Batched Differentiable Rigid Body Dynamics in PyTorch for GPU-Accelerated Robot Learning
Pith reviewed 2026-06-28 22:18 UTC · model grok-4.3
The pith
BARD delivers batched rigid-body dynamics in PyTorch that match Pinocchio accuracy while running up to 64 times faster on GPU for large robot batches.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
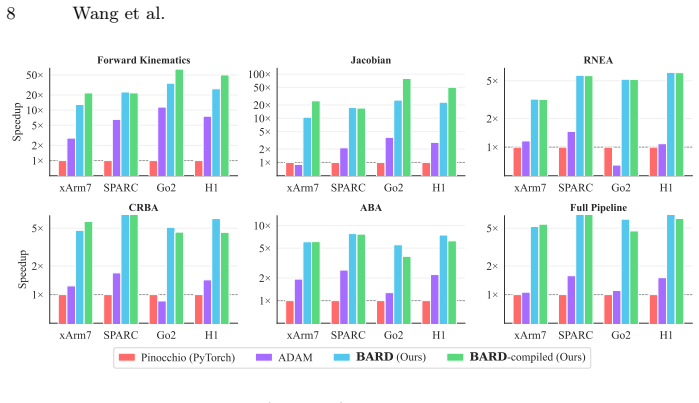
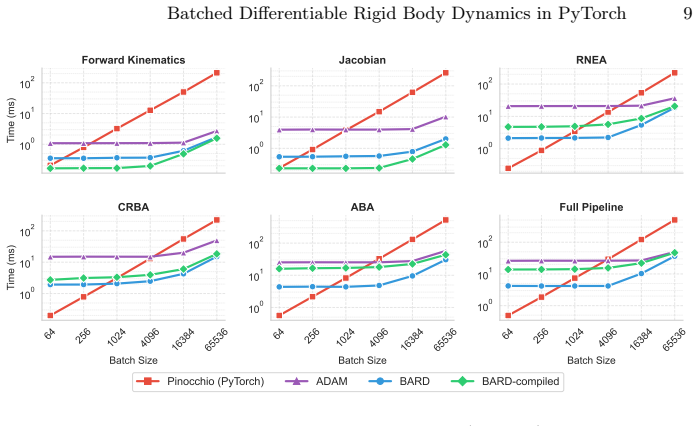
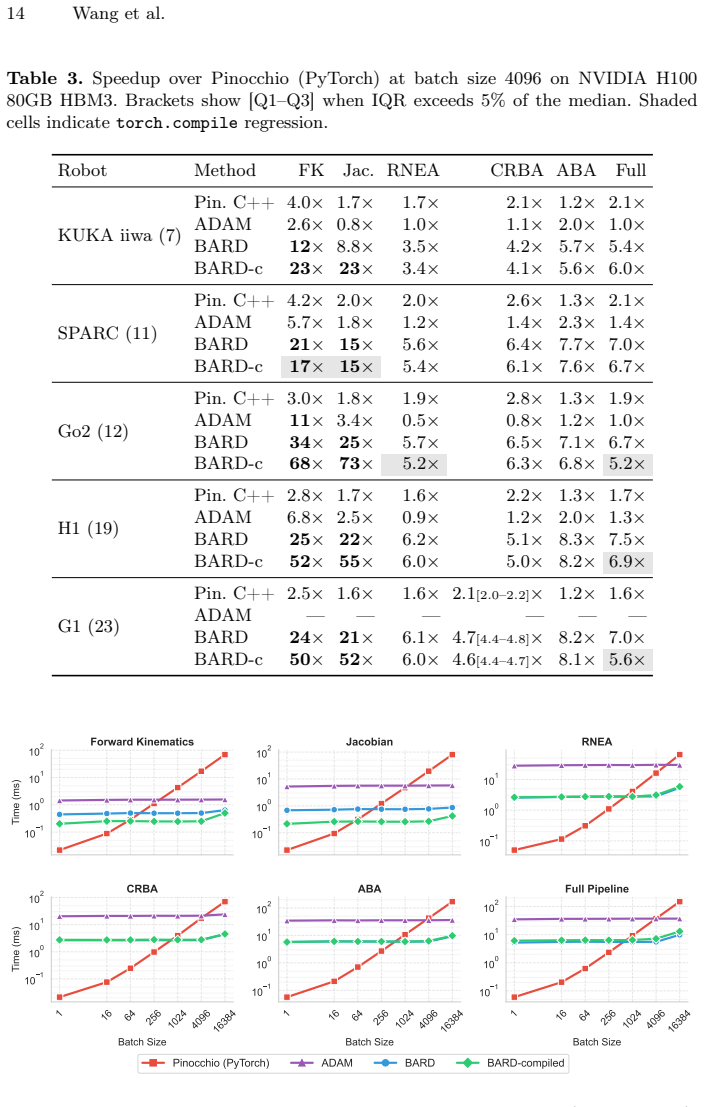
BARD implements Featherstone's algorithms in PyTorch so that forward kinematics, Jacobians, and full dynamics can be evaluated in large batches on GPU; the three design choices keep results numerically identical to Pinocchio while producing up to 64x higher throughput for kinematics and 63x for Jacobians at batch size 4096, and the same gradients support system identification to 1.24 percent mean mass error under 5 percent noise as well as 8.5x faster in-loop dynamics inside an 11-DOF quadruped training run with 4096 environments.
What carries the argument
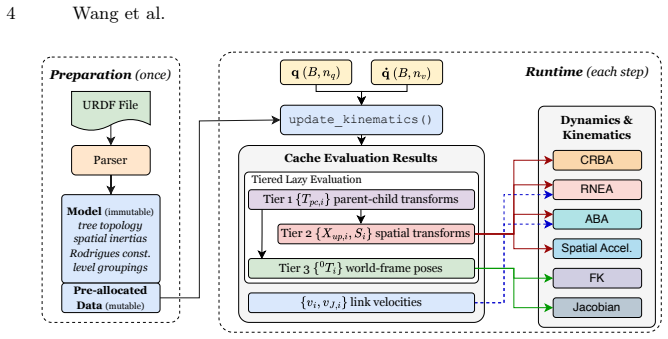
The tiered lazy-evaluation cache that skips redundant tree traversals together with matmul-free joint transforms via pre-computed Rodrigues constants and level-parallel propagation that collapses sequential steps to tree-depth batched operations.
If this is right
- Robot reinforcement learning can run thousands of parallel environments with full dynamics inside the training loop on a single GPU.
- Gradient-based system identification becomes practical without leaving the GPU.
- Existing GPU training frameworks can replace CPU dynamics calls and obtain measured speedups of 2x to 8.5x.
- Batch sizes of several thousand become usable for models between 7 and 23 degrees of freedom without accuracy loss.
Where Pith is reading between the lines
- The same cache and parallel-propagation pattern could be applied to other tree-structured kinematic or dynamic calculations.
- Extending the implementation to contact-rich or floating-base models would test whether the speed advantage survives added complexity.
- Users could measure whether the observed speedups remain when the same code runs on other GPU architectures or at even larger batch sizes.
Load-bearing premise
The caching, transform, and propagation choices keep numerical values and gradient computation correct for every robot model and every batch size that will be used.
What would settle it
Compute forward kinematics and its Jacobian for one of the 7-to-23-DOF test robots at batch size 4096 on GPU, then compare every output entry and every gradient entry against an independent high-precision CPU reference; any difference larger than machine epsilon would disprove the claim.
Figures
read the original abstract
As robot control shifts toward large-scale reinforcement learning with in-loop dynamics computation, the community's reliance on CPU-bound libraries such as Pinocchio creates a throughput bottleneck in GPU-based training pipelines. We present BARD (Batched Articulated Rigid-body Dynamics), a self-contained PyTorch implementation of Featherstone's rigid-body dynamics algorithms, optimized for batched GPU evaluation and automatic differentiation. Three design choices make this efficient: a tiered lazy-evaluation cache that avoids redundant tree traversals, matmul-free joint transforms via pre-computed Rodrigues constants, and level-parallel propagation that reduces sequential operations to tree-depth batched steps. On five robot models (7-23 DOFs), BARD matches Pinocchio numerically while reaching up to 64x higher throughput for Forward Kinematics and 63x for Jacobians at batch size 4096 on an NVIDIA H200. We validate differentiability through gradient-based system identification on a 7-DOF manipulator, recovering link masses to 1.24% mean error under 5% torque noise, and integrate BARD into an Isaac Lab AMP training pipeline for an 11-DOF spined quadruped with 4096 parallel environments, where it is 8.5x faster than Pinocchio and 2.0x faster than ADAM for in-loop dynamics. BARD is open-sourced at: https://github.com/YueWang996/bard-pytorch-dynamics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces BARD, a self-contained PyTorch implementation of Featherstone's rigid-body dynamics algorithms optimized for batched GPU evaluation and automatic differentiation. Key design choices include a tiered lazy-evaluation cache, matmul-free joint transforms using pre-computed Rodrigues constants, and level-parallel propagation. On five robot models (7-23 DOFs), it claims numerical equivalence to Pinocchio with up to 64x throughput for forward kinematics and 63x for Jacobians at batch size 4096 on an NVIDIA H200; differentiability is validated via gradient-based system identification recovering link masses to 1.24% mean error under noise; and integration into an Isaac Lab AMP pipeline for an 11-DOF quadruped shows 8.5x speedup over Pinocchio and 2.0x over ADAM with 4096 environments.
Significance. If the optimizations preserve numerical accuracy to machine precision and produce correct gradients, the work would address a key throughput bottleneck in GPU-based robot learning pipelines, enabling larger-scale in-loop dynamics for reinforcement learning. The open-source release and concrete integration example add practical value.
major comments (2)
- [Abstract] Abstract: the claim that BARD 'matches Pinocchio numerically' for forward kinematics and Jacobians on five models is load-bearing for the central accuracy and speedup assertions, yet no quantitative support (maximum absolute errors, per-model residual tables, or error-bar reporting) is provided to confirm equivalence under the tiered cache and level-parallel reordering.
- [Abstract] Abstract: the differentiability validation via system identification (1.24% mean mass error) does not address whether the lazy-evaluation cache and level-parallel propagation preserve correct autograd tape construction and gradient values relative to a sequential reference implementation; no gradient-norm comparisons or per-operation checks are mentioned.
minor comments (1)
- The throughput numbers (64x, 63x, 8.5x) are reported without benchmark methodology details, hardware configuration beyond 'NVIDIA H200', or variance across runs.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on strengthening the quantitative support for our claims. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that BARD 'matches Pinocchio numerically' for forward kinematics and Jacobians on five models is load-bearing for the central accuracy and speedup assertions, yet no quantitative support (maximum absolute errors, per-model residual tables, or error-bar reporting) is provided to confirm equivalence under the tiered cache and level-parallel reordering.
Authors: We agree that the abstract would be strengthened by explicit quantitative metrics. The full manuscript (Section 4.1 and associated tables) reports per-model maximum absolute errors for forward kinematics and Jacobians that remain below 1e-8 (within floating-point precision) when using the tiered cache and level-parallel propagation. We will revise the abstract to include a brief statement of these maximum errors and ensure clear cross-references to the supporting tables and figures. revision: yes
-
Referee: [Abstract] Abstract: the differentiability validation via system identification (1.24% mean mass error) does not address whether the lazy-evaluation cache and level-parallel propagation preserve correct autograd tape construction and gradient values relative to a sequential reference implementation; no gradient-norm comparisons or per-operation checks are mentioned.
Authors: The system-identification experiment demonstrates end-to-end correctness through accurate mass recovery, but we concur that direct verification of gradient fidelity under the proposed optimizations is warranted. We will add an appendix containing gradient-norm comparisons and per-operation checks against a sequential reference implementation, confirming that the lazy cache and level-parallel methods preserve both the autograd tape and numerical gradient values. These results will be incorporated into the revised manuscript. revision: yes
Circularity Check
No circularity: empirical validation of GPU implementation against external reference library
full rationale
The paper implements known Featherstone rigid-body algorithms in PyTorch with batched GPU optimizations (lazy cache, Rodrigues constants, level-parallel propagation). All performance and accuracy claims rest on direct numerical comparison to the independent external library Pinocchio plus separate empirical tests (system ID recovering masses, integration into Isaac Lab). No self-referential equations, fitted inputs presented as predictions, self-citation load-bearing, or ansatz smuggling appear in the provided text. The central results are externally falsifiable and do not reduce to the paper's own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)
Bledt, G., Powell, M.J., Katz, B., Di Carlo, J., Wensing, P.M., Kim, S.: Mit cheetah 3: Design and control of a robust, dynamic quadruped robot. In: 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). pp. 2245–
2018
-
[2]
In: Robotics: Science and Systems (RSS) (2018)
Carpentier, J., Mansard, N.: Analytical derivatives of rigid body dynamics algo- rithms. In: Robotics: Science and Systems (RSS) (2018)
2018
-
[3]
In: IEEE Inter- national Symposium on System Integration (SII)
Carpentier, J., Saurel, G., Buondonno, G., Mirabel, J., Lamiraux, F., Stasse, O., Mansard, N.: The Pinocchio C++ library: A fast and flexible implementation of rigid body dynamics algorithms and their analytical derivatives. In: IEEE Inter- national Symposium on System Integration (SII). pp. 614–619. IEEE (2019)
2019
-
[4]
Frontiers in neurorobotics13, 406386 (2019)
Degrave, J., Hermans, M., Dambre, J., et al.: A differentiable physics engine for deep learning in robotics. Frontiers in neurorobotics13, 406386 (2019)
2019
-
[5]
Springer, New York (2008)
Featherstone, R.: Rigid Body Dynamics Algorithms. Springer, New York (2008)
2008
-
[6]
Autonomous Robots41(2), 495–511 (2017)
Felis, M.L.: RBDL: An efficient rigid-body dynamics library using recursive algo- rithms. Autonomous Robots41(2), 495–511 (2017)
2017
-
[7]
In: Conference on Neural Information Processing Systems, Datasets and Benchmarks Track (2021)
Freeman, C.D., Frey, E., Raichuk, A., Girgin, S., Mordatch, I., Bachem, O.: Brax – a differentiable physics engine for large scale rigid body simulation. In: Conference on Neural Information Processing Systems, Datasets and Benchmarks Track (2021)
2021
-
[8]
DiffTaichi: Differentiable programming for physical simulation
Hu, Y., Anderson, L., Li, T.M., Sun, Q., Carr, N., Ragan-Kelley, J., Durand, F.: Difftaichi: Differentiable programming for physical simulation. arXiv preprint arXiv:1910.00935 (2019)
-
[9]
Science Robotics 4(26), eaau5872 (2019)
Hwangbo,J.,Lee,J.,Dosovitskiy,A.,Bellicoso,D.,Tsounis,V.,Koltun,V.,Hutter, M.: Learning agile and dynamic motor skills for legged robots. Science Robotics 4(26), eaau5872 (2019)
2019
-
[10]
IEEE Robotics and Automation Letters4(2), 1595–1602 (2019)
Kashiri, N., Baccelliere, L., Muratore, L., Laurenzi, A., Ren, Z., Hoffman, E.M., Kamedula, M., Rigano, G.F., Malzahn, J., Cordasco, S., Guria, P., Margan, A., Tsagarakis, N.G.: Centauro: A hybrid locomotion and high power resilient manip- ulation platform. IEEE Robotics and Automation Letters4(2), 1595–1602 (2019)
2019
-
[11]
IEEE Robotics and Automation Let- ters6(2), 3413–3420 (2021)
Le Lidec, Q., Kalevatykh, I., Laptev, I., Schmid, C., Carpentier, J.: Differentiable simulation for physical system identification. IEEE Robotics and Automation Let- ters6(2), 3413–3420 (2021)
2021
-
[12]
https://github.com/ami-iit/adam (2025)
L’Erario, G., Traversaro, S., Sartore, C., Grieco, R., Dafarra, S., Romualdi, G., Fer- retti, F.L., Pucci, D.: ADAM: Automatic differentiation for rigid-body-dynamics algorithms and models. https://github.com/ami-iit/adam (2025)
2025
-
[13]
In: International Conference on Principles and Practice of Multi-Agent Systems
Li, Z., Wang, Y., Wu, W., Xu, Y., Stein, S.: Hmcf: A human-in-the-loop multi- robot collaboration framework based on large language models. In: International Conference on Principles and Practice of Multi-Agent Systems. pp. 150–167 (2025)
2025
-
[14]
In: Conference on Neural Information Processing Systems, Datasets and Benchmarks Track (2021)
Makoviychuk, V., Wawrzyniak, L., Guo, Y., Lu, M., Storey, K., Macklin, M., Hoeller, D., Rudin, N., Allshire, A., Handa, A., State, G.: Isaac Gym: High perfor- mance GPU-based physics simulation for robot learning. In: Conference on Neural Information Processing Systems, Datasets and Benchmarks Track (2021)
2021
-
[15]
In: IEEE International Conference on Robotics and Automation (ICRA)
Mastalli, C., Budhiraja, R., Merkt, W., Saurel, G., Hammoud, B., Naveau, M., Carpentier, J., Righetti, L., Vijayakumar, S., Mansard, N.: Crocoddyl: An efficient and versatile framework for multi-contact optimal control. In: IEEE International Conference on Robotics and Automation (ICRA). pp. 2536–2542. IEEE (2020) 12 Wang et al
2020
-
[16]
Autonomous Robots49(3), 19 (2025)
Mattamala, M., Frey, J., Libera, P., Chebrolu, N., Martius, G., Cadena, C., Hutter, M., Fallon, M.: Wild visual navigation: Fast traversability learning via pre-trained models and online self-supervision. Autonomous Robots49(3), 19 (2025)
2025
-
[17]
arXiv preprint arXiv:2202.11217 (2022)
Meier, F., Wang, A., Sutanto, G., Lin, Y., Shah, P.: Differentiable and learnable robot models. arXiv preprint arXiv:2202.11217 (2022)
-
[18]
Advances in Neural Information Processing Sys- tems32(2019)
Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., Killeen, T., Lin, Z., Gimelshein, N., Antiga, L., et al.: PyTorch: An imperative style, high- performance deep learning library. Advances in Neural Information Processing Sys- tems32(2019)
2019
-
[19]
In: ACM SIGGRAPH
Peng,X.B.,Ma,Z.,Abbeel,P.,Levine,S.,Kanazawa,A.:AMP:Adversarialmotion priors for stylized physics-based character animation. In: ACM SIGGRAPH. pp. 1–15 (2021)
2021
-
[20]
In: IEEE International Conference on Robotics and Automation (ICRA)
Plancher,B.,Neuman,S.M.,Ghosal,R.,Kuindersma,S.,Reddi,V.J.:GRiD:GPU- accelerated rigid body dynamics with analytical gradients. In: IEEE International Conference on Robotics and Automation (ICRA). pp. 3728–3734. IEEE (2022)
2022
-
[21]
In: Conference on Robot Learning (CoRL)
Rudin, N., Hoeller, D., Reist, P., Hutter, M.: Learning to walk in minutes using massively parallel deep reinforcement learning. In: Conference on Robot Learning (CoRL). pp. 91–100. PMLR (2021)
2021
-
[22]
In: 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)
Sathyamoorthy, A.J., Weerakoon, K., Guan, T., Russell, M., Conover, D., Pusey, J., Manocha, D.: Vern: Vegetation-aware robot navigation in dense unstructured outdoor environments. In: 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). pp. 11233–11240. IEEE (2023)
2023
-
[23]
https://drake.mit.edu (2019)
Tedrake, R., the Drake Development Team: Drake: Model-based design and verifi- cation for robotics. https://drake.mit.edu (2019)
2019
-
[24]
In: Proceedings of the 3rd ACM SIGPLAN International Workshop on Machine Learning and Programming Languages
Tillet, P., Kung, H.T., Cox, D.: Triton: an intermediate language and compiler for tiled neural network computations. In: Proceedings of the 3rd ACM SIGPLAN International Workshop on Machine Learning and Programming Languages. pp. 10–19 (2019)
2019
-
[25]
arXiv preprint arXiv:2510.01984 (2025)
Wang, Y.: SPARC: Spine with prismatic and revolute compliance for quadruped robot. arXiv preprint arXiv:2510.01984 (2025)
-
[26]
In: 2025 IEEE 64th Conference on Decision and Control (CDC)
Wang, Y., Wang, H., Li, Z.: Quattro: transformer-accelerated iterative linear quadratic regulator framework for fast trajectory optimization. In: 2025 IEEE 64th Conference on Decision and Control (CDC). pp. 6629–6636. IEEE (2025)
2025
-
[27]
arXiv preprint arXiv:2103.16021 (2021)
Werling, K., Omens, D., Lee, J., Exarchos, I., Liu, C.K.: Fast and feature-complete differentiable physics for articulated rigid bodies with contact. arXiv preprint arXiv:2103.16021 (2021)
-
[28]
In: 2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)
Xu, Y., Zauner, K.P., Tarapore, D.: Blind-wayfarer: A minimalist, probing-driven framework for resilient navigation in perception-degraded environments. In: 2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). pp. 19340–19345. IEEE (2025)
2025
-
[29]
Mujoco playground.arXiv preprint arXiv:2502.08844,
Zakka, K., Tabanpour, B., Liao, Q., Haiderbhai, M., Holt, S., Luo, J.Y., Allshire, A., Frey, E., Sreenath, K., Kahrs, L.A., et al.: MuJoCo Playground. arXiv preprint arXiv:2502.08844 (2025)
-
[30]
https://github.com/UM-ARM-Lab/pytorch_ kinematics (2024)
Zhong, S., Power, T., Gupta, A., Mitrano, P.: pytorch_kinematics: A PyTorch library for differentiable kinematics. https://github.com/UM-ARM-Lab/pytorch_ kinematics (2024)
2024
-
[31]
Science robotics7(66), eabm5954 (2022)
Zhou, X., Wen, X., Wang, Z., Gao, Y., Li, H., Wang, Q., Yang, T., Lu, H., Cao, Y., Xu, C., et al.: Swarm of micro flying robots in the wild. Science robotics7(66), eabm5954 (2022)
2022
-
[32]
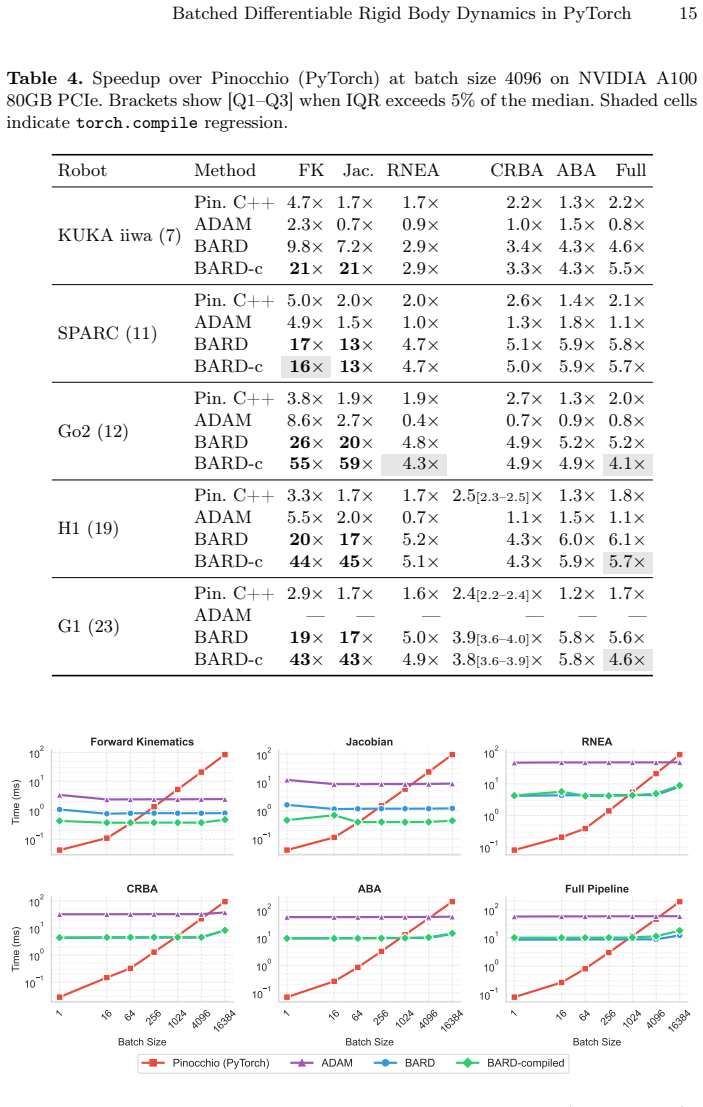
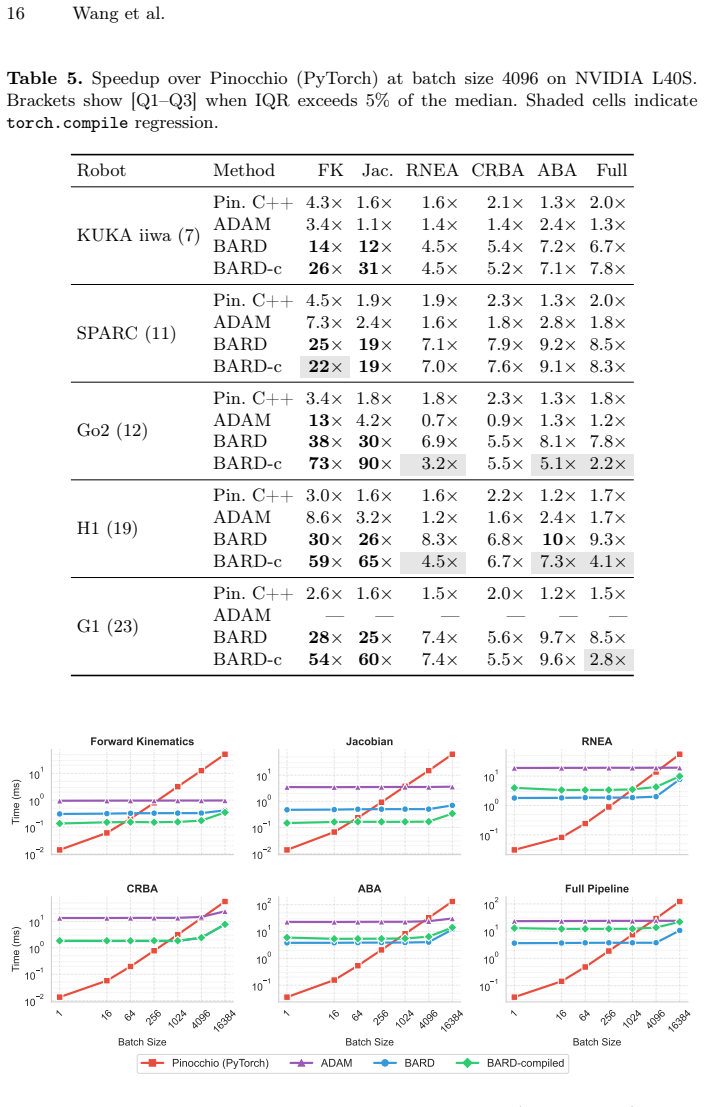
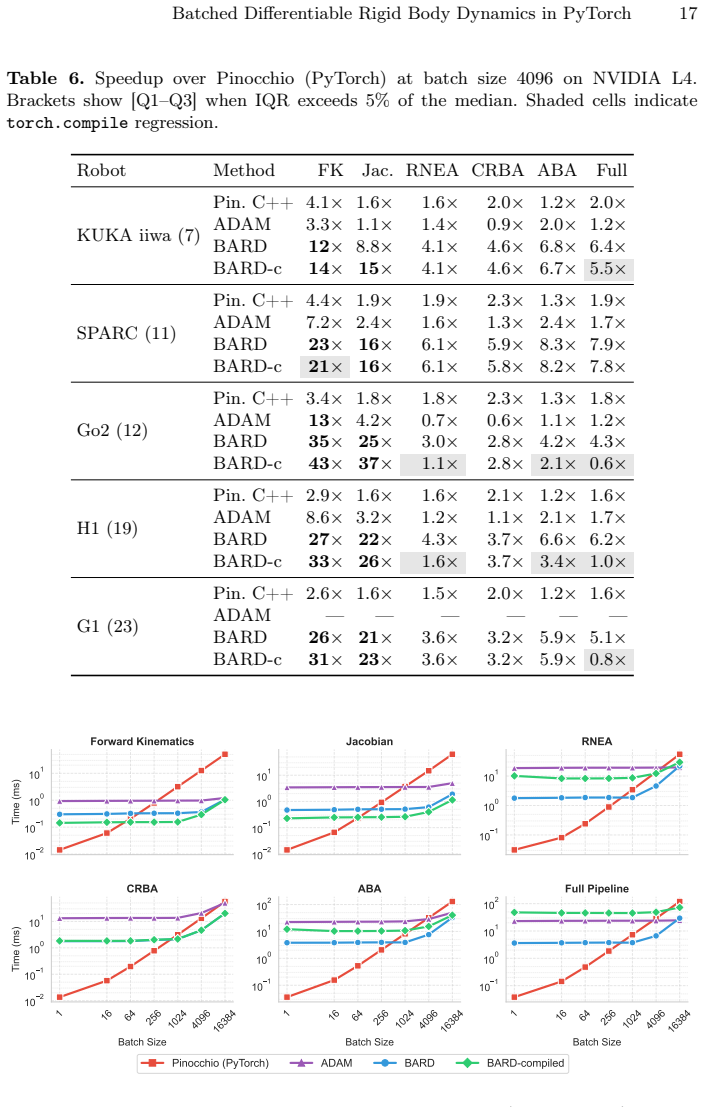
Zhuang,Z.,Yao,S.,Zhao,H.:Humanoidparkourlearning.In:ConferenceonRobot Learning. pp. 1975–1991. PMLR (2025) Batched Differentiable Rigid Body Dynamics in PyTorch 13 Supplementary Material ThisappendixprovidesextendedbenchmarkresultsforbardacrossfourNVIDIA GPUs: H100 80GB HBM3, A100 80GB PCIe, L40S, and L4. All timings use the same protocol as the main pape...
1975
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.