Algorithmic Recourse of In-Context Learning for Tabular Data
Pith reviewed 2026-06-28 23:23 UTC · model grok-4.3
The pith
Recourse for in-context learning on tabular data remains well-defined, bounded, and converges to classical solutions as context size grows.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that algorithmic recourse remains well-defined and bounded for in-context learning models on tabular data, and characterizes the convergence of this recourse toward classical solutions as context size increases; it further supplies the ASR-ICL zeroth-order framework that produces actionable and sparse recourse for black-box ICL predictors, with natural extension to multi-class tasks.
What carries the argument
Adaptive Subspace Recourse for In-Context Learning (ASR-ICL), a zeroth-order black-box optimization procedure that restricts search to adaptive low-dimensional subspaces to produce sparse recourse actions.
If this is right
- Recourse can be computed for black-box ICL predictors without access to internal gradients or model weights.
- Larger context sizes produce recourse that more closely matches what would be recommended by a trained model on the same data.
- The same framework applies to multi-class tabular prediction tasks without modification.
- Fewer model queries suffice to reach recourse quality comparable to gradient-based or white-box methods.
Where Pith is reading between the lines
- If the convergence result holds, then ICL could serve as a drop-in replacement for trained models in recourse pipelines once context is sufficiently large.
- The subspace adaptation technique might lower query budgets for other black-box optimization tasks on tabular inputs beyond recourse.
- Checking whether boundedness persists when ICL is applied to non-tabular modalities would test the scope of the theoretical claim.
Load-bearing premise
That standard definitions of recourse and zeroth-order optimization can be applied directly to ICL models on tabular data without additional assumptions specific to how the context is formed or how the language model processes it.
What would settle it
An experiment in which the recourse actions obtained from an ICL model with increasing context size fail to approach the recourse actions obtained from a classically trained model on the identical tabular dataset and task.
Figures

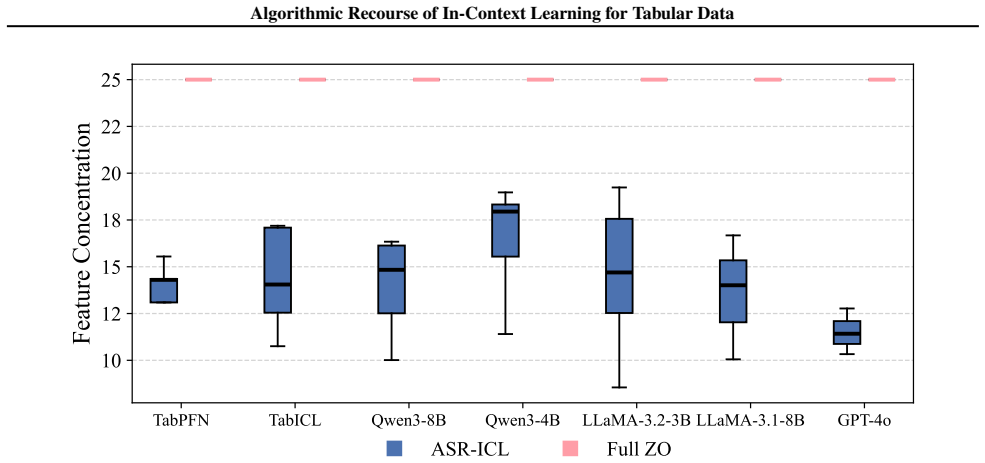
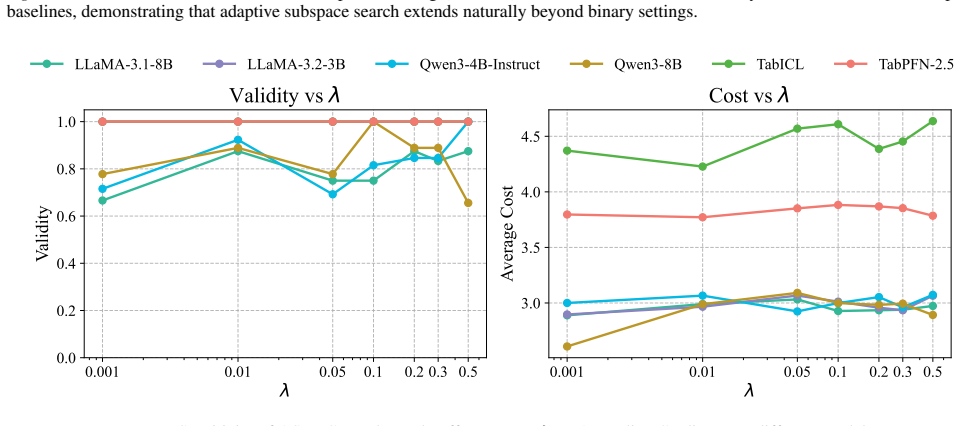
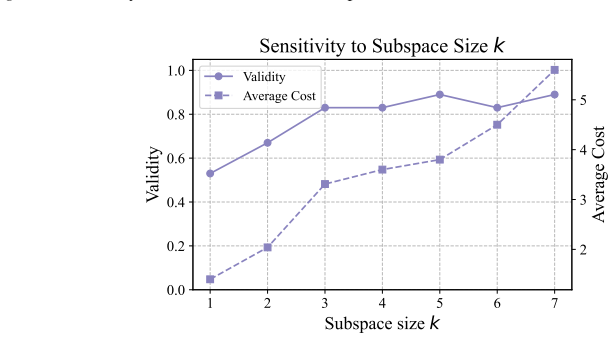
read the original abstract
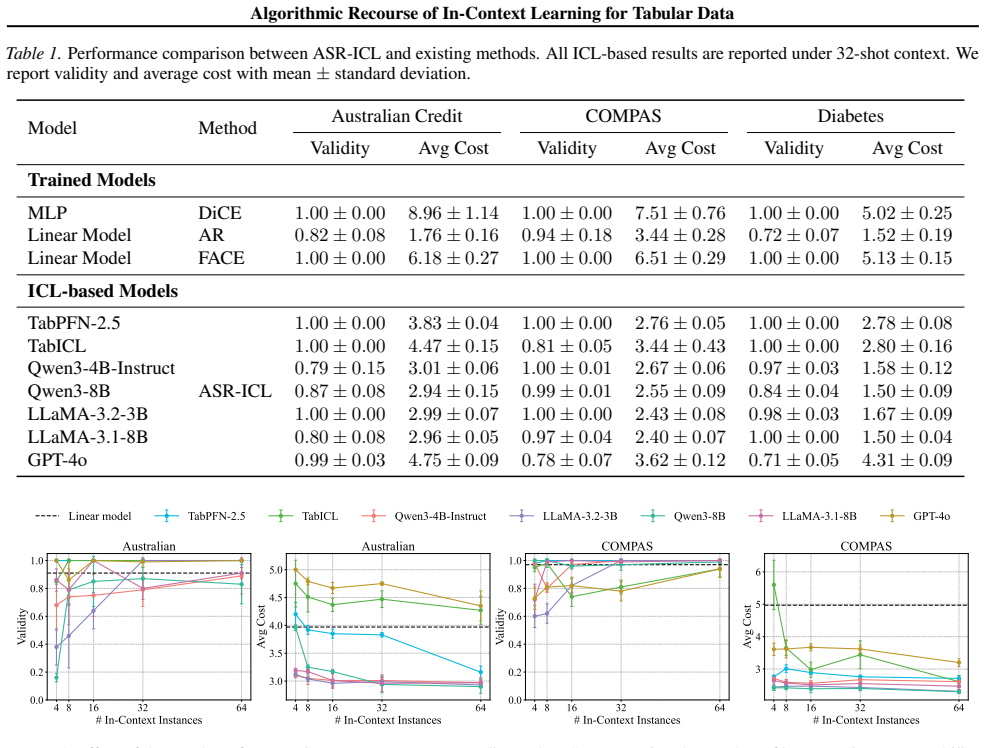
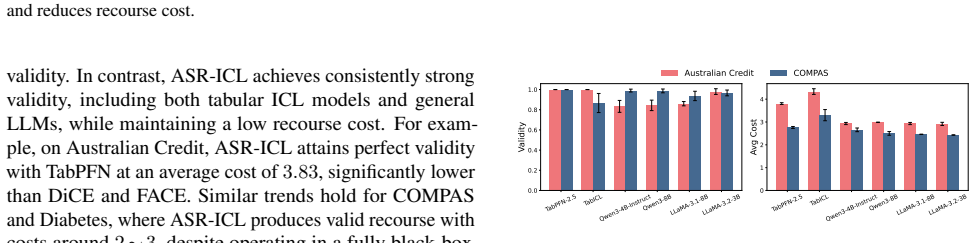
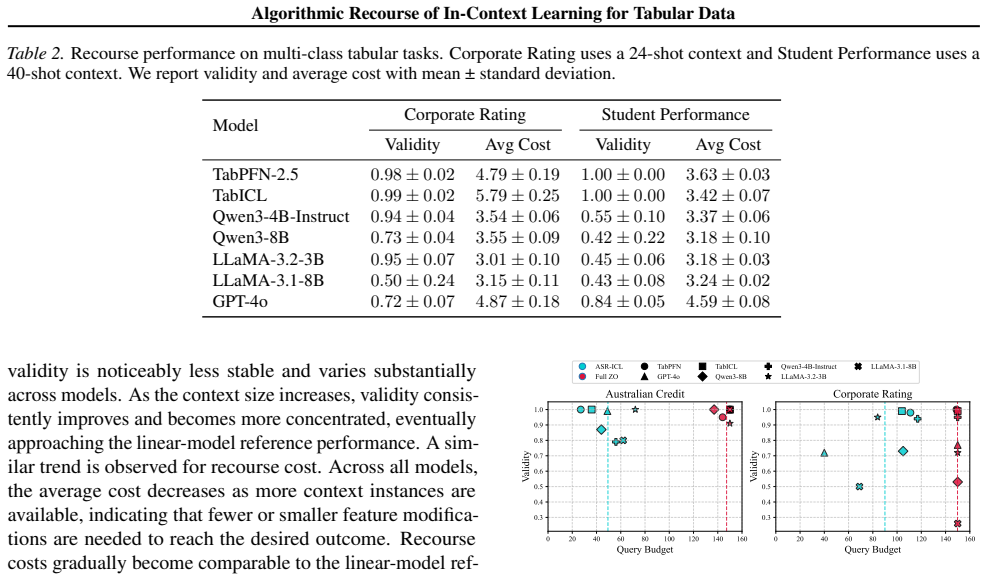
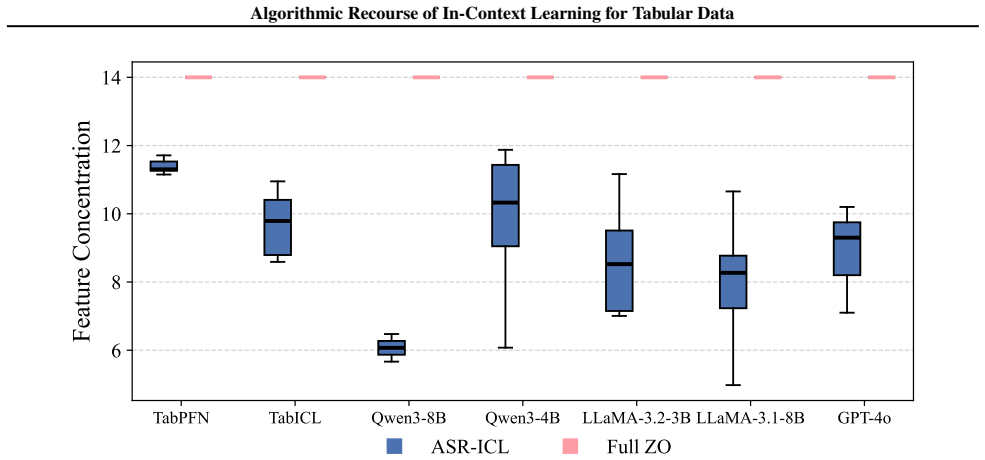
As predictive models are increasingly deployed in high-stakes settings such as credit approval, there is a growing need for post-hoc methods that provide recourse to affected individuals. Many such models operate on tabular data, where features correspond to real-world attributes. Recently, in-context learning (ICL) has enabled large language models to perform tabular prediction by conditioning on labeled examples at inference time, without explicit training. However, algorithmic recourse for tabular decision-making under ICL remains largely unexplored. In this work, we present the first study of algorithmic recourse for tabular data under ICL. We carry out a theoretical analysis, showing that recourse remains well-defined and bounded, and we characterize how recourse converges toward classical solutions as the context size increases. In practice, we propose a novel zeroth-order recourse framework, Adaptive Subspace Recourse for In-Context Learning (ASR-ICL), that efficiently generates actionable and sparse recourse for black-box ICL models. The proposed framework naturally extends to multi-class tabular tasks. Experiments across multiple real-world datasets and models demonstrate that ASR-ICL achieves recourse quality comparable to existing methods with fewer queries and empirically confirm the predicted convergence behavior, supporting our theoretical analysis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents the first study of algorithmic recourse for tabular data under in-context learning (ICL). It carries out a theoretical analysis showing that recourse remains well-defined and bounded for ICL predictors (modeled as functions of context examples) and characterizes convergence toward classical recourse solutions as context size increases. It proposes the Adaptive Subspace Recourse for In-Context Learning (ASR-ICL) zeroth-order framework to generate actionable and sparse recourse for black-box ICL models, with a natural extension to multi-class tasks. Experiments across multiple real-world datasets and models demonstrate that ASR-ICL achieves recourse quality comparable to existing methods with fewer queries while empirically confirming the predicted convergence behavior.
Significance. If the theoretical results and empirical findings hold, this work is significant as the first exploration of recourse under ICL for tabular data in high-stakes settings. The theoretical contributions establishing well-definedness, boundedness, and convergence to classical solutions provide a foundation for the area. The ASR-ICL framework offers a practical, query-efficient zeroth-order approach for black-box models. Credit is due for the convergence characterization, the modeling choices that directly support treating ICL recourse within the proposed framework, and the supporting experiments that validate both the theory and practical performance.
minor comments (2)
- The description of how the adaptive subspace is constructed and updated in ASR-ICL could be expanded with pseudocode or a clearer algorithmic outline to improve reproducibility.
- Figure captions and axis labels in the experimental section would benefit from explicit mention of the number of queries used by each baseline for direct comparison.
Simulated Author's Rebuttal
We thank the referee for the positive review, recognition of the theoretical contributions on well-definedness, boundedness, and convergence, and the recommendation for minor revision. We appreciate the acknowledgment of the practical value of the ASR-ICL framework.
Circularity Check
No significant circularity
full rationale
The abstract and skeptic summary describe a theoretical analysis establishing that recourse is well-defined and bounded for ICL predictors (modeled as functions of context), plus a convergence result to classical recourse as context size grows, and an independent zeroth-order ASR-ICL framework validated by experiments. No equations, fitting procedures, or self-citation chains are visible that reduce any load-bearing claim to its own inputs by construction. The modeling choices directly support treating ICL recourse as amenable to the proposed analysis and method without self-referential definitions or renamed fits. This is the most common honest finding when no explicit reduction is exhibited.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Transformers learn to implement preconditioned gradient descent for in-context learning
Ahn, K., Cheng, X., Daneshmand, H., and Sra, S. Transformers learn to implement preconditioned gradient descent for in-context learning. Advances in Neural Information Processing Systems, 36: 0 45614--45650, 2023
2023
-
[2]
Diabetes dataset
Akturk, M. Diabetes dataset. https://www.kaggle.com/datasets/mathchi/diabetes-data-set, 2020. Kaggle repository, accessed 2026-01-27
2020
-
[3]
Machine bias
Angwin, J., Larson, J., Mattu, S., and Kirchner, L. Machine bias. In Ethics of data and analytics, pp.\ 254--264. Auerbach Publications, 2022
2022
-
[4]
and Selbst, A
Barocas, S. and Selbst, A. D. Big data's disparate impact. Calif. L. Rev., 104: 0 671, 2016
2016
-
[5]
d., Bae, S., Cha, S., and Yun, S.-Y
Breejen, F. d., Bae, S., Cha, S., and Yun, S.-Y. Fine-tuned in-context learning transformers are excellent tabular data classifiers. arXiv preprint arXiv:2405.13396, 2024
-
[6]
D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al. Language models are few-shot learners. Advances in neural information processing systems, 33: 0 1877--1901, 2020
1901
-
[7]
N., Bhaila, K., Edemacu, K., and Wu, X
Carey, A. N., Bhaila, K., Edemacu, K., and Wu, X. Dp-tabicl: In-context learning with differentially private tabular data. In 2024 IEEE International Conference on Big Data (BigData), pp.\ 1552--1557. IEEE, 2024
2024
-
[8]
Framing algorithmic recourse for anomaly detection
Datta, D., Chen, F., and Ramakrishnan, N. Framing algorithmic recourse for anomaly detection. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pp.\ 283--293, 2022
2022
-
[9]
Time can invalidate algorithmic recourse
De Toni, G., Teso, S., Lepri, B., and Passerini, A. Time can invalidate algorithmic recourse. In Proceedings of the 2025 ACM Conference on Fairness, Accountability, and Transparency, pp.\ 89--107, 2025
2025
-
[10]
Robustness implies fairness in causal algorithmic recourse
Ehyaei, A.-R., Karimi, A.-H., Sch \"o lkopf, B., and Maghsudi, S. Robustness implies fairness in causal algorithmic recourse. In Proceedings of the 2023 ACM Conference on Fairness, Accountability, and Transparency, pp.\ 984--1001, 2023
2023
-
[11]
Fang, L., Liu, A., Zhang, H., Zou, H. P., Zhang, W., and Yu, P. S. TABGEN - ICL : Residual-aware in-context example selection for tabular data generation. In Che, W., Nabende, J., Shutova, E., and Pilehvar, M. T. (eds.), Findings of the Association for Computational Linguistics: ACL 2025, pp.\ 20027--20041, Vienna, Austria, July 2025. Association for Comp...
-
[12]
Understanding and Improving Continuous Adversarial Training for LLMs via In-context Learning Theory
Fu, S. and Wang, D. Understanding and improving continuous adversarial training for llms via in-context learning theory. arXiv preprint arXiv:2604.12817, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[13]
Fu, S., Ding, L., Zhang, J., and Wang, D. Short-length adversarial training helps llms defend long-length jailbreak attacks: Theoretical and empirical evidence. arXiv preprint arXiv:2502.04204, 2025
-
[14]
and Lakkaraju, H
Gao, R. and Lakkaraju, H. On the impact of algorithmic recourse on social segregation. In Krause, A., Brunskill, E., Cho, K., Engelhardt, B., Sabato, S., and Scarlett, J. (eds.), Proceedings of the 40th International Conference on Machine Learning, volume 202 of Proceedings of Machine Learning Research, pp.\ 10727--10743. PMLR, 23--29 Jul 2023. URL https:...
2023
-
[15]
Gardner, J., Perdomo, J. C., and Schmidt, L. Large scale transfer learning for tabular data via language modeling, 2024. URL https://arxiv. org/abs/2406.12031
-
[16]
Corporate credit rating dataset
Gewerc, A. Corporate credit rating dataset. https://www.kaggle.com/datasets/agewerc/corporate-credit-rating, 2019. Kaggle repository, accessed 2026-01-27
2019
-
[17]
Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Vaughan, A., et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
TabPFN-2.5: Advancing the State of the Art in Tabular Foundation Models
Grinsztajn, L., Fl \"o ge, K., Key, O., Birkel, F., Jund, P., Roof, B., J \"a ger, B., Safaric, D., Alessi, S., Hayler, A., et al. Tabpfn-2.5: Advancing the state of the art in tabular foundation models. arXiv preprint arXiv:2511.08667, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Tabpfn: A transformer that solves small tabular classification problems in a second
Hollmann, N., M \"u ller, S., Eggensperger, K., and Hutter, F. Tabpfn: A transformer that solves small tabular classification problems in a second. In International Conference on Learning Representations 2023, 2023
2023
-
[20]
u ller, S., Purucker, L., Krishnakumar, A., K \
Hollmann, N., M \"u ller, S., Purucker, L., Krishnakumar, A., K \"o rfer, M., Hoo, S. B., Schirrmeister, R. T., and Hutter, F. Accurate predictions on small data with a tabular foundation model. Nature, 01 2025. doi:10.1038/s41586-024-08328-6. URL https://www.nature.com/articles/s41586-024-08328-6
-
[21]
Hurst, A., Lerer, A., Goucher, A. P., Perelman, A., Ramesh, A., Clark, A., Ostrow, A., Welihinda, A., Hayes, A., Radford, A., et al. Gpt-4o system card. arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Learning decision trees and forests with algorithmic recourse
Kanamori, K., Takagi, T., Kobayashi, K., and Ike, Y. Learning decision trees and forests with algorithmic recourse. arXiv preprint arXiv:2406.01098, 2024
-
[23]
Learning gradient boosted decision trees with algorithmic recourse
Kanamori, K., Kobayashi, K., and Takagi, T. Learning gradient boosted decision trees with algorithmic recourse. Advances in Neural Information Processing Systems, 38: 0 76509--76542, 2026
2026
-
[24]
u gelgen, J., Sch \
Karimi, A.-H., Von K \"u gelgen, J., Sch \"o lkopf, B., and Valera, I. Algorithmic recourse under imperfect causal knowledge: a probabilistic approach. Advances in neural information processing systems, 33: 0 265--277, 2020
2020
-
[25]
Algorithmic recourse: from counterfactual explanations to interventions
Karimi, A.-H., Sch \"o lkopf, B., and Valera, I. Algorithmic recourse: from counterfactual explanations to interventions. In Proceedings of the 2021 ACM conference on fairness, accountability, and transparency, pp.\ 353--362, 2021
2021
-
[26]
Kharoua, R. E. Students performance dataset. https://www.kaggle.com/datasets/rabieelkharoua/students-performance-dataset, 2022. Kaggle repository, accessed 2026-01-27
2022
-
[27]
Human decisions and machine predictions
Kleinberg, J., Lakkaraju, H., Leskovec, J., Ludwig, J., and Mullainathan, S. Human decisions and machine predictions. The quarterly journal of economics, 133 0 (1): 0 237--293, 2018
2018
-
[28]
Early stopping tabular in-context learning
K \"u ken, J., Purucker, L., and Hutter, F. Early stopping tabular in-context learning. arXiv preprint arXiv:2506.21387, 2025
-
[29]
E., Papailiopoulos, D., and Oymak, S
Li, Y., Ildiz, M. E., Papailiopoulos, D., and Oymak, S. Transformers as algorithms: Generalization and stability in in-context learning. In International conference on machine learning, pp.\ 19565--19594. PMLR, 2023
2023
-
[30]
Zoopt: Toolbox for derivative-free optimization
Liu, Y.-R., Hu, Y.-Q., Qian, H., Qian, C., and Yu, Y. Zoopt: Toolbox for derivative-free optimization. arXiv preprint arXiv:1801.00329, 2017
-
[31]
K., Sharma, A., and Tan, C
Mothilal, R. K., Sharma, A., and Tan, C. Explaining machine learning classifiers through diverse counterfactual explanations. In Proceedings of the 2020 conference on fairness, accountability, and transparency, pp.\ 607--617, 2020
2020
-
[32]
Learning model-agnostic counterfactual explanations for tabular data
Pawelczyk, M., Broelemann, K., and Kasneci, G. Learning model-agnostic counterfactual explanations for tabular data. In Proceedings of the web conference 2020, pp.\ 3126--3132, 2020
2020
-
[33]
Face: feasible and actionable counterfactual explanations
Poyiadzi, R., Sokol, K., Santos-Rodriguez, R., De Bie, T., and Flach, P. Face: feasible and actionable counterfactual explanations. In Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society, pp.\ 344--350, 2020
2020
-
[34]
Qu, J., Holzm \"u ller, D., Varoquaux, G., and Morvan, M. L. Tabicl: A tabular foundation model for in-context learning on large data. arXiv preprint arXiv:2502.05564, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Statlog (Australian Credit Approval)
Quinlan, R. Statlog (Australian Credit Approval) . UCI Machine Learning Repository, 1987. DOI : https://doi.org/10.24432/C59012
-
[36]
Learning models for actionable recourse
Ross, A., Lakkaraju, H., and Bastani, O. Learning models for actionable recourse. Advances in Neural Information Processing Systems, 34: 0 18734--18746, 2021
2021
-
[37]
Retrieval & fine-tuning for in-context tabular models
Thomas, V., Ma, J., Hosseinzadeh, R., Golestan, K., Yu, G., Volkovs, M., and Caterini, A. Retrieval & fine-tuning for in-context tabular models. Advances in Neural Information Processing Systems, 37: 0 108439--108467, 2024
2024
-
[38]
Tropp, J. A. et al. An introduction to matrix concentration inequalities. Foundations and Trends in Machine Learning , 8 0 (1-2): 0 1--230, 2015
2015
-
[39]
Ellice: Efficient and provably robust algorithmic recourse via the rashomon sets
Turbal, B., Voitsitska, I., and Semenova, L. Ellice: Efficient and provably robust algorithmic recourse via the rashomon sets. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[40]
Towards robust and reliable algorithmic recourse
Upadhyay, S., Joshi, S., and Lakkaraju, H. Towards robust and reliable algorithmic recourse. Advances in Neural Information Processing Systems, 34: 0 16926--16937, 2021
2021
-
[41]
Actionable recourse in linear classification
Ustun, B., Spangher, A., and Liu, Y. Actionable recourse in linear classification. In Proceedings of the conference on fairness, accountability, and transparency, pp.\ 10--19, 2019
2019
-
[42]
and Von dem Bussche, A
Voigt, P. and Von dem Bussche, A. The eu general data protection regulation (gdpr). A practical guide, 1st ed., Cham: Springer International Publishing, 10 0 (3152676): 0 10--5555, 2017
2017
-
[43]
Transformers learn in-context by gradient descent
Von Oswald, J., Niklasson, E., Randazzo, E., Sacramento, J., Mordvintsev, A., Zhmoginov, A., and Vladymyrov, M. Transformers learn in-context by gradient descent. In International Conference on Machine Learning, pp.\ 35151--35174. PMLR, 2023
2023
-
[44]
Counterfactual explanations without opening the black box: Automated decisions and the gdpr
Wachter, S., Mittelstadt, B., and Russell, C. Counterfactual explanations without opening the black box: Automated decisions and the gdpr. Harv. JL & Tech., 31: 0 841, 2017
2017
-
[45]
Wang, L., Ren, J., Xu, H., Wang, J., Xie, H., Keyes, D. E., and Wang, D. Zo2: Scalable zeroth-order fine-tuning for extremely large language models with limited gpu memory. arXiv preprint arXiv:2503.12668, 2025 a
-
[46]
Wang, L., Xie, H., and Wang, D. Distzo2: High-throughput and memory-efficient zeroth-order fine-tuning llms with distributed parallel computing. arXiv preprint arXiv:2507.03211, 2025 b
-
[47]
Scalable in-context learning on tabular data via retrieval-augmented large language models
Wen, X., Zheng, S., Xu, Z., Sun, Y., and Bian, J. Scalable in-context learning on tabular data via retrieval-augmented large language models. arXiv preprint arXiv:2502.03147, 2025
-
[48]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al. Qwen3 technical report. arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
Derivative-free optimization via classification
Yu, Y., Qian, H., and Hu, Y.-Q. Derivative-free optimization via classification. In Proceedings of the AAAI conference on artificial intelligence, volume 30, 2016
2016
-
[50]
Zhang, R., Frei, S., and Bartlett, P. L. Trained transformers learn linear models in-context. Journal of Machine Learning Research, 25 0 (49): 0 1--55, 2024
2024
-
[51]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.