Astra: a generalizable report generation foundation model for 3D computed tomography
Pith reviewed 2026-06-28 23:14 UTC · model grok-4.3
The pith
Astra generates style-consistent and diagnostically accurate reports from 3D CT scans across institutions by harmonizing report styles and using reinforcement learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
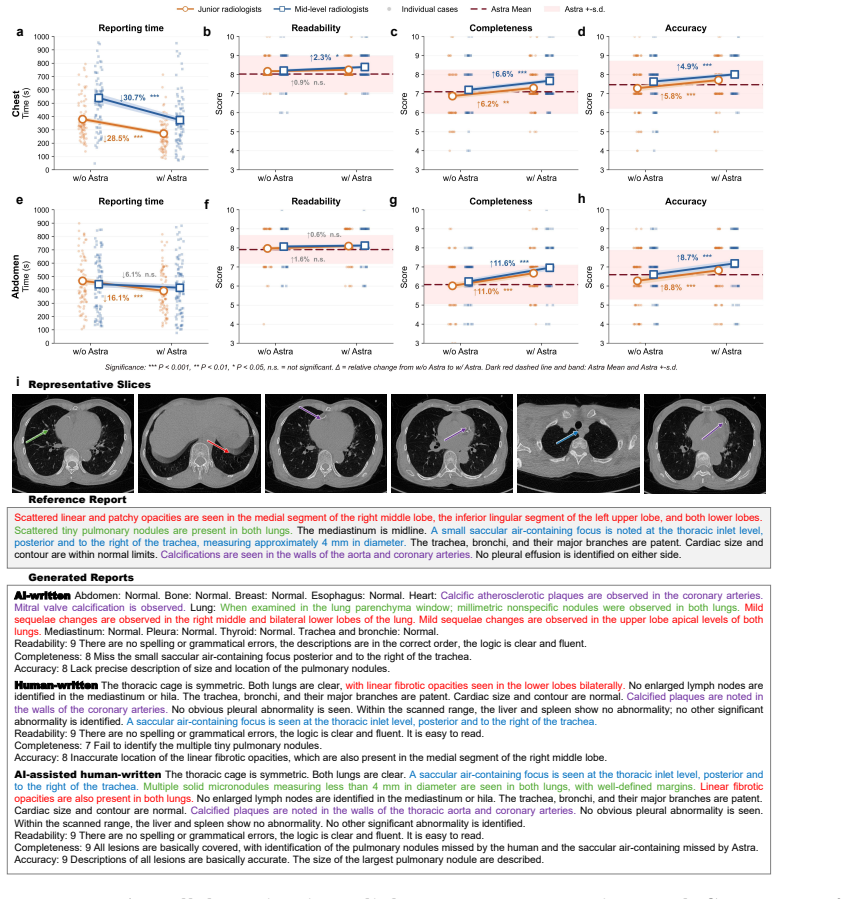
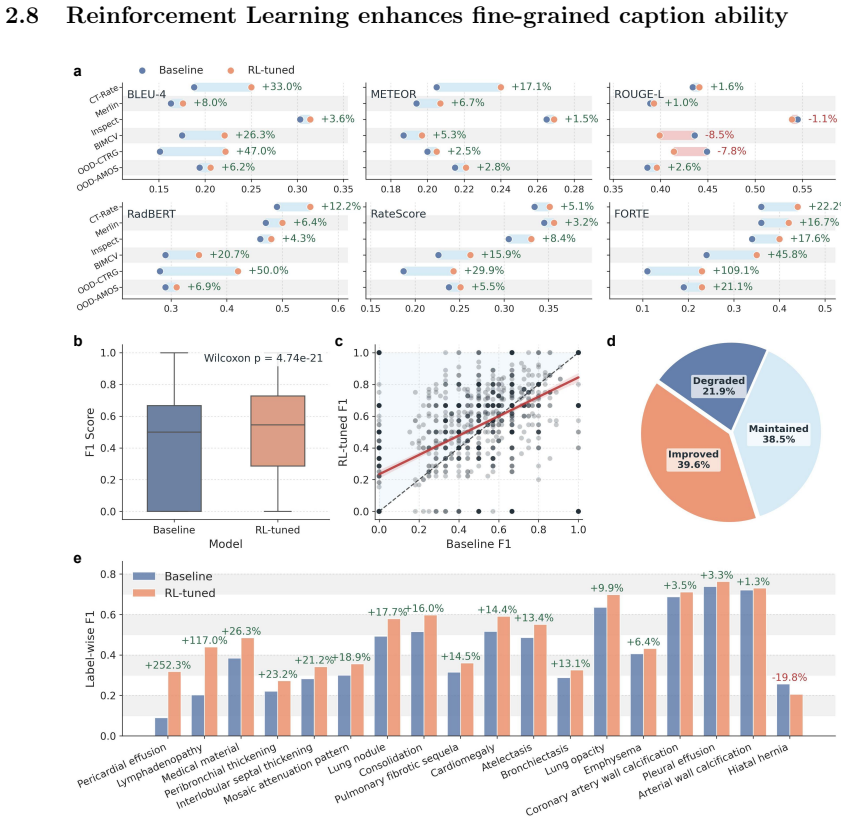
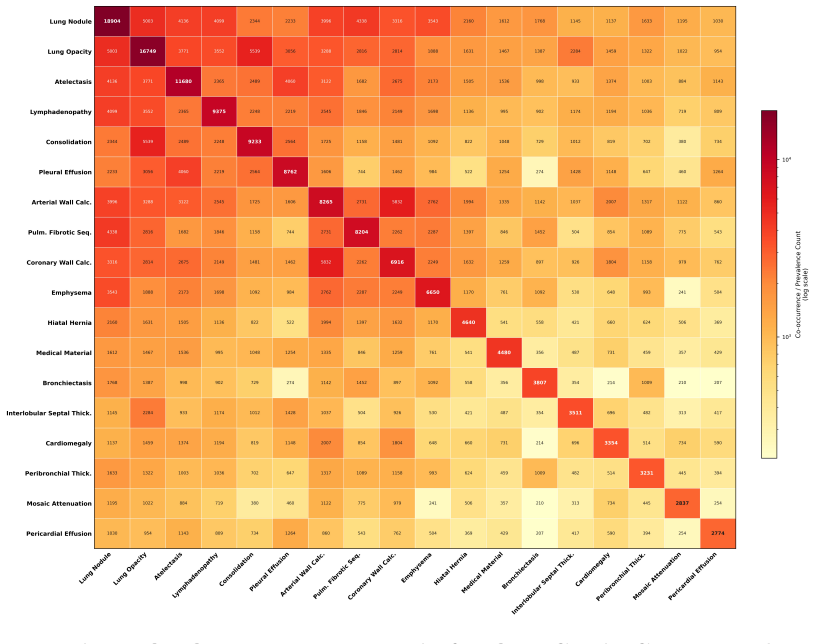
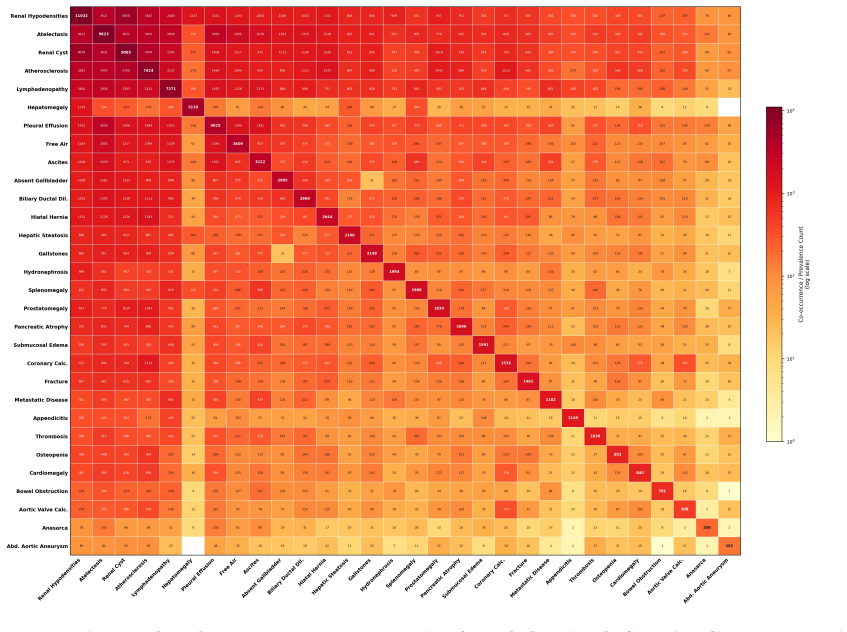
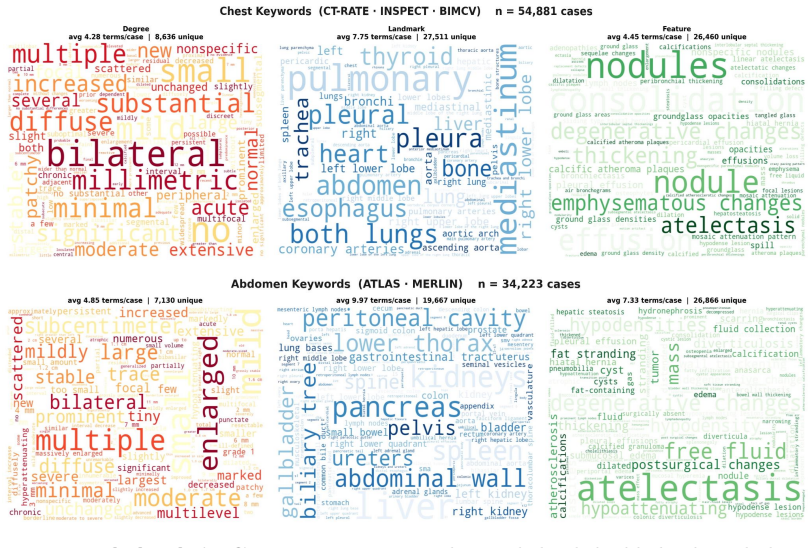
Astra, trained on 90,678 thoracoabdominal CT-report pairs spanning eight organ systems, employs report style harmonization and reinforcement learning to produce style-consistent and diagnostically accurate reports that generalize across diverse anatomical regions and institutions, delivering a 44.1 percent average gain in fine-grained diagnostic metrics on the main dataset and six external cohorts while accelerating chest report drafting by 29.6 percent and raising abdominal report completeness by 11.3 percent in real clinical workflows.
What carries the argument
Report style harmonization combined with reinforcement learning for diagnostic consistency, applied to a large multi-region CT-report dataset.
If this is right
- Astra assistance reduces time to draft chest reports by 29.6 percent in live clinical settings.
- Astra raises completeness of abdominal reports by 11.3 percent with statistical significance.
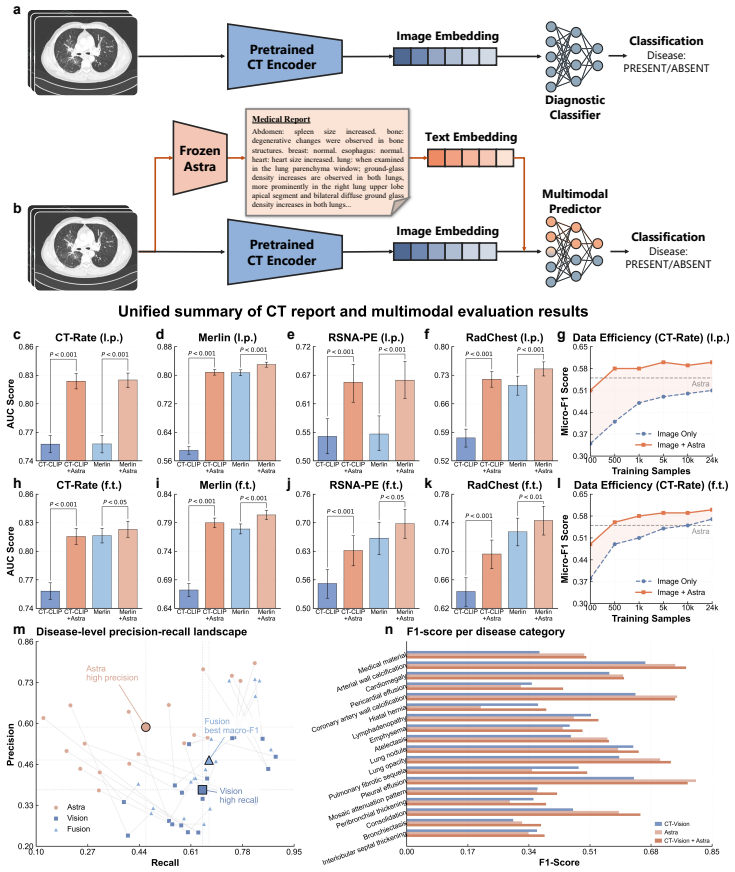
- The model improves performance on downstream CT diagnostic tasks when used for pretraining or data synthesis.
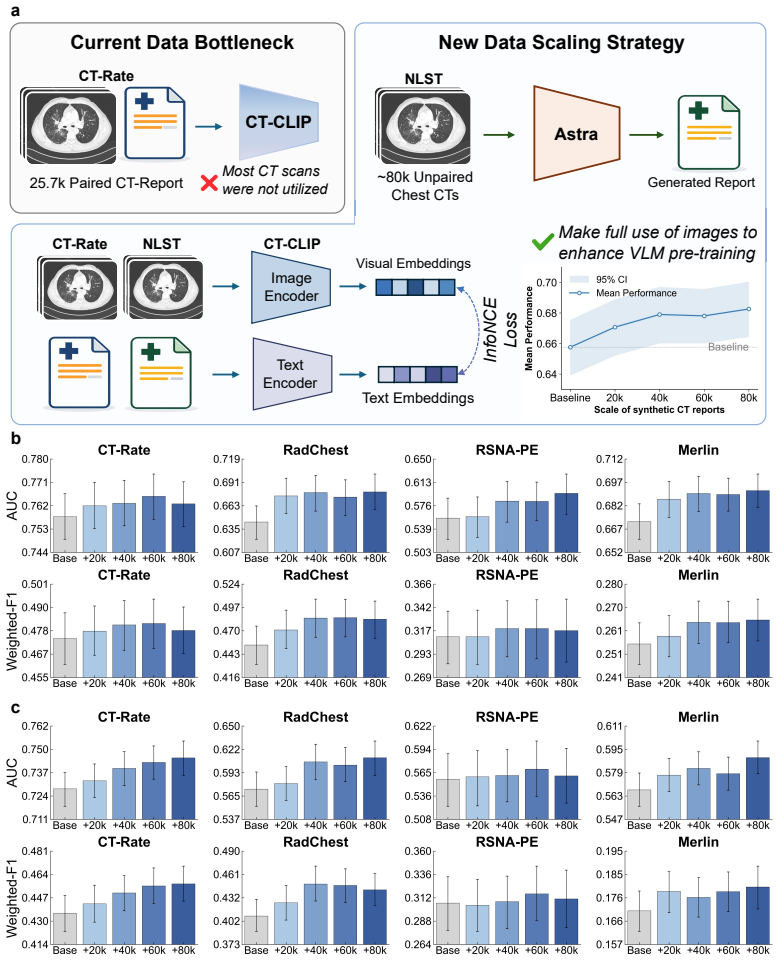
- High-quality synthetic reports from Astra scale vision-language pretraining for other CT AI models.
- The same training approach supports multi-region reporting that remains robust outside the original training distribution.
Where Pith is reading between the lines
- The style-harmonization step could transfer to report generation for other volumetric modalities such as MRI if similar terminology differences appear across sites.
- Widespread use might reduce inter-institution variability in how findings are described, affecting how referring physicians interpret results.
- Synthetic reports produced by the model could fill gaps in training data for rare conditions without requiring new manual annotations.
- Embedding the model in reporting software might shift radiologist effort from initial drafting toward verification and refinement of AI output.
Load-bearing premise
The six external cohorts capture enough real-world variation in reporting style and diagnostic practice, and the fine-grained metrics measure clinical accuracy independently of the harmonization step used in training.
What would settle it
Performance measurements on a fresh external cohort from an unseen institution that show no improvement over prior methods in diagnostic metrics or no gain in workflow completeness and speed.
Figures



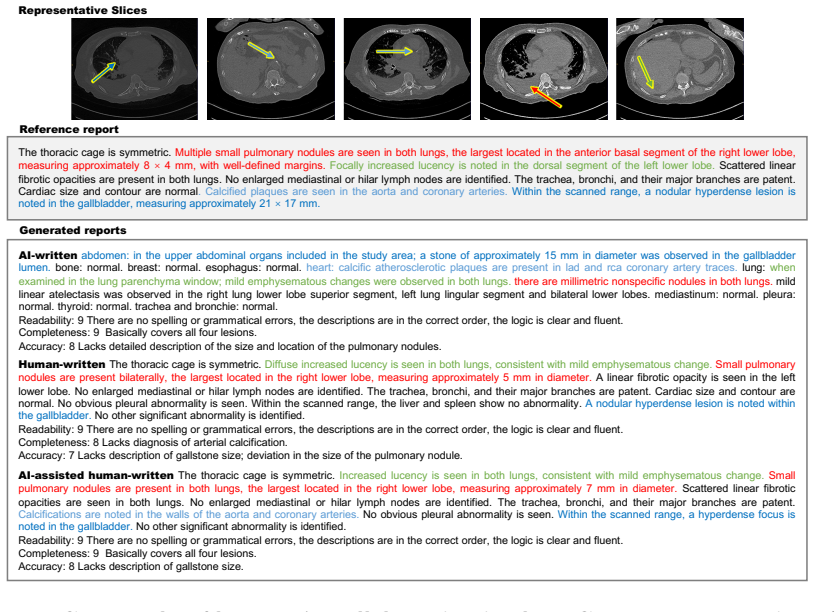
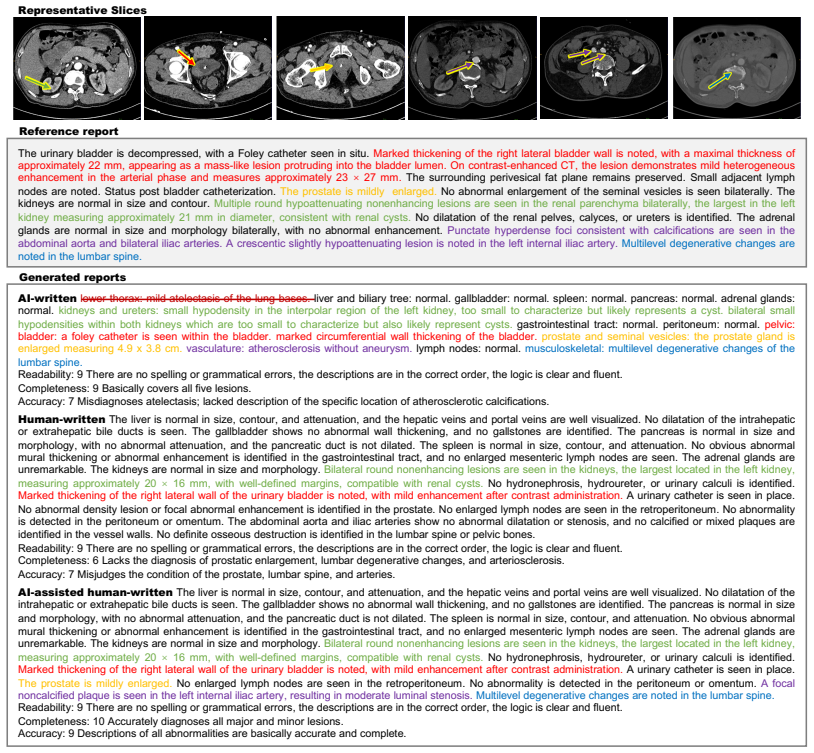
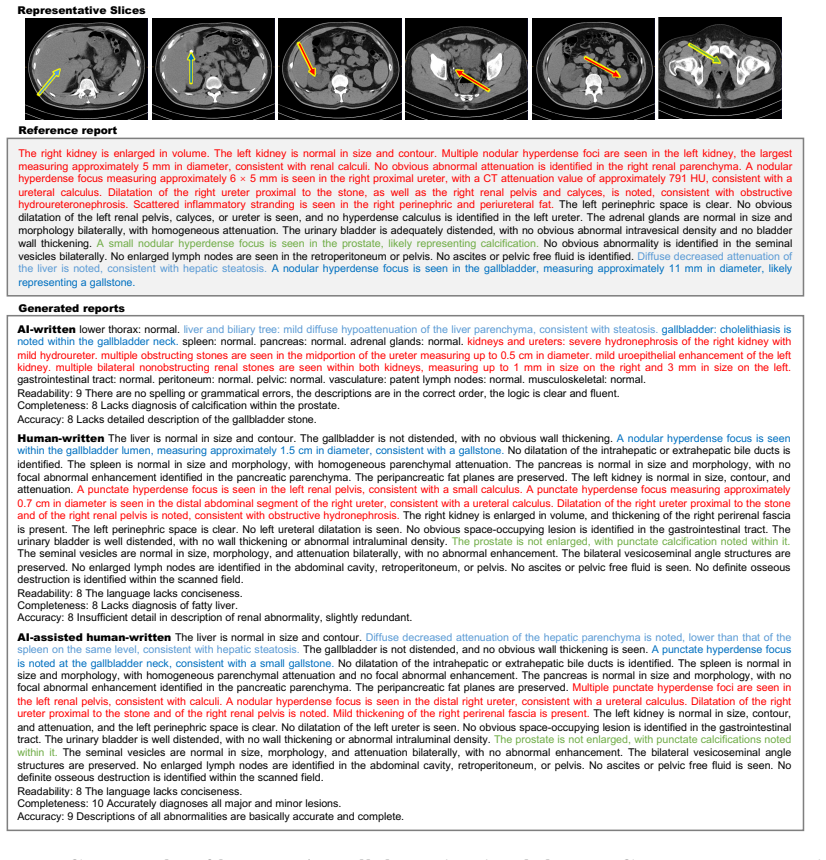
read the original abstract
CT interpretation requires radiologists to review hundreds of volumetric slices per examination, making reporting time-consuming and highly expertise-dependent. Automated CT report generation offers a promising route to improving clinical efficiency, yet the field still lacks a generalizable CT report generation foundation model that supports multi-region reporting and remains robust across external real-world cohorts. Intrinsic inconsistencies in reporting style and diagnostic terminology across cohorts make naive joint training prone to noisy textual supervision, thereby limiting model generalizability. Here we present Astra, a generalizable CT report generation foundation model trained on 90,678 thoracoabdominal CT-report pairs (CTRgDB) with 353,671 abnormalities spanning eight organ systems. By harmonizing report style and further refining diagnostic consistency via reinforcement learning, Astra achieves style-consistent and diagnostically accurate report generation across diverse anatomical regions and institutions. Evaluating on CTRgDB and six external cohorts, Astra achieves state-of-the-art performance with a 44.1% average improvement in fine-grained diagnostic metrics (P<0.001). In real-world clinical workflows, Astra assistance accelerates chest report drafting by 29.6% and improves abdominal report completeness by 11.3% (P<0.001). Furthermore, Astra also demonstrates broad utility as a foundation for CT AI development, improving downstream diagnostic performance and scaling vision-language pretrain through high-quality report synthesis. Overall, Astra serves as a broadly accessible clinical assistant and a pivotal infrastructure for the next generation of AI-powered healthcare.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents Astra, a foundation model for generating reports from 3D CT scans. Trained on 90,678 thoracoabdominal CT-report pairs (CTRgDB) containing 353,671 abnormalities across eight organ systems, the model applies report style harmonization followed by reinforcement learning to produce consistent outputs. It claims state-of-the-art performance with a 44.1% average improvement in fine-grained diagnostic metrics (P<0.001) on CTRgDB plus six external cohorts, plus real-world clinical benefits (29.6% faster chest report drafting; 11.3% better abdominal report completeness, P<0.001) and utility as a foundation for downstream CT AI tasks.
Significance. If the performance and generalizability claims are substantiated with full methodological detail and appropriate controls, the work would represent a meaningful advance in medical vision-language modeling by addressing cross-institution style and terminology inconsistencies at scale. The size of the training corpus and the inclusion of multi-cohort external evaluation plus clinical workflow measurements are positive features.
major comments (2)
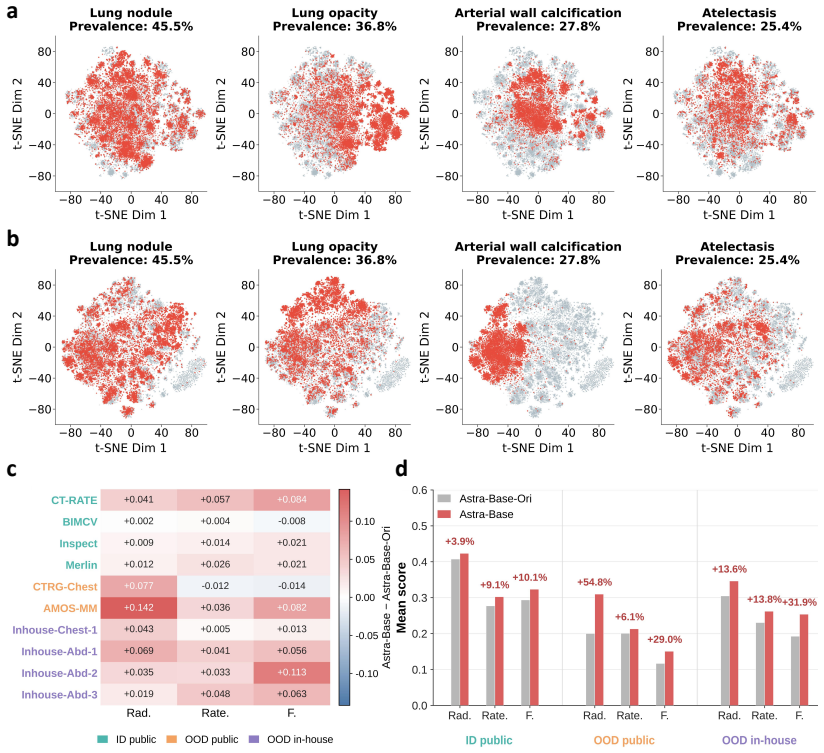
- [Abstract] Abstract: the central claim of a 44.1% average improvement in 'fine-grained diagnostic metrics' (P<0.001) across CTRgDB and six external cohorts is presented without any definition of the metrics themselves, without ablation results that hold style fixed while varying only diagnostic content, and without error bars or dataset characteristics for the external cohorts. This is load-bearing for the generalizability and diagnostic-accuracy assertions because, per the stress-test note, the metrics may incorporate terminology or structure altered by the harmonization step, so measured gains could reflect partial style transfer rather than independent diagnostic improvement.
- [Abstract] Abstract: the training description states that style harmonization and reinforcement learning are used to refine diagnostic consistency, yet no implementation details, hyper-parameters, or ablation studies isolating the contribution of each step are supplied. Without these, it is impossible to assess whether the reported external-cohort gains are robust or whether they arise from overfitting to harmonized style patterns.
minor comments (2)
- [Abstract] Abstract: the phrase 'fine-grained diagnostic metrics' is used without elaboration; a brief parenthetical definition or reference to the exact metric formulation would improve interpretability of the 44.1% figure.
- [Abstract] Abstract: the clinical workflow results (29.6% acceleration, 11.3% completeness) are reported with p-values but without the number of participating radiologists, the exact study design, or confidence intervals, which would help readers gauge practical significance.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We address each major comment below and will revise the manuscript to improve clarity while preserving the integrity of the reported results.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of a 44.1% average improvement in 'fine-grained diagnostic metrics' (P<0.001) across CTRgDB and six external cohorts is presented without any definition of the metrics themselves, without ablation results that hold style fixed while varying only diagnostic content, and without error bars or dataset characteristics for the external cohorts. This is load-bearing for the generalizability and diagnostic-accuracy assertions because, per the stress-test note, the metrics may incorporate terminology or structure altered by the harmonization step, so measured gains could reflect partial style transfer rather than independent diagnostic improvement.
Authors: We agree the abstract would benefit from greater specificity. The fine-grained diagnostic metrics are abnormality-level precision, recall, and F1 scores, defined in Methods Section 4.2. We will revise the abstract to include this definition and a parenthetical reference to the external cohort characteristics (Table 1) and error bars (Tables 2-3). Ablation results controlling for style via harmonized references while isolating diagnostic content appear in Supplementary Section S3.4; these show persistent gains attributable to diagnostic accuracy rather than style alone. The harmonization step is applied uniformly prior to training, and external-cohort evaluations use unharmonized target reports, supporting that gains are not limited to style transfer. revision: yes
-
Referee: [Abstract] Abstract: the training description states that style harmonization and reinforcement learning are used to refine diagnostic consistency, yet no implementation details, hyper-parameters, or ablation studies isolating the contribution of each step are supplied. Without these, it is impossible to assess whether the reported external-cohort gains are robust or whether they arise from overfitting to harmonized style patterns.
Authors: The implementation details for style harmonization (Section 3.1) and reinforcement learning (Section 3.2), including the style classifier, reward formulation, and training procedure, are supplied in the Methods. Hyperparameters are listed in Supplementary Table S2, and ablation studies isolating each component's contribution (including style vs. diagnostic effects) are in Figure 4 and Supplementary Table S3. These ablations demonstrate additive gains from the RL stage on external cohorts. We will revise the abstract to briefly reference these sections so readers can locate the supporting analyses. revision: yes
Circularity Check
No significant circularity; empirical claims rest on external validation
full rationale
The paper describes training a foundation model on CTRgDB with style harmonization and reinforcement learning, followed by evaluation on CTRgDB plus six external cohorts. No equations, derivations, or first-principles chains appear in the provided text. Performance metrics (e.g., 44.1% improvement) are reported from held-out external data rather than any fitted parameter renamed as a prediction or any self-referential definition. Self-citations, if present in the full text, are not load-bearing for the central empirical claims. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption External cohorts reflect real-world reporting style and diagnostic variability independent of training data
- domain assumption Fine-grained diagnostic metrics are valid proxies for clinical accuracy after style harmonization
Reference graph
Works this paper leans on
-
[1]
Role of computed tomography at a cancer center emergency department.Emergency radiology, 24(2):113–117, 2017
Jessyca Couto Otoni, Julia Noschang, Thábata Yaedu Okamoto, Diego Rosseman Vieira, Michel Souto Mayor Petry, Lucas de Araujo Ramos, Paula Nicole Vieira Pinto Barbosa, Almir Galvão Vieira Bitencourt, and Rubens Chojniak. Role of computed tomography at a cancer center emergency department.Emergency radiology, 24(2):113–117, 2017
2017
-
[2]
Developments in x-ray contrast media and the potential impact on computed tomography.Investigative radiology, 55(9):592–597, 2020
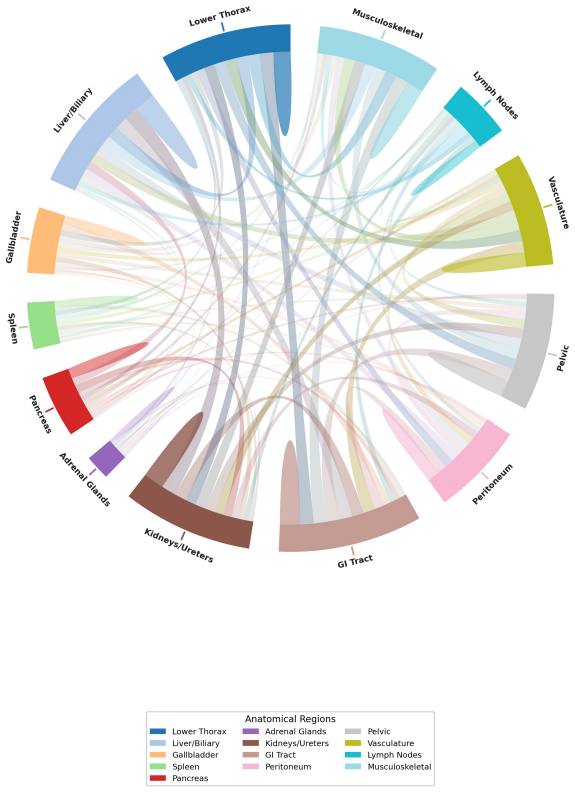
Laura Schöckel, Gregor Jost, Peter Seidensticker, Philipp Lengsfeld, Petra Palkowitsch, and Hubertus Pietsch. Developments in x-ray contrast media and the potential impact on computed tomography.Investigative radiology, 55(9):592–597, 2020
2020
-
[3]
Us diagnostic reference levels and achievable doses for 10 adult ct examinations.Radiology, 284(1):120–133, 2017
Kalpana M Kanal, Priscilla F Butler, Debapriya Sengupta, Mythreyi Bhargavan-Chatfield, Laura P Coombs, and Richard L Morin. Us diagnostic reference levels and achievable doses for 10 adult ct examinations.Radiology, 284(1):120–133, 2017
2017
-
[4]
Radiologist productivity analytics: factors impacting abdominal pelvic ct exam reporting times.Journal of Digital Imaging, 35(2):87–97, 2022
Amar Udare, Minu Agarwal, Kiret Dhindsa, Amer Alaref, Michael Patlas, Abdullah Al- abousi, Yoan K Kagoma, and Christian B van der Pol. Radiologist productivity analytics: factors impacting abdominal pelvic ct exam reporting times.Journal of Digital Imaging, 35(2):87–97, 2022
2022
-
[5]
The growing problem of radiologist shortage: China’s perspective.Korean Journal of Radiology, 24(11):1046, 2023
Fanyang Meng, Lan Zhan, Shiyuan Liu, and Huimao Zhang. The growing problem of radiologist shortage: China’s perspective.Korean Journal of Radiology, 24(11):1046, 2023
2023
-
[6]
Clinically applicable ai system for accurate diagnosis, quantitativemeasurements, andprognosisofcovid-19pneumoniausingcomputed tomography.Cell, 181(6):1423–1433, 2020
Kang Zhang, Xiaohong Liu, Jun Shen, Zhihuan Li, Ye Sang, Xingwang Wu, Yunfei Zha, Wenhua Liang, Chengdi Wang, Ke Wang, et al. Clinically applicable ai system for accurate diagnosis, quantitativemeasurements, andprognosisofcovid-19pneumoniausingcomputed tomography.Cell, 181(6):1423–1433, 2020
2020
-
[7]
Ai-based large-scale screening of gastric cancer from noncontrast ct imaging.Nature Medicine, 31(9):3011–3019, 2025
Can Hu, Yingda Xia, Zhilin Zheng, Mengxuan Cao, Guoliang Zheng, Shangqi Chen, Jiancheng Sun, Wujie Chen, Qi Zheng, Siwei Pan, et al. Ai-based large-scale screening of gastric cancer from noncontrast ct imaging.Nature Medicine, 31(9):3011–3019, 2025
2025
-
[8]
Ai-based diagnosis of acute aortic syndrome from noncontrast ct.Nature Medicine, 31(11):3832–3844, 2025
Yujian Hu, Yilang Xiang, Yan-Jie Zhou, Yangyan He, Dehai Lang, Shifeng Yang, Xiaolong Du, Chunlan Den, Youyao Xu, Gaofeng Wang, et al. Ai-based diagnosis of acute aortic syndrome from noncontrast ct.Nature Medicine, 31(11):3832–3844, 2025
2025
-
[9]
Large-scale pancreatic cancer detection via non- contrast ct and deep learning.Nature medicine, 29(12):3033–3043, 2023
Kai Cao, Yingda Xia, Jiawen Yao, Xu Han, Lukas Lambert, Tingting Zhang, Wei Tang, Gang Jin, Hui Jiang, Xu Fang, et al. Large-scale pancreatic cancer detection via non- contrast ct and deep learning.Nature medicine, 29(12):3033–3043, 2023
2023
-
[10]
Thecurrentstatusandfutureoffda-approvedartificialintelligence tools in chest radiology in the united states.Clinical Radiology, 78(2):115–122, 2023
MEMilamandCWKoo. Thecurrentstatusandfutureoffda-approvedartificialintelligence tools in chest radiology in the united states.Clinical Radiology, 78(2):115–122, 2023
2023
-
[11]
Towards a holistic frame- workformultimodalllmin3dbrainctradiologyreportgeneration.Nature Communications, 16(1):2258, 2025
Cheng-Yi Li, Kao-Jung Chang, Cheng-Fu Yang, Hsin-Yu Wu, Wenting Chen, Hritik Bansal, Ling Chen, Yi-Ping Yang, Yu-Chun Chen, Shih-Pin Chen, et al. Towards a holistic frame- workformultimodalllmin3dbrainctradiologyreportgeneration.Nature Communications, 16(1):2258, 2025
2025
-
[12]
Large language model with region- guided referring and grounding for ct report generation.IEEE Transactions on Medical Imaging, 2025
Zhixuan Chen, Yequan Bie, Haibo Jin, and Hao Chen. Large language model with region- guided referring and grounding for ct report generation.IEEE Transactions on Medical Imaging, 2025
2025
-
[13]
Ct2rep: Automated radiology report generation for 3d medical imaging
Ibrahim Ethem Hamamci, Sezgin Er, and Bjoern Menze. Ct2rep: Automated radiology report generation for 3d medical imaging. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention, pages 476–486. Springer, 2024. 25
2024
-
[14]
Dia-llama: Towards large lan- guage model-driven ct report generation
Zhixuan Chen, Luyang Luo, Yequan Bie, and Hao Chen. Dia-llama: Towards large lan- guage model-driven ct report generation. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention, pages 141–151. Springer, 2025
2025
-
[15]
Mvketr: chest ct report generation with multi-view perception and knowledge en- hancement.IEEE Journal of Biomedical and Health Informatics, 2025
Xiwei Deng, Xianchun He, Jianfeng Bao, Yudan Zhou, Shuhui Cai, Congbo Cai, and Zhong Chen. Mvketr: chest ct report generation with multi-view perception and knowledge en- hancement.IEEE Journal of Biomedical and Health Informatics, 2025
2025
-
[16]
Ct-agrg: Automated abnormality-guided report generation from 3d chest ct volumes
Theo Di Piazza, Carole Lazarus, Olivier Nempont, and Loic Boussel. Ct-agrg: Automated abnormality-guided report generation from 3d chest ct volumes. In2025 IEEE 22nd Inter- national Symposium on Biomedical Imaging (ISBI), pages 01–05. IEEE, 2025
2025
-
[17]
Ct- graph: Hierarchical graph attention network for anatomy-guided ct report generation
Hamza Kalisch, Fabian Hörst, Jens Kleesiek, Ken Herrmann, and Constantin Seibold. Ct- graph: Hierarchical graph attention network for anatomy-guided ct report generation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 6775– 6784, 2025
2025
-
[18]
Better tokens for better 3d: Advancing vision-language modeling in 3d medical imaging.Advances in Neural Information Processing Systems, 38:135074–135102, 2026
Ibrahim Ethem Hamamci, Sezgin Er, Suprosanna Shit, Hadrien Reynaud, Dong Yang, Pengfei Guo, Marc Edgar, Daguang Xu, Bernhard Kainz, and Bjoern Menze. Better tokens for better 3d: Advancing vision-language modeling in 3d medical imaging.Advances in Neural Information Processing Systems, 38:135074–135102, 2026
2026
-
[19]
Hao Chen, Wei Zhao, Yingli Li, Tianyang Zhong, Yisong Wang, Youlan Shang, Lei Guo, Junwei Han, Tianming Liu, Jun Liu, et al. 3d-ct-gpt: Generating 3d radiology reports through integration of large vision-language models.arXiv preprint arXiv:2409.19330, 2024
-
[20]
Automated structured radiology report generation
Jean-Benoit Delbrouck, Justin Xu, Johannes Moll, Alois Thomas, Zhihong Chen, Sophie Ostmeier, Asfandyar Azhar, Kelvin Zhenghao Li, Andrew Johnston, Christian Bluethgen, et al. Automated structured radiology report generation. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 26813–26829, 2025
2025
-
[21]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
Towards generalist foundation model for radiology by leveraging web-scale 2d&3d medical data
Chaoyi Wu, Xiaoman Zhang, Ya Zhang, Hui Hui, Yanfeng Wang, and Weidi Xie. Towards generalist foundation model for radiology by leveraging web-scale 2d&3d medical data. Nature Communications, 16(1):7866, 2025
2025
-
[24]
Fan Bai, Yuxin Du, Tiejun Huang, Max Q-H Meng, and Bo Zhao. M3d: Advanc- ing 3d medical image analysis with multi-modal large language models.arXiv preprint arXiv:2404.00578, 2024
-
[25]
Songtao Jiang, Yuan Wang, Sibo Song, Tianxiang Hu, Chenyi Zhou, Bin Pu, Yan Zhang, Zhibo Yang, Yang Feng, Joey Tianyi Zhou, et al. Hulu-med: A transparent generalist model towards holistic medical vision-language understanding.arXiv preprint arXiv:2510.08668, 2025
-
[26]
Large language models improve transferability of electronic health record-based predictions across countries and coding systems.npj Digital Medicine, 2026
Matthias Kirchler, Matteo Ferro, Veronica Lorenzini, Robin P van de Water, FinnGen Ganna Andrea 3, Christoph Lippert, and Andrea Ganna. Large language models improve transferability of electronic health record-based predictions across countries and coding systems.npj Digital Medicine, 2026. 26
2026
-
[27]
Benchmark evaluation of deepseek large language models in clinical decision-making.Nature medicine, 31(8):2546–2549, 2025
Sarah Sandmann, Stefan Hegselmann, Michael Fujarski, Lucas Bickmann, Benjamin Wild, Roland Eils, and Julian Varghese. Benchmark evaluation of deepseek large language models in clinical decision-making.Nature medicine, 31(8):2546–2549, 2025
2025
-
[28]
Com- parative benchmarking of the deepseek large language model on medical tasks and clinical reasoning.Nature medicine, 31(8):2550–2555, 2025
Mickael Tordjman, Zelong Liu, Murat Yuce, Valentin Fauveau, Yunhao Mei, Jerome Had- jadj, Ian Bolger, Haidara Almansour, Carolyn Horst, Ashwin Singh Parihar, et al. Com- parative benchmarking of the deepseek large language model on medical tasks and clinical reasoning.Nature medicine, 31(8):2550–2555, 2025
2025
-
[29]
Zero-shot information extraction from radiological reports using chatgpt.International Journal of Medical Infor- matics, 183:105321, 2024
Danqing Hu, Bing Liu, Xiaofeng Zhu, Xudong Lu, and Nan Wu. Zero-shot information extraction from radiological reports using chatgpt.International Journal of Medical Infor- matics, 183:105321, 2024
2024
-
[30]
Clinical entity augmented retrieval for clinical information extraction.NPJ digital medicine, 8(1):45, 2025
Ivan Lopez, Akshay Swaminathan, Karthik Vedula, Sanjana Narayanan, Fateme Nateghi Haredasht, Stephen P Ma, April S Liang, Steven Tate, Manoj Maddali, Robert Joseph Gallo, et al. Clinical entity augmented retrieval for clinical information extraction.NPJ digital medicine, 8(1):45, 2025
2025
-
[31]
Merlin: A vision language foundation model for 3d computed tomography
Louis Blankemeier, Joseph Paul Cohen, Ashwin Kumar, Dave Van Veen, Syed Jamal Safdar Gardezi, Magdalini Paschali, Zhihong Chen, Jean-Benoit Delbrouck, Eduardo Reis, Cesar Truyts, et al. Merlin: A vision language foundation model for 3d computed tomography. Research Square, pages rs–3, 2024
2024
-
[32]
Pragmatic radiology report gener- ation
Dang Nguyen, Chacha Chen, He He, and Chenhao Tan. Pragmatic radiology report gener- ation. InMachine Learning for Health (ML4H), pages 385–402. PMLR, 2023
2023
-
[33]
Deepseek-r1 incentivizes reasoning in llms through reinforcement learning.Nature, 645(8081):633–638, 2025
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1 incentivizes reasoning in llms through reinforcement learning.Nature, 645(8081):633–638, 2025
2025
-
[34]
Radgpt: Constructing 3d image-text tumor datasets
Pedro RAS Bassi, Mehmet Can Yavuz, Ibrahim Ethem Hamamci, Sezgin Er, Xiaoxi Chen, Wenxuan Li, Bjoern Menze, Sergio Decherchi, Andrea Cavalli, Kang Wang, et al. Radgpt: Constructing 3d image-text tumor datasets. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 23720–23730, 2025
2025
-
[35]
A foundation model utilizing chest ct volumes and radiology reports for supervised-level zero-shot detection of abnormalities.CoRR, 2024
Ibrahim Ethem Hamamci, Sezgin Er, Furkan Almas, Ayse Gulnihan Simsek, Sevval Nil Esir- gun, Irem Dogan, Muhammed Furkan Dasdelen, Bastian Wittmann, Enis Simsar, Mehmet Simsar, et al. A foundation model utilizing chest ct volumes and radiology reports for supervised-level zero-shot detection of abnormalities.CoRR, 2024
2024
-
[36]
Shih-ChengHuang, ZepengHuo, EthanSteinberg, Chia-ChunChiang, MatthewPLungren, Curtis P Langlotz, Serena Yeung, Nigam H Shah, and Jason A Fries. Inspect: a multimodal dataset for pulmonary embolism diagnosis and prognosis.arXiv preprint arXiv:2311.10798, 2023
-
[37]
Bimcv-r: A land- mark dataset for 3d ct text-image retrieval
Yinda Chen, Che Liu, Xiaoyu Liu, Rossella Arcucci, and Zhiwei Xiong. Bimcv-r: A land- mark dataset for 3d ct text-image retrieval. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention, pages 124–134. Springer, 2024
2024
-
[38]
Ratescore: A metric for radiology report generation
Weike Zhao, Chaoyi Wu, Xiaoman Zhang, Ya Zhang, Yanfeng Wang, and Weidi Xie. Ratescore: A metric for radiology report generation. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 15004–15019, 2024
2024
-
[39]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, et al. Qwen3 embedding: Advancing text embedding and reranking through foundation models.arXiv preprint arXiv:2506.05176, 2025. 27
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
Visualizing data using t-sne.Journal of machine learning research, 9(11), 2008
Laurens Van der Maaten and Geoffrey Hinton. Visualizing data using t-sne.Journal of machine learning research, 9(11), 2008
2008
-
[41]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
Lingshu: A Generalist Foundation Model for Unified Multimodal Medical Understanding and Reasoning
Weiwen Xu, Hou Pong Chan, Long Li, Mahani Aljunied, Ruifeng Yuan, Jianyu Wang, Chenghao Xiao, Guizhen Chen, Chaoqun Liu, Zhaodonghui Li, et al. Lingshu: A general- ist foundation model for unified multimodal medical understanding and reasoning.arXiv preprint arXiv:2506.07044, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Andrew Sellergren, Sahar Kazemzadeh, Tiam Jaroensri, Atilla Kiraly, Madeleine Traverse, Timo Kohlberger, Shawn Xu, Fayaz Jamil, Cían Hughes, Charles Lau, et al. Medgemma technical report.arXiv preprint arXiv:2507.05201, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
R2gengpt: Radiology report generation with frozen llms.Meta-Radiology, 1(3):100033, 2023
Zhanyu Wang, Lingqiao Liu, Lei Wang, and Luping Zhou. R2gengpt: Radiology report generation with frozen llms.Meta-Radiology, 1(3):100033, 2023
2023
-
[45]
A clinically accessible small multimodal radiology model and evaluation metric for chest x- ray findings.Nature Communications, 16(1):3108, 2025
Juan Manuel Zambrano Chaves, Shih-Cheng Huang, Yanbo Xu, Hanwen Xu, Naoto Usuyama, Sheng Zhang, Fei Wang, Yujia Xie, Mahmoud Khademi, Ziyi Yang, et al. A clinically accessible small multimodal radiology model and evaluation metric for chest x- ray findings.Nature Communications, 16(1):3108, 2025
2025
-
[46]
Xiaotang Gai, Jiaxiang Liu, Yichen Li, Zijie Meng, Jian Wu, and Zuozhu Liu. 3d-rad: A comprehensive 3d radiology med-vqa dataset with multi-temporal analysis and diverse diagnostic tasks.arXiv preprint arXiv:2506.11147, 2025
-
[47]
Work like a doctor: Unifying scan localizer and dynamic generator for automated computed tomography report generation
Yuhao Tang, Haichen Yang, Liyan Zhang, and Ye Yuan. Work like a doctor: Unifying scan localizer and dynamic generator for automated computed tomography report generation. Expert Systems with Applications, 237:121442, 2024
2024
-
[48]
Lung cancer screening with low-dose helical ct: results from the national lung screening trial (nlst), 2011
Barnett S Kramer, Christine D Berg, Denise R Aberle, and Philip C Prorok. Lung cancer screening with low-dose helical ct: results from the national lung screening trial (nlst), 2011
2011
-
[49]
Machine-learning-basedmultipleabnormalityprediction with large-scale chest computed tomography volumes.Medical image analysis, 67:101857, 2021
Rachel Lea Draelos, David Dov, Maciej A Mazurowski, Joseph Y Lo, Ricardo Henao, Geof- freyDRubin, andLawrenceCarin. Machine-learning-basedmultipleabnormalityprediction with large-scale chest computed tomography volumes.Medical image analysis, 67:101857, 2021
2021
-
[50]
The rsna pulmonary embolism ct dataset.Radiology: Artificial Intelligence, 3 (2):e200254, 2021
Errol Colak, Felipe C Kitamura, Stephen B Hobbs, Carol C Wu, Matthew P Lungren, Luciano M Prevedello, Jayashree Kalpathy-Cramer, Robyn L Ball, George Shih, Anouk Stein, et al. The rsna pulmonary embolism ct dataset.Radiology: Artificial Intelligence, 3 (2):e200254, 2021
2021
-
[51]
Bleu: a method for automatic evaluation of machine translation
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. Bleu: a method for automatic evaluation of machine translation. InProceedings of the 40th annual meeting of the Association for Computational Linguistics, pages 311–318, 2002
2002
-
[52]
Rouge: A package for automatic evaluation of summaries
Chin-Yew Lin. Rouge: A package for automatic evaluation of summaries. InText summa- rization branches out, pages 74–81, 2004
2004
-
[53]
Meteor: An automatic metric for mt evaluation with improved correlation with human judgments
Satanjeev Banerjee and Alon Lavie. Meteor: An automatic metric for mt evaluation with improved correlation with human judgments. InProceedings of the acl workshop on intrinsic and extrinsic evaluation measures for machine translation and/or summarization, pages 65– 72, 2005. 28
2005
-
[54]
Maira-2: Grounded radiology report generation
Shruthi Bannur, Kenza Bouzid, Daniel C Castro, Anton Schwaighofer, Anja Thieme, Sam Bond-Taylor, Maximilian Ilse, Fernando Pérez-García, Valentina Salvatelli, Harshita Sharma, et al. Maira-2: Grounded radiology report generation.arXiv preprint arXiv:2406.04449, 2024
-
[55]
Stephanie L Hyland, Shruthi Bannur, Kenza Bouzid, Daniel C Castro, Mercy Ranjit, Anton Schwaighofer, Fernando Pérez-García, Valentina Salvatelli, Shaury Srivastav, Anja Thieme, et al. Maira-1: A specialised large multimodal model for radiology report generation.arXiv preprint arXiv:2311.13668, 2023
-
[56]
Generating radiology reports via memory-driven transformer
Zhihong Chen, Yan Song, Tsung-Hui Chang, and Xiang Wan. Generating radiology reports via memory-driven transformer. InProceedings of the 2020 conference on empirical methods in natural language processing (EMNLP), pages 1439–1449, 2020
2020
-
[57]
Cross-modal memory networks for radiology report generation
Zhihong Chen, Yaling Shen, Yan Song, and Xiang Wan. Cross-modal memory networks for radiology report generation. InProceedings of the 59th annual meeting of the association for computational linguistics and the 11th international joint conference on natural language processing (volume 1: long papers), pages 5904–5914, 2021
2021
-
[58]
A vision–language pretrained transformer for versatile clinical respiratory disease applications.Nature Biomedical Engineering, pages 1–19, 2025
Liangdi Ma, Hengrui Liang, Yuwei He, Wei Wang, Zeping Yan, Wuchao Li, Rongpin Wang, Yongyi Li, Yuerong Lizhu, Yaou Liu, et al. A vision–language pretrained transformer for versatile clinical respiratory disease applications.Nature Biomedical Engineering, pages 1–19, 2025
2025
-
[59]
Col- laboration between clinicians and vision–language models in radiology report generation
Ryutaro Tanno, David GT Barrett, Andrew Sellergren, Sumedh Ghaisas, Sumanth Dathathri, Abigail See, Johannes Welbl, Charles Lau, Tao Tu, Shekoofeh Azizi, et al. Col- laboration between clinicians and vision–language models in radiology report generation. Nature Medicine, 31(2):599–608, 2025
2025
-
[60]
A deep learning based automatic report generator for retinal optical coherence tomography images.npj Digital Medicine, 8(1):618, 2025
Xinjian Chen, Huazhu Fu, Jingtao Wang, Tian Lin, Qian Cheng, Cangxin Li, Meng Wang, Zhongyue Chen, Aidi Lin, Anlin Zhang, et al. A deep learning based automatic report generator for retinal optical coherence tomography images.npj Digital Medicine, 8(1):618, 2025
2025
-
[61]
Keyword-based ai assistance in the generation of radiology reports: A pilot study.NPJ Digital Medicine, 8 (1):490, 2025
Fei Dong, Shouping Nie, Manling Chen, Fangfang Xu, and Qian Li. Keyword-based ai assistance in the generation of radiology reports: A pilot study.NPJ Digital Medicine, 8 (1):490, 2025
2025
-
[62]
Generating synthetic data for medical imaging.Radiology, 312(3):e232471, 2024
Lennart R Koetzier, Jie Wu, Domenico Mastrodicasa, Aline Lutz, Matthew Chung, W Adam Koszek, Jayanth Pratap, Akshay S Chaudhari, Pranav Rajpurkar, Matthew P Lungren, et al. Generating synthetic data for medical imaging.Radiology, 312(3):e232471, 2024
2024
-
[63]
Generative ai for misalignment- resistant virtual staining to accelerate histopathology workflows.Nature Communications, 2026
Jiabo Ma, Wenqiang Li, Jinbang Li, Ziyi Liu, Linshan Wu, Fengtao Zhou, Li Liang, Ronald Cheong Kin Chan, Terence TW Wong, and Hao Chen. Generative ai for misalignment- resistant virtual staining to accelerate histopathology workflows.Nature Communications, 2026
2026
-
[64]
Development of a large-scale grounded vision language dataset for chest ct analysis.Scientific Data, 12(1):1636, 2025
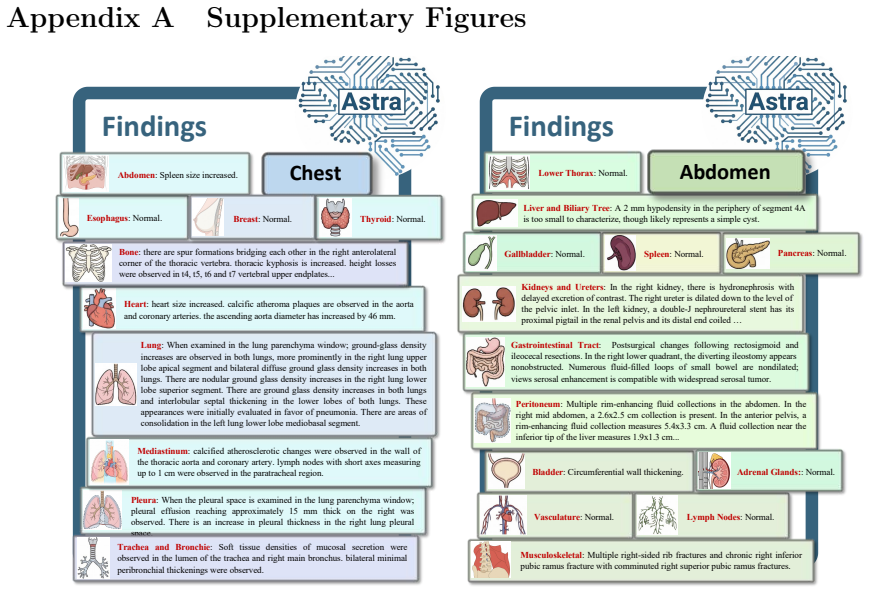
Xiaoman Zhang, Chaoyi Wu, Ziheng Zhao, Jiayu Lei, Weiwei Tian, Ya Zhang, Weidi Xie, and Yanfeng Wang. Development of a large-scale grounded vision language dataset for chest ct analysis.Scientific Data, 12(1):1636, 2025. 29 Appendix A Supplementary Figures Esophagus: Normal. Heart: heart size increased. calcific atheroma plaques are observed in the aorta ...
2025
-
[65]
lower thorax: includes lower chest and lung bases
-
[66]
liver and biliary tree: includes liver and biliary tree (bile ducts), but NOT gallbladder
-
[67]
gallbladder: gallbladder only (separate from liver)
-
[68]
pancreas: pancreas only
-
[69]
adrenal glands: adrenal glands only
-
[70]
kidneys and ureters: includes kidneys and ureters
-
[71]
gastrointestinal tract: includes stomach, intestines, appendix; be careful not to miss the appendix
-
[72]
peritoneum: includes peritoneal space, peritoneal cavity, and abdominal wall
-
[73]
pelvic: includes pelvic organs, bladder, prostate and seminal vesicles, uterus and ovaries
-
[74]
vasculature: vasculature system
-
[75]
lymph nodes: lymph nodes
-
[76]
FIND- INGS GIVEN TO Dr
musculoskeletal: includes bones and muscles Rule 1: Remove Non-Diagnostic Text Before any other processing, you must identify and completely remove any text that represents communication between clinicians, summary codes, or procedural notes. This includes but is not limited to phrases like “FIND- INGS GIVEN TO Dr. ...”, “SUMMARY 4:...”, “END OF IMPRESSIO...
-
[78]
Report:{report} Processed Report (JSON):
If a region had no positive findings (i.e., it was normal, all findings were negative, or the section was not mentioned in the report), the value MUST be the string “normal”. Report:{report} Processed Report (JSON):... Table 8: Prompt used for structured information extraction from abdominal CT reports. 48 Structured Chest CT Report Extraction Prompt: Sys...
-
[79]
abdomen: include all findings related to liver, gallbladder, pancreas, spleen, kidneys, adrenals, gastrointestinal tract, abdominal vessels, and abdominal lymph nodes, etc
-
[80]
esophagus: esophagus
-
[81]
mediastinum: mediastinum area
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.