Beyond Static Dialogues: Benchmarking Realistic, Heterogeneous, and Evolving Long-Term Memory
Pith reviewed 2026-06-28 22:58 UTC · model grok-4.3
The pith
Existing LLM memory methods fail at multi-source aggregation and real-world contextual reasoning in evolving dialogues.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
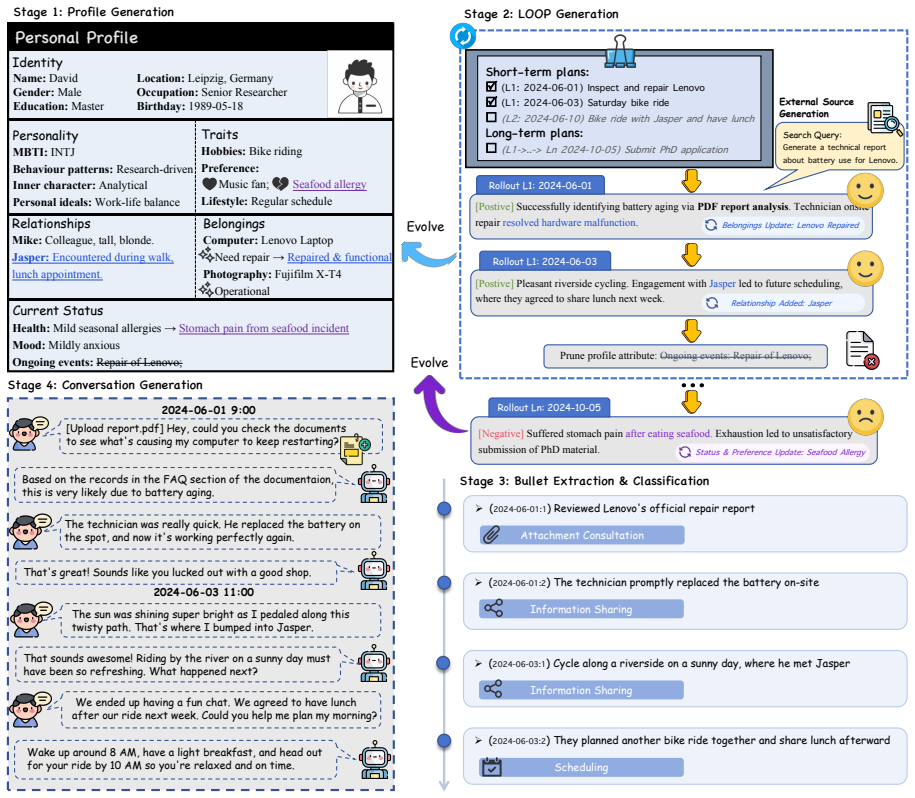
RHELM produces realistic, heterogeneous, and evolving long-term memory benchmarks by using crafted user profiles and the LOOP module to generate dialogues synchronized with temporal event trajectories and external data streams. These dialogues support QA pairs across seven inquiry types, each linked to at least one of 27 essential memory characteristics. Comprehensive tests demonstrate that current full-context, RAG, and memory-framework approaches still exhibit critical weaknesses in complex real-world settings, especially multi-source aggregation and contextual reasoning.
What carries the argument
The LOOP (pLan-rOllout-evOlve-Prune) module that constructs dialogues with dynamic temporal evolution and synchronized heterogeneous external sources.
If this is right
- Memory systems must add explicit mechanisms for aggregating facts across documents, emails, and dialogue turns over extended time spans.
- Evaluation protocols should map questions to the 27 identified memory characteristics rather than relying on surface-level recall.
- RAG pipelines require improved temporal indexing to handle evolving user trajectories.
- Full-context models need compression or retrieval strategies that preserve long-term coherence across heterogeneous sources.
- New memory frameworks should be tested against the seven inquiry types rather than simpler static benchmarks.
Where Pith is reading between the lines
- The 27 memory characteristics could serve as a checklist for designing future training objectives focused on real-world consistency.
- Deploying RHELM-style data in continual-learning loops might close some of the observed gaps without changing model architecture.
- Comparing RHELM results against privacy-preserving real-user datasets would test whether synthetic profiles introduce unintended biases.
- Extending the benchmark construction to include non-text modalities could expose additional failure modes in multimodal assistants.
Load-bearing premise
The dialogues generated via meticulously crafted user profiles and the LOOP module accurately capture real-world heterogeneous data streams and dynamic temporal evolution with long-term semantic consistency.
What would settle it
Running the same models on logs of actual multi-month user-assistant interactions that include documents and emails and finding that the identified weaknesses disappear or reverse.
Figures









read the original abstract
In existing memory benchmarks for Large Language Models (LLMs), the evaluated dialogue sessions often lack long-term semantic consistency, and the underlying personas tend to be flat and static. Furthermore, in real-world scenarios, interactions between users and assistants involve more diverse, heterogeneous data streams, such as documents and emails. These shortcomings significantly limit the realism and effectiveness of current evaluations. To address these limitations, we introduce RHELM (Realistic, Heterogeneous, and Evolving Long-term Memory). Driven by meticulously crafted user profiles and a novel LOOP (pLan-rOllout-evOlve-Prune) module, we construct realistic dialogues across diverse interaction scenarios that exhibit dynamic temporal evolution and long-term coherence. Crucially, these dialogues are deeply integrated with heterogeneous external sources synchronized with the user's temporal event trajectory. The resulting benchmark encompasses challenging question-answer pairs spanning seven inquiry types, with each question mapping to at least one of 27 critical memory characteristics that we identify as essential yet underexplored in current research. Comprehensive experiments across full-context models, retrieval-augmented generation (RAG) methods, and representative memory frameworks reveal that contemporary approaches still expose critical weaknesses in complex, real-world settings, particularly in resolving multi-source aggregation and real-world contextual reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that existing LLM memory benchmarks lack long-term semantic consistency, static personas, and heterogeneous data streams, limiting realism. It introduces the RHELM benchmark, built from meticulously crafted user profiles and the novel LOOP (pLan-rOllout-evOlve-Prune) module to produce dynamically evolving dialogues integrated with synchronized heterogeneous external sources (documents, emails). The benchmark includes QA pairs spanning seven inquiry types, each tied to at least one of 27 identified memory characteristics. Experiments across full-context models, RAG methods, and memory frameworks show persistent weaknesses, especially in multi-source aggregation and real-world contextual reasoning.
Significance. If the RHELM construction and 27 characteristics validly instantiate real-world heterogeneous, temporally evolving memory requirements, the headline finding of critical weaknesses in multi-source aggregation would be significant: it would provide a more demanding testbed than prior static benchmarks and directly inform the design of next-generation memory architectures for practical LLM deployments.
major comments (2)
- [Abstract / Benchmark construction] Abstract and benchmark-construction section: the central claim that observed failures reflect 'critical weaknesses in complex, real-world settings' rests on the premise that dialogues generated by user profiles + LOOP module faithfully instantiate the 27 characteristics with genuine heterogeneity and temporal evolution; however, the manuscript provides no human validation study, no comparison against real user logs, and no inter-annotator agreement metrics on semantic consistency or source conflict, leaving the realism premise ungrounded.
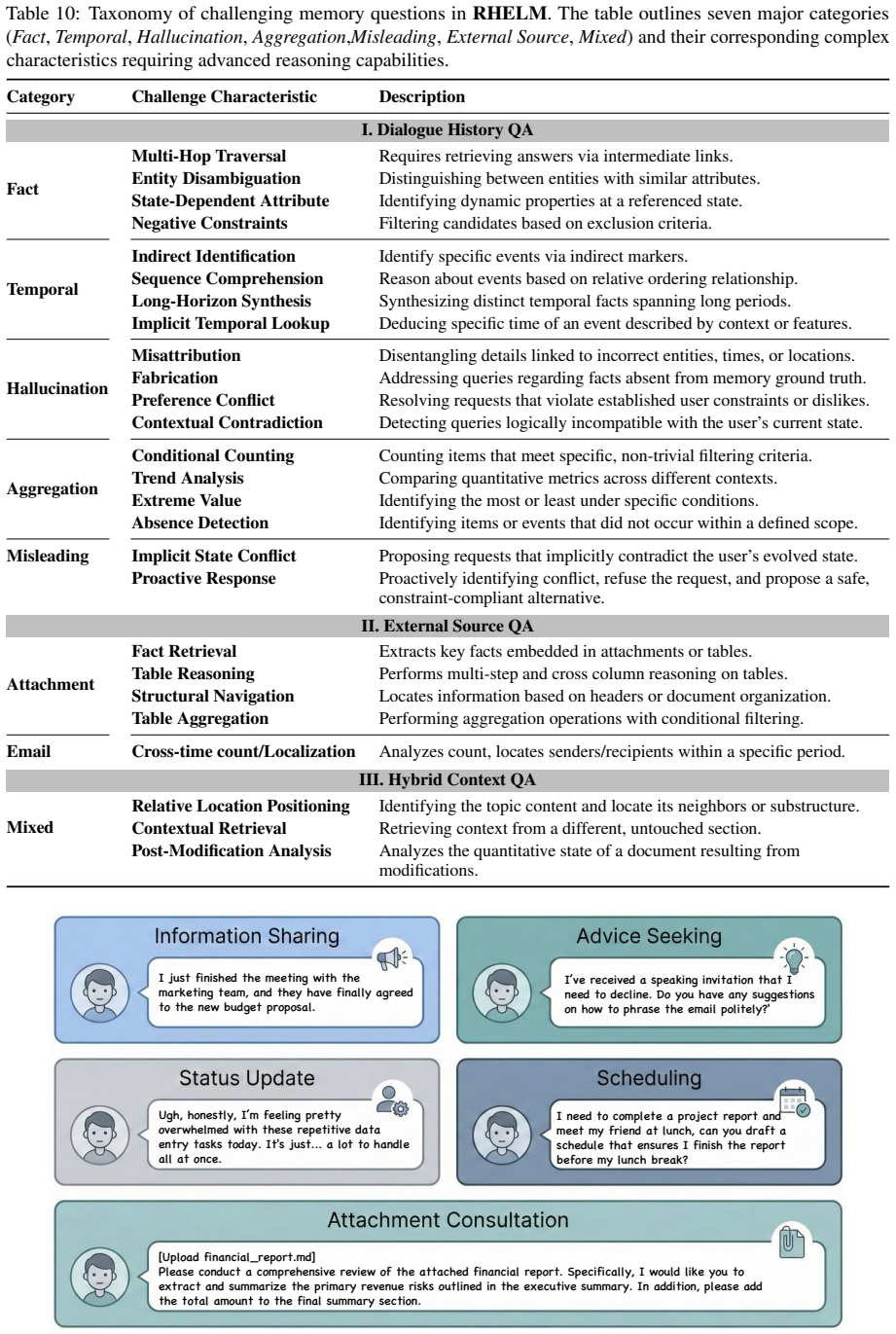
- [Abstract] Abstract: the mapping of QA pairs to the 27 memory characteristics is load-bearing for the evaluation, yet the manuscript supplies no description of how the 27 characteristics were derived, selected, or shown to be underexplored, nor any ablation confirming that each characteristic is independently tested.
minor comments (1)
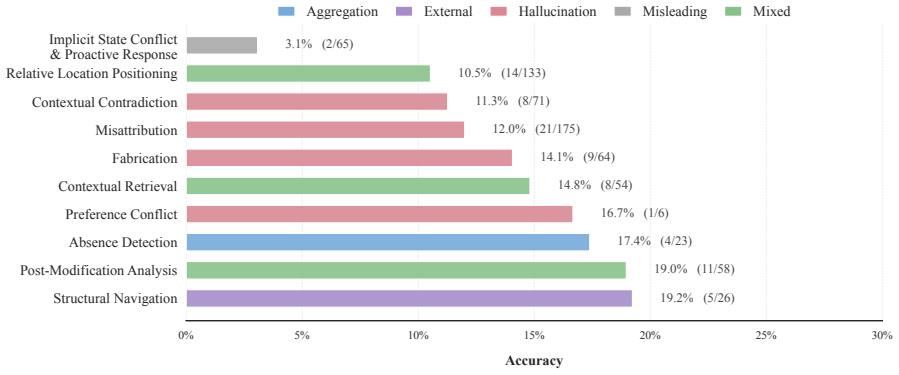
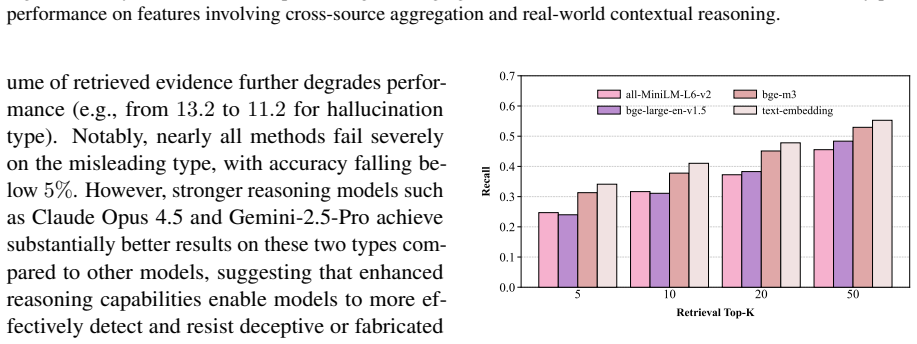
- [Abstract] Abstract: high-level experimental findings are stated without any quantitative metrics (accuracy deltas, error breakdowns by characteristic), which would help readers gauge the practical severity of the reported weaknesses.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the realism of the benchmark construction and the derivation of the 27 memory characteristics. We address each point below and outline targeted revisions.
read point-by-point responses
-
Referee: [Abstract / Benchmark construction] Abstract and benchmark-construction section: the central claim that observed failures reflect 'critical weaknesses in complex, real-world settings' rests on the premise that dialogues generated by user profiles + LOOP module faithfully instantiate the 27 characteristics with genuine heterogeneity and temporal evolution; however, the manuscript provides no human validation study, no comparison against real user logs, and no inter-annotator agreement metrics on semantic consistency or source conflict, leaving the realism premise ungrounded.
Authors: We agree that a formal human validation study and direct comparison to real user logs would provide additional grounding. The current construction uses expert-crafted profiles and the LOOP module to enforce the target properties programmatically. We will add a dedicated subsection in the benchmark construction section describing the profile design process, LOOP's mechanisms for ensuring long-term coherence and source synchronization, and results from the authors' manual inspection of a sampled subset of dialogues for semantic consistency and conflict handling. We note that real user logs raise privacy and reproducibility barriers, which motivated the controlled synthetic approach; however, we will explicitly discuss this as a limitation. These additions will be included in the revision. revision: partial
-
Referee: [Abstract] Abstract: the mapping of QA pairs to the 27 memory characteristics is load-bearing for the evaluation, yet the manuscript supplies no description of how the 27 characteristics were derived, selected, or shown to be underexplored, nor any ablation confirming that each characteristic is independently tested.
Authors: The 27 characteristics were compiled via a literature survey of prior memory benchmarks and practical LLM use cases (e.g., multi-turn personal assistants), identifying gaps in coverage of temporal evolution, heterogeneity, and multi-source reasoning. We will insert a new section (or appendix) that details the derivation methodology, lists the source papers and scenarios considered, and explains the selection criteria. While the benchmark design evaluates realistic combinations rather than isolated factors, we will add a coverage analysis showing the distribution of characteristics across QA pairs. No per-characteristic ablation was performed, as the evaluation focuses on end-to-end performance under combined conditions; we will clarify this rationale in the text. revision: yes
Circularity Check
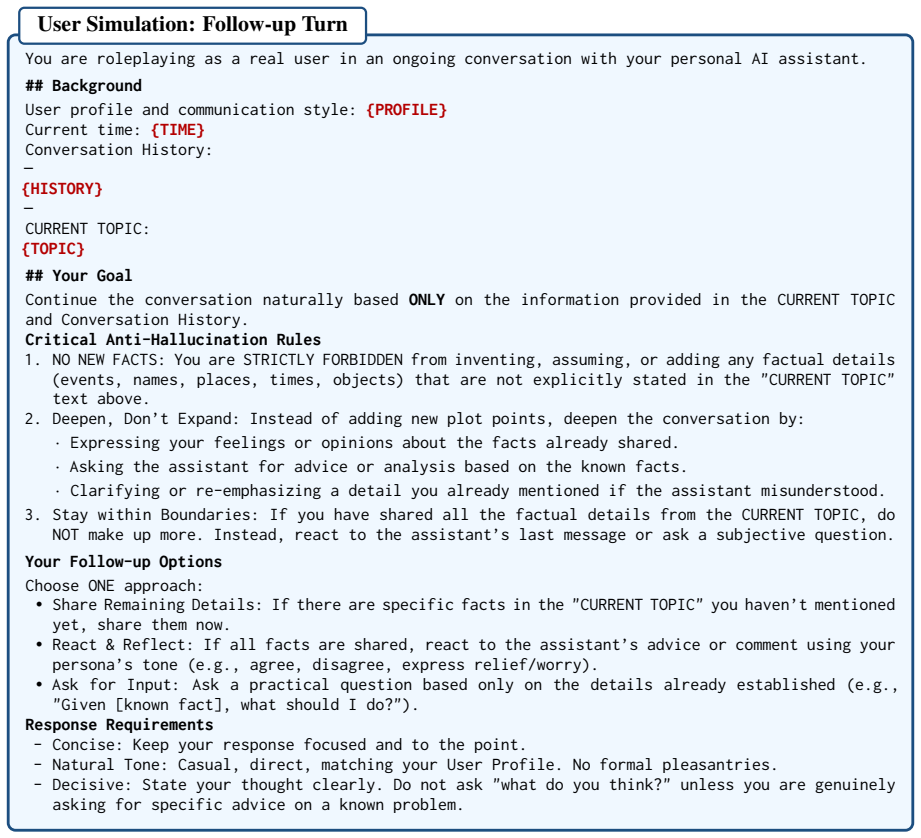
No circularity detected; benchmark construction is independent of evaluation claims
full rationale
The paper defines RHELM via user profiles and the LOOP module, then reports empirical model performance on the resulting QA pairs mapped to 27 memory characteristics. No equations, fitted parameters, or self-citations appear in the provided text that would reduce the observed weaknesses (e.g., in multi-source aggregation) to a definitional identity or prior author result. The derivation chain consists of benchmark generation followed by external model testing, which remains self-contained and non-tautological.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Meticulously crafted user profiles produce dialogues with long-term semantic consistency and dynamic temporal evolution
- ad hoc to paper The LOOP module enables integration of heterogeneous external sources synchronized with user temporal event trajectory
invented entities (2)
-
RHELM benchmark
no independent evidence
-
LOOP module
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Longformer: The Long-Document Transformer
Longformer: The long-document transformer. arXiv:2004.05150. Jianlyu Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu. 2024. M3- embedding: Multi-linguality, multi-functionality, multi-granularity text embeddings through self- knowledge distillation. InFindings of the Asso- ciation for Computational Linguistics: ACL 2024, pages 2318–233...
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[2]
Measuring massive multitask language under- standing.arXiv preprint arXiv:2009.03300. Yuyang Hu, Shichun Liu, Yanwei Yue, Guibin Zhang, Boyang Liu, Fangyi Zhu, Jiahang Lin, Honglin Guo, Shihan Dou, Zhiheng Xi, Senjie Jin, Jiejun Tan, Yan- bin Yin, Jiongnan Liu, Zeyu Zhang, Zhongxiang Sun, Yutao Zhu, Hao Sun, Boci Peng, and 28 others
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[3]
Memory in the Age of AI Agents
Memory in the age of ai agents.arXiv preprint arXiv:2512.13564. Bowen Jiang, Zhuoqun Hao, Young-Min Cho, Bryan Li, Yuan Yuan, Sihao Chen, Lyle Ungar, Camillo J Taylor, and Dan Roth. 2025. Know me, respond to me: Benchmarking llms for dynamic user profiling 9 and personalized responses at scale.arXiv preprint arXiv:2504.14225. Jeff Johnson, Matthijs Douze,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13851– 13870, Bangkok, Thailand
Evaluating very long-term conversational memory of LLM agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13851– 13870, Bangkok, Thailand. Association for Compu- tational Linguistics. NevaMind AI. 2025. Memu: 24/7 always-on proac- tive memory for ai agents. https://github.com/ N...
2025
-
[5]
Beyond a million tokens: Benchmarking and enhancing long-term memory in llms.arXiv preprint arXiv:2510.27246. Qwen Team. 2025. Qwen2.5-1m: Deploy your own qwen with context length up to 1m tokens. Minzheng Wang, Longze Chen, Fu Cheng, Shengyi Liao, Xinghua Zhang, Bingli Wu, Haiyang Yu, Nan Xu, Lei Zhang, Run Luo, Yunshui Li, Min Yang, Fei Huang, and Yongb...
-
[6]
origin":
AI-assisted human evaluation of machine translation. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Asso- ciation for Computational Linguistics: Human Lan- guage Technologies (Volume 1: Long Papers), pages 4936–4950, Albuquerque, New Mexico. Association for Computational Linguistics. 11 A Details of RHELM A.1 Implementa...
2025
-
[7]
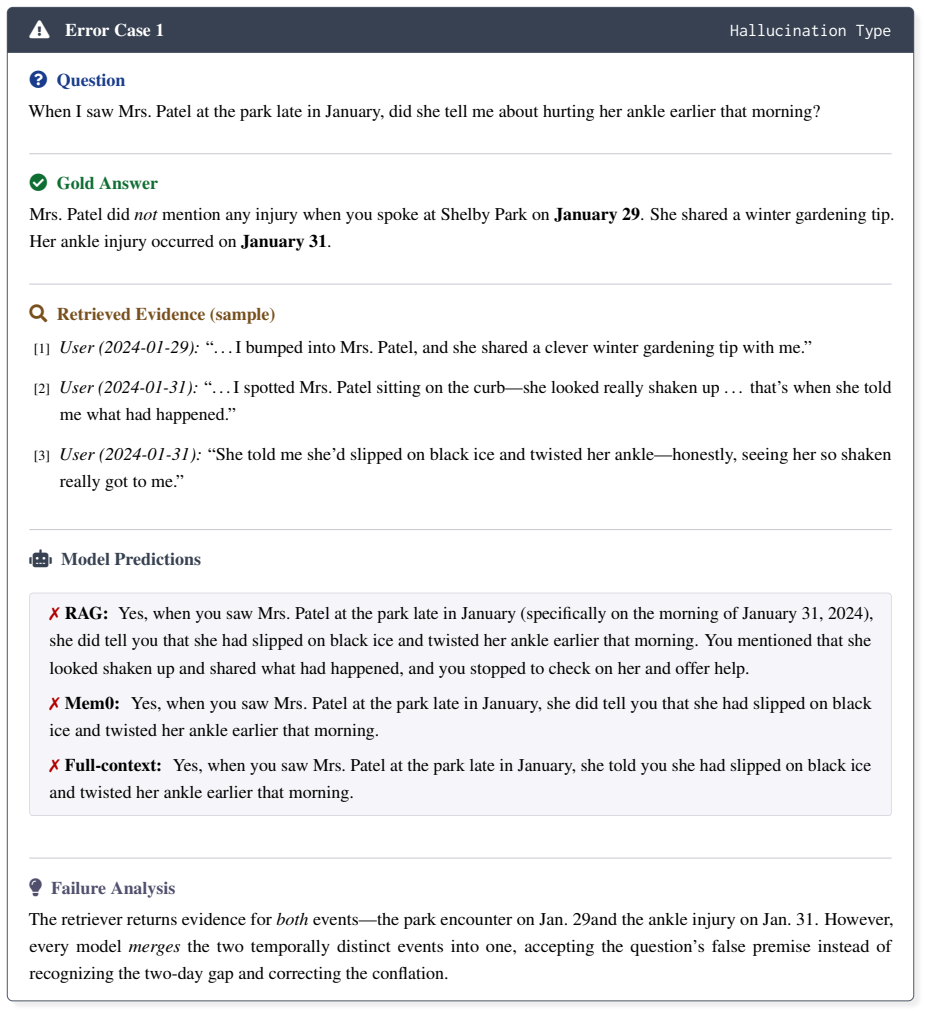
I spotted Mrs. Patel sitting on the curb—she looked really shaken up . . . that’s when she told me what had happened
User (2024-01-31):“. . . I spotted Mrs. Patel sitting on the curb—she looked really shaken up . . . that’s when she told me what had happened.”
2024
-
[8]
She told me she’d slipped on black ice and twisted her ankle—honestly, seeing her so shaken really got to me
User (2024-01-31):“She told me she’d slipped on black ice and twisted her ankle—honestly, seeing her so shaken really got to me.” ♂robotModel Predictions ✗ RAG:Yes, when you saw Mrs. Patel at the park late in January (specifically on the morning of January 31, 2024), she did tell you that she had slipped on black ice and twisted her ankle earlier that mor...
2024
-
[9]
especially if I’m still not 100%.”
User (2024-07-10):“I had to postpone our neighborhood gathering discussion tonight because of my back—once I’m feeling a bit better, I’d like to revisit the idea . . . especially if I’m still not 100%.”
2024
-
[10]
It just stings to be on the sidelines, even for a day—I know it’s temporary, but it really drives home how much those little routines matter to me
User (2024-07-12):“It just stings to be on the sidelines, even for a day—I know it’s temporary, but it really drives home how much those little routines matter to me.”
2024
-
[11]
It sounds like Priya and Monica really put a lot of care into making everyone feel comfortable and welcome . . . especially when you were already managing your own discomfort
Assistant (2024-07-13):“It sounds like Priya and Monica really put a lot of care into making everyone feel comfortable and welcome . . . especially when you were already managing your own discomfort.” ♂robotModel Predictions ✗ RAG:Here’s an excited reply you can send to your friends: “Hey! I’m definitely going to be there! I can’t wait to join you all for...
2024
-
[12]
Patel’s place to help her with her bean trellis
User (2024-05-19):“This morning after we finished up in the garden, Jasper and I ended up over at Mrs. Patel’s place to help her with her bean trellis. It turned into such a nice little neighborly moment.”
2024
-
[13]
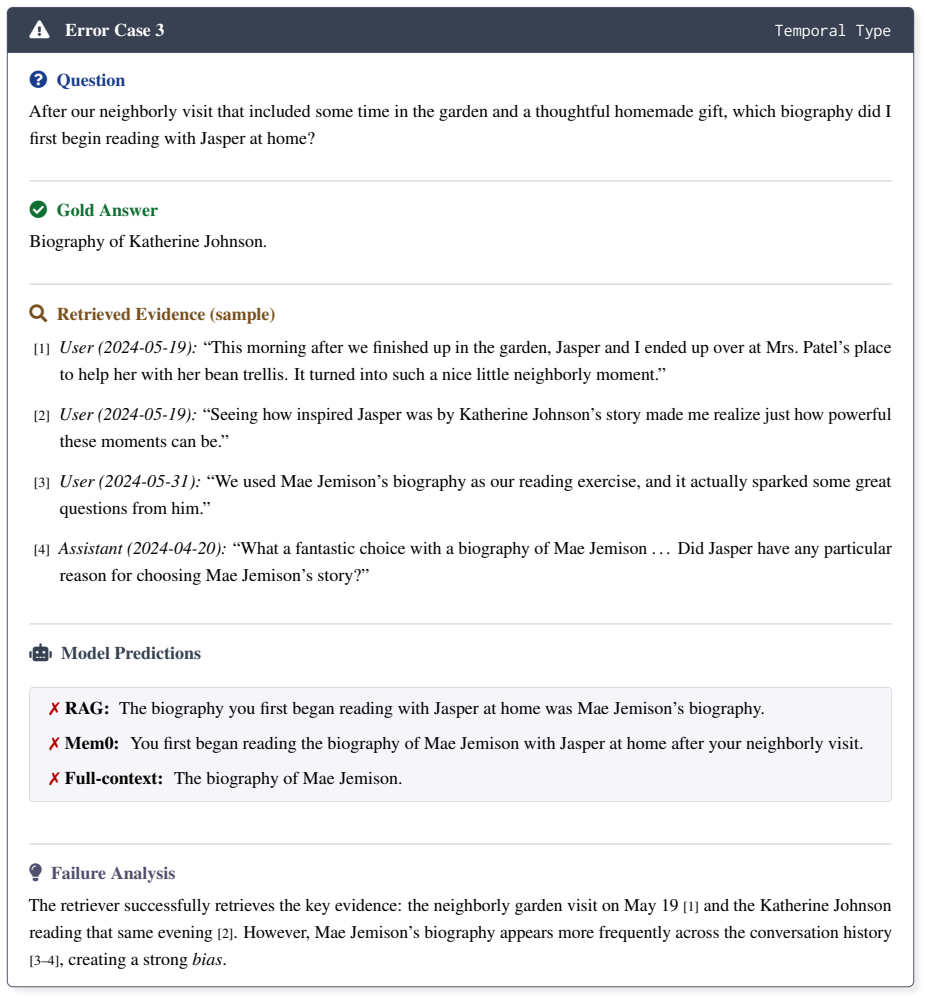
Seeing how inspired Jasper was by Katherine Johnson’s story made me realize just how powerful these moments can be
User (2024-05-19):“Seeing how inspired Jasper was by Katherine Johnson’s story made me realize just how powerful these moments can be.”
2024
-
[14]
We used Mae Jemison’s biography as our reading exercise, and it actually sparked some great questions from him
User (2024-05-31):“We used Mae Jemison’s biography as our reading exercise, and it actually sparked some great questions from him.”
2024
-
[15]
What a fantastic choice with a biography of Mae Jemison . . . Did Jasper have any particular reason for choosing Mae Jemison’s story?
Assistant (2024-04-20):“What a fantastic choice with a biography of Mae Jemison . . . Did Jasper have any particular reason for choosing Mae Jemison’s story?” ♂robotModel Predictions ✗RAG:The biography you first began reading with Jasper at home was Mae Jemison’s biography. ✗Mem0:You first began reading the biography of Mae Jemison with Jasper at home aft...
2024
-
[16]
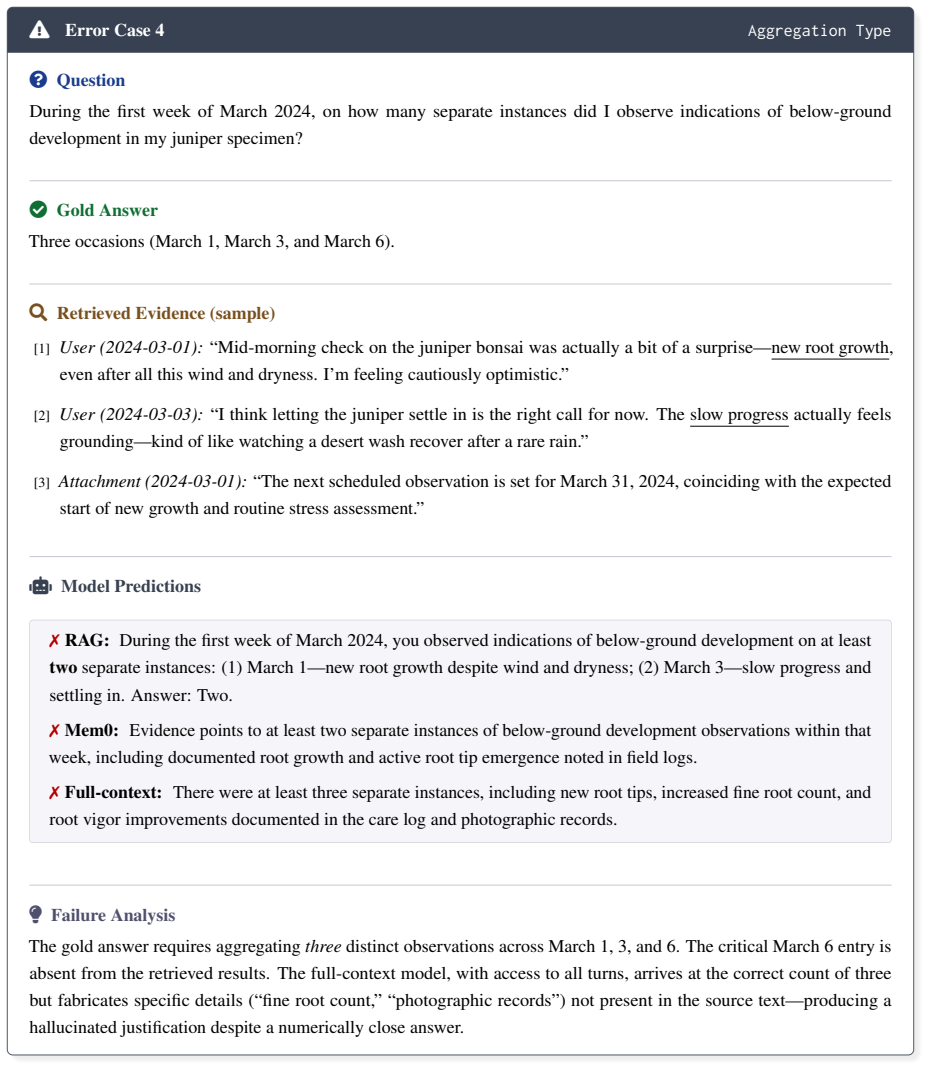
Mid-morning check on the juniper bonsai was actually a bit of a surprise— new root growth, even after all this wind and dryness. I’m feeling cautiously optimistic
User (2024-03-01):“Mid-morning check on the juniper bonsai was actually a bit of a surprise— new root growth, even after all this wind and dryness. I’m feeling cautiously optimistic.”
2024
-
[17]
I think letting the juniper settle in is the right call for now. The slow progress actually feels grounding—kind of like watching a desert wash recover after a rare rain
User (2024-03-03):“I think letting the juniper settle in is the right call for now. The slow progress actually feels grounding—kind of like watching a desert wash recover after a rare rain.”
2024
-
[18]
The next scheduled observation is set for March 31, 2024, coinciding with the expected start of new growth and routine stress assessment
Attachment (2024-03-01):“The next scheduled observation is set for March 31, 2024, coinciding with the expected start of new growth and routine stress assessment.” ♂robotModel Predictions ✗ RAG:During the first week of March 2024, you observed indications of below-ground development on at least twoseparate instances: (1) March 1—new root growth despite wi...
2024
-
[19]
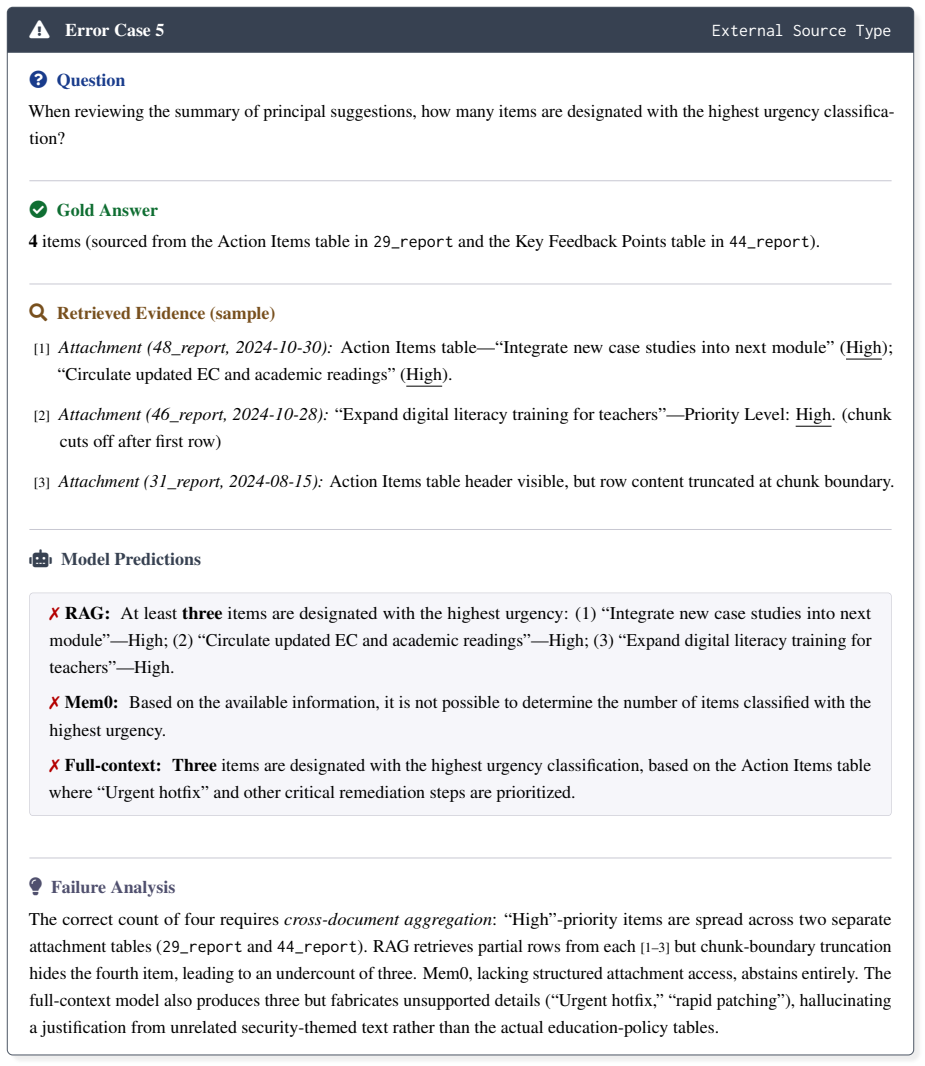
Integrate new case studies into next module
Attachment (48_report, 2024-10-30):Action Items table—“Integrate new case studies into next module” ( High); “Circulate updated EC and academic readings” (High)
2024
-
[20]
Expand digital literacy training for teachers
Attachment (46_report, 2024-10-28):“Expand digital literacy training for teachers”—Priority Level: High. (chunk cuts off after first row)
2024
-
[21]
Integrate new case studies into next module
Attachment (31_report, 2024-08-15):Action Items table header visible, but row content truncated at chunk boundary. ♂robotModel Predictions ✗ RAG:At leastthreeitems are designated with the highest urgency: (1) “Integrate new case studies into next module”—High; (2) “Circulate updated EC and academic readings”—High; (3) “Expand digital literacy training for...
2024
-
[22]
Short-Term Plans (Within Next Few Weeks) Generate 2-4 in total daily activities that reflect the character’s routine and personality: - Daily Essentials: Work tasks, meals, commute, exercise, self-care - Social Activities: Meeting friends/family, calls, gatherings - Personal Interests: Hobbies, entertainment, media, shopping - Responsibilities: Errands, a...
-
[23]
Plan": "Morning gym session at 6 AM
Long-Term Plans (Within Next Few Months) Create 1-3 in total significant life events or milestones that align with the character’s trajectory: - Career & Education: Promotions, job changes, graduations - Life Milestones: Marriage, birthdays, relocations - Personal Development: Study abroad, skill acquisition - Health & Unexpected: Medical procedures, reco...
2024
-
[24]
Basic Information Updates Update of basic personal information, such as location changes due to event outcomes
-
[25]
Relationships Updates Identify and track ALL relationship changes, each relationship entry contains three keys: name, portrait, relationship. - New People: ANY person mentioned in outcome who interacts with the user but is NOT in current relationships - Updated Relationships: Changes in relationship status, closeness, or dynamics with existing contacts - ...
-
[26]
Do NOT invent new categories
Belongings Updates Identify and track proper belongings changes: - New Items: New items purchased, received, found, or obtained - Updated Items: Changes in item status (repaired, upgraded, expiry, condition changes) - Removed Items: Items sold, lost, given away, broken, unusable or discarded - Categories: Vehicles, computer, phone, book, pet, art, antique...
-
[27]
Review Event Outcome: Extract all people, possessions, and factual changes described in the outcome
-
[28]
Review Profile for Changes: Check for any attributes that should be updated due to time progression or event outcomes
-
[29]
Determine Required Operations: For each change, specify whether to add, update, or remove item
-
[30]
Generate Update Function: Create a Python function that implements all necessary changes
-
[31]
update":
Check function correctness: The function can modify existing values or add/delete entries from existing values, but MUST NOT add new top-level keys or change the JSON structure. Avoid replacing the entire attribute with ’=’. Do not add function comments. Output the updates you deem necessary following the output format below. Provide a Python function in ...
-
[32]
strongly dislike
Traits Updates Identify key changes in personal characteristics: - hobbies (dictionary list): New activities discovered, abandoned hobbies, or modified hobby descriptions - personal_preferences (dictionary list): Changes in preference levels (Scale: "strongly dislike" to "strongly like") - lifestyle (dictionary): Significant modifications to daily routine...
-
[33]
event": event description (string) –
Current Status Updates Track the character’s current state and recent significant developments: - health_status (string): Update current physical and mental health condition - mood (string): Update current emotional state if significantly affected - ongoing_events (dictionary list): Significant events currently ongoing (work deadlines, trips). Outdated ev...
-
[34]
Extract Changes from Outcome: Identify all traits shifts and status changes
-
[35]
Compare with Current Profile: Review profile to identify attributes needing updates
-
[36]
Determine Update Operations: Specify add, modify, or remove operations
-
[37]
Generate Update Function: Create a Python function implementing changes
-
[38]
update":
Check function correctness: MUST NOT add new top-level keys or change JSON structure. Avoid replacing entire attribute with ’=’. Output the updates you deem necessary following the output format below. Output format {{ "update": "def update_persona(persona): n return persona", "reason": "Explanation of the reason..." }} Figure 14:Prompt for Traits & Statu...
-
[39]
reports" and
Analyze the event outcome thoroughly to determine which attachment types are logically relevant. For irrelevant categories, provide empty arrays. For "reports" and "notes", provide at most 2 items each
-
[40]
Ensure that there are no duplications or inconsistencies between attachments
-
[41]
utterance
Each "utterance" field should contain comprehensive instructions including format requirements, real details, and special formatting. Use professional, clear statements throughout in the first-person user perspective
-
[42]
Ensure all attachments are contextually appropriate and would realistically exist
-
[43]
Make attachments practically useful for the character’s situation. Provide your response in JSON format within the Output tags: <Output> [Generate the detailed attachment metadata JSON here] </Output> Figure 15:Prompt for Attachment Utterance Generation.The model identifies logical digital artifacts (emails, attachments) implied by the event outcome and g...
-
[44]
If the question contains factual errors, false premises, or contradicts the user’s state, explicitly point out the error and propose a compliant alternative
-
[45]
If the question cannot be answered based on the evidence, state that clearly
-
[46]
accuracy_score
Otherwise, answer the question directly based on the evidence. Answer: Figure 17:Prompt for Elaborative Real-world Questions.This template is used for real-world contextual reasoning questions likeHallucinationandMisleadingtypes. 27 LLM-as-Judge Evaluation Prompt You are an expert evaluator assessing an AI assistant’s answer against a reference answer. Qu...
-
[47]
CURRENT TOPIC
NO NEW FACTS: You are STRICTLY FORBIDDEN from inventing, assuming, or adding any factual details (events, names, places, times, objects) that are not explicitly stated in the "CURRENT TOPIC" text above
-
[48]
·Asking the assistant for advice or analysis based on the known facts
Deepen, Don’t Expand: Instead of adding new plot points, deepen the conversation by: ·Expressing your feelings or opinions about the facts already shared. ·Asking the assistant for advice or analysis based on the known facts. ·Clarifying or re-emphasizing a detail you already mentioned if the assistant misunderstood
-
[49]
CURRENT TOPIC
Stay within Boundaries: If you have shared all the factual details from the CURRENT TOPIC, do NOT make up more. Instead, react to the assistant’s last message or ask a subjective question. Your Follow-up Options Choose ONE approach: •Share Remaining Details: If there are specific facts in the "CURRENT TOPIC" you haven’t mentioned yet, share them now. •Rea...
-
[50]
Question Type Definition: {QUESTION DEFINITION}
-
[51]
What did I do
Relevant Evidence: {EVIDENCE} Guidelines Adhere to the following requirements to create the QA pairs: ### 1. Question Requirements -Consistency: Strictly follow the definition and challenging characteristics provided above. Contextualize temporally as of{DATE}. -Perspective: Use natural FIRST-PERSON tone (e.g., "What did I do..."). -Single-Target Focus: A...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.