On-Device Robotic Planning: Eliminating Inference Redundancy for Efficient Decision-Making
Pith reviewed 2026-06-28 22:23 UTC · model grok-4.3
The pith
Robotic reasoning can skip most inferences when consecutive observations repeat the same actions and subgoals.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Robotic reasoning workloads contain substantial temporal redundancy where consecutive observations frequently produce identical actions and subgoals; REIS exploits this by combining lightweight scene gating, KV-steered affordance routing, and deliberative reasoning to minimize unnecessary inference while preserving semantic adaptability and competitive performance on ALFRED and real-world tasks.
What carries the argument
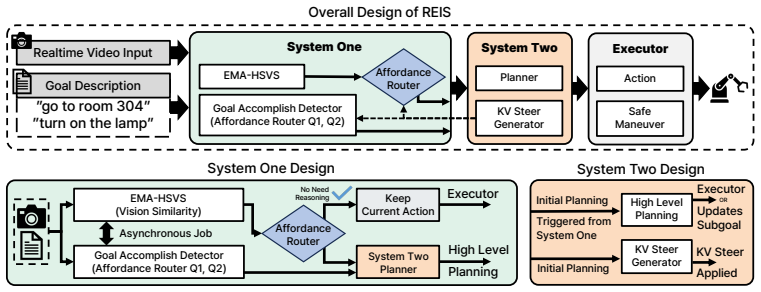
REIS framework, which uses lightweight scene gating to detect redundancy, KV-steered affordance routing to select routes, and deliberative reasoning only when needed.
If this is right
- On-device robotic policies become feasible with lower latency under embodied constraints.
- Task completion rates on ALFRED and physical robots stay close to full-reasoning baselines.
- The same redundancy pattern can be exploited in other sequential embodied tasks without changing the base model.
Where Pith is reading between the lines
- If temporal redundancy holds across a wider range of vision-language models, the approach could generalize beyond the tested planners.
- Real-world deployment would still require verifying that the gating mechanism itself stays cheap on target hardware.
- The same observation of repeated decisions might apply to non-robotic sequential planning problems such as game agents or autonomous vehicles.
Load-bearing premise
Robotic tasks produce enough repeated actions and subgoals across consecutive observations that skipping them does not hurt overall performance.
What would settle it
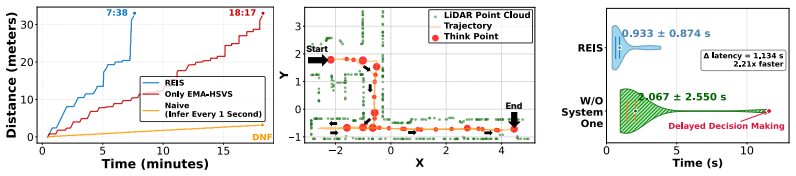
Measure the fraction of consecutive time steps that produce identical actions and subgoals in a new robotic environment or model; if the fraction is near zero, the claimed overhead reduction disappears.
Figures



read the original abstract
Reasoning-based robotic policies using large language and vision-language models achieve strong semantic planning capabilities but mostly suffer from a high inference latency that limits practical real-time deployment. In this work, we observe that robotic reasoning workloads contain substantial temporal redundancy, where consecutive observations frequently produce identical actions and subgoals. Based on this insight, we present REIS, a human cognition inspired robotic decision-making framework that minimizes unnecessary reasoning while preserving semantic adaptability. REIS combines lightweight scene gating, KV-steered affordance routing, and deliberative reasoning to accelerate robotic control under embodied constraints. Experiments on ALFRED, and real-world robotic tasks demonstrate that REIS significantly suppresses reasoning overhead while maintaining competitive task performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that robotic reasoning workloads exhibit substantial temporal redundancy (consecutive observations frequently yielding identical actions and subgoals), and introduces the REIS framework—combining lightweight scene gating, KV-steered affordance routing, and deliberative reasoning—to suppress inference overhead while preserving semantic adaptability and competitive task performance on ALFRED and real-world robotic tasks.
Significance. If the redundancy observation holds with independent quantification and the components deliver the claimed latency reductions without hidden costs to adaptability, the work would address a key barrier to real-time on-device deployment of VLM/LLM-based robotic planners, offering a practical path to lower-latency embodied decision-making.
major comments (2)
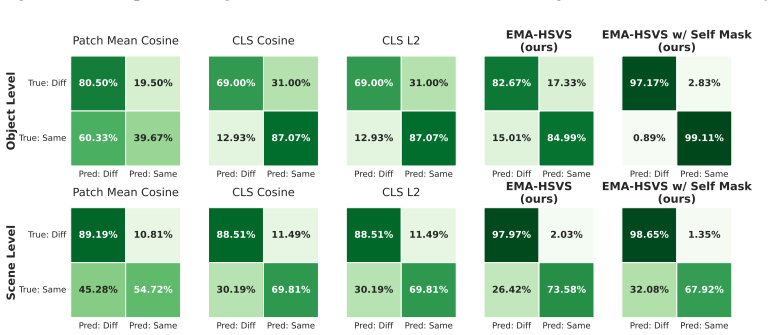
- [Abstract] Abstract: the central claim that REIS 'significantly suppresses reasoning overhead' rests on the unquantified observation of 'substantial temporal redundancy'; no metrics (e.g., fraction of identical consecutive actions/subgoals across ALFRED trajectories or robot logs, or ablation across other VLMs) are reported, so it is impossible to verify whether the property is general or setup-specific.
- [Abstract] Abstract: without baseline comparisons, error bars, or explicit measurement of redundancy and overhead (e.g., tokens or latency before/after each REIS component), the performance claims cannot be assessed for soundness or generality.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the need to strengthen the abstract with explicit quantification. We address each major comment below and will revise the manuscript to incorporate the requested metrics and clarifications.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that REIS 'significantly suppresses reasoning overhead' rests on the unquantified observation of 'substantial temporal redundancy'; no metrics (e.g., fraction of identical consecutive actions/subgoals across ALFRED trajectories or robot logs, or ablation across other VLMs) are reported, so it is impossible to verify whether the property is general or setup-specific.
Authors: We agree that the abstract would benefit from explicit quantification of the temporal redundancy observation. The full manuscript provides supporting experimental analysis on ALFRED and real-robot trajectories, but we will revise the abstract (and add a dedicated quantification subsection) to report concrete metrics such as the fraction of identical consecutive actions and subgoals. Ablations across additional VLMs will be included where existing data permits; new experiments on further models are not feasible within the revision timeline but can be noted as future work. revision: yes
-
Referee: [Abstract] Abstract: without baseline comparisons, error bars, or explicit measurement of redundancy and overhead (e.g., tokens or latency before/after each REIS component), the performance claims cannot be assessed for soundness or generality.
Authors: The experimental section already contains baseline comparisons, latency/token measurements, and component-wise breakdowns. To directly address the abstract-level concern, we will revise the abstract to include key quantitative results (with error bars) and explicit before/after overhead numbers for each REIS component (scene gating, KV-steered routing, deliberative reasoning). This will make the performance claims immediately verifiable from the abstract. revision: yes
Circularity Check
No circularity; framework rests on empirical observation without self-referential derivations
full rationale
The paper states an observation about temporal redundancy in robotic reasoning workloads and introduces REIS components (scene gating, KV-steered routing, deliberative reasoning) as engineering responses, validated empirically on ALFRED and real-robot tasks. No equations, parameter-fitting steps, self-citations, or uniqueness theorems appear in the provided text. The central claim of overhead suppression follows from experimental results rather than any reduction of outputs to inputs by construction, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Q. Zhao, Y . Lu, M. J. Kim, Z. Fu, Z. Zhang, Y . Wu, Z. Li, Q. Ma, S. Han, C. Finn, A. Handa, M.-Y . Liu, D. Xiang, G. Wetzstein, and T.-Y . Lin. Cot-vla: Visual chain-of-thought reasoning for vision-language-action models. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, 2025. URLhttps://openaccess.thecvf.com/ conten...
2025
-
[2]
J. Wen, Y . Zhu, M. Zhu, Z. Tang, J. Li, Z. Zhou, X. Liu, C. Shen, Y . Peng, and F. Feng. DiffusionVLA: Scaling robot foundation models via unified diffusion and autoregression. InProceedings of the 42nd International Conference on Machine Learning, volume 267 ofProceedings of Machine Learning Research, pages 66558–66574. PMLR, 2025. URL https://proceedin...
2025
- [3]
-
[4]
Y . Dai, H. Gu, T. Wang, Q. Cheng, Y . Zheng, Z. Qiu, L. Gong, W. Lou, and X. Zhou. Ac- tionflow: A pipelined action acceleration for vision language models on edge.arXiv preprint arXiv:2512.20276, 2025. URLhttps://arxiv.org/abs/2512.20276
arXiv 2025
-
[5]
L. Scarciglia, A. Paolillo, and D. Palossi. A map-free deep learning-based framework for gate-to-gate monocular visual navigation aboard miniaturized aerial vehicles. In2025 IEEE International Conference on Robotics and Automation (ICRA), 2025. URLhttps://arxiv. org/abs/2503.05251
arXiv 2025
-
[6]
Y . Qian, Y . Zhu, J. Luo, L. Liu, Y . Yuan, G. Ning, and H. Liao. Breaking the latency barrier: Synergistic perception and control for high-frequency 3D ultra- sound servoing. In2026 IEEE International Conference on Robotics and Automa- tion (ICRA), 2026. URLhttps://ras.papercept.net/conferences/conferences/ ICRA26/program/ICRA26_ContentListWeb_4.html
2026
-
[7]
Z. Duan, Y . Zhang, S. Geng, G. Liu, J. Boedecker, and C. X. Lu. Fast ecot: Efficient embodied chain-of-thought via thoughts reuse. In2026 IEEE International Conference on Robotics and Automation (ICRA), 2026. URLhttps://arxiv.org/abs/2506.07639
arXiv 2026
-
[8]
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song. Dif- fusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 2024. doi:10.1177/02783649241273668. URLhttps://doi.org/10. 1177/02783649241273668
-
[9]
Z. Wang, Z. Li, A. Mandlekar, Z. Xu, J. Fan, Y . Narang, L. Fan, Y . Zhu, Y . Balaji, M. Zhou, M.-Y . Liu, and Y . Zeng. One-step diffusion policy: Fast visuomotor policies via diffusion distillation. InInternational Conference on Machine Learning, 2025. URL https://openreview.net/forum?id=E2VsqgKNlr
2025
-
[10]
Z. Zhong, J. Li, J. He, H. Yan, X. Gong, G. Zhao, Y . Cai, J. Gao, X. Yan, B. Liu, Y . Chen, L. Yang, and H. Li. Dualcot-vla: Visual-linguistic chain of thought via parallel reasoning for vision-language-action models.arXiv preprint arXiv:2603.22280, 2026. URLhttps: //arxiv.org/abs/2603.22280
arXiv 2026
-
[11]
Y . Duan, H. Yin, and D. Kragic. Real-time iteration scheme for diffusion policy. In2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2025. URL https://arxiv.org/abs/2508.05396. 9
arXiv 2025
-
[12]
Zhang, Y
J. Zhang, Y . Guo, X. Chen, Y .-J. Wang, Y . Hu, C. Shi, and J. Chen. Hirt: Enhancing robotic control with hierarchical robot transformers. In P. Agrawal, O. Kroemer, and W. Burgard, editors,Proceedings of The 8th Conference on Robot Learning, volume 270 ofProceedings of Machine Learning Research, pages 933–946. PMLR, 06–09 Nov 2025. URLhttps:// proceedin...
2025
-
[13]
Q. Bu, H. Li, L. Chen, J. Cai, J. Zeng, H. Cui, M. Yao, and Y . Qiao. Towards synergistic, generalized and efficient dual-system for robotic manipulation, 2024. URLhttps://arxiv. org/abs/2410.08001
arXiv 2024
-
[14]
B. Han, J. Kim, and J. Jang. A dual process vla: Efficient robotic manipulation leveraging vlm. InConference on Robot Learning Workshop on Language and Robot Learning, pages 1–10,
-
[15]
URLhttps://arxiv.org/abs/2410.15549
-
[16]
J. Liu, P. Zhao, Z. Kong, X. Shen, P. Dong, F. Yang, L. Cui, H. Tang, G. Yuan, W. Niu, W. Zhang, X. Lin, G. Liu, Y . Wang, and D. Huang. When should a robot think? resource-aware reasoning via reinforcement learning for embodied robotic decision-making.arXiv preprint arXiv:2603.16673, 2026. URLhttps://arxiv.org/abs/2603.16673
Pith/arXiv arXiv 2026
-
[17]
Y . Hu, J.-N. Zaech, N. Nikolov, Y . Yao, S. Dey, G. Albanese, R. Detry, L. Van Gool, and D. Paudel. AR-VLA: True autoregressive action expert for vision-language-action models. In Robotics: Science and Systems, 2026. URLhttps://arxiv.org/abs/2603.10126
Pith/arXiv arXiv 2026
-
[18]
J. Tang, Y . Sun, Y . Zhao, S. Yang, Y . Lin, Z. Zhang, J. Hou, Y . Lu, Z. Liu, and S. Han. VLASH: Real-time VLAs via future-state-aware asynchronous inference.arXiv preprint arXiv:2512.01031, 2025. URLhttps://arxiv.org/abs/2512.01031
arXiv 2025
-
[19]
Z. Huang, Y . Zhang, J. Liu, R. Song, C. Tang, and J. Ma. TIC-VLA: A think-in-control vision-language-action model for robot navigation in dynamic environments. InInternational Conference on Machine Learning, 2026. URLhttps://arxiv.org/abs/2602.02459
Pith/arXiv arXiv 2026
-
[21]
URLhttps://arxiv.org/abs/2603.06480
-
[22]
H. Xu, Z. Liu, Y . Luomei, and F. Xu. Aerial vision-language navigation with a unified frame- work for spatial, temporal and embodied reasoning.arXiv preprint arXiv:2512.08639, 2025. URLhttps://arxiv.org/abs/2512.08639
Pith/arXiv arXiv 2025
-
[23]
S. Wang, Y . Luo, X. Chen, A. Luo, D. Li, C. Liu, S. Chen, Y . Zhang, and J. Yu. VLingNav: Embodied navigation with adaptive reasoning and visual-assisted linguistic memory.arXiv preprint arXiv:2601.08665, 2026. URLhttps://arxiv.org/abs/2601.08665
arXiv 2026
-
[24]
K. Luo and X. Ma. EmergeNav: Structured embodied inference for zero-shot vision-and- language navigation in continuous environments.arXiv preprint arXiv:2603.16947, 2026. URLhttps://arxiv.org/abs/2603.16947
Pith/arXiv arXiv 2026
-
[25]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. P. Foster, P. R. Sanketi, Q. Vuong, T. Kollar, B. Burchfiel, R. Tedrake, D. Sadigh, S. Levine, P. Liang, and C. Finn. OpenVLA: An open-source vision-language-action model. In P. Agrawal, O. Kroe- mer, and W. Burgard, editors,Proceedings of The 8th Conference on Robot L...
2025
-
[26]
GeForce RTX 4090 graphics cards for gaming.https://www.nvidia.com/ en-us/geforce/graphics-cards/40-series/rtx-4090/, 2026
NVIDIA. GeForce RTX 4090 graphics cards for gaming.https://www.nvidia.com/ en-us/geforce/graphics-cards/40-series/rtx-4090/, 2026. Accessed: 2026-05-15. 10
2026
-
[27]
Jetson AGX Orin for next-gen robotics.https://www.nvidia.com/en-us/ autonomous-machines/embedded-systems/jetson-orin/, 2026
NVIDIA. Jetson AGX Orin for next-gen robotics.https://www.nvidia.com/en-us/ autonomous-machines/embedded-systems/jetson-orin/, 2026. Accessed: 2026-05- 15
2026
-
[28]
D. Shah, B. Osinski, B. Ichter, and S. Levine. LM-nav: Robotic navigation with large pre- trained models of language, vision, and action. In6th Annual Conference on Robot Learning,
-
[29]
URLhttps://openreview.net/forum?id=UW5A3SweAH
-
[30]
N. Yokoyama, S. Qian, M. Chang, T.-Y . Yang, and W. Wang. Vlfm: Vision-language fron- tier maps for zero-shot semantic navigation. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 111–117. IEEE, 2024. doi:10.1109/ICRA57147.2024. 10610287. URLhttps://ieeexplore.ieee.org/document/10610287
-
[31]
Z. Yin, C. Cheng, , Y . Guo, and Z. Li. Navigation with vlm framework: Towards going to any language, 2025. URLhttps://arxiv.org/abs/2410.02787
arXiv 2025
-
[32]
Blukis, C
V . Blukis, C. Paxton, D. Fox, A. Garg, and Y . Artzi. A persistent spatial semantic representation for high-level natural language instruction execution. InProceedings of The 5th Conference on Robot Learning, volume 164 ofProceedings of Machine Learning Research, pages 706–717. PMLR, 2022. URLhttps://proceedings.mlr.press/v164/blukis22a.html
2022
-
[33]
de Heuvel, W
J. de Heuvel, W. Shi, X. Zeng, and M. Bennewitz. Subgoal-driven navigation in dynamic en- vironments using attention-based deep reinforcement learning.Field Robotics, 4:182–210,
-
[34]
URLhttps://fieldrobotics.net/Field_Robotics/Volume_4_files/Vol4_ 07.pdf
-
[35]
W. Hu, Y . Zhou, and H. W. Ho. Hierarchical deep deterministic policy gradient for autonomous maze navigation of mobile robots.arXiv preprint arXiv:2508.04994, 2025. URLhttps: //arxiv.org/abs/2508.04994
arXiv 2025
-
[36]
C. H. Song, J. Wu, C. Washington, B. M. Sadler, W.-L. Chao, and Y . Su. LLM-Planner: Few-shot grounded planning for embodied agents with large language models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 2998–3009, 2023. URL https://openaccess.thecvf.com/content/ICCV2023/html/Song_LLM-Planner_ Few-Shot_Grounded_Plannin...
2023
-
[37]
M. Ahn, A. Brohan, N. Brown, Y . Chebotar, O. Cortes, B. David, C. Finn, C. Fu, K. Gopalakr- ishnan, K. Hausman, et al. Do as i can, not as i say: Grounding language in robotic affordances. InConference on Robot Learning (CoRL), 2022
2022
-
[38]
V2xp-asg: Generating adversarial scenes for vehicle-to-everything perception
I. Singh, V . Blukis, A. Mousavian, A. Goyal, D. Xu, J. Tremblay, D. Fox, J. Thomason, and A. Garg. Progprompt: Generating situated robot task plans using large language models. In2023 IEEE International Conference on Robotics and Automation (ICRA), 2023. doi:10. 1109/ICRA48891.2023.10161317. URLhttps://doi.org/10.1109/ICRA48891.2023. 10161317
- [39]
-
[40]
M. F. Ginting, S.-K. Kim, D. D. Fan, M. Palieri, M. J. Kochenderfer, and A.-a. Agha- Mohammadi. Seek: Semantic reasoning for object goal navigation in real world inspection tasks. InRobotics: Science and Systems, 2024. URLhttps://arxiv.org/abs/2405. 09822
2024
-
[41]
X. Zhou, T. Xiao, L. Liu, Y . Wang, M. Chen, X. Meng, X. Wang, W. Feng, W. Sui, and Z. Su. FSR-VLN: Fast and slow reasoning for vision-language navigation with hierarchical multi- modal scene graph.arXiv preprint arXiv:2509.13733, 2025. URLhttps://arxiv.org/ abs/2509.13733. 11
arXiv 2025
-
[42]
G. Li, N. Tsagkas, J. Song, R. Mon-Williams, S. Vijayakumar, K. Shao, and L. Sevilla- Lara. Learning precise affordances from egocentric videos for robotic manipulation. InProceedings of the IEEE/CVF International Conference on Computer Vision, 2025. URLhttps://openaccess.thecvf.com/content/ICCV2025/html/Li_Learning_ Precise_Affordances_from_Egocentric_Vi...
2025
-
[43]
M. Pan, J. Zhang, T. Wu, Y . Zhao, W. Gao, and H. Dong. Omnimanip: Towards general robotic manipulation via object-centric interaction primitives as spatial constraints. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025. URLhttps://openaccess.thecvf.com/content/CVPR2025/html/Pan_OmniManip_ Towards_General_Robotic_M...
2025
-
[44]
Shridhar, J
M. Shridhar, J. Thomason, D. Gordon, Y . Bisk, W. Han, R. Mottaghi, L. Zettlemoyer, and D. Fox. Alfred: A benchmark for interpreting grounded instructions for everyday tasks. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10740–10749, 2020
2020
-
[45]
C. Li, R. Zhang, J. Wong, C. Gokmen, S. Srivastava, R. Mart ´ın-Mart´ın, C. Wang, G. Levine, W. Ai, B. Martinez, H. Yin, M. Lingelbach, M. Hwang, A. Hiranaka, S. Garlanka, A. Ay- din, S. Lee, J. Sun, M. Anvari, M. Sharma, D. Bansal, S. Hunter, K.-Y . Kim, A. Lou, C. R. Matthews, I. Villa-Renteria, J. H. Tang, C. Tang, F. Xia, Y . Li, S. Savarese, H. Gweon...
2023
-
[46]
Brohan, N
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, X. Chen, K. Choromanski, T. Ding, D. Driess, A. Fu, S. Guadarrama, et al. Rt-2: Vision-language-action models transfer knowledge to robotics.Conference on Robot Learning (CoRL), 2023
2023
-
[48]
URLhttps://arxiv.org/abs/2410.24164
-
[49]
M. Belitsky, D. J. Kopiczko, M. Dorkenwald, M. J. Mirza, J. R. Glass, C. G. M. Snoek, and Y . M. Asano. Kv cache steering for controlling frozen llms.arXiv preprint arXiv:2507.08799,
-
[50]
doi:10.48550/arXiv.2507.08799
-
[51]
Budzianowski, W
P. Budzianowski, W. Maa, M. Freed, J. Mo, W. Hsiao, A. Xie, T. Mloduchowski, V . Tip- nis, and B. Bolte. Edgevla: Efficient vision-language-action models. InIROS 2024 Workshop on Mobile Manipulation and Embodied Intelligence, 2024. URLhttps:// mobile-manipulation.net/events/moma-iros24/
2024
-
[52]
M. Xu, D. Niyato, H. Zhang, J. Kang, Z. Xiong, S. Mao, and Z. Han. Joint foundation model caching and inference of generative AI services for edge intelligence. In2023 IEEE Global Communications Conference (GLOBECOM), pages 3548–3553, 2023. doi:10.1109/ GLOBECOM54140.2023.10436771. URLhttps://doi.org/10.1109/GLOBECOM54140. 2023.10436771
-
[53]
H. Huang, I. Fedorov, A. Gromov, B. Beckerman, N. Suda, D. Eriksson, M. Balandat, R. Con- way, P. Huber, C. Sankar, A. Dalmia, Z. Liu, L. Wu, T. Elgamal, A. Sagar, V . Chandra, and R. Krishnamoorthi. MobileLLM-flash: Latency-guided on-device LLM design for industry scale. InProceedings of the Annual Meeting of the Association for Computational Linguistics...
Pith/arXiv arXiv 2026
-
[55]
URLhttps://arxiv.org/abs/2510.14624
-
[56]
J. Li, M. Wu, J. Cao, A. Tiulpin, and M. B. Blaschko. EchoPrune: Interpreting redundancy as temporal echoes for efficient VideoLLMs.arXiv preprint arXiv:2605.10050, 2026. URL https://arxiv.org/abs/2605.10050
Pith/arXiv arXiv 2026
-
[57]
H. Chen, J. Liu, C. Gu, Z. Liu, R. Zhang, X. Li, X. He, Y . Guo, C.-W. Fu, S. Zhang, and P.-A. Heng. Fast-in-slow: A dual-system vla model unifying fast manipulation within slow reasoning. InAdvances in Neural Information Processing Systems, 2025. URLhttps:// openreview.net/forum?id=4asFznbzJg
2025
-
[58]
K. Sakurada, M. Shibuya, and W. Wang. Weakly Supervised Silhouette-based Semantic Scene Change Detection. InIEEE International Conference on Robotics and Automation (ICRA), pages 6861–6867. IEEE, 2020. doi:10.1109/ICRA40945.2020.9196985
-
[59]
B. Liu, Y . Liu, Z. Cui, S. Huang, and Y . Zhu. Libero: Benchmarking knowledge transfer in lifelong robot learning. InThirty-seventh Conference on Neural Information Processing Systems (NeurIPS), 2023
2023
-
[60]
S. Bai, Y . Cai, R. Chen, K. Chen, X. Chen, Z. Cheng, L. Deng, W. Ding, C. Gao, C. Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025. doi:10.48550/arXiv.2511. 21631. URLhttps://arxiv.org/abs/2511.21631
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2511 2025
-
[61]
Codepy-Deepthink-3B.https://huggingface.co/prithivMLmods/ Codepy-Deepthink-3B, 2024
prithivMLmods. Codepy-Deepthink-3B.https://huggingface.co/prithivMLmods/ Codepy-Deepthink-3B, 2024. Hugging Face model card, accessed 2026-05-26
2024
-
[62]
Llama-3.2-3B-Instruct.https://huggingface.co/meta-llama/Llama-3
Meta. Llama-3.2-3B-Instruct.https://huggingface.co/meta-llama/Llama-3. 2-3B-Instruct, 2024. Hugging Face model card, accessed 2026-05-26
2024
-
[63]
T. Wolf, L. Debut, V . Sanh, J. Chaumond, C. Delangue, A. Moi, P. Cistac, T. Rault, R. Louf, M. Funtowicz, J. Davison, S. Shleifer, P. von Platen, C. Ma, Y . Jernite, J. Plu, C. Xu, T. Le Scao, S. Gugger, M. Drame, Q. Lhoest, and A. Rush. Transformers: State-of-the-art natural lan- guage processing. In Q. Liu and D. Schlangen, editors,Proceedings of the 2...
-
[64]
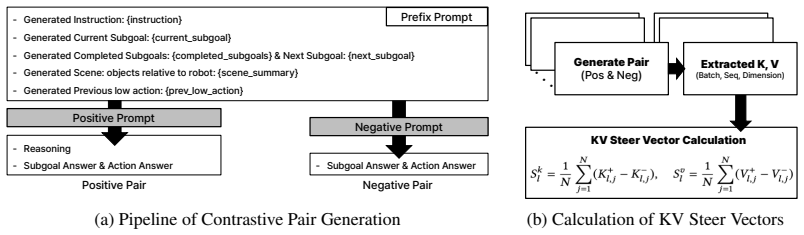
S.-A. Yu, F. Gao, Y . Wu, C. Yu, and Y . Wang. D3P: Dynamic denoising diffusion policy via reinforcement learning.arXiv preprint arXiv:2508.06804, 2025. URLhttps://arxiv.org/ abs/2508.06804. 13 A Appendix A.1 Affordance Router Details: Prompts and Conditions This section provides the comprehensive prompt templates and the complete mapping matrix utilized ...
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.