MIMO: Multilingual Information Retrieval via Monolingual Objectives
Pith reviewed 2026-06-28 21:02 UTC · model grok-4.3
The pith
MIMO improves multilingual retrieval by anchoring student embeddings to an English teacher model through initial distillation then joint contrastive optimization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
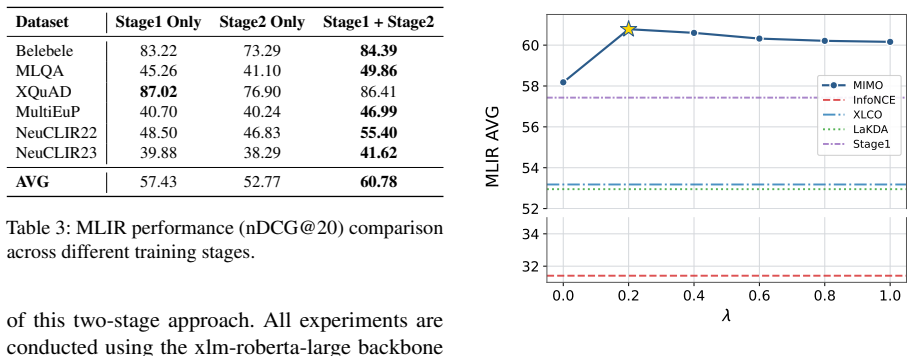
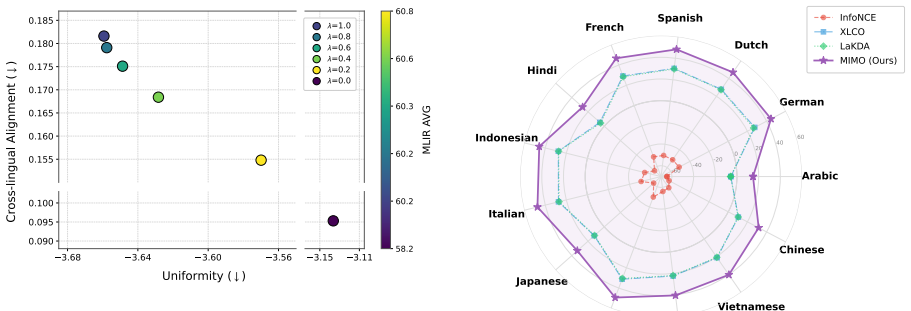
MIMO is a two-stage framework that initializes a student model’s cross-lingual alignment by distilling from a stable English semantic space supplied by a high-performing teacher, then jointly optimizes the distillation objective together with cross-lingual contrastive learning; the combination produces better retrieval discrimination while preserving alignment and yields a favorable alignment-uniformity trade-off.
What carries the argument
The two-stage MIMO process that first distills alignment from an English teacher model and then jointly optimizes distillation with cross-lingual contrastive loss.
If this is right
- MIMO outperforms existing cross-lingual training baselines on MLIR and Multi-Monolingual benchmarks.
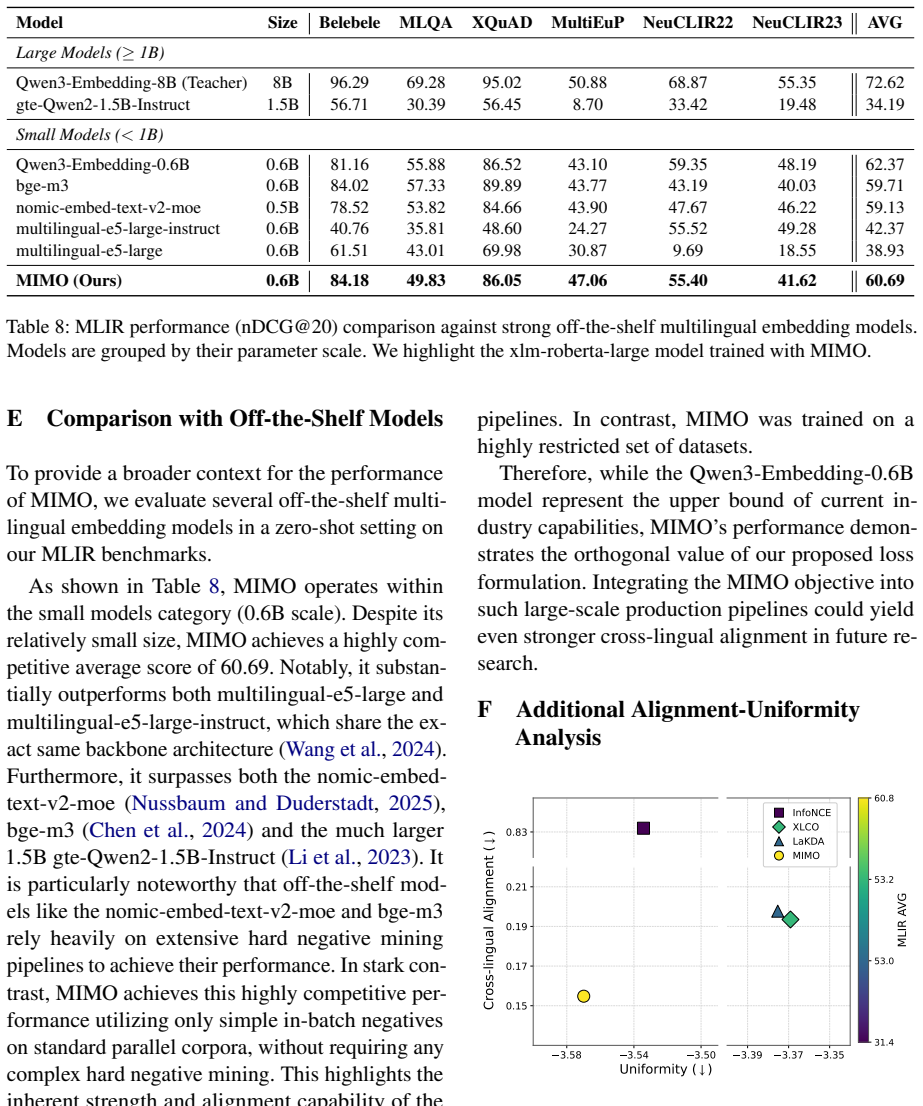
- MIMO stays competitive with off-the-shelf models of similar or larger parameter count.
- The joint use of distillation and contrastive loss produces a measurable improvement in the alignment-uniformity trade-off compared with either loss alone.
Where Pith is reading between the lines
- The same anchoring idea could be tested by substituting another high-resource language for English when a stronger teacher exists in that language.
- The framework may extend to other embedding objectives such as dense passage retrieval or sentence similarity where language clustering is also observed.
- If the English anchor proves critical, future work could explore whether progressively replacing it with a multilingual teacher after initial alignment preserves the gains.
Load-bearing premise
The English teacher model supplies a stable semantic space that can serve as an anchor without introducing language-specific biases that later limit cross-lingual discrimination.
What would settle it
If an otherwise identical training run that omits the English teacher anchor or replaces it with a different language anchor matches or exceeds MIMO’s MLIR benchmark scores, the necessity of the English anchor would be falsified.
Figures
read the original abstract
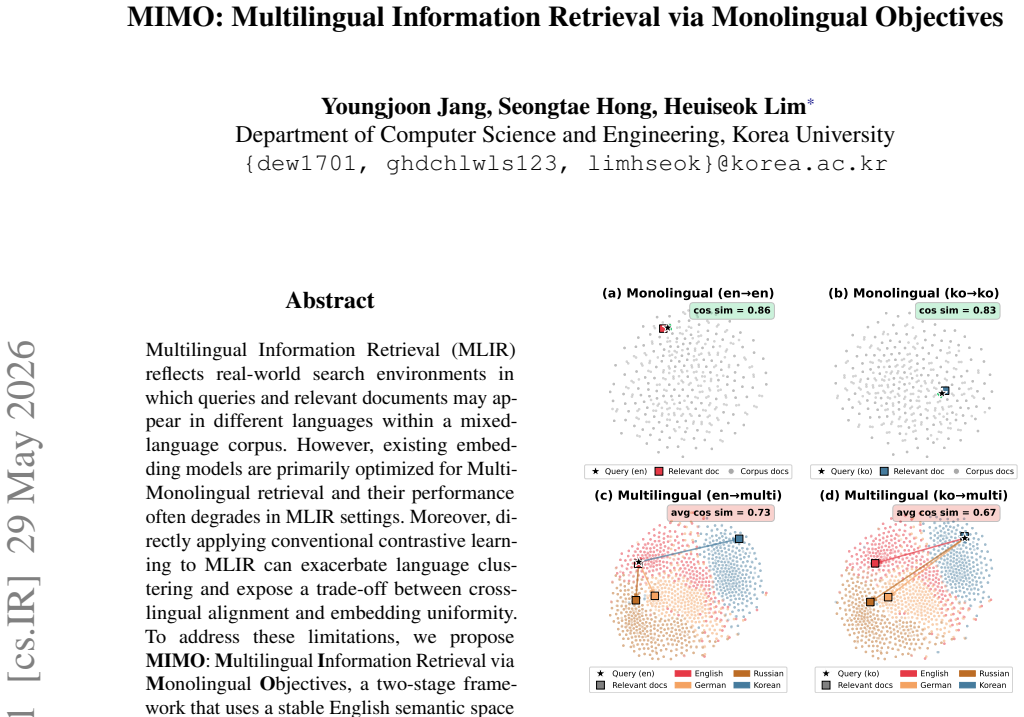
Multilingual Information Retrieval (MLIR) reflects real-world search environments in which queries and relevant documents may appear in different languages within a mixed-language corpus. However, existing embedding models are primarily optimized for Multi-Monolingual retrieval and their performance often degrades in MLIR settings. Moreover, directly applying conventional contrastive learning to MLIR can exacerbate language clustering and expose a trade-off between cross-lingual alignment and embedding uniformity. To address these limitations, we propose MIMO: Multilingual Information Retrieval via Monolingual Objectives, a two-stage framework that uses a stable English semantic space from a high-performing teacher model as an anchor. MIMO first initializes the student model's cross-lingual alignment through knowledge distillation, and then jointly optimizes distillation and cross-lingual contrastive learning to improve retrieval discrimination while preserving alignment. Extensive experiments show that MIMO consistently outperforms existing cross-lingual training baselines across various MLIR and Multi-Monolingual benchmarks. MIMO also remains competitive with off-the-shelf models of similar or larger parameter scales. Furthermore, our cross-lingual Alignment-Uniformity analysis clarifies the distinct roles of the two loss components and shows that their combination yields a favorable trade-off between alignment and uniformity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes MIMO, a two-stage framework for Multilingual Information Retrieval (MLIR) that initializes a student model via knowledge distillation from a high-performing English teacher to establish cross-lingual alignment, then jointly optimizes distillation with cross-lingual contrastive learning to enhance retrieval discrimination. The central claims are that MIMO consistently outperforms cross-lingual training baselines on MLIR and Multi-Monolingual benchmarks, remains competitive with off-the-shelf models of similar or larger scale, and yields a favorable alignment-uniformity trade-off whose distinct loss-component roles are clarified by the authors' analysis.
Significance. If the empirical results and analysis hold under scrutiny, the work addresses a practical gap in MLIR for mixed-language corpora by mitigating language clustering in contrastive objectives. The explicit decomposition of alignment versus uniformity contributions from each loss term offers a reusable diagnostic for multilingual embedding training and could inform more robust cross-lingual systems.
major comments (2)
- [Method (Section 3) and Experiments (Section 4)] The central claim that the English teacher supplies a stable, unbiased semantic anchor is load-bearing, yet the manuscript provides no direct test (e.g., controlled ablation on entity or topical granularity distinctions that are English-centric) showing that such biases are neutralized in non-English or mixed-language discrimination; the alignment-uniformity analysis in the experiments section does not address this.
- [Abstract and Experiments (Section 4)] The abstract asserts 'extensive experiments show consistent outperformance' and 'favorable alignment-uniformity trade-off' but supplies no quantitative results, error bars, dataset statistics, or ablation controls; without these, the data support for the outperformance claim cannot be verified from the provided text.
minor comments (2)
- Add explicit statements of the exact MLIR and Multi-Monolingual benchmarks, language pairs, and teacher model used so that the initialization and joint-optimization stages can be reproduced.
- Clarify notation for the two loss terms in the joint-optimization stage to avoid ambiguity when readers compare the alignment-uniformity plots.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We respond point-by-point to the major comments below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Method (Section 3) and Experiments (Section 4)] The central claim that the English teacher supplies a stable, unbiased semantic anchor is load-bearing, yet the manuscript provides no direct test (e.g., controlled ablation on entity or topical granularity distinctions that are English-centric) showing that such biases are neutralized in non-English or mixed-language discrimination; the alignment-uniformity analysis in the experiments section does not address this.
Authors: We acknowledge that the manuscript lacks a direct controlled ablation isolating English-centric biases at entity or topical granularity levels to demonstrate neutralization in non-English or mixed-language settings. The alignment-uniformity analysis examines loss-component contributions to alignment and uniformity but does not specifically test for such biases. We will revise Section 4 to include additional discussion of potential English-centric biases and their mitigation through the two-stage distillation-plus-contrastive process, along with any supporting indirect evidence from the MLIR benchmark results. revision: partial
-
Referee: [Abstract and Experiments (Section 4)] The abstract asserts 'extensive experiments show consistent outperformance' and 'favorable alignment-uniformity trade-off' but supplies no quantitative results, error bars, dataset statistics, or ablation controls; without these, the data support for the outperformance claim cannot be verified from the provided text.
Authors: We agree that the abstract would be strengthened by including key quantitative results to support the claims of outperformance and the alignment-uniformity trade-off. We will revise the abstract to incorporate specific performance metrics (e.g., relative improvements over baselines), references to error bars, dataset statistics, and ablation controls drawn from Section 4. revision: yes
Circularity Check
No significant circularity detected in MIMO framework
full rationale
The paper describes a two-stage training procedure (distillation initialization from English teacher followed by joint distillation + cross-lingual contrastive optimization) and an alignment-uniformity analysis that is presented as diagnostic rather than load-bearing for the performance claims. No equations, self-citations, or fitted-parameter renamings are quoted that reduce any prediction or uniqueness claim to the inputs by construction. The derivation chain remains self-contained against external benchmarks and experimental results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
On the cross-lingual transferability of mono- lingual representations.CoRR, abs/1910.11856. Yauhen Babakhin, Radek Osmulski, Ronay Ak, Gabriel Moreira, Mengyao Xu, Benedikt Schifferer, Bo Liu, and Even Oldridge. 2025. Llama-embed- nemotron-8b: A universal text embedding model for multilingual and cross-lingual tasks.Preprint, arXiv:2511.07025. Lucas Banda...
-
[2]
Multilingual E5 Text Embeddings: A Technical Report
Cosface: Large margin cosine loss for deep face recognition. InProceedings of the IEEE con- ference on computer vision and pattern recognition, pages 5265–5274. 10 Liang Wang, Nan Yang, Xiaolong Huang, Linjun Yang, Rangan Majumder, and Furu Wei. 2024. Multilin- gual e5 text embeddings: A technical report.arXiv preprint arXiv:2402.05672. Tongzhou Wang and ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Mr. TyDi: A multi-lingual benchmark for dense retrieval. InProceedings of the 1st Workshop on Multilingual Representation Learning, pages 127– 137, Punta Cana, Dominican Republic. Association for Computational Linguistics. Xinyu Zhang, Nandan Thakur, Odunayo Ogundepo, Ehsan Kamalloo, David Alfonso-Hermelo, Xi- aoguang Li, Qun Liu, Mehdi Rezagholizadeh, an...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Data Composition for InfoNCEFor InfoNCE, which uses monolingual pairs, each of the 14 lan- 2https://opus.nlpl.eu/ 12 guage pairs appear 29,710 times
ordered language pairs appear with equal fre- quency (2,286 times each, max-min difference of 1), resulting in equal 415,938 pairs. Data Composition for InfoNCEFor InfoNCE, which uses monolingual pairs, each of the 14 lan- 2https://opus.nlpl.eu/ 12 guage pairs appear 29,710 times. This uniform dis- tribution prevents any language pair from dominat- ing th...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.