Before Parc Ferm\'e: RL-Time Pruning for Efficient Embodied LLMs in Autonomous Driving
Pith reviewed 2026-06-28 21:59 UTC · model grok-4.3
The pith
Pruning embodied LLMs during RL training yields better size-to-performance trade-offs for autonomous driving than post-training methods or smaller models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
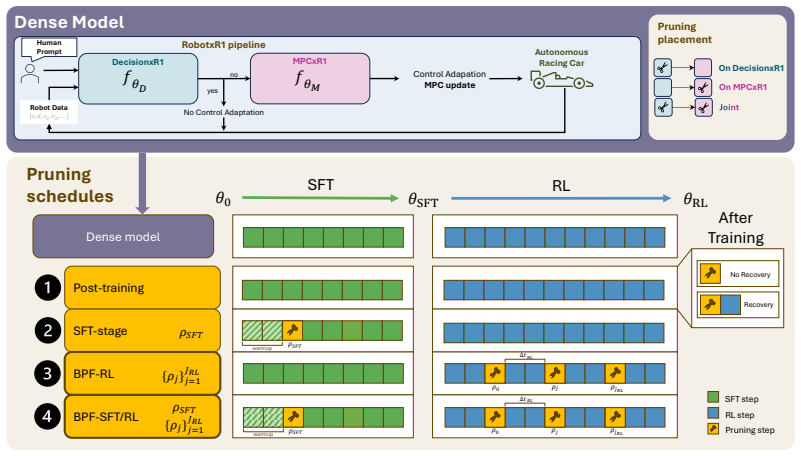
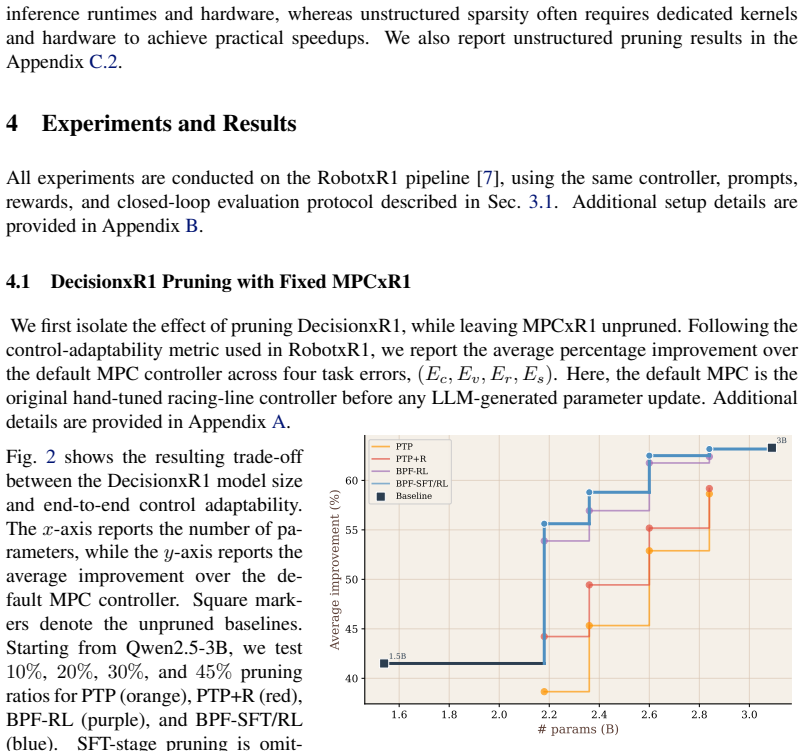
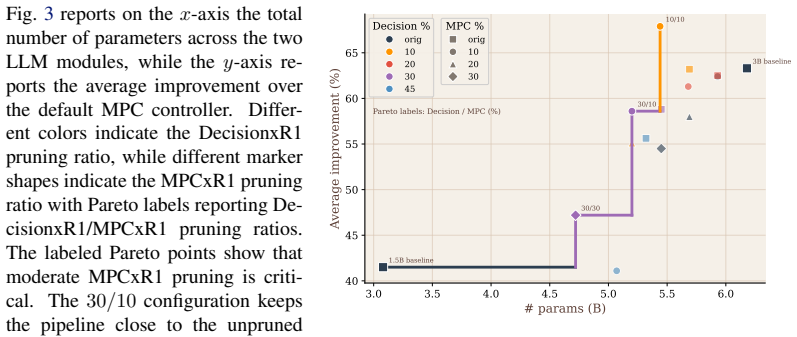
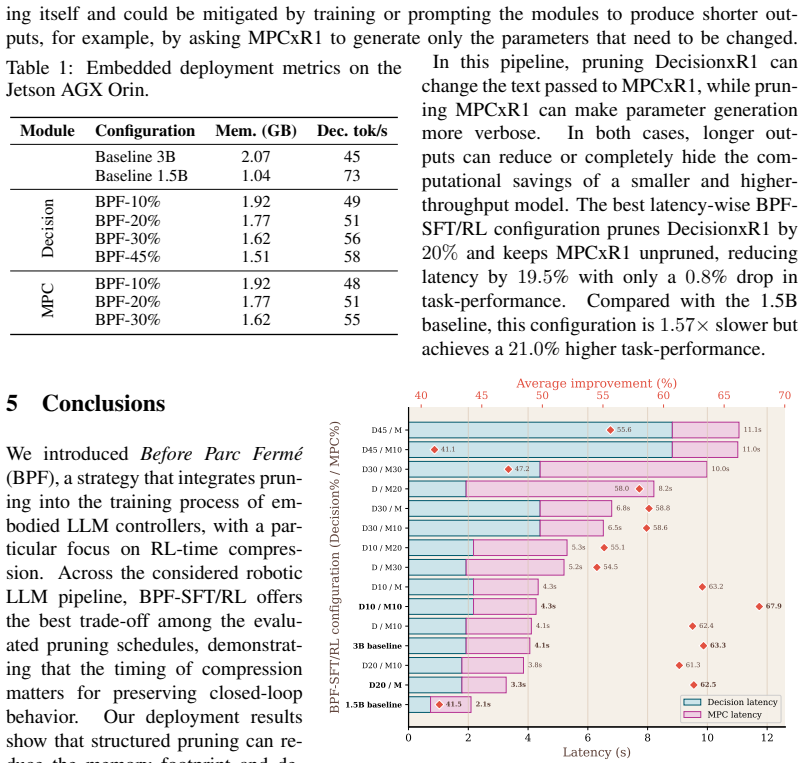
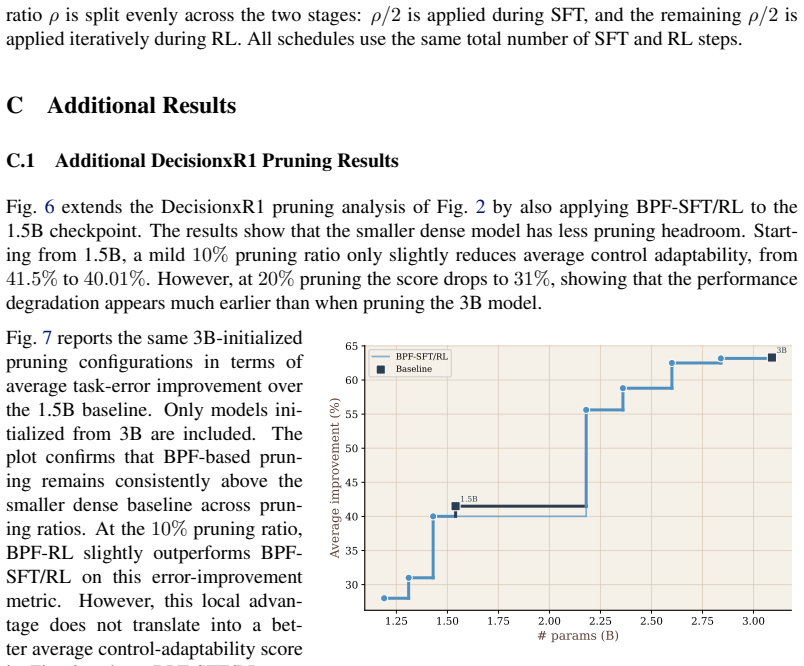
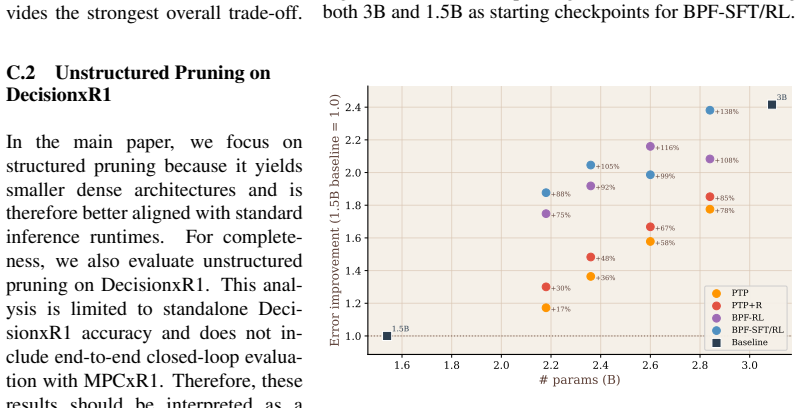
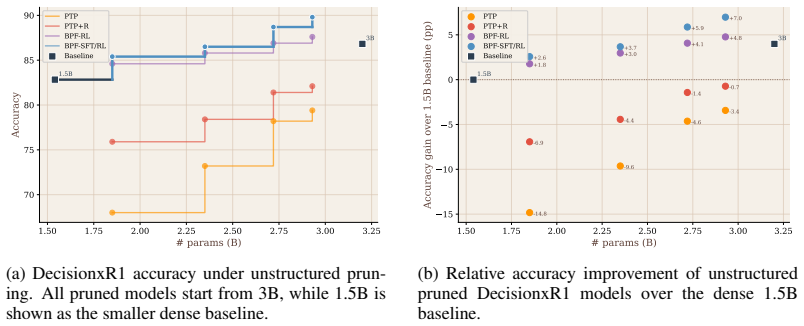
Before Parc Fermé (BPF) is a pruning strategy that compresses embodied LLM controllers during reinforcement learning so that pruning decisions can incorporate closed-loop task supervision and feedback. BPF-RL removes portions of the model at predefined intervals throughout RL, while BPF-SFT/RL first prunes during supervised fine-tuning and then continues the same iterative process during RL until the target ratio is reached. When evaluated on the RobotxR1 autonomous-driving pipeline using LLM-Pruner, BPF produces the best task-performance versus memory and throughput trade-off; BPF-SFT/RL achieves a 1.69 times better size-to-end-to-end-performance ratio than smaller dense models from the sam
What carries the argument
Before Parc Fermé (BPF), the iterative pruning strategy performed at predefined intervals during RL training (using LLM-Pruner) so that compression accounts for the closed-loop feedback that shapes the final controller.
If this is right
- Embodied LLM controllers can reach target compression levels while retaining more closed-loop driving capability than is possible with post-training pruning.
- Hardware deployment on embedded platforms gains higher generation throughput for a given level of control adaptability.
- Larger base models become preferable to training smaller dense models from scratch when the goal is an efficient final controller.
- The pruning schedule can be integrated into existing RL pipelines for embodied agents without separate recovery stages.
Where Pith is reading between the lines
- The same during-RL pruning schedule could be tested on other embodied tasks such as manipulation or multi-agent coordination to check whether the timing benefit generalizes beyond driving.
- Developers might explore using performance feedback during deployment to trigger additional light pruning steps without full retraining.
- If the method scales, it could reduce the number of separately trained model sizes needed for different hardware constraints in robotic fleets.
Load-bearing premise
Iterative pruning decisions made during RL will preserve closed-loop driving performance better than post-training pruning or SFT-only pruning without the need for extensive hyperparameter retuning after each pruning step.
What would settle it
A head-to-head measurement on the same RobotxR1 models showing that post-training pruning followed by RL recovery removes at least as many parameters per lost point of control adaptability as BPF-SFT/RL.
Figures


read the original abstract
Embodied Large Language Models (LLMs) are increasingly used as reasoning modules in robotic control pipelines to improve human-robot interaction, but their memory and generation latency make real-time deployment difficult. Pruning can reduce these costs, but for controllers that undergo multiple pre- and post-training phases, the crucial question is not only how much to prune, but when pruning should occur. In this work, we propose Before Parc Ferm\'e (BPF), a pruning strategy performed during RL that compresses embodied LLM controllers while they are still being optimized for closed-loop behavior. This allows pruning decisions to account for the task-specific supervision and closed-loop feedback that shape the final controller. We propose two variants: BPF-RL, which performs iterative pruning during RL by removing part of the model at predefined training intervals, and BPF-SFT/RL, which first prunes part of the model structure during SFT and then further compresses it during RL using the same iterative strategy as BPF-RL until the target pruning ratio is reached. We evaluate BPF on RobotxR1, an LLM-based autonomous-driving control pipeline, using an established LLM pruning framework (LLM-Pruner), and compare it against post-training pruning, post-training pruning with RL recovery, SFT-stage pruning, and smaller dense models from the same family. Our results show that BPF provides the best task-performance vs. memory and throughput trade-off among the considered pruning strategies. When compressing the larger RobotxR1 models, BPF-SFT/RL achieves a $1.69\times$ better size-end-to-end performance trade-off than directly selecting a smaller dense model from the same family, measured as removed parameters per lost percentage point of control adaptability. On the Jetson AGX Orin mounted on the target robotic platform, the compact models improve decode throughput by up to $27\%$.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Before Parc Fermé (BPF), a pruning strategy for embodied LLMs in autonomous driving that performs iterative pruning (via LLM-Pruner) during the RL optimization phase rather than post-training. It evaluates two variants—BPF-RL and BPF-SFT/RL—on the RobotxR1 pipeline against post-training pruning, post-training pruning with RL recovery, SFT-stage pruning, and smaller dense models from the same family, claiming the best task-performance vs. memory/throughput trade-off and a specific 1.69× advantage in removed-parameters-per-lost-adaptability for BPF-SFT/RL over smaller dense baselines, plus up to 27% decode throughput gains on Jetson AGX Orin.
Significance. If the empirical trade-off results prove robust under matched compute and hyperparameter controls, the approach could meaningfully advance practical compression of LLM-based robotic controllers by leveraging task-specific closed-loop feedback during pruning. The core idea of timing structural changes to coincide with RL adaptation is a clear conceptual contribution, though its advantage over standard post-training methods remains to be isolated.
major comments (2)
- [Experiments section] Experiments section: The 1.69× size-end-to-end performance trade-off for BPF-SFT/RL versus smaller dense models is presented without an ablation that holds total RL gradient steps, learning-rate schedules, and optimizer state constant across pruning conditions and baselines. This leaves open the possibility that observed gains arise from unequal optimization effort or recovery-phase differences rather than from the timing of pruning decisions themselves.
- [Method description of BPF-RL and BPF-SFT/RL] Method description of BPF-RL and BPF-SFT/RL: Iterative pruning at predefined RL intervals is described without specifying whether reward scaling, policy gradient clipping, or learning-rate warm-up is adjusted after each structural change; if the RL optimizer is sensitive to sudden capacity drops, this could confound attribution of closed-loop performance preservation to the BPF timing strategy.
minor comments (2)
- [Abstract] Abstract: The phrase 'removed parameters per lost percentage point of control adaptability' is introduced without a precise definition or reference to the exact metric formula used in the 1.69× calculation.
- The manuscript would benefit from explicit reporting of the number of random seeds and error bars on all closed-loop driving metrics to support the reliability of the reported trade-offs.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. The points raised regarding experimental controls and method details are well-taken, and we address each below with clarifications and proposed revisions.
read point-by-point responses
-
Referee: [Experiments section] Experiments section: The 1.69× size-end-to-end performance trade-off for BPF-SFT/RL versus smaller dense models is presented without an ablation that holds total RL gradient steps, learning-rate schedules, and optimizer state constant across pruning conditions and baselines. This leaves open the possibility that observed gains arise from unequal optimization effort or recovery-phase differences rather than from the timing of pruning decisions themselves.
Authors: We agree that an explicit ablation matching total RL gradient steps, learning-rate schedules, and optimizer state would strengthen isolation of the pruning-timing effect. In the original experiments, all conditions (including smaller dense baselines) used the same total RL steps and base hyperparameter schedules as detailed in Section 4, with pruning occurring at fixed intervals during those steps. To directly address the concern, the revised manuscript will include a new ablation that equalizes total optimization effort by extending the post-pruning recovery phase for BPF variants to match the full step count of the dense baselines. revision: yes
-
Referee: [Method description of BPF-RL and BPF-SFT/RL] Method description of BPF-RL and BPF-SFT/RL: Iterative pruning at predefined RL intervals is described without specifying whether reward scaling, policy gradient clipping, or learning-rate warm-up is adjusted after each structural change; if the RL optimizer is sensitive to sudden capacity drops, this could confound attribution of closed-loop performance preservation to the BPF timing strategy.
Authors: In the reported experiments, reward scaling, policy gradient clipping, and learning-rate warm-up were not modified after each pruning step; the original schedules were retained to test adaptation under the BPF timing alone. We will revise the method description of BPF-RL and BPF-SFT/RL to explicitly document this choice and note that no per-pruning hyperparameter retuning was performed. revision: yes
Circularity Check
No circularity: empirical trade-off claims rest on measured metrics, not self-referential derivations
full rationale
The paper proposes BPF pruning variants and evaluates them via direct comparisons of task performance, memory footprint, throughput, and a derived size-end-to-end performance metric (removed parameters per lost adaptability point) against post-training pruning, SFT-only pruning, and smaller dense baselines. No equations, fitted parameters presented as predictions, self-citations as load-bearing uniqueness theorems, or ansatzes smuggled via prior work appear in the abstract or method description. The 1.69× claim is computed from observed experimental outcomes rather than reducing to the input data or method definition by construction. The work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
M. Ahn, A. Brohan, N. Brown, Y . Chebotar, O. Cortes, B. David, C. Finn, K. Gopalakrishnan, K. Hausman, A. Herzog, D. Ho, J. Hsu, J. Ibarz, B. Ichter, A. Irpan, E. Jang, R. M. J. Ru- ano, K. Jeffrey, S. Jesmonth, N. J. Joshi, R. C. Julian, D. Kalashnikov, Y . Kuang, K.-H. Lee, S. Levine, Y . Lu, L. Luu, C. Parada, P. Pastor, J. Quiambao, K. Rao, J. Rettin...
2022
-
[2]
Liang, W
J. Liang, W. Huang, F. Xia, P. Xu, K. Hausman, B. Ichter, P. R. Florence, and A. Zeng. Code as policies: Language model programs for embodied control.2023 IEEE Interna- tional Conference on Robotics and Automation (ICRA), pages 9493–9500, 2022. URL https://api.semanticscholar.org/CorpusID:252355542
2023
-
[3]
Huang, F
W. Huang, F. Xia, T. Xiao, H. Chan, J. Liang, P. Florence, A. Zeng, J. Tompson, I. Mordatch, Y . Chebotar, P. Sermanet, T. Jackson, N. Brown, L. Luu, S. Levine, K. Hausman, and brian ichter. Inner monologue: Embodied reasoning through planning with language models. In6th Annual Conference on Robot Learning, 2022. URLhttps://openreview.net/forum?id= 3R3Pz5i0tye
2022
-
[4]
C. H. Song, J. Wu, C. Washington, B. M. Sadler, W.-L. Chao, and Y . Su. Llm-planner: Few- shot grounded planning for embodied agents with large language models.2023 IEEE/CVF International Conference on Computer Vision (ICCV), pages 2986–2997, 2022. URLhttps: //api.semanticscholar.org/CorpusID:254408960
2023
-
[5]
Ismail, A
S. Ismail, A. Arbues, R. Cotterell, R. Zurbr ¨ugg, and C. A. Alonso. Narrate: Versatile language architecture for optimal control in robotics.2024 IEEE/RSJ International Con- ference on Intelligent Robots and Systems (IROS), pages 9628–9635, 2024. URLhttps: //api.semanticscholar.org/CorpusID:268513494
2024
- [6]
-
[7]
Boyle, N
L. Boyle, N. Baumann, P. Sivasothilingam, M. Magno, and L. Benini. Robotxr1: Enabling embodied robotic intelligence on large language models through closed-loop reinforcement learning. In9th Annual Conference on Robot Learning, 2025. URLhttps://openreview. net/forum?id=Ggu7Hh2xnn
2025
-
[8]
D. Guo, D. Yang, H. Zhang, J. Song, P. Wang, Q. Zhu, R. Xu, R. Zhang, S. Ma, X. Bi, X. Zhang, et al. Deepseek-r1 incentivizes reasoning in llms through reinforcement learning. Nature, 645(8081):633–638, 2025. ISSN 1476-4687. doi:10.1038/s41586-025-09422-z. URL http://dx.doi.org/10.1038/s41586-025-09422-z
-
[9]
B. Hui, J. Yang, Z. Cui, J. Yang, D. Liu, L. Zhang, T. Liu, J. Zhang, B. Yu, K. Lu, et al. Qwen2. 5-coder technical report.arXiv preprint arXiv:2409.12186, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Z. Xu, Y . Zhang, E. Xie, Z. Zhao, Y . Guo, K.-Y . K. Wong, Z. Li, and H. Zhao. Drivegpt4: Interpretable end-to-end autonomous driving via large language model.IEEE Robotics and Automation Letters, 9:8186–8193, 2023. URLhttps://api.semanticscholar.org/ CorpusID:263605524. 9
2023
-
[11]
C. Sima, K. Renz, K. Chitta, L. Chen, H. Zhang, C. Xie, P. Luo, A. Geiger, and H. Li. Drivelm: Driving with graph visual question answering. InEuropean Conference on Computer Vision,
-
[12]
URLhttps://api.semanticscholar.org/CorpusID:266435584
-
[13]
C. Cui, Y . Ma, X. Cao, W. Ye, and Z. Wang. Drive as you speak: Enabling human-like inter- action with large language models in autonomous vehicles.2024 IEEE/CVF Winter Confer- ence on Applications of Computer Vision Workshops (WACVW), pages 902–909, 2023. URL https://api.semanticscholar.org/CorpusID:262054629
2024
-
[14]
N. Baumann, C. Hu, P. Sivasothilingam, H. Qin, L. Xie, M. Magno, and L. Benini. Enhanc- ing autonomous driving systems with on-board deployed large language models, 2025. URL https://arxiv.org/abs/2504.11514
-
[15]
arXiv preprint arXiv:2301.00774 , year=
E. Frantar and D. Alistarh. SparseGPT: Massive language models can be accurately pruned in one-shot.arXiv preprint arXiv:2301.00774, 2023
-
[16]
M. Sun, Z. Liu, A. Bair, and J. Z. Kolter. A simple and effective pruning approach for large language models. InThe Twelfth International Conference on Learning Representations, 2024. URLhttps://openreview.net/forum?id=PxoFut3dWW
2024
-
[17]
X. Ma, G. Fang, and X. Wang. LLM-pruner: On the structural pruning of large language models. InThirty-seventh Conference on Neural Information Processing Systems, 2023. URL https://openreview.net/forum?id=J8Ajf9WfXP
2023
-
[18]
Y . An, X. Zhao, T. Yu, M. Tang, and J. Wang. Fluctuation-based adaptive structured pruning for large language models. InAAAI Conference on Artificial Intelligence, 2023. URLhttps: //api.semanticscholar.org/CorpusID:266362404
2023
-
[19]
Ashkboos, M
S. Ashkboos, M. L. Croci, M. G. do Nascimento, T. Hoefler, and J. Hensman. SliceGPT: Compress large language models by deleting rows and columns. InThe Twelfth International Conference on Learning Representations, 2024. URLhttps://openreview.net/forum? id=vXxardq6db
2024
-
[20]
G. Yao, Y . Wang, W. Zhang, X. Deng, C. Du, R. Han, Z. Qin, Y . Li, B. Xie, B. Dong, H. Peng, S. Zhu, L. Zhang, Z. Wang, and Z. Zhang. Rl-pruner: Retraining-free global exploration pruning method based on reinforcement learning. In2025 International Joint Conference on Neural Networks (IJCNN), pages 1–8, 2025. doi:10.1109/IJCNN64981.2025.11228409
-
[21]
M. Xia, T. Gao, Z. Zeng, and D. Chen. Sheared LLaMA: Accelerating language model pre- training via structured pruning. InWorkshop on Advancing Neural Network Training: Com- putational Efficiency, Scalability, and Resource Optimization (WANT@NeurIPS 2023), 2023. URLhttps://openreview.net/forum?id=6s77hjBNfS
2023
- [22]
-
[23]
B. Wang, R. Pan, S. Diao, X. Pan, J. Zhang, R. Pi, and T. Zhang. Adapt-pruner: Adaptive structural pruning for efficient small language model training.CoRR, abs/2502.03460, Febru- ary 2025. URLhttps://doi.org/10.48550/arXiv.2502.03460
-
[24]
B. Wang and V . Kindratenko. Rl-pruner: Structured pruning using reinforcement learning for cnn compression and acceleration, 2024. URLhttps://arxiv.org/abs/2411.06463
-
[25]
Y . Wang, M. Ma, Z. Wang, J. Chen, S. Liping, Q. Yang, D. Xu, M. Liu, and B. Qin. CFSP: An efficient structured pruning framework for LLMs with coarse-to-fine activation information. In O. Rambow, L. Wanner, M. Apidianaki, H. Al-Khalifa, B. D. Eugenio, and S. Schockaert, editors,Proceedings of the 31st International Conference on Computational Linguistics...
2025
-
[26]
Gerganov and O.-S
G. Gerganov and O.-S. Contributors. Llama.cpp.https://github.com/ggerganov/ llama.cpp, 2023. Accessed: May 2026
2023
-
[27]
Stay directly on the middle of the track
N. Baumann, E. Ghignone, J. K ¨uhne, N. Bastuck, J. Becker, N. Imholz, T. Kr¨anzlin, T. Y . Lim, M. L¨otscher, L. Schwarzenbach, et al. ForzaETH Race Stack—Scaled Autonomous Head-to- Head Racing on Fully Commercial Off-the-Shelf Hardware.Journal of Field Robotics, 2024. 11 Appendix A RobotxR1 Pipeline and Evaluation Details This work uses the RobotxR1 pip...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.