TokTalk: Expressive Real-time Facial Animation from Audio-LLM Tokens
Pith reviewed 2026-06-28 22:43 UTC · model grok-4.3
The pith
Audio tokens from Audio-LLMs suffice to drive expressive real-time 3D facial animation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Audio-tokens produced by current Audio-LLMs carry sufficient information to reconstruct a plausible facial performance. TokTalk directly outputs expressive facial animation in real-time from streaming audio-tokens using a Chunk-based Conditional Flow Matching model trained on a novel audio-token to 3D facial motion dataset, with a lightweight adaptation strategy to connect to any Audio-LLM.
What carries the argument
Chunk-based Conditional Flow Matching model that maps streaming audio-tokens to 3D facial motion sequences, with chunk size controlling the latency-quality trade-off.
Load-bearing premise
The constructed audio-token to 3D facial motion dataset and the perceptual study results are representative of real conversational scenarios and generalize beyond the tested conditions.
What would settle it
Run TokTalk on unscripted multi-speaker audio recorded in noisy real-world settings and check whether human raters still rate its expressivity and naturalness above prior art by the same margin reported in the paper.
Figures




read the original abstract
Recent advances in Audio-LLMs like GPT-4o have ushered in an era of conversational interaction with language models. Conversational avatars however, still seem robotic in facial expression and conversational flow, in part due to sequential stages of speech recognition, text generation, turn-based text response, speech synthesis, and audio driven facial animation. Based on our insight that audio-tokens produced by current Audio-LLMs carry sufficient information to reconstruct a plausible facial performance, we present TokTalk, a system that directly outputs expressive facial animation in real-time from streaming audio-tokens. We construct a novel audio-token to 3D facial motion dataset, on which TokTalk is trained using a Chunk-based Conditional Flow Matching model. A lightweight adaptation strategy allows our trained model to seamlessly connect to any token-based Audio-LLM at minimal computational overhead. Our chunk-based processing further enables parametric trade-off between latency and facial quality, shown through ablation studies. We further show that the real-time performance of TokTalk is comparable in latency to prior art solutions, and significantly favorable (via a perceptual study) in terms of quality, expressivity and control of the 3D facial performance. We showcase TokTalk's flexibility using a chatbot Avatar, a voice-driven user Avatar, and an animation Director's interface, as diverse audio-visual face applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents TokTalk, a system for real-time expressive 3D facial animation directly from streaming audio-tokens produced by Audio-LLMs. It constructs a novel audio-token to 3D facial motion dataset, trains the model using Chunk-based Conditional Flow Matching, enables lightweight adaptation to any token-based Audio-LLM, and provides ablations on chunk-based latency-quality trade-offs. The central claims are that audio-tokens carry sufficient information for plausible facial performance, that TokTalk achieves real-time performance with latency comparable to prior art, and that it is significantly superior in quality, expressivity, and control per a perceptual study, with demonstrations in chatbot, voice-driven, and director interfaces.
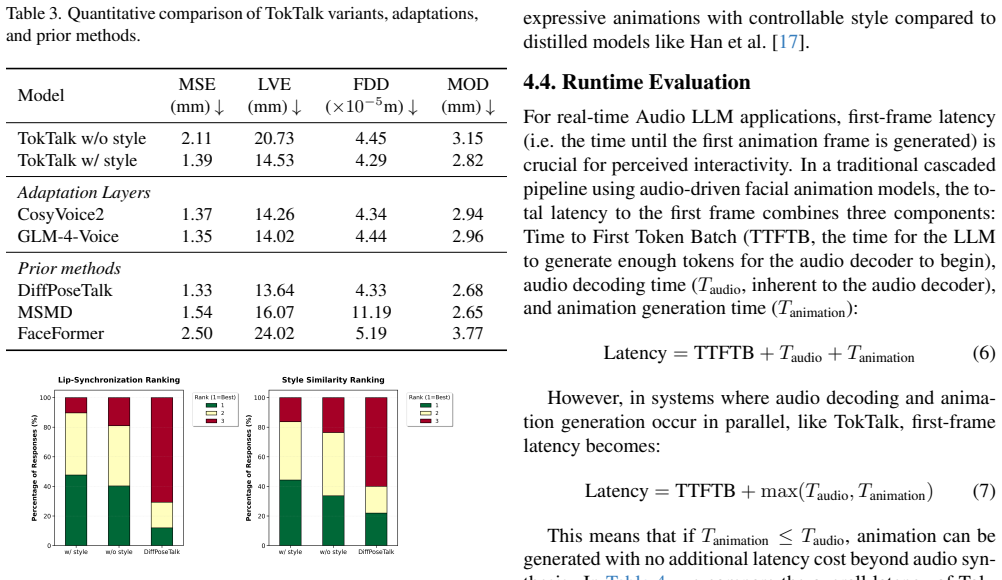
Significance. If the perceptual study and generalization claims hold, the work could advance conversational avatars by enabling direct token-to-animation pipelines that reduce sequential processing stages and improve naturalness. The chunk-based Conditional Flow Matching for parametric latency control and the lightweight adaptation strategy represent practical strengths for deployment with existing Audio-LLMs.
major comments (1)
- [Abstract] Abstract: the claim that TokTalk is 'significantly favorable (via a perceptual study)' in quality, expressivity, and control of the 3D facial performance is unsupported because the manuscript provides no details on study design, participant numbers, statistical tests, or data exclusion criteria, leaving the superiority assertion without verifiable evidence.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We address the single major comment below and will incorporate the requested details in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that TokTalk is 'significantly favorable (via a perceptual study)' in quality, expressivity, and control of the 3D facial performance is unsupported because the manuscript provides no details on study design, participant numbers, statistical tests, or data exclusion criteria, leaving the superiority assertion without verifiable evidence.
Authors: We agree that the abstract claim requires supporting details from the perceptual study to be verifiable. The current manuscript text does not include these specifics. In the revision we will add a new subsection (or expand the experiments section) that reports the full study design, number of participants, statistical tests (including p-values), and exclusion criteria. The abstract will be updated to reference this section so the superiority claim is properly grounded. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper's central claim rests on constructing an audio-token to 3D facial motion dataset, training a Chunk-based Conditional Flow Matching model on it, and validating via perceptual study and latency comparisons. No equations, parameter fits renamed as predictions, or load-bearing self-citations appear in the provided text that would reduce any result to its inputs by construction. The approach is empirical and externally benchmarked, qualifying as independent content.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Soul Machines — We Humanize AI. 3
-
[2]
Distributed by Warner Bros
Her, 2013. Distributed by Warner Bros. Pictures. 1
2013
-
[3]
Gesturediffu- clip: Gesture diffusion model with clip latents.ACM Trans
Tenglong Ao, Zeyi Zhang, and Libin Liu. Gesturediffu- clip: Gesture diffusion model with clip latents.ACM Trans. Graph., 2023. 9
2023
-
[4]
wav2vec 2.0: a framework for self-supervised learning of speech representations
Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, and Michael Auli. wav2vec 2.0: a framework for self-supervised learning of speech representations. InProceedings of the 34th International Conference on Neural Information Pro- cessing Systems, Red Hook, NY , USA, 2020. Curran Asso- ciates Inc. 2, 3, 4
2020
-
[5]
WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing
Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yan- min Qian, Yao Qian, Jian Wu, Michael Zeng, Xiangzhan Yu, and Furu Wei. WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing. 16(6):1505–
-
[6]
Cohen and Dominic W
Michael M. Cohen and Dominic W. Massaro. Modeling Coarticulation in Synthetic Visual Speech. InModels and Techniques in Computer Animation, pages 139–156, Tokyo,
-
[7]
Emotional speech-driven animation with content-emotion disentangle- ment
Radek Dan ˇeˇcek, Kiran Chhatre, Shashank Tripathi, Yan- dong Wen, Michael Black, and Timo Bolkart. Emotional speech-driven animation with content-emotion disentangle- ment. InSIGGRAPH Asia 2023 Conference Papers, pages 1–13, 2023. 3
2023
-
[8]
Moshi: a speech-text foundation model for real-time dialogue
Alexandre D ´efossez, Laurent Mazar´e, Manu Orsini, Am ´elie Royer, Patrick P´erez, Herv´e J´egou, Edouard Grave, and Neil Zeghidour. Moshi: a speech-text foundation model for real- time dialogue.arXiv preprint arXiv:2410.00037, 2024. 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
CosyV oice: A Scalable Multilin- gual Zero-shot Text-to-speech Synthesizer based on Super- vised Semantic Tokens
Zhihao Du, Qian Chen, Shiliang Zhang, Kai Hu, Heng Lu, Yexin Yang, Hangrui Hu, Siqi Zheng, Yue Gu, Ziyang Ma, Zhifu Gao, and Zhijie Yan. CosyV oice: A Scalable Multilin- gual Zero-shot Text-to-speech Synthesizer based on Super- vised Semantic Tokens. 3, 4, 5, 6, 7, 8
-
[10]
High Fidelity Neural Audio Compression
Alexandre D ´efossez, Jade Copet, Gabriel Synnaeve, and Yossi Adi. High Fidelity Neural Audio Compression. 3
-
[11]
JALI: an animator-centric viseme model for expres- sive lip synchronization.ACM Transactions on Graphics, 35 (4):1–11, 2016
Pif Edwards, Chris Landreth, Eugene Fiume, and Karan Singh. JALI: an animator-centric viseme model for expres- sive lip synchronization.ACM Transactions on Graphics, 35 (4):1–11, 2016. 2, 3
2016
-
[12]
Jali-driven expressive facial animation and multilin- gual speech in cyberpunk 2077
Pif Edwards, Chris Landreth, Mateusz Popławski, Robert Malinowski, Sarah Watling, Eugene Fiume, and Karan Singh. Jali-driven expressive facial animation and multilin- gual speech in cyberpunk 2077. InACM SIGGRAPH 2020 Talks, New York, NY , USA, 2020. Association for Comput- ing Machinery. 2
2077
-
[13]
Papka, Sanjif Shanmugavelu, Darshan Gandhi, Hengyu Zhao, Dun Ma, Kiran Ranganath, Rick Weisner, Jiunn-yeu Chen, Yuting Yang, Natalia Vas- silieva, Bin C
Murali Emani, Sam Foreman, Varuni Sastry, Zhen Xie, Sid- dhisanket Raskar, William Arnold, Rajeev Thakur, Venka- tram Vishwanath, Michael E. Papka, Sanjif Shanmugavelu, Darshan Gandhi, Hengyu Zhao, Dun Ma, Kiran Ranganath, Rick Weisner, Jiunn-yeu Chen, Yuting Yang, Natalia Vas- silieva, Bin C. Zhang, Sylvia Howland, and Alexander Tsyplikhin. Toward a Holi...
2024
-
[14]
Faceformer: Speech-driven 3d facial anima- tion with transformers
Yingruo Fan, Zhaojiang Lin, Jun Saito, Wenping Wang, and Taku Komura. Faceformer: Speech-driven 3d facial anima- tion with transformers. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022. 3, 6
2022
-
[15]
Qingkai Fang, Shoutao Guo, Yan Zhou, Zhengrui Ma, Shaolei Zhang, and Yang Feng. Llama-omni: Seam- less speech interaction with large language models.arXiv preprint arXiv:2409.06666, 2024. 6
-
[16]
Tiny is not small enough: High quality, low- resource facial animation through hybrid knowledge distil- lation.ACM Trans
Zhen Han, Mattias Teye, Derek Yadgaroff, and Judith B¨utepage. Tiny is not small enough: High quality, low- resource facial animation through hybrid knowledge distil- lation.ACM Trans. Graph., 44(4), 2025. 2, 3, 7, 8, 12
2025
-
[17]
Classifier-free diffusion guidance, 2022
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance, 2022. 5
2022
-
[18]
HuBERT: Self-Supervised Speech Representa- tion Learning by Masked Prediction of Hidden Units
Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, and Abdelrahman Mohamed. HuBERT: Self-Supervised Speech Representa- tion Learning by Masked Prediction of Hidden Units. 2, 3, 4
-
[19]
Speed- aware audio-driven speech animation using adaptive win- dows.ACM Transactions on Graphics, 44(1):1–14, 2024
Sunjin Jung, Yeongho Seol, Kwanggyoon Seo, Hyeonho Na, Seonghyeon Kim, Vanessa Tan, and Junyong Noh. Speed- aware audio-driven speech animation using adaptive win- dows.ACM Transactions on Graphics, 44(1):1–14, 2024. 3
2024
-
[20]
Audio-driven facial animation by joint end- to-end learning of pose and emotion.ACM Trans
Tero Karras, Timo Aila, Samuli Laine, Antti Herva, and Jaakko Lehtinen. Audio-driven facial animation by joint end- to-end learning of pose and emotion.ACM Trans. Graph., 36 (4):94:1–94:12, 2017. 3
2017
-
[21]
Audio Driven Real-Time Facial Animation for Social Telep- resence
Jiye Lee, Chenghui Li, Linh Tran, Shih-En Wei, Jason Saragih, Alexander Richard, Hanbyul Joo, and Shaojie Bai. Audio Driven Real-Time Facial Animation for Social Telep- resence. InProceedings of the SIGGRAPH Asia 2025 Con- ference Papers, pages 1–12. 3, 7, 8
2025
-
[22]
Ditto: Motion-Space Diffusion for Control- lable Realtime Talking Head Synthesis
Tianqi Li, Ruobing Zheng, Minghui Yang, Jingdong Chen, and Ming Yang. Ditto: Motion-Space Diffusion for Control- lable Realtime Talking Head Synthesis. 2
-
[23]
Tianye Li, Timo Bolkart, Michael. J. Black, Hao Li, and Javier Romero. Learning a model of facial shape and ex- pression from 4D scans. pages 194:1–194:17, 2017. 2, 4
2017
-
[24]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maxi- milian Nickel, and Matt Le. Flow Matching for Generative Modeling. 4
-
[25]
Medtalk: Multimodal controlled 3d facial animation with dynamic emotions by disentangled embed- ding
Chang Liu, Ye Pan, Chenyang Ding, Susanto Rahardja, and Xiaokang Yang. Medtalk: Multimodal controlled 3d facial animation with dynamic emotions by disentangled embed- ding. InProceedings of the 33rd ACM International Confer- ence on Multimedia, pages 7538–7547, 2025. 3
2025
-
[26]
D. W. Massaro, M. M. Cohen, M. Tabain, J. Beskow, and R. Clark. Animated speech: research progress and appli- cations. InAudiovisual Speech Processing, pages 309–345. Cambridge University Press, 2012. 2
2012
-
[27]
Learning to Listen: Modeling Non-Deterministic Dyadic Facial Motion
Evonne Ng, Hanbyul Joo, Liwen Hu, Hao Li, Trevor Darrell, Angjoo Kanazawa, and Shiry Ginosar. Learning to Listen: Modeling Non-Deterministic Dyadic Facial Motion. 9
-
[28]
S3: Speech, Script and Scene driven Head and Eye Animation
Yifang Pan, Rishabh Agrawal, and Karan Singh. S3: Speech, Script and Scene driven Head and Eye Animation. 43(4): 47:1–47:12, . 9
-
[29]
Model See Model Do: Speech-Driven Facial Animation with Style Control
Yifang Pan, Karan Singh, and Luiz Gustavo Hafemann. Model See Model Do: Speech-Driven Facial Animation with Style Control. InProceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Confer- ence Conference Papers, pages 1–10. Association for Com- puting Machinery, . 2, 3, 4, 6
-
[30]
VOCAL: V owel and Consonant Layering for Expres- sive Animator-Centric Singing Animation
Yifang Pan, Chris Landreth, Eugene Fiume, and Karan Singh. VOCAL: V owel and Consonant Layering for Expres- sive Animator-Centric Singing Animation. InSIGGRAPH Asia 2022 Conference Papers, pages 1–9, New York, NY , USA, 2022. Association for Computing Machinery. 2
2022
-
[31]
Emotalk: Speech-driven emotional disentanglement for 3d face anima- tion
Ziqiao Peng, Haoyu Wu, Zhenbo Song, Hao Xu, Xiangyu Zhu, Jun He, Hongyan Liu, and Zhaoxin Fan. Emotalk: Speech-driven emotional disentanglement for 3d face anima- tion. InProceedings of the IEEE/CVF International Confer- ence on Computer Vision, pages 20687–20697, 2023. 3, 6
2023
-
[32]
MeshTalk: 3D Face Animation from Speech using Cross-Modality Disentangle- ment
Alexander Richard, Michael Zollhoefer, Yandong Wen, Fer- nando de la Torre, and Yaser Sheikh. MeshTalk: 3D Face Animation from Speech using Cross-Modality Disentangle- ment. 2022. arXiv:2104.08223 [cs]. 3
-
[33]
Facediffuser: Speech-driven 3d facial animation synthesis using diffusion
Stefan Stan, Kazi Injamamul Haque, and Zerrin Yumak. Facediffuser: Speech-driven 3d facial animation synthesis using diffusion. InACM SIGGRAPH Conference on Motion, Interaction and Games (MIG ’23), November 15–17, 2023, Rennes, France, New York, NY , USA, 2023. ACM. 3
2023
-
[34]
Diffposetalk: Speech-driven stylistic 3d facial animation and head pose generation via diffusion models.ACM Transactions on Graphics (TOG), 43(4):1–9, 2024
Zhiyao Sun, Tian Lv, Sheng Ye, Matthieu Lin, Jenny Sheng, Yu-Hui Wen, Minjing Yu, and Yong-jin Liu. Diffposetalk: Speech-driven stylistic 3d facial animation and head pose generation via diffusion models.ACM Transactions on Graphics (TOG), 43(4):1–9, 2024. 2, 3, 5, 6, 7, 12
2024
-
[35]
Turn-taking and Backchannel Pre- diction with Acoustic and Large Language Model Fusion
Jinhan Wang, Long Chen, Aparna Khare, Anirudh Raju, Pranav Dheram, Di He, Minhua Wu, Andreas Stolcke, and Venkatesh Ravichandran. Turn-taking and Backchannel Pre- diction with Acoustic and Large Language Model Fusion. 9
-
[36]
Mini-Omni2: Towards Open- source GPT-4o with Vision, Speech and Duplex Capabilities
Zhifei Xie and Changqiao Wu. Mini-Omni2: Towards Open- source GPT-4o with Vision, Speech and Duplex Capabilities. 3, 6
-
[37]
CodeTalker: Speech- Driven 3D Facial Animation with Discrete Motion Prior
Jinbo Xing, Menghan Xia, Yuechen Zhang, Xiaodong Cun, Jue Wang, and Tien-Tsin Wong. CodeTalker: Speech- Driven 3D Facial Animation with Discrete Motion Prior. In 2023 IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR), pages 12780–12790, Vancouver, BC, Canada, 2023. IEEE. 3
2023
-
[38]
Qwen3-Omni Technical Report
Jin Xu, Zhifang Guo, Hangrui Hu, Yunfei Chu, Xiong Wang, Jinzheng He, Yuxuan Wang, Xian Shi, Ting He, Xinfa Zhu, Yuanjun Lv, Yongqi Wang, Dake Guo, He Wang, Linhan Ma, Pei Zhang, Xinyu Zhang, Hongkun Hao, Zishan Guo, Baosong Yang, Bin Zhang, Ziyang Ma, Xipin Wei, Shuai Bai, Keqin Chen, Xuejing Liu, Peng Wang, Mingkun Yang, Dayiheng Liu, Xingzhang Ren, Bo ...
-
[39]
SoundStream: An End- to-End Neural Audio Codec
Neil Zeghidour, Alejandro Luebs, Ahmed Omran, Jan Skoglund, and Marco Tagliasacchi. SoundStream: An End- to-End Neural Audio Codec. 3
-
[40]
GLM-4-V oice: Towards Intelligent and Human-Like End-to- End Spoken Chatbot
Aohan Zeng, Zhengxiao Du, Mingdao Liu, Kedong Wang, Shengmin Jiang, Lei Zhao, Yuxiao Dong, and Jie Tang. GLM-4-V oice: Towards Intelligent and Human-Like End-to- End Spoken Chatbot. 3, 6, 7
-
[41]
SpeechGPT: Empow- ering Large Language Models with Intrinsic Cross-Modal Conversational Abilities,
Dong Zhang, Shimin Li, Xin Zhang, Jun Zhan, Pengyu Wang, Yaqian Zhou, and Xipeng Qiu. SpeechGPT: Empow- ering Large Language Models with Intrinsic Cross-Modal Conversational Abilities, . 4
-
[42]
MuseTalk: Real-Time High-Fidelity Video Dubbing via Spatio-Temporal Sampling,
Yue Zhang, Zhizhou Zhong, Minhao Liu, Zhaokang Chen, Bin Wu, Yubin Zeng, Chao Zhan, Yingjie He, Junxin Huang, and Wenjiang Zhou. MuseTalk: Real-Time High-Fidelity Video Dubbing via Spatio-Temporal Sampling, . 2
-
[43]
Flow-guided one-shot talking face generation with a high-resolution audio-visual dataset
Zhimeng Zhang, Lincheng Li, Yu Ding, and Changjie Fan. Flow-guided one-shot talking face generation with a high-resolution audio-visual dataset. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021. 5
2021
-
[44]
Media2Face: Co-speech Facial Ani- mation Generation With Multi-Modality Guidance, 2024
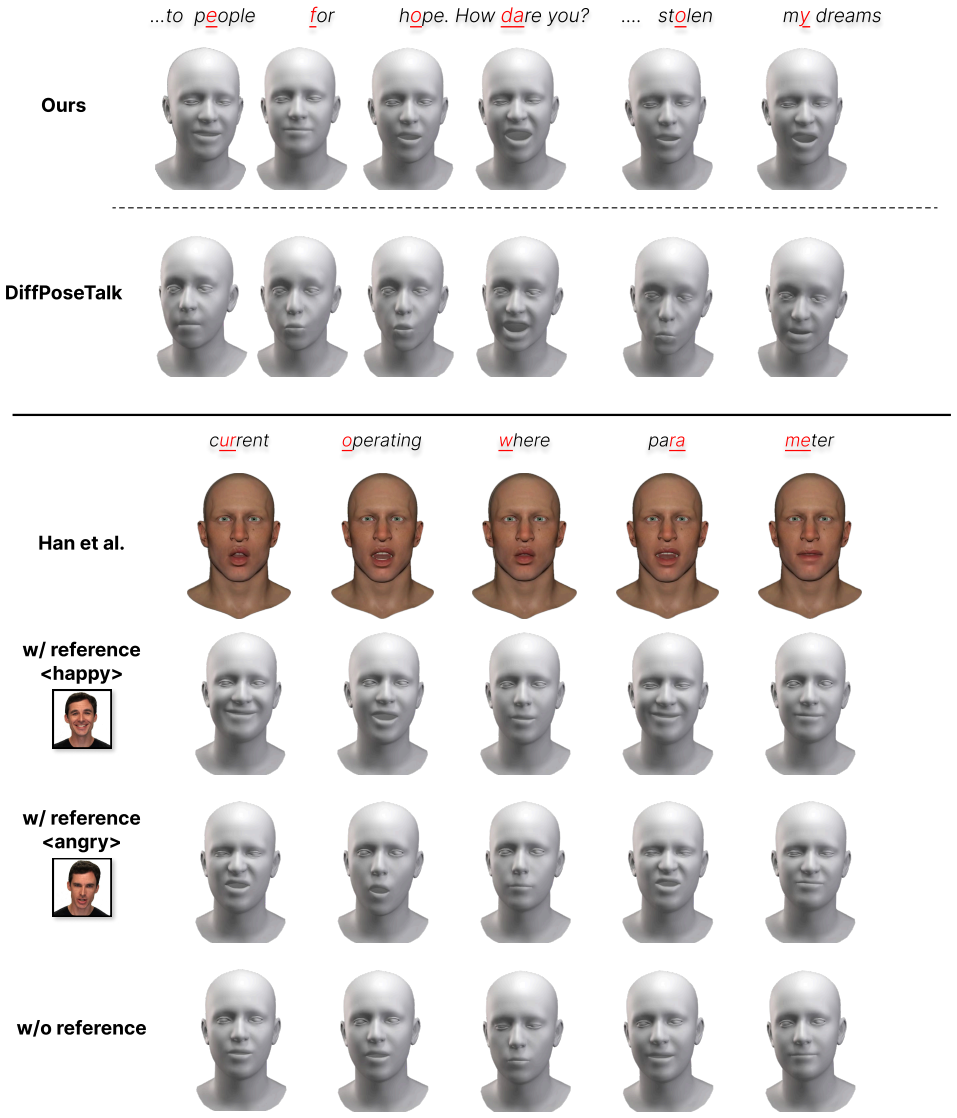
Qingcheng Zhao, Pengyu Long, Qixuan Zhang, Dafei Qin, Han Liang, Longwen Zhang, Yingliang Zhang, Jingyi Yu, and Lan Xu. Media2Face: Co-speech Facial Ani- mation Generation With Multi-Modality Guidance, 2024. arXiv:2401.15687 [cs]. 2, 3 ...t o p ople or h pe. Ho w r e y ou? .... st len m dr eams e f o da o y c r ent ur o perating w her e pa ra me t er Ours...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.