Cross-Modal Clinical Knowledge Integration for Mammography Report Generation
Pith reviewed 2026-06-28 23:08 UTC · model grok-4.3
The pith
MammoRG generates mammography reports by simulating BI-RADS clinical reasoning in a two-stage process that first classifies multi-view images and then fine-tunes on terminology.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
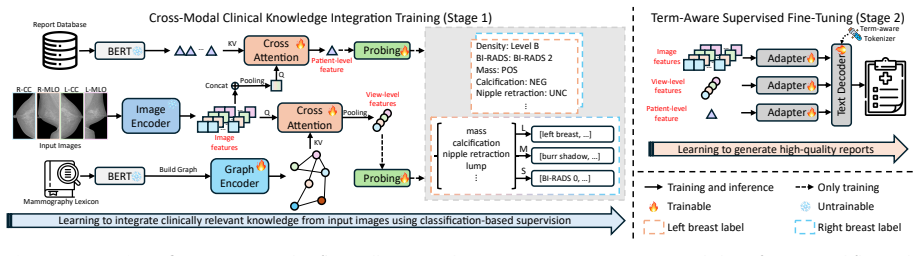
MammoRG adopts a two-stage training framework. In the first stage, the model learns to integrate clinically relevant prior knowledge from a patient's four-view mammograms through classification-based supervision. In the second stage, a terminology-aware supervised fine-tuning strategy is introduced to model mammography-specific clinical terms as atomic semantic units, enabling the generation of high-quality reports with improved clinical consistency.
What carries the argument
The two-stage training framework that follows the BI-RADS guideline by combining classification-based multi-view knowledge integration with terminology-aware supervised fine-tuning.
If this is right
- MammoRG produces higher BI-RADS F1 scores than prior methods, with gains of 2.73%, 2.04%, 1.90%, and 3.27% on the internal, external 1, external 2, and VinDr-Mammo datasets.
- Generated reports exhibit improved clinical consistency through explicit modeling of mammography-specific terms.
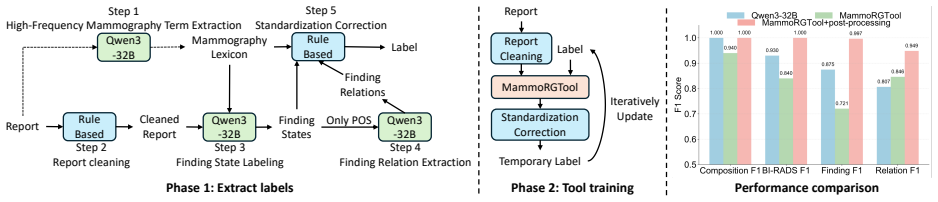
- MammoRGTool enables automated extraction of structured clinical information from free-text reports for quantitative evaluation.
- The framework reduces reliance on direct visual-to-text mapping by incorporating prior clinical knowledge from multiple views.
Where Pith is reading between the lines
- The classification supervision step may reduce factual errors in reports by grounding generation in explicit diagnostic categories before text production.
- Similar two-stage pipelines could be tested on other structured reporting tasks such as chest X-ray or pathology report generation.
- Performance on external datasets suggests the method may transfer across different imaging equipment and patient populations, though this would need separate confirmation.
Load-bearing premise
The two-stage training framework with classification-based supervision followed by terminology-aware supervised fine-tuning actually captures and simulates the structured clinical reasoning process followed by radiologists under the BI-RADS guideline.
What would settle it
A controlled test in which the BI-RADS F1 gains disappear when the second-stage terminology modeling is removed or when the model is evaluated on reports that do not follow BI-RADS structure.
Figures

read the original abstract
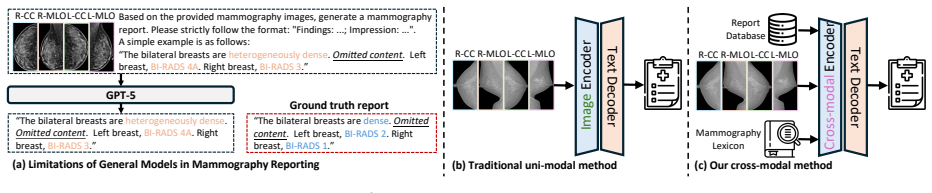
Breast cancer is a major global health concern, and mammography screening plays a central role in early detection. The large volume of screening examinations creates a substantial workload for radiologists, making accurate and consistent report generation a critical clinical challenge. Existing automated mammography report generation methods primarily focus on direct visual-to-text mapping, while overlooking the structured clinical reasoning process followed by radiologists in real-world practice. To address this limitation, we propose MammoRG, a mammography report generation framework that explicitly simulates the clinical reporting workflow by following the BI-RADS guideline and incorporating prior clinical knowledge to produce diagnostic reports. Specifically, MammoRG adopts a two-stage training framework. In the first stage, the model learns to integrate clinically relevant prior knowledge from a patient's four-view mammograms through classification-based supervision. In the second stage, a terminology-aware supervised fine-tuning strategy is introduced to model mammography-specific clinical terms as atomic semantic units, enabling the generation of high-quality reports with improved clinical consistency. To facilitate clinical efficacy evaluation of generated reports, we further develop MammoRGTool, a dedicated mammography report parsing tool that extracts structured clinical information from free-text reports. Extensive experiments demonstrate that MammoRG consistently outperforms existing methods across multiple clinical efficacy metrics, particularly in diagnosis-related BI-RADS F1, where it surpasses the second-best model by 2.73%, 2.04%, 1.90%, and 3.27% on the internal, external 1, external 2, and VinDr-Mammo datasets, respectively.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MammoRG, a two-stage mammography report generation framework that simulates BI-RADS-guided clinical reasoning: stage 1 uses classification-based supervision to integrate prior knowledge from four-view mammograms, and stage 2 applies terminology-aware supervised fine-tuning to treat clinical terms as atomic units. It introduces MammoRGTool to parse free-text reports for structured clinical metrics and claims consistent outperformance over baselines, with BI-RADS F1 gains of 2.73%, 2.04%, 1.90%, and 3.27% on the internal, external 1, external 2, and VinDr-Mammo datasets.
Significance. If the empirical gains hold under validated evaluation, the work could advance clinically aligned report generation by explicitly modeling structured diagnostic reasoning rather than direct visual-to-text mapping, with the dedicated parsing tool offering a step toward more meaningful efficacy assessment in medical imaging.
major comments (3)
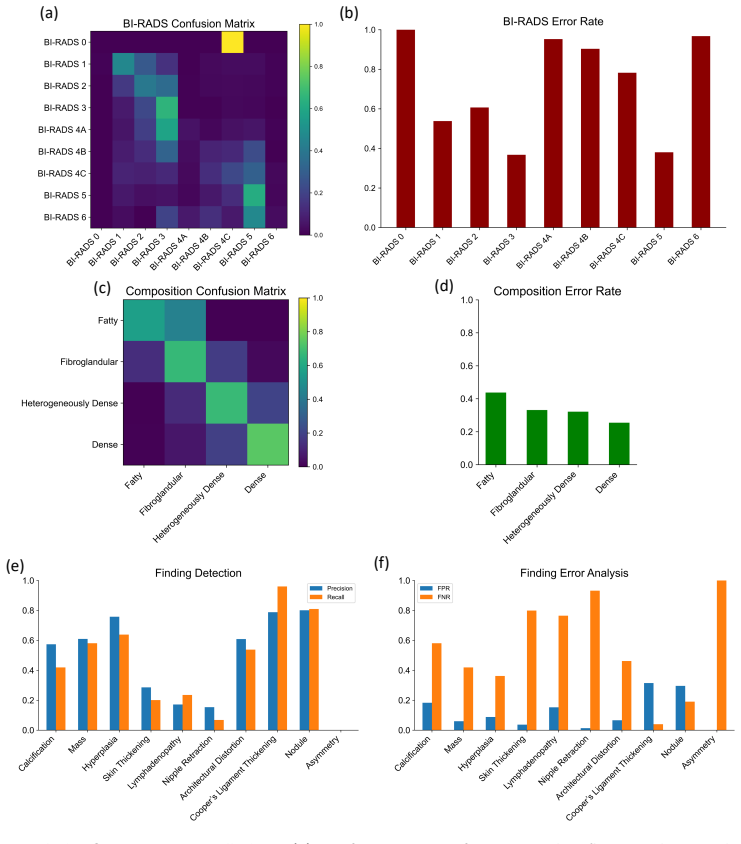
- [MammoRGTool description] MammoRGTool section: The tool is presented as extracting structured clinical information for BI-RADS F1 computation, yet no validation metrics (precision/recall/F1 against radiologist-annotated free-text reports on a held-out set) are reported. This is load-bearing for the central claim, as unvalidated parsing errors could artifactually inflate the reported 2-3% margins if they correlate with model outputs.
- [Experiments] Experiments section: No statistical significance tests, confidence intervals, or p-values are provided for the BI-RADS F1 and other metric differences, and baseline implementation details (e.g., exact architectures, training hyperparameters) are insufficiently specified to rule out confounding factors in the cross-dataset comparisons.
- [§3] §3 (two-stage framework): The claim that classification-based supervision followed by terminology-aware fine-tuning simulates radiologists' BI-RADS reasoning process lacks supporting ablations (e.g., vs. standard end-to-end fine-tuning) or qualitative analysis showing alignment with guideline-structured outputs, weakening attribution of gains to the proposed clinical integration.
minor comments (1)
- [Abstract] Abstract: Dataset sizes, BI-RADS category distributions, and exact number of views per case could be stated explicitly to aid quick assessment of experimental scope.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript accordingly to strengthen the presentation and evidence.
read point-by-point responses
-
Referee: [MammoRGTool description] MammoRGTool section: The tool is presented as extracting structured clinical information for BI-RADS F1 computation, yet no validation metrics (precision/recall/F1 against radiologist-annotated free-text reports on a held-out set) are reported. This is load-bearing for the central claim, as unvalidated parsing errors could artifactually inflate the reported 2-3% margins if they correlate with model outputs.
Authors: We agree that validation metrics for MammoRGTool are necessary to substantiate the BI-RADS F1 results. The current manuscript does not report precision, recall, or F1 against radiologist annotations on a held-out set. In the revised version, we will add these metrics from a dedicated validation study. revision: yes
-
Referee: [Experiments] Experiments section: No statistical significance tests, confidence intervals, or p-values are provided for the BI-RADS F1 and other metric differences, and baseline implementation details (e.g., exact architectures, training hyperparameters) are insufficiently specified to rule out confounding factors in the cross-dataset comparisons.
Authors: We acknowledge that statistical tests and fuller baseline details are missing. We will incorporate p-values, confidence intervals for all reported differences, and expanded specifications of baseline models and hyperparameters in the revised experiments section. revision: yes
-
Referee: [§3] §3 (two-stage framework): The claim that classification-based supervision followed by terminology-aware fine-tuning simulates radiologists' BI-RADS reasoning process lacks supporting ablations (e.g., vs. standard end-to-end fine-tuning) or qualitative analysis showing alignment with guideline-structured outputs, weakening attribution of gains to the proposed clinical integration.
Authors: While the two-stage design follows BI-RADS clinical workflow, we agree that ablations and qualitative evidence would better support attribution of gains. The revised manuscript will include comparisons against end-to-end fine-tuning baselines and qualitative report examples aligned with guideline structure. revision: yes
Circularity Check
No circularity: empirical claims rest on held-out dataset comparisons
full rationale
The paper's derivation consists of a two-stage training procedure (classification supervision then terminology-aware fine-tuning) followed by empirical evaluation on internal/external/VinDr-Mammo datasets using BI-RADS F1 and other metrics extracted via the authors' MammoRGTool. No equation, prediction, or central result is shown to reduce by construction to a fitted parameter or self-referential definition; the reported gains are presented as direct comparisons against baselines on held-out data. Any self-citations (if present) are not load-bearing for the performance claims, and the tool is introduced solely for evaluation rather than as part of a self-defining loop. This is the standard non-circular empirical pattern.
Axiom & Free-Parameter Ledger
free parameters (1)
- neural network parameters
axioms (1)
- domain assumption BI-RADS guideline defines a structured clinical reasoning process that can be simulated by classification supervision and terminology-aware fine-tuning
invented entities (1)
-
MammoRGTool
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Sequential reading effects in dutch screening mammography, in: Medical Imaging 2020: Image Perception, Observer Performance, and Technology Assessment, SPIE. pp. 66–70. de Avila Armenta, E., Bosques-Palomo, B., Ález, G.A.F.G., Monsivais-Molina, M.A., Garza-Abdala, J.A., Hussain, S., Vela-Jarquin, D., Cardona- Huerta, S., Ño-Avalos, D.B.A., Ña, J.G.T.P.,
2020
-
[2]
Qwen3-vl technical report. arXiv preprint arXiv:2511.21631 . Broeders, M., Moss, S., Nyström, L., Njor, S., Jonsson, H., Paap, E., Massat, N., Duffy, S., Lynge, E., Paci, E.,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Information Fusion 118, 102998
Mammovlm: A generative large vision–language model for mammography-related diagnostic assistance. Information Fusion 118, 102998. Chen,Z.,Song,Y.,Chang,T.H.,Wan,X.,2020. Generatingradiologyreportsviamemory-driventransformer,in:Proceedingsofthe2020Conference on Empirical Methods in Natural Language Processing. Devlin, J., Chang, M.W., Lee, K., Toutanova, K.,
2020
-
[4]
4171–4186
Bert: Pre-training of deep bidirectional transformers for language understanding, in: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, volume 1 (long and short papers), pp. 4171–4186. Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Che...
2019
-
[5]
arXiv preprint arXiv:2509.20271
A versatile foundation model for ai-enabled mammogram interpretation. arXiv preprint arXiv:2509.20271 . Irvin, J., Rajpurkar, P., Ko, M., Yu, Y., Ciurea-Ilcus, S., Chute, C., Marklund, H., Haghgoo, B., Ball, R., Shpanskaya, K., et al.,
-
[6]
Chexpert: A large chest radiograph dataset with uncertainty labels and expert comparison, in: Proceedings of the AAAI Conference on Artificial Intelligence, pp. 590–597. Jain,S.,Agrawal,A.,Saporta,A.,Truong,S.,Duong,D.N.D.N.,Bui,T.,Chambon,P.,Zhang,Y.,Lungren,M.,Ng,A.,Langlotz,C.,Rajpurkar,P.,Ra- jpurkar,P.,2021. Radgraph:Extractingclinicalentitiesandrela...
2021
-
[7]
Diseases of the Chest, Breast, Heart and Vessels 2019-2022: Diagnostic and Interventional Imaging ,
Diagnosis and staging of breast cancer: When and how to use mammography. Diseases of the Chest, Breast, Heart and Vessels 2019-2022: Diagnostic and Interventional Imaging ,
2019
-
[8]
7123–7138
Factual accuracy is not enough: Planning consistent description order for radiology report generation, in: Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pp. 7123–7138. Papineni, K., Roukos, S., Ward, T., Zhu, W.J.,
2022
-
[9]
Openai gpt-5 system card. arXiv preprint arXiv:2601.03267 . :Preprint submitted to Elsevier Page 15 of 16 Smit, A., Jain, S., Rajpurkar, P., Pareek, A., Ng, A.Y., Lungren, M.,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
1500–1519
Combining automatic labelers and expert annotations for accurate radiology report labeling using bert, in: Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 1500–1519. Spak, D.A., Plaxco, J., Santiago, L., Dryden, M., Dogan, B.,
2020
-
[11]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency. arXiv preprint arXiv:2508.18265 . Xu, W., Chan, H.P., Li, L., Aljunied, M., Yuan, R., Wang, J., Xiao, C., Chen, G., Liu, C., Li, Z., et al.,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Lingshu: A Generalist Foundation Model for Unified Multimodal Medical Understanding and Reasoning
Lingshu: A generalist foundation model for unified multimodal medical understanding and reasoning. arXiv preprint arXiv:2506.07044 . Yalunin, A., Sokolova, E., Burenko, I., Ponomarchuk, A., Puchkova, O., Umerenkov, D.,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Generating mammography reports from multi-view mammograms with bert, in: Findings of the Association for Computational Linguistics: EMNLP 2021, pp. 153–162. Yan, S., Cheung, W.K., Chiu, K., Tong, T.M., Cheung, K.C., See, S.,
2021
-
[14]
Qwen3 technical report. arXiv preprint arXiv:2505.09388 . Yang, S., Wu, X., Ge, S., Zheng, Z., Zhou, S.K., Xiao, L.,
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.