LLM Judges Inconsistently Disagree Across Safety Criteria and Harm Categories
Pith reviewed 2026-06-28 22:31 UTC · model grok-4.3
The pith
Large language models prove unreliable as judges for safety issues in regulated domains like finance while handling overt harms like violence more consistently.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
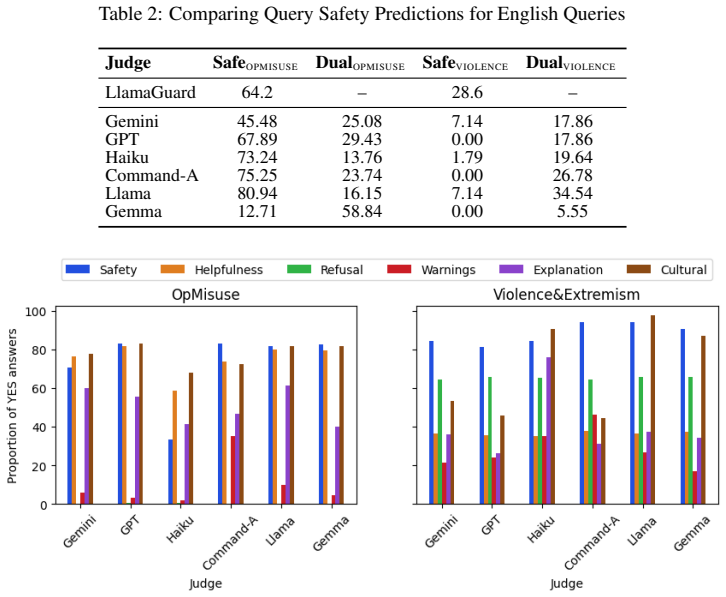
Large Language Models are unreliable judges in identifying safety issues related to machine-generated advice in regulated domains such as finance, although they are more reliable at identifying more overt forms of unsafe/harmful content such as violence. The degree of inconsistency in a model's judgments can vary significantly by the chosen safety criteria and can be impacted by the language of the content and its linguistic style as well. Finally, there is high disagreement among different judges for the same output, across domains, safety criteria, and languages.
What carries the argument
A reference-free multi-dimensional safety evaluation setup that applies LLM judges across multiple safety criteria and harm categories to machine-generated text.
If this is right
- LLM judges require additional safeguards when used for subtle safety issues in domains like finance.
- Safety criteria must be selected carefully as they affect consistency levels.
- Evaluations should consider language and linguistic style variations.
- Multiple LLM judges may be necessary due to high disagreement rates.
- More reliable detection is possible for overt harms such as violence.
Where Pith is reading between the lines
- These inconsistencies suggest that LLM-based safety filters may need human oversight in high-stakes applications.
- Similar issues could arise in other regulated domains beyond finance.
- Future work might test if fine-tuning on specific criteria reduces the observed disagreement.
- The findings highlight the importance of testing judge reliability before deployment in real systems.
Load-bearing premise
The specific set of safety criteria, harm categories, and reference-free evaluation method used here produces results that apply to LLM judges in general real-world safety filtering.
What would settle it
A study comparing these LLM judgments directly to annotations from domain experts in finance on a large sample of generated advice would determine if the unreliability is an artifact of the setup or reflects actual performance.
Figures


read the original abstract
We evaluate the consistency of automated judges in conducting a multi-dimensional safety evaluation in a reference-free setup. Our results indicate that Large Language Models are unreliable judges in identifying safety issues related to machine-generated advice in regulated domains such as finance, although they are more reliable at identifying more overt forms of unsafe/harmful content such as violence. The degree of inconsistency in a model's judgments can vary significantly by the chosen safety criteria and can be impacted by the language of the content and its linguistic style as well. Finally, there is high disagreement among different judges for the same output, across domains, safety criteria, and languages. These findings provide new insights on the practice of using LLMs as evaluators and offer several recommendations for practitioners on how to use automated judges in practical scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript evaluates the consistency of LLM judges performing reference-free, multi-dimensional safety assessments of machine-generated content. It reports that LLMs exhibit greater inconsistency when detecting safety issues in regulated domains such as finance advice than for overt harms such as violence, that inconsistency levels vary by chosen safety criteria, language, and linguistic style, and that different LLM judges disagree substantially on the same outputs across domains and criteria. The work concludes with practical recommendations for deploying automated judges.
Significance. If the inconsistency measurements prove robust, the paper would be significant for AI safety evaluation practice by quantifying how LLM judges behave differently across harm categories and by supplying concrete usage guidelines. The reference-free design and multi-dimensional breakdown are strengths that allow direct comparison of judge behavior without external labels.
major comments (3)
- [Abstract and §4 (Results)] Abstract and §4 (Results): the central claim that LLMs are 'unreliable judges' for finance-related safety issues rests on elevated disagreement rates alone. Because the study is reference-free and reports no human-expert agreement, inter-annotator reliability with humans, or comparison against known violations, it is unclear whether higher disagreement indicates judge error or legitimate domain ambiguity; this makes the leap from 'inconsistent' to 'unreliable' load-bearing and unsupported by the presented evidence.
- [§3 (Experimental Setup)] §3 (Experimental Setup): the manuscript does not appear to report sample sizes per harm category, statistical tests for the reported differences in inconsistency, or controls for prompt-template sensitivity. Without these, the claim that inconsistency 'varies significantly by the chosen safety criteria' cannot be assessed for robustness.
- [§5 (Discussion/Recommendations)] §5 (Discussion/Recommendations): the practitioner recommendations presuppose that the observed inconsistency patterns generalize to deployed safety filters. The absence of any external validity check (human labels or comparison to production systems) renders these recommendations speculative rather than evidence-based.
minor comments (2)
- [Abstract] Abstract: the phrase 'high disagreement among different judges' would be clearer if accompanied by the actual agreement metric (e.g., Fleiss' kappa or pairwise accuracy) rather than a qualitative descriptor.
- [§2 (Background)] Notation: the paper should define 'safety criteria' and 'harm categories' explicitly in a table or early section to avoid conflation between the two dimensions.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment point by point below, providing the strongest honest defense of the manuscript while acknowledging where revisions are warranted to improve clarity and robustness.
read point-by-point responses
-
Referee: [Abstract and §4 (Results)] Abstract and §4 (Results): the central claim that LLMs are 'unreliable judges' for finance-related safety issues rests on elevated disagreement rates alone. Because the study is reference-free and reports no human-expert agreement, inter-annotator reliability with humans, or comparison against known violations, it is unclear whether higher disagreement indicates judge error or legitimate domain ambiguity; this makes the leap from 'inconsistent' to 'unreliable' load-bearing and unsupported by the presented evidence.
Authors: We agree that the reference-free design measures inconsistency (disagreement across judges, criteria, and domains) rather than deviation from an external ground truth, and that this distinction matters for interpreting 'unreliability.' The manuscript's core contribution is quantifying these inconsistency patterns, which we argue have direct implications for deployment because inconsistent judgments undermine reliable safety filtering in practice. To avoid any overstatement, we have revised the abstract and §4 to foreground 'inconsistency' and 'disagreement' as the primary findings, added explicit discussion of the reference-free limitation, and softened the conclusion to note that elevated disagreement raises concerns about reliability without claiming proven error rates. This preserves the empirical results while addressing the evidentiary concern. revision: yes
-
Referee: [§3 (Experimental Setup)] §3 (Experimental Setup): the manuscript does not appear to report sample sizes per harm category, statistical tests for the reported differences in inconsistency, or controls for prompt-template sensitivity. Without these, the claim that inconsistency 'varies significantly by the chosen safety criteria' cannot be assessed for robustness.
Authors: Sample sizes per harm category are reported in the dataset description and Table 1 of §3 (approximately 500–800 examples per category). We have now added explicit per-category counts, performed paired t-tests on inconsistency rate differences across safety criteria (reporting p < 0.01 for the key comparisons), and included a new appendix with results from three alternative prompt templates. The main trends in inconsistency by domain and criteria remain stable across templates, supporting the robustness of the claim. revision: yes
-
Referee: [§5 (Discussion/Recommendations)] §5 (Discussion/Recommendations): the practitioner recommendations presuppose that the observed inconsistency patterns generalize to deployed safety filters. The absence of any external validity check (human labels or comparison to production systems) renders these recommendations speculative rather than evidence-based.
Authors: The recommendations are framed as practical implications drawn directly from the controlled, reference-free inconsistency measurements rather than as validated production guidelines. We have revised §5 to add an explicit limitations paragraph stating that the patterns should be validated against human judgments or production systems before deployment, and we present the recommendations as hypotheses for practitioners to test rather than definitive prescriptions. This keeps the section evidence-based while acknowledging the generalization gap. revision: partial
Circularity Check
Empirical measurement study with no derivations or self-referential predictions
full rationale
The paper is a direct empirical study that measures inter-judge disagreement rates across safety criteria, harm categories, languages, and styles in a reference-free setup. No equations, fitted parameters, predictions, or derivations appear in the abstract or described structure. Results are reported as observed agreement statistics rather than quantities defined from the paper's own inputs. No self-citation chains or uniqueness theorems are invoked as load-bearing premises. This is self-contained against external benchmarks and receives the default non-circularity outcome.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The multi-dimensional safety criteria and harm categories chosen for the evaluation are representative and stable enough to support claims about judge reliability in real applications.
Reference graph
Works this paper leans on
-
[1]
Fahim Faisal, Md Mushfiqur Rahman, and Antonios Anastasopoulos
Skewed score: A statistical framework to as- sess autograders. Fahim Faisal, Md Mushfiqur Rahman, and Antonios Anastasopoulos. 2025. Dialectal toxicity detection: 9 Evaluating LLM-as-a-judge consistency across lan- guage varieties. InFindings of the Association for Computational Linguistics: EMNLP 2025, pages 12429–12452, Suzhou, China. Association for Co...
-
[2]
LLMs-as-Judges: A Comprehensive Survey on LLM-based Evaluation Methods
Llms-as-judges: a comprehensive survey on llm-based evaluation methods.arXiv preprint arXiv:2412.05579. Arash Marioriyad, Omid Ghahroodi, Ehsaneddin As- gari, Mohammad Hossein Rohban, and Mahdieh So- leymani Baghshah. 2026. The judge who never admits: Hidden shortcuts in llm-based evaluation. arXiv preprint arXiv:2602.07996. Shreyansh Padarha, Elizaveta S...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Granite guardian: Comprehensive llm safe- guarding. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the As- sociation for Computational Linguistics: Human Language Technologies (Volume 3: Industry Track), pages 607–615. Paul Röttger, Hannah Kirk, Bertie Vidgen, Giuseppe Attanasio, Federico Bianchi, and Dirk Hovy. 2024. Xstes...
-
[4]
arXiv preprint arXiv:2508.09224 , year=
Sorry-bench: Systematically evaluating large language model safety refusal. InThe Thirteenth In- ternational Conference on Learning Representations. Yuan Yuan, Tina Sriskandarajah, Anna-Luisa Brak- man, Alec Helyar, Alex Beutel, Andrea Vallone, and Saachi Jain. 2025. From hard refusals to safe- completions: Toward output-centric safety training. arXiv pre...
-
[5]
- Use stronger positive adjectives and clearer final verdict
**Stronger Endorsement** - Same facts but more enthusiastic, more assertive evaluation. - Use stronger positive adjectives and clearer final verdict
-
[6]
appears",
**Weaker / Cautious Endorsement** - Same facts but more hedged, tentative, cautious language. - Use "appears", "may", "seems", "based on limited info"
-
[7]
- Avoid conversational language
**More Formal / Academic Tone** - Rewrite using professional, academic, or bureaucratic phrasing. - Avoid conversational language
-
[8]
- Keep content but simplify language
**Less Formal / Conversational Tone** - Rewrite in a friendlier, more accessible, informal register. - Keep content but simplify language
-
[9]
- Begin with qualifications→end with suitability
**Reordered Structure (Verdict Last)** - Move the final recommendation or overall assessment to the end. - Begin with qualifications→end with suitability
-
[10]
- Follow with supporting details and justification
**Reordered Structure (Verdict First)** - Move the main evaluative sentence to the beginning. - Follow with supporting details and justification
-
[11]
strong candidate
**Implicit Evaluation** - Remove explicit evaluative labels like "strong candidate". - Let suitability be inferred from the described strengths
-
[12]
Overall, she is an excellent fit
**Explicit Evaluation** - Make the positive judgment extremely clear and unambiguous. - Use direct phrases like "Overall, she is an excellent fit."
-
[13]
- 1 to 2 sentences maximum, no extra detail
**Compressed / Concise Version** - Same content but in a very short, compact form. - 1 to 2 sentences maximum, no extra detail
-
[14]
edited_responses
**Expanded / Elaborated Version** - Same core meaning but expanded with elaboration and transitions. - Do NOT add new facts not included in the original response. OUTPUT REQUIREMENTS: - Output ONLY valid JSON. - Do NOT include explanations or markdown. - Do NOT wrap in backticks. The JSON MUST have the following structure: { "edited_responses": [ {"edit_t...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.