DynaTree: Dynamic Agentic Retrieval Tree for Time-Sensitive News Retrieval
Pith reviewed 2026-06-28 20:49 UTC · model grok-4.3
The pith
DynaTree builds a reusable retrieval tree offline with agents then selects subtrees daily via lightweight proxy to handle time-sensitive news without ongoing reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DynaTree performs offline agentic construction of a retrieval tree that materializes the semantic space of a query topic, then executes online lightweight daily subtree selection over a time-localized evaluation proxy without further agentic reasoning, tree modification, or retraining, delivering improved recall, ranking, and production survival rates on time-sensitive news tasks.
What carries the argument
The offline-constructed retrieval tree that materializes topic semantics for later lightweight daily subtree selection via time-localized proxy.
If this is right
- DynaTree achieves strong recall and ranking on the multi-day Syft news benchmark and multiple BEIR datasets.
- The dynamically adapted variant raises survival rate from 0.32-0.53 to 0.59-0.73 over a fixed offline-selected subtree.
- It outperforms existing production recallers on every day of the January-February 2026 A/B test.
- Persistent structure-aware semantic expansion converts offline agentic reasoning into gains in coverage, freshness, and relevance.
Where Pith is reading between the lines
- The separation of expensive tree construction from cheap daily selection could let agentic methods scale to larger, slower-changing corpora by spreading cost over time.
- If the time-localized proxy remains predictive, the approach may reduce retraining frequency in production retrieval systems facing gradual topic drift.
- Similar offline-tree plus online-subtree logic might apply to other retrieval settings where semantic neighborhoods evolve on daily rather than minute timescales.
Load-bearing premise
Once built, the retrieval tree stays complete and stable enough that daily proxy-based subtree selection keeps performance high without any further agentic work or updates.
What would settle it
A day-by-day comparison in which the dynamically chosen subtree misses a substantial fraction of relevant documents that a full agentic search would retrieve, or in which survival rate falls below the fixed-subtree baseline on multiple evaluation days.
Figures

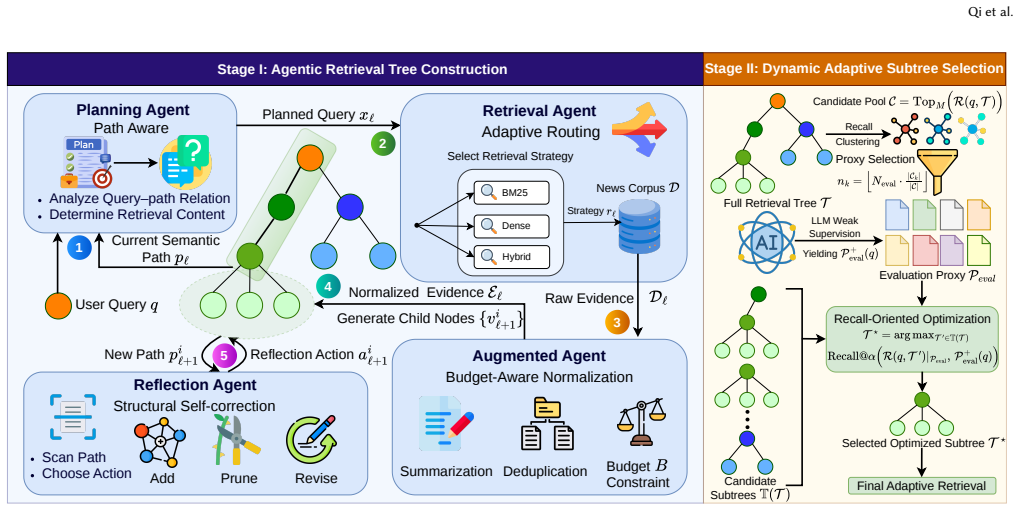
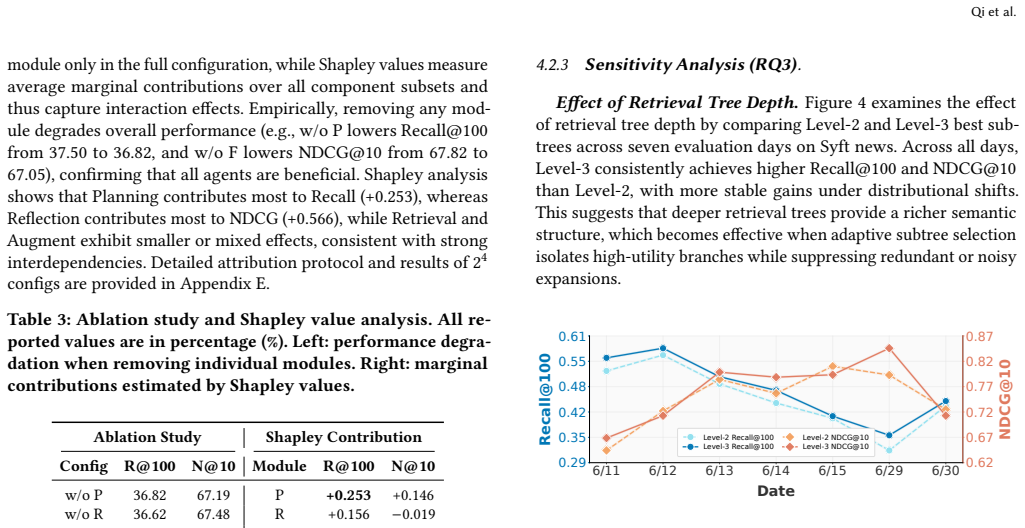
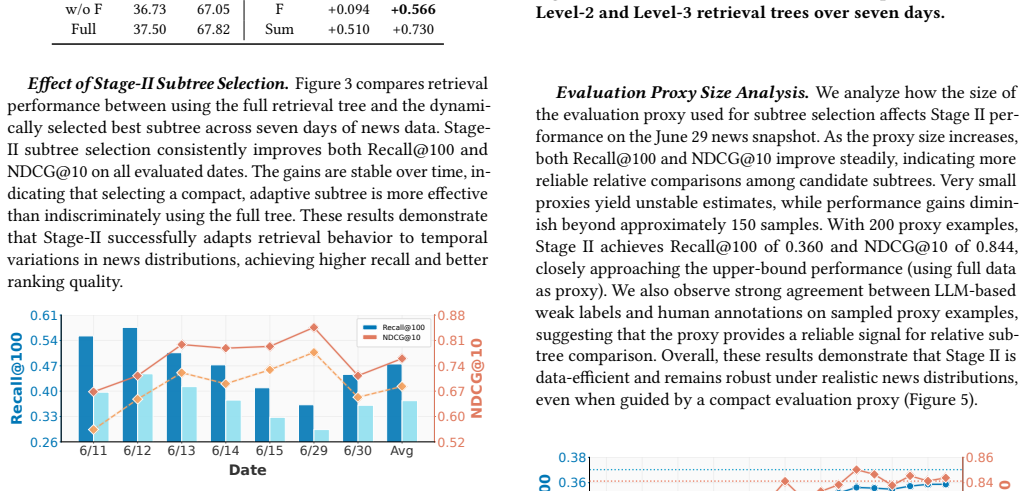
read the original abstract
Agentic Retrieval-Augmented Generation improves retrieval by integrating planning, tool use, and iterative reasoning, but existing agentic RAG methods often couple semantic expansion with retrieval decisions in short-horizon inference loops, leading to high inference cost and limited suitability for time-sensitive news retrieval. We propose DynaTree, a two-stage framework for efficient and adaptive news retrieval. In the offline stage, DynaTree uses coordinated agents to construct a reusable retrieval tree that materializes the semantic space of a query topic. In the online stage, DynaTree performs lightweight daily subtree selection over a time-localized evaluation proxy, without further agentic reasoning, tree modification, or retraining. Experiments on a multi-day Syft news benchmark and multiple BEIR datasets show that DynaTree achieves strong recall and ranking performance, consistently outperforming standard RAG and prior agentic baselines. We further deploy DynaTree in the Syft production system and evaluate it through online A/B testing from Jan. 28 to Feb. 6, 2026. The dynamically adapted variant improves survival rate from 0.32-0.53 to 0.59-0.73 over a fixed offline-selected subtree and outperforms existing production recallers on every evaluation day. These results show that persistent, structure-aware semantic expansion can translate offline agentic reasoning into practical improvements in coverage, freshness, and relevance for real-world news retrieval.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce DynaTree, a two-stage framework for efficient and adaptive news retrieval. The offline stage uses coordinated agents to build a reusable retrieval tree materializing the semantic space of a query topic. The online stage performs lightweight daily subtree selection over a time-localized evaluation proxy without further agentic reasoning, tree modification, or retraining. It reports strong recall and ranking performance on a multi-day Syft news benchmark and BEIR datasets, outperforming standard RAG and prior agentic baselines. In production A/B testing from Jan. 28 to Feb. 6, 2026, the dynamically adapted variant improves survival rate from 0.32-0.53 to 0.59-0.73 over a fixed offline-selected subtree and outperforms existing production recallers on every evaluation day.
Significance. If the results hold, this work could be significant for making agentic RAG practical in time-sensitive domains by decoupling expensive offline semantic expansion from efficient online adaptation. The use of a persistent retrieval tree and production deployment with A/B testing are notable strengths, providing evidence of real-world applicability in coverage, freshness, and relevance. The approach addresses high inference costs in existing agentic methods.
major comments (1)
- [Abstract] Abstract: The headline claim that the dynamically adapted variant improves survival rate from 0.32-0.53 to 0.59-0.73 and outperforms production recallers every day rests on the offline-constructed tree plus time-localized proxy being able to cover the semantic space of future news without tree modification or retraining. The manuscript provides no evidence, analysis, or experiments testing whether the proxy can surface subtrees for query semantics absent from the initial agentic construction (e.g., breaking events outside the materialized tree). This assumption is load-bearing for the central no-retraining claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline claim that the dynamically adapted variant improves survival rate from 0.32-0.53 to 0.59-0.73 and outperforms production recallers every day rests on the offline-constructed tree plus time-localized proxy being able to cover the semantic space of future news without tree modification or retraining. The manuscript provides no evidence, analysis, or experiments testing whether the proxy can surface subtrees for query semantics absent from the initial agentic construction (e.g., breaking events outside the materialized tree). This assumption is load-bearing for the central no-retraining claim.
Authors: We agree that the manuscript contains no dedicated experiments, ablation, or analysis that directly test the time-localized proxy's ability to surface relevant subtrees when query semantics lie entirely outside the semantic space materialized during offline agentic tree construction (for example, unanticipated breaking events). The production A/B results demonstrate consistent daily gains over the 10-day window, but these results were obtained within the distribution of events covered by the pre-built tree for the evaluated topics. We will revise the manuscript to explicitly acknowledge this boundary condition as a limitation of the current no-retraining claim and to qualify the scope of the reported gains. revision: yes
Circularity Check
No circularity; empirical claims rest on external benchmarks
full rationale
The paper presents a two-stage empirical framework (offline agentic tree construction, online subtree selection) whose performance is measured via direct comparisons on Syft news benchmark, BEIR datasets, and production A/B testing. No equations, fitted parameters, self-citations, or uniqueness theorems appear in the provided text that would reduce any result to its own inputs by construction. The derivation chain consists of system design followed by independent evaluation metrics, making the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Akari Asai, Zeqiu Wu, Yizhong Wang, Avi Sil, and Hannaneh Hajishirzi
-
[2]
InInternational Conference on Learning Representations, Vol
Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection. InInternational Conference on Learning Representations, Vol. 2024. 9112–9141. https://proceedings.iclr.cc/paper_files/paper/2024/file/ 25f7be9694d7b32d5cc670927b8091e1-Paper-Conference.pdf
2024
-
[3]
Aslam, Matthew Ekstrand-Abueg, Virgil Pavlu, Fernando Diaz, Richard McCreadie, and Tetsuya Sakai
Javed A. Aslam, Matthew Ekstrand-Abueg, Virgil Pavlu, Fernando Diaz, Richard McCreadie, and Tetsuya Sakai. 2014. TREC 2014 Temporal Summarization Track Overview. InProceedings of The Twenty-Third Text REtrieval Conference, TREC 2014, Gaithersburg, Maryland, USA, November 19-21, 2014 (NIST Special Publication). http://trec.nist.gov/pubs/trec23/papers/overv...
2014
-
[4]
Hiteshwar Kumar Azad and Akshay Deepak. 2019. Query expansion techniques for information retrieval: A survey.Inf. Process. Manage.56, 5 (Sept. 2019), 1698–1735. doi:10.1016/j.ipm.2019.05.009
-
[5]
Andy Brock, Michela Paganini, Geoffrey Irving, Oriol Vinyals, Simon Osindero, Karen Simonyan, Jack Rae, Erich Elsen, and Laurent Sifre
Sebastian Borgeaud, Arthur Mensch, Jordan Hoffmann, Trevor Cai, Eliza Ruther- ford, Katie Millican, George Bm Van Den Driessche, Jean-Baptiste Lespiau, Bog- dan Damoc, Aidan Clark, Diego De Las Casas, Aurelia Guy, Jacob Menick, Roman Ring, Tom Hennigan, Saffron Huang, Loren Maggiore, Chris Jones, Albin Cassirer, Qi et al. Andy Brock, Michela Paganini, Geo...
2022
-
[6]
Claudio Carpineto and Giovanni Romano. 2012. A Survey of Automatic Query Expansion in Information Retrieval.ACM Comput. Surv.44, 1, Article 1 (Jan. 2012), 50 pages. doi:10.1145/2071389.2071390
-
[7]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. 2025. Gemini 2.5: Pushing the frontier with advanced reasoning, multi- modality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261(2025). https://arxiv.org/abs/2507.06261
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Anlei Dong, Yi Chang, Zhaohui Zheng, Gilad Mishne, Jing Bai, Ruiqiang Zhang, Karolina Buchner, Ciya Liao, and Fernando Diaz. 2010. Towards recency ranking in web search. InProceedings of the Third ACM International Conference on Web Search and Data Mining. 11–20. doi:10.1145/1718487.1718490
-
[9]
Anlei Dong, Ruiqiang Zhang, Pranam Kolari, Jing Bai, Fernando Diaz, Yi Chang, Zhaohui Zheng, and Hongyuan Zha. 2010. Time is of the essence: improving recency ranking using Twitter data. InProceedings of the 19th International Conference on World Wide Web. 331–340. doi:10.1145/1772690.1772725
-
[10]
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, Dasha Metropolitansky, Robert Osazuwa Ness, and Jonathan Larson. 2025. From Local to Global: A Graph RAG Approach to Query-Focused Summarization. arXiv:2404.16130 [cs.CL] https://arxiv.org/abs/2404.16130
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Jonathan L. Elsas and Susan T. Dumais. 2010. Leveraging temporal dynamics of document content in relevance ranking. InProceedings of the Third ACM International Conference on Web Search and Data Mining (WSDM ’10). 1–10. doi:10.1145/1718487.1718489
-
[12]
Frank, Steven J
John R. Frank, Steven J. Bauer, Max Kleiman-Weiner, Daniel A. Roberts, Nilesh Tripuraneni, Ce Zhang, Christopher Ré, Ellen M. Voorhees, and Ian Sobo- roff. 2013. Evaluating Stream Filtering for Entity Profile Updates for TREC
2013
-
[13]
http://trec.nist.gov/pubs/trec22/papers/KBA.OVERVIEW.pdf
InProceedings of The Twenty-Second Text REtrieval Conference, TREC 2013, Gaithersburg, Maryland, USA, November 19-22, 2013 (NIST Special Publication). http://trec.nist.gov/pubs/trec22/papers/KBA.OVERVIEW.pdf
2013
-
[14]
Luyu Gao, Xueguang Ma, Jimmy Lin, and Jamie Callan. 2023. Precise Zero-Shot Dense Retrieval without Relevance Labels. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 1762–1777. doi:10.18653/v1/2023.acl-long.99
-
[15]
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, Meng Wang, and Haofen Wang. 2024. Retrieval-Augmented Generation for Large Language Models: A Survey. arXiv:2312.10997 [cs.CL] https://arxiv.org/abs/2312.10997
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Gautier Izacard and Edouard Grave. 2021. Leveraging Passage Retrieval with Generative Models for Open Domain Question Answering. InProceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume. 874–880. doi:10.18653/v1/2021.eacl-main.74
-
[17]
Nattiya Kanhabua and Avishek Anand. 2016. Temporal Information Retrieval. InProceedings of the 39th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR ’16). 1235–1238. doi:10.1145/2911451. 2914805
-
[18]
Victor Lavrenko and W. Bruce Croft. 2001. Relevance based language models. In Proceedings of the 24th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR ’01). 120–127. doi:10.1145/ 383952.383972
-
[19]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. 2020. Retrieval-augmented generation for knowledge-intensive NLP tasks. InProceedings of the 34th Inter- national Conference on Neural Information Processing Systems (...
2020
-
[20]
Minghan Li, Xinxuan Lv, Junjie Zou, Tongna Chen, Chao Zhang, Suchao An, Ercong Nie, and Guodong Zhou. 2026. Query Expansion in the Age of Pre-trained and Large Language Models: A Comprehensive Survey. arXiv:2509.07794 [cs.IR] https://arxiv.org/abs/2509.07794
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[21]
Xiaoyan Li and W. Bruce Croft. 2003. Time-based language models. InProceedings of the Twelfth International Conference on Information and Knowledge Management (CIKM ’03). 469–475. doi:10.1145/956863.956951
-
[22]
Xinbei Ma, Yeyun Gong, Pengcheng He, Hai Zhao, and Nan Duan. 2023. Query Rewriting in Retrieval-Augmented Large Language Models. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 5303–5315. doi:10.18653/v1/2023.emnlp-main.322
-
[23]
Bhawna Piryani, Abdelrahman Abdallah, Jamshid Mozafari, Avishek Anand, and Adam Jatowt. 2026. It’s High Time: A Survey of Temporal Question Answering. arXiv:2505.20243 [cs.CL] https://arxiv.org/abs/2505.20243
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[24]
Parth Sarthi, Salman Abdullah, Aditi Tuli, Shubh Khanna, Anna Goldie, and Christopher D. Manning. 2024. RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. https://openreview. net/forum?id=GN921JHCRw
2024
-
[25]
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. 2023. Reflexion: language agents with verbal reinforcement learn- ing. InProceedings of the 37th International Conference on Neural Information Processing Systems (NIPS ’23). Article 377, 19 pages
2023
-
[26]
Agentic Retrieval-Augmented Generation: A Survey on Agentic RAG
Aditi Singh, Abul Ehtesham, Saket Kumar, Tala Talaei Khoei, and Athanasios V. Vasilakos. 2026. Agentic Retrieval-Augmented Generation: A Survey on Agentic RAG. arXiv:2501.09136 [cs.AI] https://arxiv.org/abs/2501.09136
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[27]
Yixuan Tang, Yuanyuan Shi, Yiqun Sun, and Anthony Kum Hoe Tung. 2025. Uncovering the Bigger Picture: Comprehensive Event Understanding Via Diverse News Retrieval. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 33939–33957. doi:10.18653/v1/2025.emnlp-main. 1722
-
[28]
Nandan Thakur, Nils Reimers, Andreas Rücklé, Abhishek Srivastava, and Iryna Gurevych. 2021. BEIR: A Heterogenous Benchmark for Zero-shot Evaluation of Information Retrieval Models. arXiv:2104.08663 [cs.IR] https://arxiv.org/abs/ 2104.08663
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[29]
Tu Vu, Mohit Iyyer, Xuezhi Wang, Noah Constant, Jerry Wei, Jason Wei, Chris Tar, Yun-Hsuan Sung, Denny Zhou, Quoc Le, and Thang Luong. 2024. Fresh- LLMs: Refreshing Large Language Models with Search Engine Augmentation. In Findings of the Association for Computational Linguistics: ACL 2024. 13697–13720. doi:10.18653/v1/2024.findings-acl.813
-
[30]
Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, Wayne Xin Zhao, Zhewei Wei, and Jirong Wen. 2024. A survey on large language model based autonomous agents.Frontiers of Computer Science18, 6 (March 2024). doi:10.1007/s11704- 024-40231-1
-
[31]
Yining Wang, Liwei Wang, Yuanzhi Li, Di He, and Tie-Yan Liu. 2013. A Theoretical Analysis of NDCG Type Ranking Measures. InProceedings of the 26th Annual Conference on Learning Theory (Proceedings of Machine Learning Research, Vol. 30). 25–54. https://proceedings.mlr.press/v30/Wang13.html
2013
-
[32]
Yingxuan Yang, Bo Huang, Siyuan Qi, Chao Feng, Haoyi Hu, Yuxuan Zhu, Jinbo Hu, Haoran Zhao, Ziyi He, Xiao Liu, Muning Wen, Zongyu Wang, Lin Qiu, Xuezhi Cao, Xunliang Cai, Yong Yu, and Weinan Zhang. 2025. Understanding and Optimizing Agentic Workflows via Shapley value. arXiv:2502.00510 [cs.AI] https://arxiv.org/abs/2502.00510
-
[33]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. ReAct: Synergizing Reasoning and Acting in Language Models. arXiv:2210.03629 [cs.CL] https://arxiv.org/abs/2210.03629
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[34]
Zijun Yao, Weijian Qi, Liangming Pan, Shulin Cao, Linmei Hu, Liu Weichuan, Lei Hou, and Juanzi Li. 2025. SeaKR: Self-aware Knowledge Retrieval for Adaptive Retrieval Augmented Generation. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 27022–27043. doi:10.18653/v1/2025.acl-long.1312
-
[35]
Andy Zhou, Kai Yan, Michal Shlapentokh-Rothman, Haohan Wang, and Yu- Xiong Wang. 2024. Language agent tree search unifies reasoning, acting, and planning in language models. InProceedings of the 41st International Conference on Machine Learning (ICML’24). Article 2572, 23 pages
2024
-
[36]
Xiangrong Zhu, Yuexiang Xie, Yi Liu, Yaliang Li, and Wei Hu. 2025. Knowledge Graph-Guided Retrieval Augmented Generation. InProceedings of the 2025 Con- ference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 8912–8924. doi:10.18653/v1/2025.naacl-long.449
-
[37]
Yutao Zhu, Huaying Yuan, Shuting Wang, Jiongnan Liu, Wenhan Liu, Chenlong Deng, Haonan Chen, Zheng Liu, Zhicheng Dou, and Ji-Rong Wen. 2025. Large Language Models for Information Retrieval: A Survey.ACM Trans. Inf. Syst.44, 1, Article 12 (Nov. 2025), 54 pages. doi:10.1145/3748304 A Algorithmic Description Algorithm 1 presents the complete algorithmic desc...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.