objectives could be tested on other paired sensor types such as hyperspectral and LiDAR data.
- If the SWAP-test simulation scales efficiently, the FQS term might be replaced by a true quantum circuit on future hardware while keeping the rest of the pipeline unchanged.
- The framework implies that quantum-inspired similarity measures can act as drop-in regularizers even when run on classical simulators.
Load-bearing premise
The Fidelity Quantum Similarity loss must supply an independent and beneficial regularization signal that improves representations beyond what the classical prediction and alignment objectives already achieve.
What would settle it
An ablation experiment in which removing the FQS loss from the training objectives leaves performance on the GeoBench linear-probing and fine-tuning tasks unchanged or lower than the full model.
Figures

read the original abstract
We introduce HQ-JEPA, a hybrid quantum-classical joint-embedding predictive architecture for cross-modal remote sensing representation learning. The proposed framework extends JEPA-style masked latent prediction to paired Sentinel-1 and Sentinel-2 imagery by predicting masked target representations from visible context regions while aligning heterogeneous modality features in a shared embedding space. To improve representation quality, HQ-JEPA combines four complementary objectives: latent token prediction, cross-modal token alignment, SIGReg-based Gaussian regularization in the fused latent space, and a differentiable SWAP-test-based Fidelity Quantum Similarity (FQS) loss. Unlike pixel reconstruction methods, HQ-JEPA learns semantic representations directly in latent space and uses quantum state-overlap-based similarity as an additional regularization signal. We evaluate the pretrained encoder on GeoBench classification and segmentation tasks under linear probing and fine-tuning settings. Results show that HQ-JEPA achieves competitive and often superior performance over strong self-supervised and remote sensing foundation-model baselines, demonstrating the benefit of integrating predictive self-supervision, cross-modal geometric regularization, and quantum fidelity-based representation learning for remote sensing applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces HQ-JEPA, a hybrid quantum-classical joint-embedding predictive architecture for cross-modal remote sensing representation learning from paired Sentinel-1 and Sentinel-2 imagery. It extends JEPA-style masked latent prediction with cross-modal token alignment, SIGReg-based Gaussian regularization in the fused latent space, and a differentiable SWAP-test-based Fidelity Quantum Similarity (FQS) loss. The pretrained encoder is evaluated on GeoBench classification and segmentation tasks under linear probing and fine-tuning, with the abstract claiming competitive or superior performance over self-supervised and remote sensing foundation-model baselines, thereby demonstrating the benefit of integrating predictive self-supervision, cross-modal geometric regularization, and quantum fidelity-based representation learning.
Significance. If the performance gains can be shown to arise from the independent contribution of the quantum fidelity term rather than the classical objectives alone, the work would provide a notable example of incorporating quantum state-overlap measures as regularization in self-supervised remote sensing models. This could encourage further exploration of hybrid quantum-classical techniques in geospatial representation learning, provided the empirical isolation of each component is addressed.
major comments (1)
- [Abstract] Abstract: The central claim that the results demonstrate the benefit of integrating ... quantum fidelity-based representation learning rests on the premise that the FQS loss supplies a distinct additive regularization signal. However, the manuscript provides no controlled ablation (full model vs. identical architecture with the FQS term removed) on the same GeoBench splits, so any observed superiority could be explained entirely by the JEPA-style prediction, cross-modal alignment, or SIGReg objectives; the quantum component's contribution remains unmeasured.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We agree that the current manuscript does not isolate the contribution of the FQS loss through a controlled ablation and that this limits the strength of claims about the quantum component. We will add the requested ablation study in the revision.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the results demonstrate the benefit of integrating ... quantum fidelity-based representation learning rests on the premise that the FQS loss supplies a distinct additive regularization signal. However, the manuscript provides no controlled ablation (full model vs. identical architecture with the FQS term removed) on the same GeoBench splits, so any observed superiority could be explained entirely by the JEPA-style prediction, cross-modal alignment, or SIGReg objectives; the quantum component's contribution remains unmeasured.
Authors: We concur that the absence of a controlled ablation isolating the FQS term prevents a definitive attribution of performance gains to the quantum fidelity loss. In the revised manuscript we will add a direct comparison of the full HQ-JEPA model against an otherwise identical architecture trained without the FQS loss, using the same GeoBench splits, training protocol, and evaluation settings. The results will be reported in a new table and discussed in the experimental section, allowing readers to assess the independent regularization effect of the SWAP-test-based fidelity term. revision: yes
Circularity Check
No circularity; architecture and claims are empirically grounded
full rationale
The paper introduces a composite loss with four terms (latent prediction, cross-modal alignment, SIGReg, FQS) and reports empirical results on GeoBench under linear probing and fine-tuning. No equation or claim reduces a derived quantity to a fitted input by construction, no self-citation is load-bearing for a uniqueness result, and no ansatz is smuggled via prior work. The central performance claim rests on external benchmark comparisons rather than tautological redefinition of inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- loss weighting coefficients
axioms (1)
- domain assumption A differentiable approximation to quantum state overlap via SWAP test can serve as a useful similarity regularizer in latent space.
invented entities (1)
-
Fidelity Quantum Similarity (FQS) loss
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Self-supervised learning from im- ages with a joint-embedding predictive architecture
Mahmoud Assran, Quentin Duval, Ishan Misra, Piotr Bojanowski, Pascal Vincent, Michael Rabbat, Yann LeCun, and Nicolas Ballas. Self-supervised learning from im- ages with a joint-embedding predictive architecture. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15619–15629, 2023
2023
-
[2]
Anysat: One earth observation model for many resolutions, scales, and modalities
Guillaume Astruc, Nicolas Gonthier, Clement Mallet, and Loic Landrieu. Anysat: One earth observation model for many resolutions, scales, and modalities. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 19530–19540, 2025
2025
-
[3]
LeJEPA: Provable and Scalable Self-Supervised Learning Without the Heuristics
Randall Balestriero and Yann LeCun. Lejepa: Provable and scalable self-supervised learning without the heuristics.arXiv preprint, arXiv:2511.08544, 10, November 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
BEiT: BERT Pre-Training of Image Transformers
Hangbo Bao, Li Dong, Songhao Piao, and Furu Wei. Beit: Bert pre-training of image transformers.arXiv preprint arXiv:2106.08254, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
VICReg: Variance-Invariance-Covariance Regularization for Self-Supervised Learning
Adrien Bardes, Jean Ponce, and Yann LeCun. Vicreg: Variance-invariance-covariance regularization for self-supervised learning.arXiv preprint arXiv:2105.04906, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
Satlaspretrain: A large-scale dataset for remote sensing image understanding
Favyen Bastani, Piper Wolters, Ritwik Gupta, Joe Ferdinando, and Aniruddha Kemb- havi. Satlaspretrain: A large-scale dataset for remote sensing image understanding. In Proceedings of the IEEE/CVF ICCV, pages 16772–16782, 2023
2023
-
[7]
Quantum machine learning.Nature, 549(7671):195–202, 2017
Jacob Biamonte, Peter Wittek, Nicola Pancotti, Patrick Rebentrost, Nathan Wiebe, and Seth Lloyd. Quantum machine learning.Nature, 549(7671):195–202, 2017
2017
-
[8]
A survey on joint embedding predictive architectures and world models.Available at SSRN 5772122, 2025
Shamyo Brotee, Gaurab Chhetri, Sazzad Bin Bashar Polock, Venkata Surya Bel- lamkonda, Amir Rafe, and Subasish Das. A survey on joint embedding predictive architectures and world models.Available at SSRN 5772122, 2025
2025
-
[9]
Emerging properties in self-supervised vision trans- formers
Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bo- janowski, and Armand Joulin. Emerging properties in self-supervised vision trans- formers. InProceedings of the IEEE/CVF international conference on computer vision, pages 9650–9660, 2021
2021
-
[10]
Variational quantum algorithms.Nature Reviews Physics, 3(9):625–644, 2021
Marco Cerezo, Andrew Arrasmith, Ryan Babbush, Simon C Benjamin, Suguru Endo, Keisuke Fujii, Jarrod R McClean, Kosuke Mitarai, Xiao Yuan, Lukasz Cincio, et al. Variational quantum algorithms.Nature Reviews Physics, 3(9):625–644, 2021
2021
-
[11]
Why do we need large batchsizes in contrastive learning? a gradient-bias perspective.Advances in Neural Information Processing Systems, 35:33860–33875, 2022
Changyou Chen, Jianyi Zhang, Yi Xu, Liqun Chen, Jiali Duan, Yiran Chen, Son Tran, Belinda Zeng, and Trishul Chilimbi. Why do we need large batchsizes in contrastive learning? a gradient-bias perspective.Advances in Neural Information Processing Systems, 35:33860–33875, 2022. 16HOSSAIN ET AL.: HQ-JEPA: HYBRID QUANTUM JEPA FOR REMOTE SENSING
2022
-
[12]
Self- supervised learning for few-shot image classification
Da Chen, Yuefeng Chen, Yuhong Li, Feng Mao, Yuan He, and Hui Xue. Self- supervised learning for few-shot image classification. InIEEE ICASSP, pages 1745–
-
[13]
Vl-jepa: Joint embedding pre- dictive architecture for vision-language, 2026
Delong Chen, Mustafa Shukor, Theo Moutakanni, Willy Chung, Jade Yu, Te- jaswi Kasarla, Yejin Bang, Allen Bolourchi, Yann LeCun, and Pascale Fung. Vl- jepa: Joint embedding predictive architecture for vision-language.arXiv preprint arXiv:2512.10942, 2025
-
[14]
A simple framework for contrastive learning of visual representations
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. InInternational confer- ence on machine learning, pages 1597–1607. PmLR, 2020
2020
-
[15]
Exploring simple siamese representation learning
Xinlei Chen and Kaiming He. Exploring simple siamese representation learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15750–15758, 2021
2021
-
[16]
Satmae: Pre-training transformers for temporal and multi-spectral satellite imagery.Advances in Neural Information Pro- cessing Systems, 35:197–211, 2022
Yezhen Cong, Samar Khanna, Chenlin Meng, Patrick Liu, Erik Rozi, Yutong He, Mar- shall Burke, David Lobell, and Stefano Ermon. Satmae: Pre-training transformers for temporal and multi-spectral satellite imagery.Advances in Neural Information Pro- cessing Systems, 35:197–211, 2022
2022
-
[17]
Romain Cosentino, Sarath Shekkizhar, Mahdi Soltanolkotabi, Salman Avestimehr, and Antonio Ortega. The geometry of self-supervised learning models and its impact on transfer learning.arXiv preprint arXiv:2209.08622, 2022
-
[18]
The hidden pitfalls of the cosine similarity loss.arXiv preprint arXiv:2406.16468, 2024
Andrew Draganov, Sharvaree Vadgama, and Erik J Bekkers. The hidden pitfalls of the cosine similarity loss.arXiv preprint arXiv:2406.16468, 2024
-
[19]
Whitening for self-supervised representation learning
Aleksandr Ermolov, Aliaksandr Siarohin, Enver Sangineto, and Nicu Sebe. Whitening for self-supervised representation learning. InInternational conference on machine learning, pages 3015–3024. PMLR, 2021
2021
-
[20]
Chal- lenges and proposed solutions in modeling multimodal data: A systematic review
Maryam Farhadizadeh, Maria Weymann, Michael Blaß, Johann Kraus, Christopher Gundler, Sebastian Walter, Noah Hempen, Harald Binder, and Nadine Binder. Chal- lenges and proposed solutions in modeling multimodal data: A systematic review. arXiv preprint arXiv:2505.06945, 2025
-
[21]
Bootstrap your own latent-a new approach to self-supervised learning.Advances in neural information processing systems, 33:21271–21284, 2020
Jean-Bastien Grill, Florian Strub, Florent Altché, Corentin Tallec, Pierre Richemond, Elena Buchatskaya, Carl Doersch, Bernardo Avila Pires, Zhaohan Guo, Mohammad Gheshlaghi Azar, et al. Bootstrap your own latent-a new approach to self-supervised learning.Advances in neural information processing systems, 33:21271–21284, 2020
2020
-
[22]
A survey on self-supervised learning: Algorithms, applications, and future trends.IEEE T-PAMI, 46(12):9052–9071, 2024
Jie Gui, Tuo Chen, Jing Zhang, Qiong Cao, Zhenan Sun, Hao Luo, and Dacheng Tao. A survey on self-supervised learning: Algorithms, applications, and future trends.IEEE T-PAMI, 46(12):9052–9071, 2024
2024
-
[23]
Exploring the gap between collapsed & whitened features in self-supervised learning
Bobby He and Mete Ozay. Exploring the gap between collapsed & whitened features in self-supervised learning. InInternational Conference on Machine Learning, pages 8613–8634. PMLR, 2022. HOSSAIN ET AL.: HQ-JEPA: HYBRID QUANTUM JEPA FOR REMOTE SENSING17
2022
-
[24]
Momentum con- trast for unsupervised visual representation learning
Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum con- trast for unsupervised visual representation learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9729–9738, 2020
2020
-
[25]
Masked autoencoders are scalable vision learners
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick. Masked autoencoders are scalable vision learners. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16000–16009, 2022
2022
-
[26]
Self-supervised representation learning for bayesian quantum architecture search
Zhimin He, Hongxiang Chen, Yan Zhou, Haozhen Situ, Yongyao Li, and Lvzhou Li. Self-supervised representation learning for bayesian quantum architecture search. Physical Review A, 111(3):032403, 2025
2025
-
[27]
Masked image modeling: A survey.International Journal of Computer Vision, 133(10):7154–7200, 2025
Vlad Hondru, Florinel Alin Croitoru, Shervin Minaee, Radu Tudor Ionescu, and Nicu Sebe. Masked image modeling: A survey.International Journal of Computer Vision, 133(10):7154–7200, 2025
2025
-
[28]
QMC-Net: Data-Aware Quantum Representations for Remote Sensing Image Classification
Md Aminur Hossain, Ayush V Patel, and Biplab Banerjee. Qmc-net: Data-aware quantum representations for remote sensing image classification.arXiv preprint arXiv:2604.11817, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[29]
HQF-Net: A Hybrid Quantum-Classical Multi-Scale Fusion Network for Remote Sensing Image Segmentation
Md Aminur Hossain, Ayush V Patel, Siddhant Gole, Sanjay K Singh, and Biplab Baner- jee. Hqf-net: A hybrid quantum-classical multi-scale fusion network for remote sensing image segmentation.arXiv preprint arXiv:2604.06715, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[30]
Md Aminur Hossain, Ayush V Patel, Ikshwaku Vanani, and Biplab Banerjee. Hq-unet: A hybrid quantum-classical u-net with a quantum bottleneck for remote sensing image segmentation.arXiv preprint arXiv:2604.27206, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[31]
A survey of self-supervised and few-shot object detection.IEEE T-PAMI, 45 (4):4071–4089, 2022
Gabriel Huang, Issam Laradji, David Vazquez, Simon Lacoste-Julien, and Pau Ro- driguez. A survey of self-supervised and few-shot object detection.IEEE T-PAMI, 45 (4):4071–4089, 2022
2022
-
[32]
Self-supervised learning for medical image classification: a systematic review and implementation guidelines.NPJ Digital Medicine, 6(1):74, 2023
Shih-Cheng Huang, Anuj Pareek, Malte Jensen, Matthew P Lungren, Serena Yeung, and Akshay S Chaudhari. Self-supervised learning for medical image classification: a systematic review and implementation guidelines.NPJ Digital Medicine, 6(1):74, 2023
2023
-
[33]
Quantum self-supervised learning.Quantum Science & Technology, 7 (3):035005, 2022
Ben Jaderberg, Lewis W Anderson, Weidi Xie, Samuel Albanie, Martin Kiffner, and Dieter Jaksch. Quantum self-supervised learning.Quantum Science & Technology, 7 (3):035005, 2022
2022
-
[34]
A survey on contrastive self-supervised learning.Technologies, 9 (1):2, 2020
Ashish Jaiswal, Ashwin Ramesh Babu, Mohammad Zaki Zadeh, Debapriya Banerjee, and Fillia Makedon. A survey on contrastive self-supervised learning.Technologies, 9 (1):2, 2020
2020
-
[35]
Li Jing, Pascal Vincent, Yann LeCun, and Yuandong Tian. Understanding dimensional collapse in contrastive self-supervised learning.arXiv preprint arXiv:2110.09348, 2021
-
[36]
Debanjan Konar, Siddhartha Bhattacharyya, Bijaya K Panigrahi, and Elizabeth C Behrman. Qutrit-inspired fully self-supervised shallow quantum learning network for brain tumor segmentation.IEEE Transactions on Neural Networks and Learning Sys- tems, 33(11):6331–6345, 2021. 18HOSSAIN ET AL.: HQ-JEPA: HYBRID QUANTUM JEPA FOR REMOTE SENSING
2021
-
[37]
Geo-bench: Toward foundation models for earth monitoring.Advances in Neural Information Processing Systems, 36:51080–51093, 2023
Alexandre Lacoste, Nils Lehmann, Pau Rodriguez, Evan Sherwin, Hannah Kerner, Björn Lütjens, Jeremy Irvin, David Dao, Hamed Alemohammad, Alexandre Drouin, et al. Geo-bench: Toward foundation models for earth monitoring.Advances in Neural Information Processing Systems, 36:51080–51093, 2023
2023
-
[38]
Qsea: Quantum self- supervised learning with entanglement augmentation.Advanced Quantum Technolo- gies, 9(4):e00530, 2026
LingXiao Li, XiaoHui Ni, Jing Li, SuJuan Qin, and Fei Gao. Qsea: Quantum self- supervised learning with entanglement augmentation.Advanced Quantum Technolo- gies, 9(4):e00530, 2026
2026
-
[39]
Quantum fidelity measures for mixed states.Reports on Progress in Physics, 82(7):076001, 2019
Yeong-Cherng Liang, Yu-Hao Yeh, Paulo EMF Mendonça, Run Yan Teh, Margaret D Reid, and Peter D Drummond. Quantum fidelity measures for mixed states.Reports on Progress in Physics, 82(7):076001, 2019
2019
-
[40]
V-JEPA 2.1: Unlocking Dense Features in Video Self-Supervised Learning
Lorenzo Mur-Labadia, Matthew Muckley, Amir Bar, Mido Assran, Koustuv Sinha, Mike Rabbat, Yann LeCun, Nicolas Ballas, and Adrien Bardes. V-jepa 2.1: Unlocking dense features in video self-supervised learning.arXiv preprint arXiv:2603.14482, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[41]
KL Navaneet, Soroush Abbasi Koohpayegani, Ajinkya Tejankar, and Hamed Pirsi- avash. Simreg: Regression as a simple yet effective tool for self-supervised knowledge distillation.arXiv preprint arXiv:2201.05131, 2022
-
[42]
Mmearth: Exploring multi-modal pretext tasks for geospatial repre- sentation learning
Vishal Nedungadi, Ankit Kariryaa, Stefan Oehmcke, Serge Belongie, Christian Igel, and Nico Lang. Mmearth: Exploring multi-modal pretext tasks for geospatial repre- sentation learning. InECCV, pages 164–182. Springer, 2024
2024
-
[43]
Self-supervised learning for few-shot medical image segmentation.IEEE Transactions on Medical Imaging, 41(7):1837–1848, 2022
Cheng Ouyang, Carlo Biffi, Chen Chen, Turkay Kart, Huaqi Qiu, and Daniel Rueckert. Self-supervised learning for few-shot medical image segmentation.IEEE Transactions on Medical Imaging, 41(7):1837–1848, 2022
2022
-
[44]
Qclr: Quantum-lstm contrastive learning frame- work for continuous mental health monitoring.Expert Systems with Applications, 238: 121921, 2024
Anupama Padha and Anita Sahoo. Qclr: Quantum-lstm contrastive learning frame- work for continuous mental health monitoring.Expert Systems with Applications, 238: 121921, 2024
2024
-
[45]
Scale- mae: A scale-aware masked autoencoder for multiscale geospatial representation learn- ing
Colorado J Reed, Ritwik Gupta, Shufan Li, Sarah Brockman, Christopher Funk, Brian Clipp, Kurt Keutzer, Salvatore Candido, Matt Uyttendaele, and Trevor Darrell. Scale- mae: A scale-aware masked autoencoder for multiscale geospatial representation learn- ing. InProceedings of the IEEE/CVF ICCV, pages 4088–4099, 2023
2023
-
[46]
Quantum con- trastive learning for human activity recognition.Smart Health, 36:100574, 2025
Yanhui Ren, Di Wang, Lingling An, Shiwen Mao, and Xuyu Wang. Quantum con- trastive learning for human activity recognition.Smart Health, 36:100574, 2025
2025
-
[47]
Collapse-proof non- contrastive self-supervised learning.arXiv preprint arXiv:2410.04959, 2024
Emanuele Sansone, Tim Lebailly, and Tinne Tuytelaars. Collapse-proof non- contrastive self-supervised learning.arXiv preprint arXiv:2410.04959, 2024
-
[48]
Oriane Siméoni, Huy V V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michaël Ramamonjisoa, et al. Dinov3.arXiv preprint arXiv:2508.10104, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
Prithvi-eo-2.0: A versatile multi-temporal foun- dation model for earth observation applications.IEEE TGRS, 2025
Daniela Szwarcman, Sujit Roy, Paolo Fraccaro, Orsteinn Elí Gíslason, Benedikt Blu- menstiel, Rinki Ghosal, Pedro Henrique De Oliveira, Joao Lucas de Sousa Almeida, Rocco Sedona, Yanghui Kang, et al. Prithvi-eo-2.0: A versatile multi-temporal foun- dation model for earth observation applications.IEEE TGRS, 2025. HOSSAIN ET AL.: HQ-JEPA: HYBRID QUANTUM JEPA...
2025
-
[50]
Decoupling common and unique representations for multimodal self-supervised learning
Yi Wang, Conrad M Albrecht, Nassim Ait Ali Braham, Chenying Liu, Zhitong Xiong, and Xiao Xiang Zhu. Decoupling common and unique representations for multimodal self-supervised learning. InECCV, pages 286–303. Springer, 2024
2024
-
[51]
Zhitong Xiong, Yi Wang, Fahong Zhang, Adam J Stewart, Joëlle Hanna, Damian Borth, Ioannis Papoutsis, Bertrand Le Saux, Gustau Camps-Valls, and Xiao Xiang Zhu. Neural plasticity-inspired multimodal foundation model for earth observation. arXiv preprint arXiv:2403.15356, 2024
-
[52]
Self-supervised pre-trained neural network for quantum natural language processing.Neural Networks, 184:107004, 2025
Ben Yao, Prayag Tiwari, and Qiuchi Li. Self-supervised pre-trained neural network for quantum natural language processing.Neural Networks, 184:107004, 2025
2025
-
[53]
Shuhei Yokoo. Contrastive learning with large memory bank and negative embedding subtraction for accurate copy detection.arXiv preprint arXiv:2112.04323, 2021
-
[54]
QUSL: Quantum Unsupervised Image Similarity Learning with Enhanced Perfor- mance.arXiv e-prints, April 2024
Lian-Hui Yu, Xiao-Yu Li, Geng Chen, Qin-Sheng Zhu, Hui Li, and Guo-Wu Yang. QUSL: Quantum Unsupervised Image Similarity Learning with Enhanced Perfor- mance.arXiv e-prints, April 2024
2024
-
[55]
Barlow twins: Self-supervised learning via redundancy reduction
Jure Zbontar, Li Jing, Ishan Misra, Yann LeCun, and Stéphane Deny. Barlow twins: Self-supervised learning via redundancy reduction. InInternational conference on ma- chine learning, pages 12310–12320. PMLR, 2021
2021
-
[56]
Self-supervised mul- timodal learning: A survey.IEEE Transactions on Pattern Analysis and Machine In- telligence, 47(7):5299–5318, 2024
Yongshuo Zong, Oisin Mac Aodha, and Timothy M Hospedales. Self-supervised mul- timodal learning: A survey.IEEE Transactions on Pattern Analysis and Machine In- telligence, 47(7):5299–5318, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.