AutoSci: A Memory-Centric Agentic System for the Full Scientific Research Lifecycle
Pith reviewed 2026-06-28 22:05 UTC · model grok-4.3
The pith
AutoSci integrates four modules to create a persistent LLM agent system that executes, remembers, and improves full scientific research projects over time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
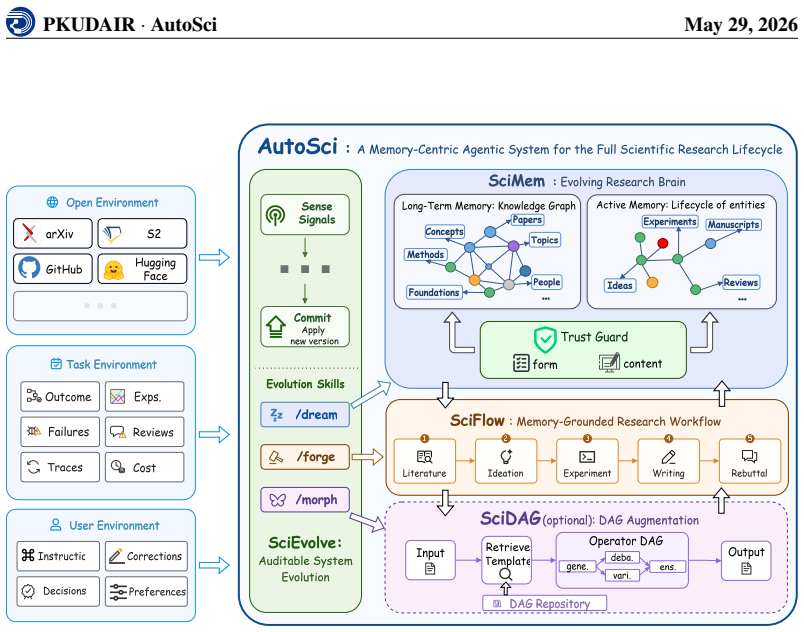
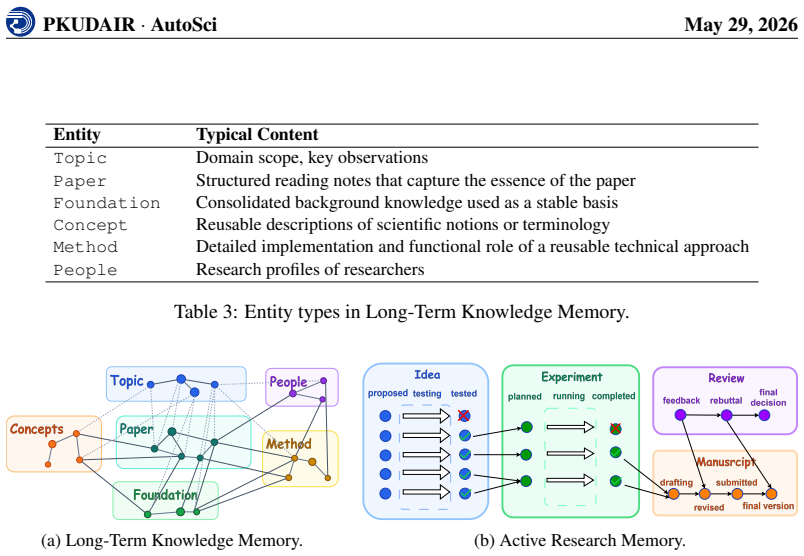
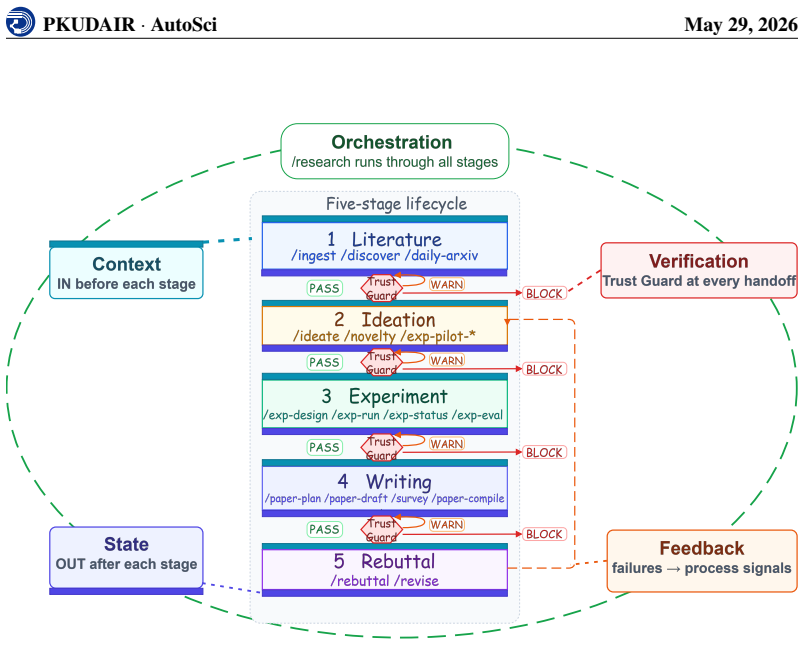
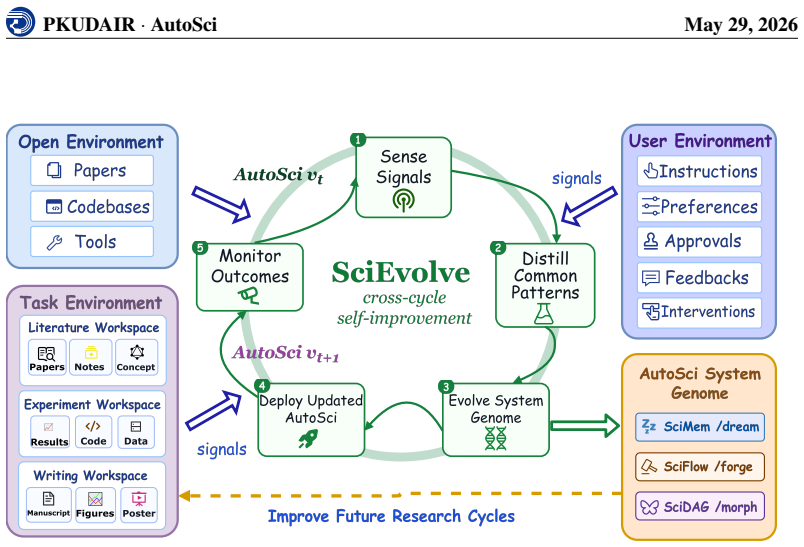
AutoSci is organized around four modules. SciMem provides schema-governed research memory, separating Long-Term Knowledge Memory for reusable scientific knowledge from Active Research Memory for project-level artifacts such as ideas, experiments, manuscripts, and reviews. SciFlow executes a five-stage lifecycle from literature understanding to rebuttal through a harness that controls state, context, verification, feedback, and orchestration. SciDAG augments difficult skills with DAG-shaped multi-agent operators and reusable stage-specific templates. SciEvolve converts feedback signals from users, experiments, reviews, and external environments into versioned updates to SciMem organization, S
What carries the argument
The four integrated modules (SciMem for schema-governed memory separation, SciFlow for five-stage lifecycle harness, SciDAG for DAG-shaped multi-agent operators with templates, and SciEvolve for feedback-driven versioned updates) that together enable execution, persistence, and self-improvement.
If this is right
- The system can carry a project through literature understanding, idea generation, experiments, manuscript writing, and rebuttal responses without resetting between stages.
- Structured memory keeps reusable scientific knowledge separate from project-specific artifacts so later work can draw on earlier results.
- Difficult research skills are handled by reusable DAG-shaped multi-agent operators and stage-specific templates.
- Feedback from experiments, reviews, and users produces versioned updates to memory schemas, workflow skills, and operator templates.
- The result is a single environment that persists across separate research projects rather than treating each one in isolation.
Where Pith is reading between the lines
- Over repeated projects the accumulated memory could reduce duplication of effort in fields where similar background knowledge applies.
- The self-update mechanism might allow gradual refinement of research practices that are hard to codify in advance.
- Testing on narrow domains first would reveal whether the integration of the four modules holds together at scale.
Load-bearing premise
The four modules can be successfully combined into a working system that uses feedback to improve its own research procedures across multiple projects.
What would settle it
Run the system on a complete research task from literature search to final rebuttal and check whether it produces usable outputs while showing measurable reduction in errors or manual interventions on a follow-up similar task.
Figures

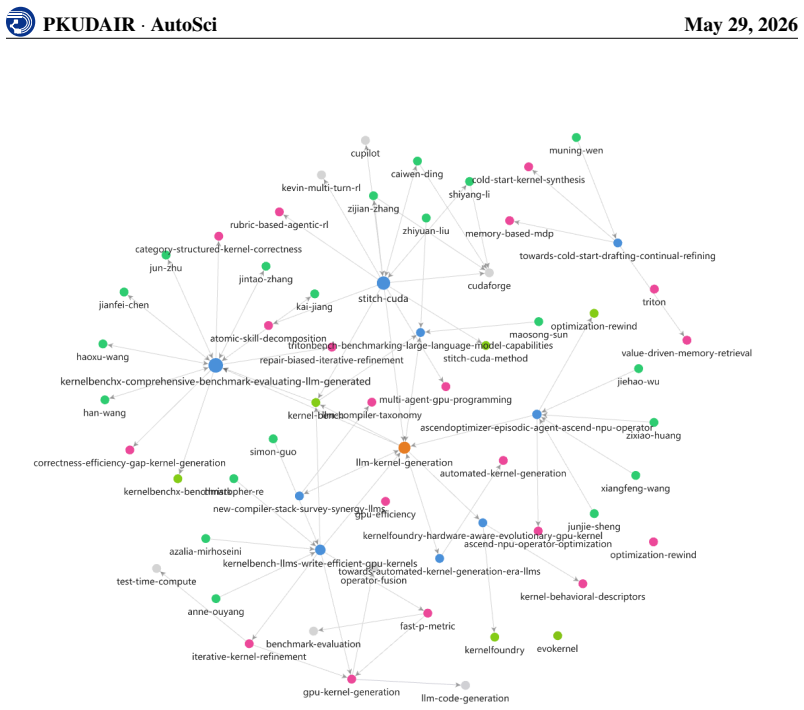
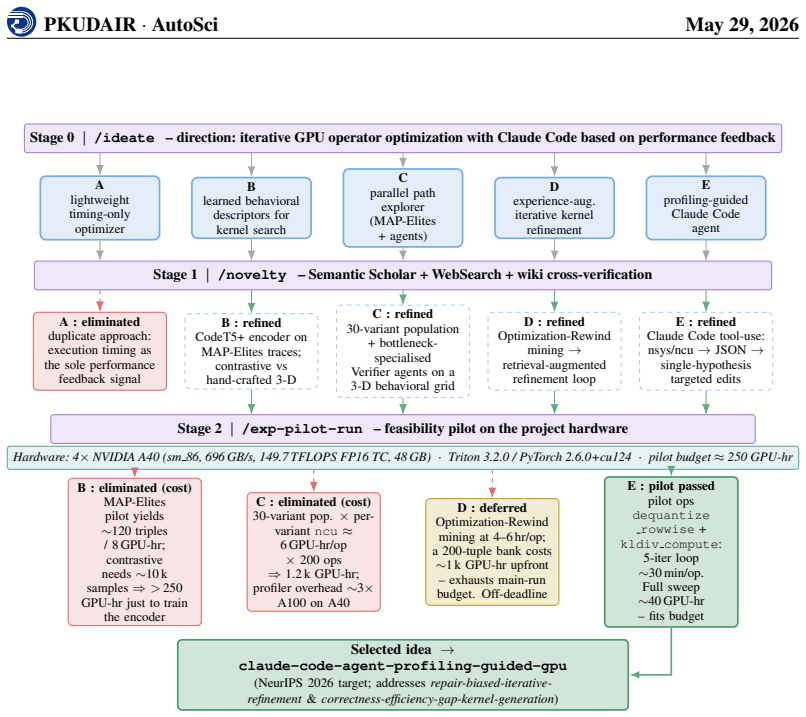


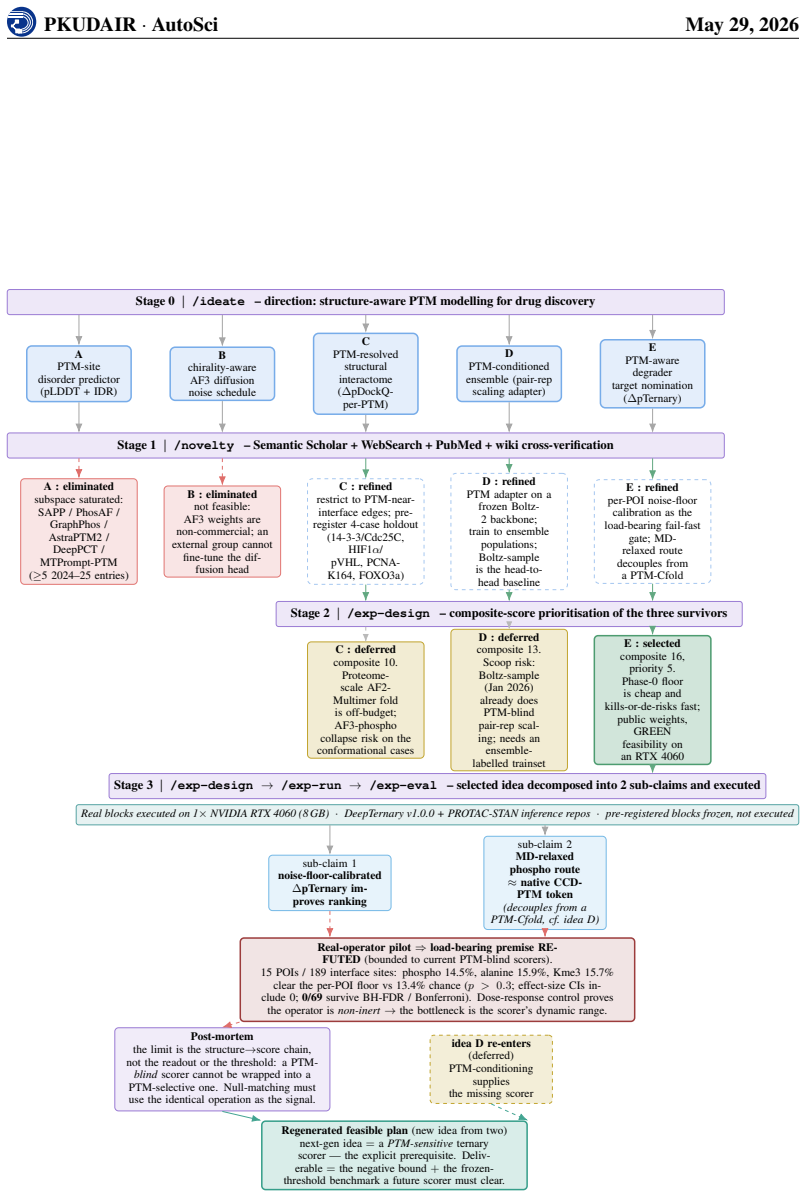

read the original abstract
Scientific research has traditionally been human-intensive, requiring researchers to coordinate literature, ideas, experiments, manuscripts, and review responses across long project cycles. The rise of LLM-based scientific agents creates an opportunity to automate this process. Such a system must support the full research lifecycle, maintain structured persistent memory across projects, and improve its own research procedures over time. However, existing systems either partially satisfy or fail to satisfy these requirements, leaving a gap for a unified automated scientific research system. As a result, we present AutoSci, a memory-centric agentic system for the full scientific research lifecycle. AutoSci is organized around four modules. SciMem provides schema-governed research memory, separating Long-Term Knowledge Memory for reusable scientific knowledge from Active Research Memory for project-level artifacts such as ideas, experiments, manuscripts, and reviews. SciFlow executes a five-stage lifecycle from literature understanding to rebuttal through a harness that controls state, context, verification, feedback, and orchestration. SciDAG augments difficult skills with DAG-shaped multi-agent operators and reusable stage-specific templates. SciEvolve converts feedback signals from users, experiments, reviews, and external environments into versioned updates to SciMem organization, SciFlow skills, and SciDAG templates. Together, these modules make AutoSci a persistent research environment that can execute, remember, and evolve across research projects. The code repository is available at https://github.com/skyllwt/AutoSci.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents AutoSci, a memory-centric agentic system for automating the full scientific research lifecycle. It is organized into four modules: SciMem (schema-governed memory separating long-term knowledge from active project artifacts), SciFlow (five-stage execution harness from literature review to rebuttal), SciDAG (DAG-shaped multi-agent operators with reusable templates), and SciEvolve (feedback-driven versioned updates to memory organization, skills, and templates). The central claim is that these modules together enable a persistent environment that can execute, remember, and evolve its own research procedures across projects; a code repository is linked.
Significance. If the described integration can be validated to produce measurable self-improvement in research tasks, the work would address a genuine gap in existing LLM-based scientific agents by providing structured persistence and evolution mechanisms. The modular design and explicit feedback-to-update loop are conceptually coherent and could serve as a useful reference architecture for future agentic systems in science.
major comments (2)
- [Abstract / system overview] Abstract and system description (throughout): The manuscript asserts that the four modules 'make AutoSci a persistent research environment that can execute, remember, and evolve across research projects,' yet supplies no quantitative metrics, ablation studies, multi-project case studies, before/after performance comparisons, or error analysis demonstrating that SciEvolve updates produce measurable downstream improvements. This absence directly undermines the central claim of functional integration and self-evolution.
- [SciEvolve description] SciEvolve module description: The feedback-to-update mechanism is described at a high level (converting signals from users, experiments, reviews into versioned changes), but no concrete update rules, versioning schema, or evaluation of whether updates actually improve SciFlow or SciDAG performance are provided. Without such evidence the self-improvement loop remains an untested assumption.
minor comments (2)
- [SciFlow] The five-stage harness in SciFlow is outlined but lacks detail on state management, verification steps, or how context is maintained across stages; a concrete example or pseudocode would improve clarity.
- [Abstract] The GitHub link is provided but the manuscript does not indicate whether the released code includes runnable examples or the full module implementations described.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We appreciate the recognition of the modular design's conceptual coherence. We address the major comments below and indicate planned revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract / system overview] Abstract and system description (throughout): The manuscript asserts that the four modules 'make AutoSci a persistent research environment that can execute, remember, and evolve across research projects,' yet supplies no quantitative metrics, ablation studies, multi-project case studies, before/after performance comparisons, or error analysis demonstrating that SciEvolve updates produce measurable downstream improvements. This absence directly undermines the central claim of functional integration and self-evolution.
Authors: We agree that the manuscript does not contain quantitative metrics, ablation studies, or performance comparisons demonstrating measurable improvements from SciEvolve. As a system-description paper, the central claim concerns the architectural integration that enables persistence and evolution, with the linked code repository providing the concrete implementation. We will revise the abstract, introduction, and conclusion to qualify the claim as describing design-enabled capabilities rather than validated outcomes, and we will add an explicit limitations section noting the absence of such empirical evaluations. revision: yes
-
Referee: [SciEvolve description] SciEvolve module description: The feedback-to-update mechanism is described at a high level (converting signals from users, experiments, reviews into versioned changes), but no concrete update rules, versioning schema, or evaluation of whether updates actually improve SciFlow or SciDAG performance are provided. Without such evidence the self-improvement loop remains an untested assumption.
Authors: The SciEvolve section presents the mechanism at the architectural level. Concrete update rules and the versioning schema are realized in the released code. We will expand the SciEvolve description with additional concrete examples of update rules and the versioning approach. We concur that the manuscript does not evaluate whether these updates improve downstream performance and will add a limitations paragraph stating that empirical assessment of the self-improvement loop is left for future work. revision: partial
- Quantitative metrics, ablation studies, multi-project case studies, and before/after performance comparisons demonstrating that SciEvolve produces measurable improvements, as these are not present in the current manuscript and would require new experiments.
Circularity Check
No circularity: high-level system design with no derivations or fitted claims
full rationale
The manuscript is a system architecture proposal describing four modules (SciMem, SciFlow, SciDAG, SciEvolve) and their intended interactions. No equations, parameters, predictions, or derivation chains appear in the provided text. The central claim is that the described components together form a persistent self-evolving environment; this is presented as a design statement rather than a result derived from prior equations or self-citations. No load-bearing self-citation, ansatz smuggling, or renaming of known results is present. The absence of any mathematical or empirical reduction means the paper is self-contained as a proposal and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
NORA: A Harness-Engineered Autonomous Research Agent for End-to-End Spatial Data Science
URLhttps://arxiv.org/abs/2605.02092. Wangchunshu Zhou, Yixin Ou, Shengwei Ding, Long Li, Jialong Wu, Tiannan Wang, Jiamin Chen, Shuai Wang, Xiaohua Xu, Ningyu Zhang, et al. Symbolic learning enables self-evolving agents. arXiv preprint arXiv:2406.18532, 2024. Mingchen Zhuge, Wenyi Wang, Louis Kirsch, Francesco Faccio, Dmitrii Khizbullin, and Juergen Schmi...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Start from the strongest available implementation of an operator
-
[3]
An inverse agent proposes semantically meaningful de-optimizations (removing pipelining, breaking vectorized paths, reintroducing synchronization, . . . )
-
[4]
Each de-optimized candidate is compiled, correctness-checked and profiled on real hardware
-
[5]
Validated degradations are distilled into experience tuples(Title, Bottleneck, Applicability, Effect, Diff)
-
[6]
KernelBench: Can LLMs Write Efficient GPU Kernels?
## Assumptions (excerpt) Optimization motifs arecompositional– they can be removed and added independently, so a single-factor screen (∆m = Lat(K A\{m})−Lat(K A)) recovers each motif’s marginal contribution. The profiling noise thresholdτ noise is taken to be stable across de-optimizations . . . ## ... Method entry.A concrete system, algorithm or benchmar...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.