Answer-Set-Programming-based Abstractions for Reinforcement Learning
Pith reviewed 2026-06-28 22:08 UTC · model grok-4.3
The pith
Answer-Set Programming realizes the CARCASS framework for abstractions in reinforcement learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We demonstrate that an ASP-based implementation of CARCASS can leverage domain knowledge to construct abstractions for RL by modeling Markov Decision Processes in first-order logic, with evaluations in the Blocks World and Minigrid domains indicating that the approach is promising for building such abstractions.
What carries the argument
ASP realization of the CARCASS framework, which encodes relational structure to abstract first-order MDPs.
If this is right
- RL agents gain access to relational abstractions that reduce effective state-space size when objects and relations are present.
- Domain knowledge can be expressed declaratively to guide abstraction without writing procedural code.
- Abstraction construction becomes compatible with any off-the-shelf ASP solver.
- The same logical modeling step supports generalization across states that share relational structure.
Where Pith is reading between the lines
- The declarative style of ASP could simplify combining CARCASS abstractions with other logic-based planning or verification tools.
- The method might extend naturally to domains where objects have typed attributes or numeric relations.
- Switching the modeling language could reduce implementation effort when porting relational RL techniques to new solvers.
- Further case studies in domains with partial observability would test whether the abstractions remain effective.
Load-bearing premise
The ASP translation must faithfully reproduce the abstraction power of the original Prolog CARCASS, and the two test domains must be representative enough to indicate general usefulness.
What would settle it
Running the ASP version and the original Prolog version on an additional relational domain and finding that the ASP abstractions yield no improvement in learning speed or policy quality over non-abstracted RL would undermine the claim.
Figures
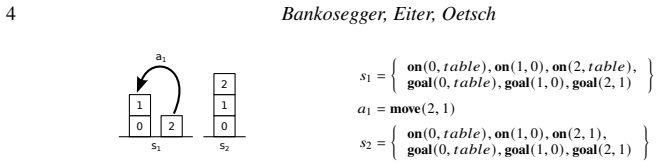

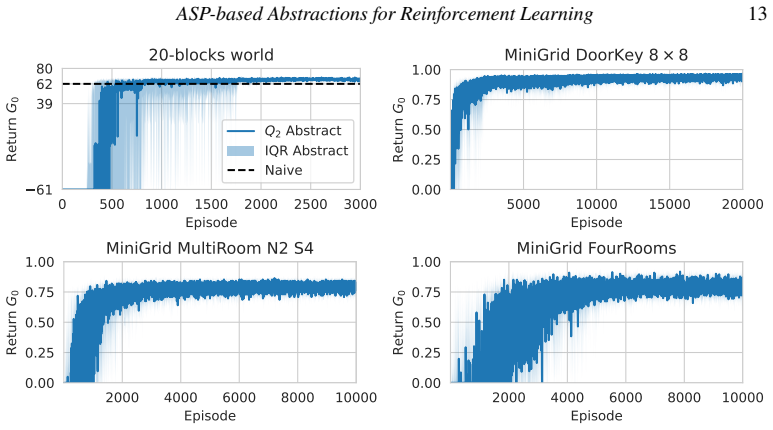
read the original abstract
Reinforcement Learning (RL) enables autonomous agents to learn policies from experience, but realistic problems often involve enormous state spaces, making learning and generalisation challenging. Abstraction and approximation are therefore essential. Relational Reinforcement Learning (RRL) offers a way to reason about objects and their relations, and the CARCASS framework by Martijn van Otterlo demonstrates how logical representations can model Markov Decision Processes (MDPs) in first-order domains. Originally implemented in Prolog, CARCASS leverages domain knowledge to create powerful abstractions. We explore Answer-Set Programming (ASP), which is a rich and, contrary to Prolog, fully declarative modelling language, to realise CARCASS abstractions. We evaluate our ASP-based implementation in case studies of two domains, viz. Blocks World and Minigrid. Our results indicate that CARCASS with ASP provides a promising approach to constructing abstractions for RL, especially when domain knowledge is available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an ASP-based realization of the CARCASS framework (originally in Prolog) for constructing logical abstractions of MDPs in relational reinforcement learning. It presents case studies on Blocks World and Minigrid domains and concludes that the approach is promising when domain knowledge is available.
Significance. If the ASP encoding is shown to faithfully reproduce CARCASS abstractions, the work could demonstrate a more declarative modeling language for relational RL abstractions, potentially easing incorporation of domain knowledge compared to Prolog. The case-study format provides initial evidence of applicability but lacks the quantitative grounding needed to establish broader utility.
major comments (2)
- [Abstract / case studies] Abstract and case-study descriptions: the claim that results 'indicate that CARCASS with ASP provides a promising approach' is unsupported by any reported metrics, baselines, policy performance numbers, or error analysis. This is load-bearing for the central claim of promise.
- [Implementation and evaluation sections] Implementation description: no equivalence verification (shared test states, side-by-side abstraction outputs, or metric comparing ASP vs. Prolog CARCASS state aggregations or learned policies) is provided. Without this, it is impossible to confirm that observed behavior arises from the intended CARCASS mechanisms rather than an altered encoding.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address the major points below and will revise the manuscript to strengthen the presentation of the case studies.
read point-by-point responses
-
Referee: [Abstract / case studies] Abstract and case-study descriptions: the claim that results 'indicate that CARCASS with ASP provides a promising approach' is unsupported by any reported metrics, baselines, policy performance numbers, or error analysis. This is load-bearing for the central claim of promise.
Authors: We agree that the abstract claim is not supported by quantitative metrics, as the evaluation consists of qualitative case studies on Blocks World and Minigrid demonstrating successful abstraction construction rather than policy learning curves or baselines. We will revise the abstract and conclusion sections to state that the implementation shows the feasibility of realizing CARCASS abstractions in ASP and appears suitable for domains with available domain knowledge, removing the unsupported indication of promise from results. revision: yes
-
Referee: [Implementation and evaluation sections] Implementation description: no equivalence verification (shared test states, side-by-side abstraction outputs, or metric comparing ASP vs. Prolog CARCASS state aggregations or learned policies) is provided. Without this, it is impossible to confirm that observed behavior arises from the intended CARCASS mechanisms rather than an altered encoding.
Authors: We acknowledge the absence of explicit equivalence checks. The ASP encoding was derived directly from the CARCASS logical framework description. In revision we will add a dedicated subsection with the rule-by-rule correspondence to the original Prolog formulation and include concrete examples of state aggregation outputs on shared small test states from Blocks World to illustrate fidelity. A quantitative metric comparison is not feasible without the original Prolog implementation source. revision: partial
Circularity Check
No circularity; implementation and case-study paper with no derivation chain
full rationale
The paper presents an ASP reimplementation of the existing CARCASS framework (originally in Prolog) together with case studies on Blocks World and Minigrid. No mathematical derivations, parameter fitting, predictions, or uniqueness theorems are claimed. The central claim rests on empirical results from the case studies rather than any reduction to self-defined inputs or self-citations. External citation to van Otterlo's prior work is independent and does not create a load-bearing self-citation loop. The work is therefore self-contained as an engineering report.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
doi: 10.1145/2043174.2043195. F. Calimeri, W. Faber, M. Gebser, G. Ianni, R. Kaminski, T. Krennwallner, N. Leone, M. Maratea, F. Ricca, and T. Schaub. ASP-Core-2 input language format.Theory Pract. Log. Program., 20(2):294–309,
-
[2]
doi: 10.1017/S1471068419000450. M. Chevalier-Boisvert, B. Dai, M. Towers, R. de Lazcano, L. Willems, S. Lahlou, S. Pal, P. S. Castro, and J. Terry. Minigrid & miniworld: Modular & customizable reinforcement learning environments for goal-oriented tasks.CoRR, abs/2306.13831,
-
[3]
doi: 10.48550/ARXIV.2306.13831. L. A. Ferreira, R. A. C. Bianchi, P. E. Santos, and R. L. de M´antaras. Answer set programming for non-stationary markov decision processes.Appl. Intell., 47(4):993–1007,
-
[4]
doi: 10.1007/S10489-017-0988-Y. C. E. Guestrin.Planning under uncertainty in complex structured environments. Stanford University,
-
[5]
H. Itoh. Towards learning to learn and plan by relational reinforcement learning. InProceedings of the Workshop on Relational Reinforcement Learning at the Twenty-First International Conference on Machine Learning (RRL at ICML-2004), pages 34–39,
2004
-
[6]
Kersting and L
16Bankosegger, Eiter, Oetsch K. Kersting and L. De Raedt. Logical markov decision programs and the convergence of logical td(lambda). In R. Camacho, R. D. King, and A. Srinivasan, editors,Inductive Logic Programming, 14th International Conference, ILP 2004, Porto, Portugal, September 6-8, 2004, Proceedings, volume 3194 ofLecture Notes in Computer Science,...
2004
-
[7]
doi: 10.1007/978-3-540-30109-7\
-
[8]
D. Mellor. A learning classifier system approach to relational reinforcement learning. In J. Bacardit, E. Bernad´o-Mansilla, M. V. Butz, T. Kovacs, X. Llor`a, and K. Takadama, editors,Learning Classifier Systems, 10th International Workshop, IWLCS 2006, Seattle, MA, USA, July 8, 2006 and 11th International Workshop, IWLCS 2007, London, UK, July 8, 2007, R...
2006
-
[9]
E. F. Morales. Scaling up reinforcement learning with a relational representation. InProceedings of the Workshop on Adaptability in Multi-Agent Systems at AORC 2003, Sydney, Australia,
2003
-
[10]
ISBN 3-540-62927-0. doi: 10.1007/3-540-62927-0. E. Saad. Bridging the gap between reinforcement learning and knowledge representation: A logical off- and on-policy framework. In W. Liu, editor,Symbolic and Quantitative Approaches to Reasoning with Uncertainty - 11th European Conference, ECSQARU 2011, Belfast, UK, June 29-July 1,
-
[11]
doi: 10.1007/978-3-642-22152-1\
-
[12]
doi: 10.1016/J.ARTINT.2021.103563. J. K. Slaney and S. Thi´ebaux. Blocks world revisited.Artif. Intell., 125(1-2):119–153,
-
[13]
van Otterlo
M. van Otterlo. Reinforcement learning for relational MDPs. In A. Now´e, T. Lenaerts, and K. Steenhaut, editors,Proceedings of the Annual Machine Learning Conference of Belgium and the Netherlands (BeNeLearn 2004), January 8-9, 2004, pages 138–145,
2004
-
[14]
Accessed: 2025-08-20. M. van Otterlo.The logic of adaptive behavior: Knowledge representation and algorithms for adaptive sequential decision making under uncertainty in first-order and relational domains, volume
2025
- [15]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.