SpecDB: LLM-Generated Customized Databases via Feature-Oriented Decomposition
Pith reviewed 2026-06-28 20:33 UTC · model grok-4.3
The pith
LLMs can generate a workload-matched database that matches PostgreSQL throughput on TPC-C while using roughly three percent of the code.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
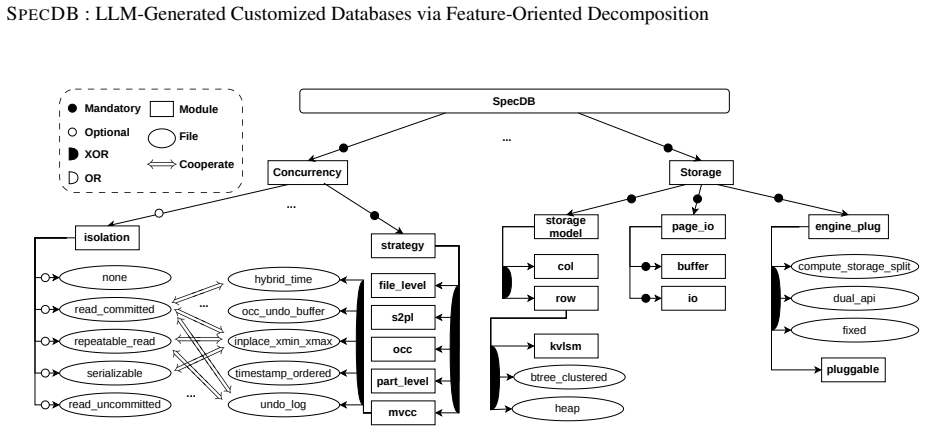
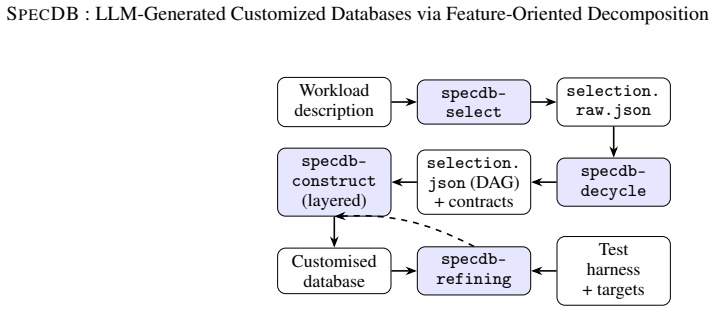
By surveying nine production databases, decomposing them into ten functional modules with multiple implementation variants, extending the FODA feature model with cooperate edges to capture cross-module constraints, and driving the resulting DBGraph with a layered agent pipeline plus an iterative refining agent, it is possible to synthesize from a natural-language workload description a complete, correct, and deployable relational database whose performance on TPC-C is comparable to established engines.
What carries the argument
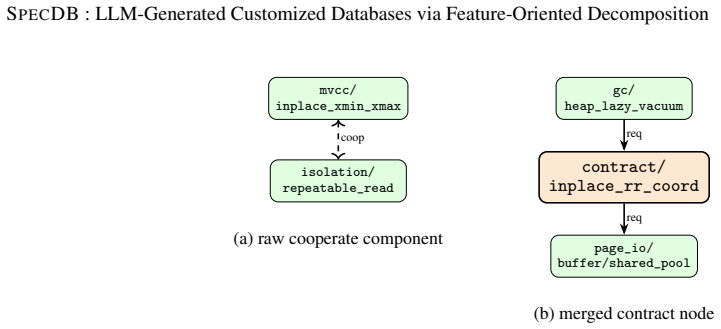
DBGraph, the dependency graph formed by extending the FODA feature model with cooperate edges that link implementation choices required to work together across modules.
If this is right
- A natural-language description of a workload can be translated directly into a ready-to-run database binary.
- Implementation techniques previously scattered across separate source trees can be combined inside one generated product.
- The final artifact can be orders of magnitude smaller than conventional database engines while retaining equivalent performance on the chosen workload.
- Iterative repair against a read-only harness can remove defects introduced during module assembly.
Where Pith is reading between the lines
- Workloads too narrow to justify a full commercial database might still receive a purpose-built implementation at low cost.
- The same decomposition and agent pipeline could be applied to other large, feature-rich software systems outside the database domain.
- Repeated regeneration of the database as workload characteristics change would become practical if LLM inference costs continue to fall.
Load-bearing premise
The LLM subagents and refining agent can produce and integrate module code that satisfies every cross-module dependency recorded in the model and passes the user-supplied validation harness without hidden defects.
What would settle it
A second independent workload description fed to the same pipeline produces a database that either fails to complete its benchmark or returns incorrect results on any transaction.
Figures

read the original abstract
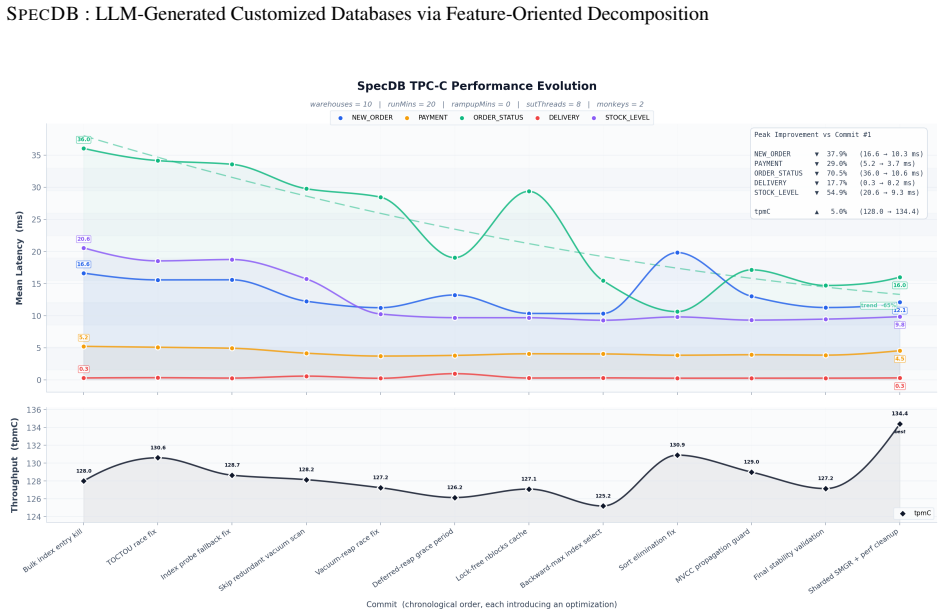
Mainstream relational databases ship a uniform feature set across deployments, although individual workloads exercise only a fraction of the available subsystems. We investigate whether a database can instead be generated on demand with a feature set matched to the target workload. We present SpecDB, a system that uses large language models (LLMs) to synthesize customized relational databases. We survey 9 production systems and decompose them into 10 functional modules, each further divided into implementation variants. To capture cross-module dependencies, including cases where implementations in disjoint subtrees must be co-designed, we adopt the FODA feature model and extend it with a cooperate edge, yielding a dependency graph DBGraph. SpecDB operationalizes DBGraph through a layered module-construction pipeline in which each module is generated, validated, and integrated by a dedicated subagent (driven by three inner agents: Main, Tester, Architect), and a Refining Agent that iteratively repairs and tunes the assembled database against a user-supplied refining harness with read-only access to existing database source code. A companion selection component translates a natural-language workload description into a set of implementation variants, providing an end-to-end pipeline from workload description to deployable database. We evaluate SpecDB on TPC-C with BenchmarkSQL. The generated database (23,779 lines of Rust) completes 60-minute TPC-C at 1 and 10 warehouses with zero errors. At 10 warehouses it reaches tpmC=130, compared to 128 for PostgreSQL and 127 for MySQL, with comparable latency at ~3% of their code size. Because the agent operates at module-specification level rather than product source, it can in principle combine techniques across system boundaries. Paired with falling LLM costs, generating a purpose-built database for a target workload is becoming straightforward.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that SpecDB uses LLMs to synthesize customized relational databases from natural-language workload descriptions. It decomposes 9 production systems into 10 modules with implementation variants, extends the FODA model with cooperate edges to form DBGraph for capturing cross-module dependencies, and employs a three-layer agent pipeline (Main/Tester/Architect per module plus a Refining Agent with read-only source access) to generate, validate, and iteratively repair a Rust implementation. On TPC-C with BenchmarkSQL, the resulting 23,779-line database completes 60-minute runs at 1 and 10 warehouses with zero errors, achieving tpmC=130 at 10 warehouses (vs. 128 for PostgreSQL and 127 for MySQL) with comparable latency at ~3% of their code size.
Significance. If the central empirical claim holds, the work would be significant for demonstrating an end-to-end pipeline from workload description to a deployable, high-performance database via LLM agents operating at the module-specification level. The DBGraph extension for co-design dependencies and the agent-based synthesis provide a concrete operationalization of feature-oriented database generation. The TPC-C result supplies a benchmark data point showing competitive throughput with dramatically reduced code size, which, paired with the reproducible construction approach, could stimulate further research on automated, workload-specific systems.
major comments (3)
- [Abstract] Abstract: The concrete TPC-C performance numbers (zero-error 60-min runs, tpmC=130 at 10 warehouses) are presented without any information on the number of experimental runs, statistical significance, variance, prompt engineering details, or failure modes of the subagents, leaving the central performance claim with only weak evidential grounding.
- [Refining Agent description] Section describing the Refining Agent: The manuscript states that the Refining Agent has only read-only access to existing source code and is driven by the same LLM family; this does not establish that subtle concurrency, transaction, or index-interaction defects violating DBGraph cooperate edges will be detected if they evade the BenchmarkSQL workload used for refinement.
- [Evaluation] Evaluation section: No details are supplied on how the refining harness was constructed or on any validation that cross-module dependencies captured by the extended FODA model are satisfied in the final generated code, which is load-bearing for the zero-error and tpmC claims.
minor comments (1)
- [Abstract] The abstract would benefit from explicitly stating the number of modules and variants surveyed from the 9 production systems to clarify the scope of the decomposition.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. The comments highlight important gaps in experimental reporting and validation details that we will address in revision. Below we respond point-by-point to the three major comments.
read point-by-point responses
-
Referee: [Abstract] Abstract: The concrete TPC-C performance numbers (zero-error 60-min runs, tpmC=130 at 10 warehouses) are presented without any information on the number of experimental runs, statistical significance, variance, prompt engineering details, or failure modes of the subagents, leaving the central performance claim with only weak evidential grounding.
Authors: We agree the current presentation provides insufficient experimental context. In the revised manuscript we will expand both the abstract and Evaluation section to report: (1) that a single end-to-end generation and single 60-minute TPC-C run per warehouse count was performed (due to the high cost of LLM-based synthesis and validation), (2) the specific prompt-engineering patterns used for the subagents, and (3) the main failure modes observed during iterative refinement (e.g., transaction isolation violations caught by the Tester agent). We will also note the absence of statistical significance testing as a limitation of the current evaluation. revision: yes
-
Referee: [Refining Agent description] Section describing the Refining Agent: The manuscript states that the Refining Agent has only read-only access to existing source code and is driven by the same LLM family; this does not establish that subtle concurrency, transaction, or index-interaction defects violating DBGraph cooperate edges will be detected if they evade the BenchmarkSQL workload used for refinement.
Authors: The observation is correct. The Refining Agent operates under read-only constraints and relies on the BenchmarkSQL workload to surface defects; it therefore cannot guarantee detection of all possible violations of DBGraph cooperate edges. We will revise the Refining Agent section to explicitly acknowledge this scope limitation and to clarify that the reported zero-error result holds only for the exercised BenchmarkSQL workload. We maintain that this is still a meaningful practical validation for a workload-specific database, but we will not claim exhaustive coverage of all cross-module interactions. revision: yes
-
Referee: [Evaluation] Evaluation section: No details are supplied on how the refining harness was constructed or on any validation that cross-module dependencies captured by the extended FODA model are satisfied in the final generated code, which is load-bearing for the zero-error and tpmC claims.
Authors: We accept that the Evaluation section lacks necessary detail on harness construction and dependency validation. In revision we will add: (1) a description of how the BenchmarkSQL refining harness was configured for the generated Rust database (including any required schema adaptations and connection parameters), and (2) the concrete checks performed by the Refining Agent and Architect agents to verify that DBGraph cooperate edges are respected in the assembled code. These additions will directly support the zero-error and performance claims. revision: yes
Circularity Check
No circularity: empirical system construction with direct benchmark measurement
full rationale
The paper presents an LLM-driven pipeline for synthesizing a customized database from a feature model (extended FODA/DBGraph) and reports direct empirical results on TPC-C via BenchmarkSQL. No equations, fitted parameters, predictions derived from inputs, or self-citation chains appear. The central claim (zero-error 60-min run at tpmC=130) is a measured outcome of the constructed artifact, not a reduction to prior definitions or fits. The reader's circularity score of 0.0 is confirmed; the work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The extended FODA model with cooperate edges is sufficient to capture all cross-module dependencies that affect correctness or performance in relational database implementations.
Reference graph
Works this paper leans on
-
[1]
https://www.postgresql.org/, 2026
PostgreSQL: The world’s most advanced open source relational database. https://www.postgresql.org/, 2026
2026
-
[2]
Accessed: 2025-12-28
Oracle Corporation.MySQL 8.0 Reference Manual, 2025. Accessed: 2025-12-28
2025
-
[3]
AutoAdmin project at Microsoft Research: Lessons learned.IEEE Data Engineering Bulletin, 34(3):12–19, 2011
Nicolas Bruno, Surajit Chaudhuri, Arnd Christian König, Vivek Narasayya, Ravi Ramamurthy, and Manoj Syamala. AutoAdmin project at Microsoft Research: Lessons learned.IEEE Data Engineering Bulletin, 34(3):12–19, 2011
2011
-
[4]
Gordon, and Bohan Zhang
Dana Van Aken, Andrew Pavlo, Geoffrey J. Gordon, and Bohan Zhang. Automatic database management system tuning through large-scale machine learning. InProceedings of the 2017 ACM International Conference on Management of Data (SIGMOD), pages 1009–1024, 2017
2017
-
[5]
Mowry, Matthew Perron, Ian Quah, Siddharth Santurkar, Anthony Tomasic, Skye Toor, Dana Van Aken, Ziqi Wang, Yingjun Wu, Ran Xian, and Tieying Zhang
Andrew Pavlo, Gustavo Angulo, Joy Arulraj, Haibin Lin, Jiexi Lin, Lin Ma, Prashanth Menon, Todd C. Mowry, Matthew Perron, Ian Quah, Siddharth Santurkar, Anthony Tomasic, Skye Toor, Dana Van Aken, Ziqi Wang, Yingjun Wu, Ran Xian, and Tieying Zhang. Self-driving database management systems. In8th Biennial Conference on Innovative Data Systems Research (CIDR), 2017
2017
-
[6]
Abadi, Stavros Harizopoulos, Nabil Hachem, and Pat Helland
Michael Stonebraker, Samuel Madden, Daniel J. Abadi, Stavros Harizopoulos, Nabil Hachem, and Pat Helland. The end of an architectural era (It’s Time for a Complete Rewrite). InProceedings of the 33rd International Conference on Very Large Data Bases (VLDB), pages 1150–1160, 2007
2007
-
[7]
Sharpen the spec, cut the code: A case for generative file system with {SYSSPEC}
Qingyuan Liu, Mo Zou, Hengbin Zhang, Dong Du, Yubin Xia, and Haibo Chen. Sharpen the spec, cut the code: A case for generative file system with {SYSSPEC}. In24th USENIX Conference on File and Storage Technologies (FAST 26), pages 291–311, 2026
2026
-
[8]
Un- veiling inefficiencies in llm-generated code: Toward a comprehensive taxonomy
Altaf Allah Abbassi, Leuson Da Silva, Amin Nikanjam, and Foutse Khomh. A taxonomy of inefficiencies in LLM-generated Python code. arXiv:2503.06327, 2025
-
[9]
How efficient is LLM-generated code? a rigorous & high-standard benchmark
Ruizhong Qiu, Weiliang Will Zeng, James Ezick, Christopher Lott, and Hanghang Tong. How efficient is LLM-generated code? a rigorous & high-standard benchmark. InThe Thirteenth International Conference on Learning Representations (ICLR), 2025
2025
-
[10]
Feature-oriented domain analysis (foda) feasibility study
Kyo C Kang, Sholom G Cohen, James A Hess, William E Novak, and A Spencer Peterson. Feature-oriented domain analysis (foda) feasibility study. Technical report, 1990
1990
-
[11]
Github copilot.https://github.com/features/copilot, 2026
2026
-
[12]
Claude.https://www.anthropic.com/claude, 2026
2026
-
[13]
Johannes Wehrstein, Timo Eckmann, Matthias Jasny, and Carsten Binnig. Bespoke OLAP: Synthesizing workload- specific one-size-fits-one database engines.Proceedings of the VLDB Endowment, 14(1), 2026. arXiv:2603.02001
-
[14]
ChatDev: Communicative agents for software development
Chen Qian, Wei Liu, Hongzhang Liu, Nuo Chen, Yufan Dang, Jiahao Li, Cheng Yang, Weize Chen, Yusheng Su, Xin Cong, Juyuan Xu, Dahai Li, Zhiyuan Liu, and Maosong Sun. ChatDev: Communicative agents for software development. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL), 2024
2024
-
[15]
MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework
Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Ceyao Zhang, Jinlin Wang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, Chenyu Ran, Lingfeng Xiao, Chenglin Wu, and Jürgen Schmidhuber. MetaGPT: Meta programming for a multi-agent collaborative framework. arXiv:2308.00352, 2023. 21 SPECDB : LLM-Generated Customized Databases ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, Ahmed Hassan Awadallah, Ryen W. White, Doug Burger, and Chi Wang. AutoGen: Enabling next-gen LLM applications via multi-agent conversation. arXiv:2308.08155, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
Reflexion: Language agents with verbal reinforcement learning
Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[18]
Teaching large language models to self-debug
Xinyun Chen, Maxwell Lin, Nathanael Schärli, and Denny Zhou. Teaching large language models to self-debug. InThe Twelfth International Conference on Learning Representations (ICLR), 2024
2024
-
[19]
".join(map(str, arr))] 10return
Tal Ridnik, Dedy Kredo, and Itamar Friedman. Code generation with AlphaCodium: From prompt engineering to flow engineering. arXiv:2401.08500, 2024
-
[20]
Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press
John Yang, Carlos E. Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. SWE-agent: Agent-computer interfaces enable automated software engineering. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[21]
BenchmarkSQL: Tpc-c benchmark tool.https://github.com/pgsql-io/benchmarksql, 2024
2024
-
[22]
Tpc-c.http://www.tpc.org/tpcc/, 2026
2026
-
[23]
Jones, Samuel Madden, Michael Stonebraker, Yang Zhang, John Hugg, and Daniel J
Robert Kallman, Hideaki Kimura, Jonathan Natkins, Andrew Pavlo, Alexander Rasin, Stanley Zdonik, Evan P.C. Jones, Samuel Madden, Michael Stonebraker, Yang Zhang, John Hugg, and Daniel J. Abadi. H-Store: A high- performance, distributed main memory transaction processing system.Proceedings of the VLDB Endowment, 1(2):1496–1499, 2008. A Per-database Extract...
2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.