Translation Analytics for Freelancers II: Benchmarking Local LLMs for Confidential Translation Workflows
Pith reviewed 2026-06-28 22:47 UTC · model grok-4.3
The pith
Selected local LLMs match or surpass local NMT systems and a frontier model for confidential translation but remain behind top commercial NMTs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
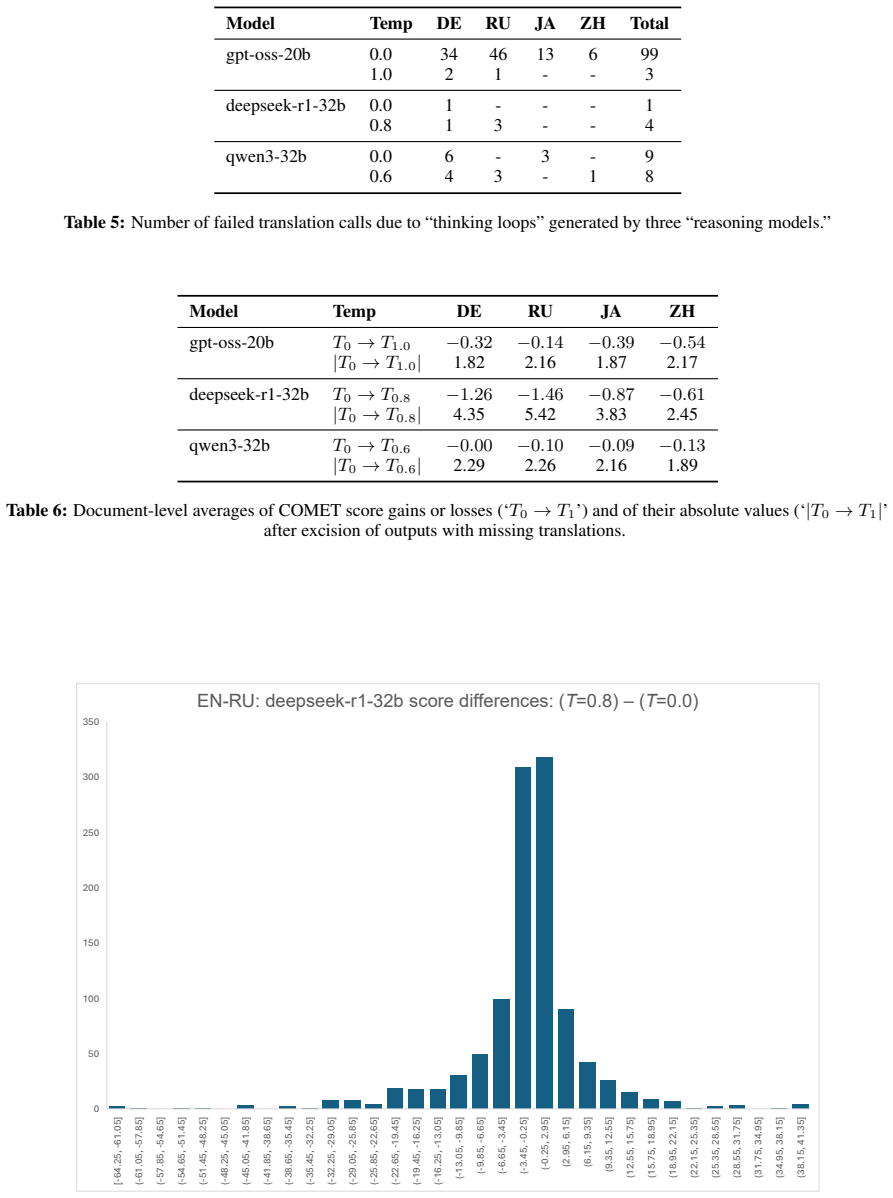
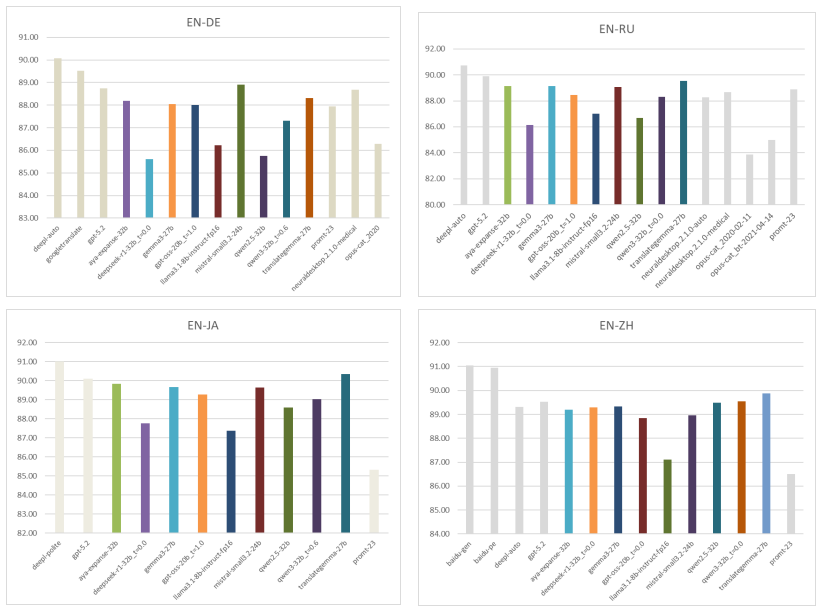
Building on prior work, the authors expand the Reeve Foundation Trilingual Corpus into the RFMC by adding sentence-aligned German and Simplified Chinese references. They then benchmark several locally runnable models via Ollama on 1000+ sentences in four language directions using single-prompt calls with no fine-tuning. Automatic evaluation with MATEO shows substantial variation by language pair and model size; the best local LLMs match or surpass local NMT systems and a frontier LLM while remaining behind top commercial NMTs such as DeepL and Baidu.
What carries the argument
The RFMC corpus paired with MATEO automatic scoring applied to single-prompt outputs from Ollama-hosted local LLMs, used to rank performance against commercial and local NMT baselines.
If this is right
- Freelance translators gain concrete evidence that selected local LLMs can serve as viable offline options for privacy-constrained assignments.
- Performance differences across language directions and model sizes guide model selection without additional training.
- The benchmark method itself supplies a low-barrier template that smaller providers can replicate on their own data.
- Results highlight the remaining gap to commercial leaders and the potential value of further scaling local models.
Where Pith is reading between the lines
- The same benchmark protocol could be applied to domain-specific corpora drawn from legal or medical texts to test whether the observed ranking holds under stricter terminology demands.
- Integration of the highest-scoring local LLMs into existing desktop tools such as OPUS-CAT might reduce post-editing effort for users already familiar with those interfaces.
- If model size continues to improve local multilingual capability, the current gap to commercial NMTs could narrow without any increase in data exposure.
Load-bearing premise
Automatic evaluation with MATEO on general-domain sentences from the expanded corpus serves as a reliable stand-in for professional translation quality in confidentiality-sensitive work without human assessment or domain adaptation.
What would settle it
A side-by-side human evaluation by professional translators on the same 1000+ sentence outputs that produces a different ranking between the top local LLMs and the local NMT systems.
Figures
read the original abstract
Building on our previous work, this paper develops practical, low-barrier methods for freelance translators and smaller language service providers to evaluate translation technologies using rigorous yet accessible analytic methods. Here we address a high-stakes, specialized need: offline translation for confidentiality-sensitive domains in which privacy constraints preclude the use of cloud-based engines and commercial LLMs. We expand the Reeve Foundation Trilingual Corpus (RFTC) used in our previous work into a multilingual corpus (RFMC) by adding sentence-aligned German and Simplified Chinese reference translations. We then benchmark several locally runnable language models (via Ollama) across four language directions on 1000+ sentences selected from this corpus. We use consistent single-prompt calls without fine-tuning or domain adaptation, comparing local LLM outputs against commercial NMTs (DeepL, Baidu), a frontier LLM (GPT-5.2), and professional-grade local NMT systems (OPUS-CAT, NeuralDesktop, Promt). Automatic evaluation is conducted with MATEO. Results reveal substantial variation in local LLM performance across language directions and model sizes. The best local LLMs match or surpass local NMT systems and a frontier LLM, though they remain behind top commercial NMTs. These findings underscore the viability of carefully selected local LLM translation for privacy-constrained professionals and inform future research on model scaling and multilingual capability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper expands the Reeve Foundation Trilingual Corpus (RFTC) into the multilingual RFMC by adding German and Simplified Chinese references. It benchmarks local LLMs runnable via Ollama on 1000+ sentences across four language directions using consistent single-prompt calls and MATEO automatic evaluation, comparing them to commercial NMTs (DeepL, Baidu), GPT-5.2, and local NMT systems (OPUS-CAT, etc.). The results indicate that the best local LLMs match or surpass local NMT and the frontier LLM but remain behind top commercial NMTs, supporting their use in confidentiality-sensitive translation workflows.
Significance. If the findings hold, the work offers practical value for freelancers and small providers needing offline translation tools under privacy constraints. The expansion of the corpus to include German and Chinese, the consistent benchmarking protocol across models and metrics, and the direct empirical comparisons are notable strengths that could guide technology adoption in specialized domains.
major comments (2)
- [Abstract / Results] Abstract / Results: The central claim that best local LLMs match or surpass local NMT systems and GPT-5.2 rests on MATEO scores from 1000+ sentences under single-prompt conditions. No human evaluation, error analysis, or correlation between MATEO and professional judgments on the RFMC corpus is reported, which is load-bearing because reference-based metrics are known to correlate only moderately with human assessments of terminology precision and stylistic appropriateness in specialized domains.
- [Abstract / Methods] Abstract / Methods: Sentence selection criteria for the 1000+ sentences, statistical testing of MATEO score differences, and checks for domain representativeness of the RFMC expansion for confidentiality-sensitive content are not described, undermining assessment of the robustness of the cross-model and cross-language comparisons.
minor comments (1)
- [Abstract] Abstract: The transition from 'Reeve Foundation Trilingual Corpus (RFTC)' to 'multilingual corpus (RFMC)' is introduced clearly, but verify consistent acronym usage and full expansion on first mention in all sections.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on arXiv:2605.31452. We address each major comment below with planned revisions to improve methodological transparency and acknowledge limitations of the automatic evaluation.
read point-by-point responses
-
Referee: [Abstract / Results] Abstract / Results: The central claim that best local LLMs match or surpass local NMT systems and GPT-5.2 rests on MATEO scores from 1000+ sentences under single-prompt conditions. No human evaluation, error analysis, or correlation between MATEO and professional judgments on the RFMC corpus is reported, which is load-bearing because reference-based metrics are known to correlate only moderately with human assessments of terminology precision and stylistic appropriateness in specialized domains.
Authors: We agree that human evaluation would strengthen interpretation of the results for specialized domains. The manuscript centers on a reproducible automatic protocol using MATEO for practical benchmarking accessible to freelancers. We will add a Limitations section noting the reliance on automatic metrics and their moderate correlation with human judgments, plus a sample-based qualitative error analysis to illustrate patterns in the outputs. revision: partial
-
Referee: [Abstract / Methods] Abstract / Methods: Sentence selection criteria for the 1000+ sentences, statistical testing of MATEO score differences, and checks for domain representativeness of the RFMC expansion for confidentiality-sensitive content are not described, undermining assessment of the robustness of the cross-model and cross-language comparisons.
Authors: We accept that these details require expansion for full assessment of robustness. The revised manuscript will expand the Methods section to specify sentence selection criteria, include statistical significance testing on MATEO differences, and discuss domain representativeness of the RFMC expansion drawing on the Reeve Foundation source materials. revision: yes
Circularity Check
Empirical benchmarking paper with no circular derivations or self-referential predictions
full rationale
The paper reports direct empirical comparisons of local LLMs against NMT systems and GPT-5.2 using the standard MATEO metric on 1000+ sentences from the newly expanded RFMC corpus. No equations, fitted parameters, predictions, or first-principles derivations are present that could reduce to inputs by construction. The mention of building on prior work is limited to corpus expansion and does not serve as load-bearing justification for the current results; the evaluation is self-contained against external benchmarks and standard metrics.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
https://doi.org/10.1080/0907676X
Assessing the effects of translation prompts on the translation quality of GPT-4 Turbo using automated and human evaluation met- rics: a case study.Perspectives, pages 1– 25, May. https://doi.org/10.1080/0907676X. 2025.2464120 https://www.tandfonline.com/ doi/full/10.1080/0907676X.2025.2464120 Alves, Duarte M., José Pombal, Nuno M. Guerreiro, Pe- dro H. M...
-
[2]
Translation Analytics for Freelancers: I. Intro- duction, Data Preparation, Baseline Evaluations. In Bouillon, Pierrette, Johanna Gerlach, Sabrina Girletti, Lise V olkart, Raphael Rubino, Rico Sennrich, Ana C. Farinha, Marco Gaido, Joke Daems, Dorothy Kenny, Helena Moniz, and Sara Szoc, editors,Proceed- ings of Machine Translation Summit XX: V olume 1, pa...
-
[3]
Language Models are Few-Shot Learners
Language Models are Few-Shot Learners. https://arxiv.org/abs/2005.14165 Castilho, Sheila, Clodagh Quinn Mallon, Rahel Meis- ter, and Shengya Yue. 2023. Do online Machine Translation Systems Care for Context? What About a GPT Model? In Nurminen, Mary, Judith Brenner, Maarit Koponen, Sirkku Latomaa, Mikhail Mikhailov, Frederike Schierl, Tharindu Ranasinghe,...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2025.naacl-long.280 2005
-
[4]
Generating radiology reports via memory-driven transformer
Unlocking reasoning capability on machine translation in large language models. https:// arxiv.org/abs/2602.14763 Rei, Ricardo, Craig Stewart, Ana C Farinha, and Alon Lavie. 2020. COMET: A Neural Framework for MT Evaluation. In Webber, Bonnie, Trevor Cohn, Yulan He, and Yang Liu, editors,Proceedings of the 2020 Conference on Empirical Methods in Natural L...
-
[5]
In Koehn, Philipp, Loïc Barrault, Ondˇrej Bojar, Fethi Bougares, Rajen Chatterjee, Marta R
COMET-22: Unbabel-IST 2022 Submission for the Metrics Shared Task. In Koehn, Philipp, Loïc Barrault, Ondˇrej Bojar, Fethi Bougares, Rajen Chatterjee, Marta R. Costa-jussà, Christian Feder- mann, Mark Fishel, Alexander Fraser, Markus Fre- itag, Yvette Graham, Roman Grundkiewicz, Paco Guzman, Barry Haddow, Matthias Huck, Anto- nio Jimeno Yepes, Tom Kocmi, A...
-
[6]
Prompting Large Language Model for Machine Translation: A Case Study. https://doi.org/10. 48550/ARXIV.2301.07069 https://arxiv.org/ abs/2301.07069 Zheng, Jiawei, Hanghai Hong, Feiyan Liu, Xiaoli Wang, Jingsong Su, Yonggui Liang, and Shikai Wu. 2024. Fine-tuning Large Language Models for Domain- specific Machine Translation. https://arxiv.org/ abs/2402.150...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.