NTR: Neural Token Reconstruction for Scene Token Bottleneck in End-to-End Driving
Pith reviewed 2026-06-28 22:55 UTC · model grok-4.3
The pith
A masked self-distillation reconstruction objective on scene tokens produces richer visual representations that improve end-to-end driving performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
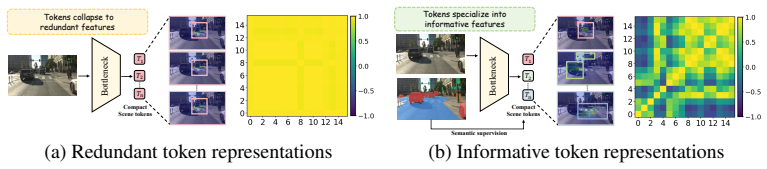
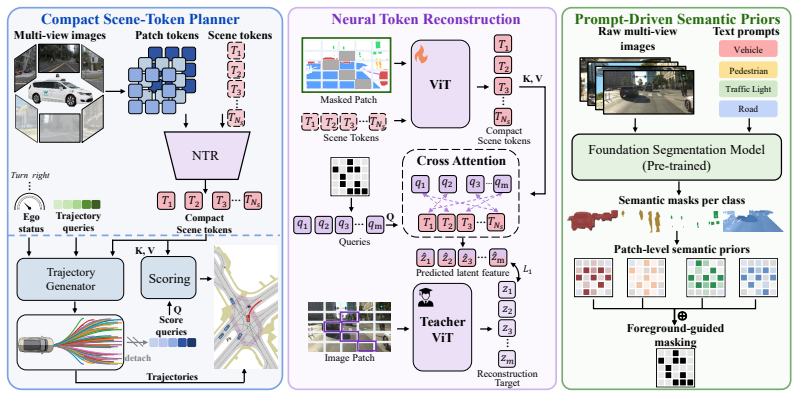
NTR constrains the scene-token bottleneck in perception-free E2E driving by a self-distillation masked latent reconstruction objective that reconstructs masked patch-level latent features using only the compact scene tokens as reconstruction memory. This forces reconstruction gradients to pass exclusively through the scene-token bottleneck, encouraging scene tokens to preserve richer and less redundant visual representations for planning. Weak semantic priors derived from foundation-model annotations bias reconstruction targets toward driving-related structures without introducing explicit perception heads. All auxiliary reconstruction components are removed at inference time.
What carries the argument
Neural Token Reconstruction (NTR) via self-distillation masked latent reconstruction objective that reconstructs masked patch latents using only scene tokens
If this is right
- Scene tokens exhibit lower pairwise redundancy and higher effective rank.
- Planning performance reaches 8.0461 RFS on Waymo E2E and 94.1 PDMS / 90.9 EPDMS on NavSim1&2.
- All auxiliary reconstruction components are removed at inference, leaving the deployed planner unchanged.
- Effective bottleneck supervision improves both compact visual representation learning and planning performance.
Where Pith is reading between the lines
- The same reconstruction pattern could be applied to other compressed token bottlenecks where downstream supervision is indirect.
- Token effective rank and redundancy metrics may serve as lightweight diagnostics for representation quality in other vision-planning systems.
- If foundation-model priors prove hard to obtain, simpler unsupervised reconstruction targets might still deliver part of the bottleneck improvement.
Load-bearing premise
Forcing reconstruction gradients to pass exclusively through the scene-token bottleneck will cause the tokens to preserve richer and less redundant visual representations that directly improve downstream planning.
What would settle it
An ablation removing only the masked reconstruction objective while keeping all other training elements fixed, followed by no change in planning scores or token redundancy metrics on the same benchmarks, would falsify the claim.
Figures

read the original abstract
Recent perception-free end-to-end (E2E) autonomous driving methods bypass explicit perception outputs by compressing dense image patch tokens into compact scene tokens for downstream trajectory generation and scoring. While these scene tokens form a compact visual bottleneck for the planner, they receive supervision solely from the planning objective, providing limited constraints on the encoded visual information. To address this limitation, we introduce Neural Token Reconstruction (NTR), a representation learning framework to directly constrain the compact scene-token bottleneck in perception-free driving. NTR introduces a self-distillation masked latent reconstruction objective that reconstructs masked patch-level latent features using only compact scene tokens as reconstruction memory. This forces reconstruction gradients to pass exclusively through the scene-token bottleneck, encouraging scene tokens to preserve richer and less redundant visual representations for planning. We further introduce semantic priors derived from foundation-model annotations as a weak semantic interface biasing reconstruction targets toward driving-related structures without introducing explicit perception heads. All auxiliary reconstruction components are removed at inference time, leaving the deployed planner unchanged. NTR achieves state-of-the-art performance on three public autonomous driving benchmarks, including 8.0461 RFS on Waymo E2E and 94.1 PDMS / 90.9 EPDMS on NavSim1&2. The learned scene tokens exhibit lower pairwise redundancy and higher effective rank, indicating that effective bottleneck supervision improves both compact visual representation learning and planning performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Neural Token Reconstruction (NTR), a self-distillation masked latent reconstruction objective that supervises the compact scene-token bottleneck in perception-free end-to-end autonomous driving. Scene tokens reconstruct masked patch-level latent features (using only the bottleneck as memory), with semantic priors from foundation-model annotations serving as weak targets; all auxiliary components are discarded at inference. The paper reports state-of-the-art results on three benchmarks (8.0461 RFS on Waymo E2E; 94.1 PDMS / 90.9 EPDMS on NavSim1&2) together with improved token statistics (lower pairwise redundancy, higher effective rank).
Significance. If the reported gains and token metrics hold under scrutiny, the work shows that an auxiliary reconstruction objective can enrich the visual information retained by a planning-only bottleneck without altering the deployed model. The mechanism is internally consistent: gradients are routed exclusively through the scene tokens, semantic priors act only as soft targets, and direct measurements of redundancy and rank provide supporting evidence beyond planning metrics alone. This addresses a clear limitation of prior perception-free E2E methods and could influence future bottleneck designs.
major comments (2)
- [§4] §4 (Experiments) and associated tables: the SOTA claims rest on single-run point estimates (e.g., 8.0461 RFS, 94.1 PDMS) without reported standard deviations, multiple random seeds, or statistical tests; this weakens the ability to attribute gains specifically to the NTR objective versus training variance.
- [§3.2, §4.3] §3.2 and §4.3: while token redundancy and effective-rank metrics are presented as evidence that the reconstruction objective improves representations, the manuscript does not include an ablation that isolates the masked latent reconstruction loss from the semantic-prior term; without this control it remains unclear which component drives the reported token-quality improvements.
minor comments (2)
- [§3.1] The description of the self-distillation target construction (how masked latents are generated and aligned) would benefit from an explicit equation or pseudocode block for reproducibility.
- [Figure 3] Figure 3 (token visualization) and the associated redundancy plots would be clearer with explicit axis labels and a statement of the exact distance metric used for pairwise redundancy.
Simulated Author's Rebuttal
We thank the referee for the positive assessment and constructive feedback. We address the two major comments point by point below.
read point-by-point responses
-
Referee: [§4] §4 (Experiments) and associated tables: the SOTA claims rest on single-run point estimates (e.g., 8.0461 RFS, 94.1 PDMS) without reported standard deviations, multiple random seeds, or statistical tests; this weakens the ability to attribute gains specifically to the NTR objective versus training variance.
Authors: We agree that single-run point estimates limit the strength of the SOTA claims and that variance estimates would better isolate the contribution of NTR from training stochasticity. End-to-end driving models are computationally expensive to train, which is why we initially reported single runs (a practice seen in several recent E2E driving papers). In the revision we will rerun the key experiments with at least three random seeds, report means and standard deviations, and add a brief statistical comparison where appropriate. revision: yes
-
Referee: [§3.2, §4.3] §3.2 and §4.3: while token redundancy and effective-rank metrics are presented as evidence that the reconstruction objective improves representations, the manuscript does not include an ablation that isolates the masked latent reconstruction loss from the semantic-prior term; without this control it remains unclear which component drives the reported token-quality improvements.
Authors: We acknowledge that the current manuscript lacks an ablation that separates the masked latent reconstruction loss from the semantic-prior term. The semantic priors are used only as soft targets to bias reconstruction toward driving-relevant structures; however, without the requested control experiment it is indeed difficult to quantify their individual impact on the token statistics. We will add this ablation (full NTR vs. reconstruction loss only) to §4.3 and update the corresponding discussion in the revised manuscript. revision: yes
Circularity Check
No significant circularity
full rationale
The paper describes an auxiliary masked latent reconstruction objective used only during training to supervise the scene-token bottleneck; this objective and all associated components are explicitly removed at inference time, leaving the planner unchanged. Performance claims rest on empirical SOTA metrics across external benchmarks plus post-hoc token statistics (pairwise redundancy, effective rank), none of which are defined in terms of the same fitted parameters or reduced to self-citations. No equations, uniqueness theorems, or ansatzes are shown to collapse the reported gains to quantities already present in the inputs. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard assumptions of gradient-based optimization in neural networks.
Reference graph
Works this paper leans on
-
[1]
End to End Learning for Self-Driving Cars
M. Bojarski, D. D. Testa, D. Dworakowski, B. Firner, B. Flepp, P. Goyal, L. D. Jackel, M. Mon- fort, U. Muller, J. Zhang, X. Zhang, J. Zhao, and K. Zieba. End to end learning for self-driving cars, 2016. URLhttps://arxiv.org/abs/1604.07316
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[2]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
F. Codevilla, E. Santana, A. Lopez, and A. Gaidon. Exploring the limitations of behavior cloning for autonomous driving. In2019 IEEE/CVF International Conference on Computer Vision (ICCV), pages 9328–9337, 2019. doi:10.1109/ICCV .2019.00942
- [3]
- [4]
-
[5]
L. Feng, Y . Gao, E. Zablocki, Q. Li, W. Li, S. Liu, M. Cord, and A. Alahi. RAP: 3d rasterization augmented end-to-end planning. InThe Fourteenth International Conference on Learning Representations, 2026. URLhttps://openreview.net/forum?id=a9bOgeqbdB
2026
-
[6]
Y . Hu, J. Yang, L. Chen, K. Li, C. Sima, X. Zhu, S. Chai, S. Du, T. Lin, W. Wang, L. Lu, X. Jia, Q. Liu, J. Dai, Y . Qiao, and H. Li. Planning-oriented autonomous driving. In2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 17853–17862, 2023. doi:10.1109/CVPR52729.2023.01712
-
[7]
In: IEEE/CVF International Conference on Computer Vision
B. Jiang, S. Chen, Q. Xu, B. Liao, J. Chen, H. Zhou, Q. Zhang, W. Liu, C. Huang, and X. Wang. Vad: Vectorized scene representation for efficient autonomous driving. In2023 IEEE/CVF International Conference on Computer Vision (ICCV), pages 8306–8316, Los Alamitos, CA, USA, Oct 2023. IEEE Computer Society. doi:10.1109/ICCV51070.2023.00766. URLhttps: //doi.i...
-
[8]
Jiang, S
B. Jiang, S. Chen, H. Gao, B. Liao, Q. Zhang, W. Liu, and X. Wang. V ADv2: End-to-end vectorized autonomous driving via probabilistic planning. InThe Fourteenth International Conference on Learning Representations, 2026. URLhttps://openreview.net/forum? id=0a4dA6eUHN
2026
-
[9]
Y . Li, Y . Wang, Y . Liu, J. He, L. Fan, and Z. Zhang. End-to-end driving with online trajectory evaluation via bev world model. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 27137–27146, October 2025
2025
-
[10]
W. Sun, X. Lin, Y . Shi, C. Zhang, H. Wu, and S. Zheng. Sparsedrive: End-to-end autonomous driving via sparse scene representation. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 8795–8801, 2025. doi:10.1109/ICRA55743.2025.11128800
- [11]
-
[12]
Y . Li, D. Yuan, H. Zhang, Y . Yang, and X. Luo. End to end autonomous driving via occu- pancy and motion flow. In2024 IEEE International Conference on Real-time Computing and Robotics (RCAR), pages 360–365, 2024. doi:10.1109/RCAR61438.2024.10670964
-
[13]
Kirby, A
E. Kirby, A. Boulch, Y . Xu, Y . Yin, G. Puy, E. Zablocki, A. Bursuc, S. Gidaris, R. Marlet, F. Bartoccioni, A.-Q. Cao, N. Samet, T.-H. VU, and M. Cord. Driving on registers. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 32058–32069, June 2026
2026
-
[14]
S. Ang, Y . Yang, C. Chen, and Y . Wang. CLOVER: Closed-loop value estimation and ranking for end-to-end autonomous driving planning.arXiv preprint arXiv:2605.15120, 2026. 9
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[15]
Q. Yu, M. Weber, X. Deng, X. Shen, D. Cremers, and L.-C. Chen. An image is worth 32 tokens for reconstruction and generation. InThe Thirty-eighth Annual Conference on Neural Informa- tion Processing Systems, 2024. URLhttps://openreview.net/forum?id=tOXoQPRzPL
2024
-
[16]
Bachmann, J
R. Bachmann, J. Allardice, D. Mizrahi, E. Fini, O. F. Kar, E. Amirloo, A. El-Nouby, A. Zamir, and A. Dehghan. Flextok: Resampling images into 1d token sequences of flex- ible length. InForty-second International Conference on Machine Learning, 2025. URL https://openreview.net/forum?id=DgdOkUUBzf
2025
-
[17]
Marouani, O
A. Marouani, O. Sim ´eoni, H. Jegou, P. Bojanowski, and H. V . V o. Revisiting [CLS] and patch token interaction in vision transformers. InThe Fourteenth International Conference on Learn- ing Representations, 2026. URLhttps://openreview.net/forum?id=xs9xwFphLy
2026
-
[18]
C. Shi, Y . Yu, and S. Yang. Vision transformers need more than registers. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 26328–26337, June 2026
2026
-
[19]
Oquab, T
M. Oquab, T. Darcet, T. Moutakanni, H. V . V o, M. Szafraniec, V . Khalidov, P. Fernandez, D. HAZIZA, F. Massa, A. El-Nouby, M. Assran, N. Ballas, W. Galuba, R. Howes, P.-Y . Huang, S.-W. Li, I. Misra, M. Rabbat, V . Sharma, G. Synnaeve, H. Xu, H. Jegou, J. Mairal, P. Labatut, A. Joulin, and P. Bojanowski. DINOv2: Learning robust visual features without s...
2024
-
[20]
Sim ´eoni, H
O. Sim ´eoni, H. V . V o, M. Seitzer, F. Baldassarre, M. Oquab, C. Jose, V . Khalidov, M. Szafraniec, S. E. Yi, M. Ramamonjisoa, F. Massa, D. HAZIZA, L. Wehrstedt, J. Wang, T. Darcet, T. Moutakanni, L. Sentana, C. Roberts, A. Vedaldi, J. Tolan, J. Brandt, C. Cou- prie, J. Mairal, H. Jegou, P. Labatut, and P. Bojanowski. DINOv3.Transactions on Machine Lear...
2026
-
[21]
Assran, Q
M. Assran, Q. Duval, I. Misra, P. Bojanowski, P. Vincent, M. Rabbat, Y . LeCun, and N. Ballas. Self-supervised learning from images with a joint-embedding predictive architecture. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 15619–15629, June 2023
2023
-
[22]
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
M. Assran, A. Bardes, D. Fan, Q. Garrido, R. Howes, M. Komeili, M. J. Muckley, A. Rizvi, C. Roberts, K. Sinha, A. Zholus, S. Arnaud, A. Gejji, A. Martin, F. R. Hogan, D. Dugas, P. Bojanowski, V . Khalidov, P. Labatut, F. Massa, M. Szafraniec, K. Krishnakumar, Y . Li, X. Ma, S. Chandar, F. Meier, Y . LeCun, M. Rabbat, and N. Ballas. V-jepa 2: Self-supervis...
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
URLhttps://doi.org/10.48550/arXiv.2506.09985
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2506.09985
-
[24]
M. K. Wozniak, L. Liu, Y . Cai, and P. Jensfelt. Prix: Learning to plan from raw pixels for end-to-end autonomous driving.IEEE Robotics and Automation Letters, 11:6400–6407, 2025
2025
-
[25]
Chitta, A
K. Chitta, A. Prakash, B. Jaeger, Z. Yu, K. Renz, and A. Geiger. Transfuser: Imitation with transformer-based sensor fusion for autonomous driving.IEEE transactions on pattern analy- sis and machine intelligence, 45(11):12878–12895, 2022
2022
-
[26]
Z. Li, W. Wang, H. Li, E. Xie, C. Sima, T. Lu, Y . Qiao, and J. Dai. Bevformer: Learning bird’s-eye-view representation from multi-camera images via spatiotemporal transformers. In S. Avidan, G. Brostow, M. Ciss´e, G. M. Farinella, and T. Hassner, editors,Computer Vision – ECCV 2022, pages 1–18, Cham, 2022. Springer Nature Switzerland. ISBN 978-3-031-20077- 9
2022
-
[27]
K. He, X. Chen, S. Xie, Y . Li, P. Doll ´ar, and R. Girshick. Masked autoencoders are scalable vision learners. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 16000–16009, June 2022. 10
2022
-
[28]
Z. Tong, Y . Song, J. Wang, and L. Wang. VideoMAE: Masked autoencoders are data-efficient learners for self-supervised video pre-training. In A. H. Oh, A. Agarwal, D. Belgrave, and K. Cho, editors,Advances in Neural Information Processing Systems, 2022. URLhttps: //openreview.net/forum?id=AhccnBXSne
2022
-
[29]
Baevski, W.-N
A. Baevski, W.-N. Hsu, Q. Xu, A. Babu, J. Gu, and M. Auli. data2vec: A general framework for self-supervised learning in speech, vision and language. In K. Chaudhuri, S. Jegelka, L. Song, C. Szepesvari, G. Niu, and S. Sabato, editors,Proceedings of the 39th Interna- tional Conference on Machine Learning, volume 162 ofProceedings of Machine Learning Resear...
2022
-
[30]
J. Zhou, C. Wei, H. Wang, W. Shen, C. Xie, A. Yuille, and T. Kong. Image BERT pre-training with online tokenizer. InInternational Conference on Learning Representations, 2022. URL https://openreview.net/forum?id=ydopy-e6Dg
2022
-
[31]
Y . Li, S. Shang, W. Liu, B. Zhan, H. Wang, Y . Wang, Y . Chen, X. Wang, AnYasong, C. Tang, L. Hou, L. Fan, and Z. Zhang. DriveVLA-w0: World models amplify data scaling law in au- tonomous driving. InThe Fourteenth International Conference on Learning Representations,
-
[32]
URLhttps://openreview.net/forum?id=plrGn3RdzN
-
[33]
Y . Chen, Y . Wang, and Z. Zhang. Drivinggpt: Unifying driving world modeling and planning with multi-modal autoregressive transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 26890–26900, October 2025
2025
-
[34]
J. Wang, G. Li, Z. Huang, C. Dang, H. Ye, Y . Han, and L. Chen. Vggdrive: Empowering vision-language models with cross-view geometric grounding for autonomous driving. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10954–10964, June 2026
2026
-
[35]
Zhang, H
Z. Zhang, H. Li, Y . Dai, Z. Zhu, L. Zhou, C. Liu, D. Wang, F. E. H. Tay, S. Chen, Z. Liu, Y . Liu, X. Li, and P. Zhou. From spatial to actions: Grounding vision-language-action model in spatial foundation priors. InThe Fourteenth International Conference on Learning Representations,
-
[36]
URLhttps://openreview.net/forum?id=fzmittHfq3
-
[37]
S. Zeng, X. Chang, M. Xie, X. Liu, Y . Bai, Z. Pan, M. Xu, and X. Wei. Futuresightdrive: Thinking visually with spatio-temporal cot for autonomous driving. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URLhttps://openreview. net/forum?id=fCirUh6FRb
2026
-
[38]
W. Song, Z. Zhou, H. Zhao, J. Chen, P. Ding, H. Yan, Y . Huang, F. Tang, D. Wang, and H. Li. Reconvla: Reconstructive vision-language-action model as effective robot perceiver.CoRR, abs/2508.10333, August 2025. URLhttps://doi.org/10.48550/arXiv.2508.10333
-
[39]
Carion, L
N. Carion, L. Gustafson, Y .-T. Hu, S. Debnath, R. Hu, D. S. Coll-Vinent, C. Ryali, K. V . Al- wala, H. Khedr, A. Huang, J. Lei, T. Ma, B. Guo, A. Kalla, M. Marks, J. Greer, M. Wang, P. Sun, R. R¨adle, T. Afouras, E. Mavroudi, K. Xu, T.-H. Wu, Y . Zhou, L. Momeni, R. HAZRA, S. Ding, S. Vaze, F. Porcher, F. Li, S. Li, A. Kamath, H. K. Cheng, P. Dollar, N. ...
2026
-
[40]
E. J. Hu, yelong shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen. LoRA: Low-rank adaptation of large language models. InInternational Conference on Learning Rep- resentations, 2022. URLhttps://openreview.net/forum?id=nZeVKeeFYf9. 11
2022
-
[42]
Dauner, M
D. Dauner, M. Hallgarten, T. Li, X. Weng, Z. Huang, Z. Yang, H. Li, I. Gilitschenski, B. Ivanovic, M. Pavone, A. Geiger, and K. Chitta. NA VSIM: Data-driven non-reactive au- tonomous vehicle simulation and benchmarking. InThe Thirty-eight Conference on Neu- ral Information Processing Systems Datasets and Benchmarks Track, 2024. URLhttps: //openreview.net/...
2024
-
[43]
W. Cao, M. Hallgarten, T. Li, D. Dauner, X. Gu, C. Wang, Y . Miron, M. Aiello, H. Li, I. Gilitschenski, B. Ivanovic, M. Pavone, A. Geiger, and K. Chitta. Pseudo-simulation for autonomous driving. In9th Annual Conference on Robot Learning, 2025. URLhttps: //openreview.net/forum?id=9uKL9FJBiz
2025
-
[44]
Loshchilov and F
I. Loshchilov and F. Hutter. Decoupled weight decay regularization. InInternational Con- ference on Learning Representations, 2019. URLhttps://openreview.net/forum?id= Bkg6RiCqY7
2019
- [45]
-
[46]
Available: https://arxiv.org/abs/2508.06571
A. Jiang, Y . Gao, Y . Wang, Z. Sun, S. Wang, Y . Heng, H. Sun, S. Tang, L. Zhu, J. Chai, J. Wang, Z. Gu, H. Jiang, and L. Sun. Irl-vla: Training an vision-language-action policy via reward world model, 2025. URLhttps://arxiv.org/abs/2508.06571
- [47]
- [48]
-
[49]
Y . Ma, Y . Cao, W. Ding, S. Zhang, Y . Wang, B. Ivanovic, M. Jiang, M. Pavone, and C. Xiao. dvlm-ad: Enhance diffusion vision-language-model for driving via controllable reasoning,
- [50]
-
[51]
Z. Zhou, T. Cai, S. Zhao, Y . Zhang, Z. Huang, B. Zhou, and J. Ma. Autovla: A vision-language- action model for end-to-end autonomous driving with adaptive reasoning and reinforcement fine-tuning.Advances in Neural Information Processing Systems, 38:27920–27956, 2026
2026
-
[52]
R. Xu, H. Lin, W. Jeon, H. Feng, Y . Zou, L. Sun, J. Gorman, E. Tolstaya, S. Tang, B. White, B. Sapp, M. Tan, J.-J. Hwang, and D. Anguelov. Wod-e2e: Waymo open dataset for end-to- end driving in challenging long-tail scenarios, 2025. URLhttps://arxiv.org/abs/2510. 26125
2025
- [53]
- [54]
-
[55]
Dauner, M
D. Dauner, M. Hallgarten, A. Geiger, and K. Chitta. Parting with misconceptions about learning-based vehicle motion planning. InConference on Robot Learning, pages 1268–1281. PMLR, 2023. 12
2023
-
[56]
K. Chitta, A. Prakash, B. Jaeger, Z. Yu, K. Renz, and A. Geiger. Transfuser: Imitation with transformer-based sensor fusion for autonomous driving.IEEE Transactions on Pattern Analy- sis and Machine Intelligence, 45(11):12878–12895, 2023. doi:10.1109/TPAMI.2022.3200245
-
[57]
B. Liao, S. Chen, H. Yin, B. Jiang, C. Wang, S. Yan, X. Zhang, X. Li, Y . Zhang, Q. Zhang, and X. Wang. Diffusiondrive: Truncated diffusion model for end-to-end autonomous driving. InProceedings of the Computer Vision and Pattern Recognition Conference (CVPR), pages 12037–12047, June 2025
2025
-
[58]
Z. Xing, X. Zhang, Y . Hu, B. Jiang, T. He, Q. Zhang, X. Long, and W. Yin. Goalflow: Goal- driven flow matching for multimodal trajectories generation in end-to-end autonomous driving. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 1602–1611, June 2025
2025
-
[59]
Y . Li, K. Xiong, X. Guo, F. Li, S. Yan, G. Xu, L. Zhou, L. Chen, H. Sun, B. Wang, G. Chen, H. Ye, W. Liu, and X. Wang. ReCogDrive: A reinforced cognitive framework for end-to-end autonomous driving. InInternational Conference on Learning Representations (ICLR), 2026
2026
-
[60]
Z. Li, Z. Yu, S. Lan, J. Li, J. Kautz, T. Lu, and J. M. Alvarez. Is ego status all you need for open-loop end-to-end autonomous driving? InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 14864–14873, June 2024
2024
-
[61]
R. Feng, N. Xi, D. Chu, R. Wang, Z. Deng, A. Wang, L. Lu, J. Wang, and Y . Huang. Artemis: Autoregressive end-to-end trajectory planning with mixture of experts for au- tonomous driving.IEEE Robotics and Automation Letters, 11(1):226–233, 2026. doi: 10.1109/LRA.2025.3632616
- [62]
-
[63]
W. Yao, Z. Li, S. Lan, Z. Wang, X. Sun, J. M. Alvarez, and Z. Wu. Drivesuprim: Towards precise trajectory selection for end-to-end planning.Proceedings of the AAAI Conference on Artificial Intelligence, 40:11910–11918, 03 2026. doi:10.1609/aaai.v40i14.38178
- [64]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.