Balanced LoRA: Removing Parameter Invariance to Accelerate Convergence
Pith reviewed 2026-06-28 22:59 UTC · model grok-4.3
The pith
Projecting LoRA factors onto a balanced manifold removes invariance and accelerates convergence during fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
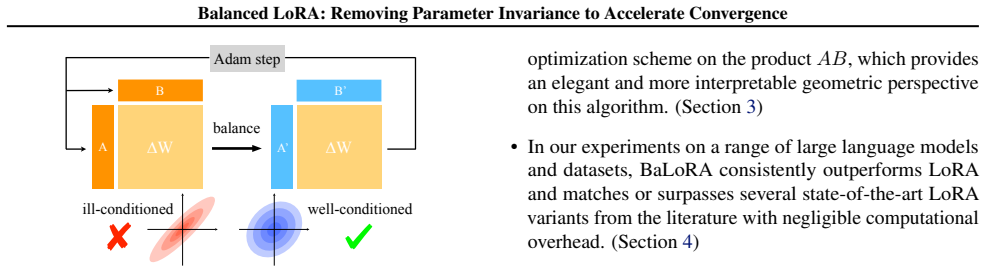
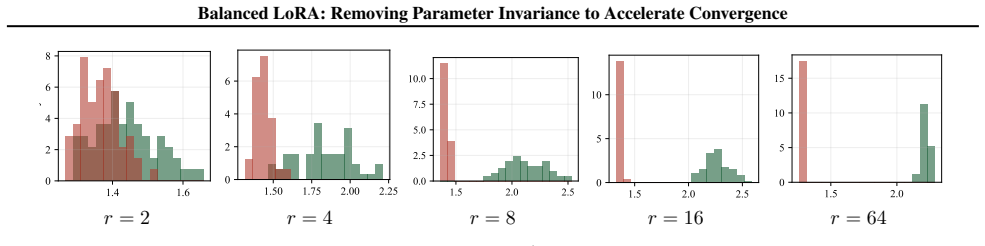
LoRA admits many equivalent low-rank factor pairs for any given adapted matrix; these pairs display significantly different condition numbers, and the choice among them directly governs the convergence rate. BaLoRA projects each iterate onto the balanced manifold that equalizes the factors while preserving their product, thereby improving the conditioning of the loss landscape. The projection is cheap and leaves the set of reachable adapted matrices unchanged, resulting in faster convergence and better task performance.
What carries the argument
The balanced manifold together with the projection step that maps low-rank factor pairs to equivalent pairs with improved conditioning while keeping their outer product fixed.
If this is right
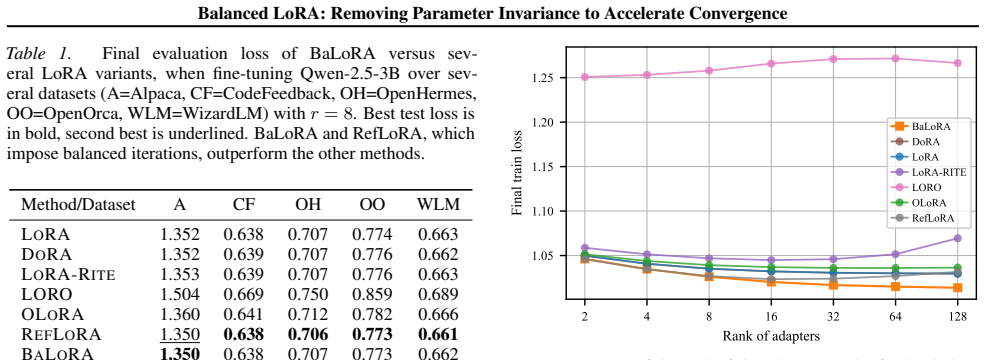
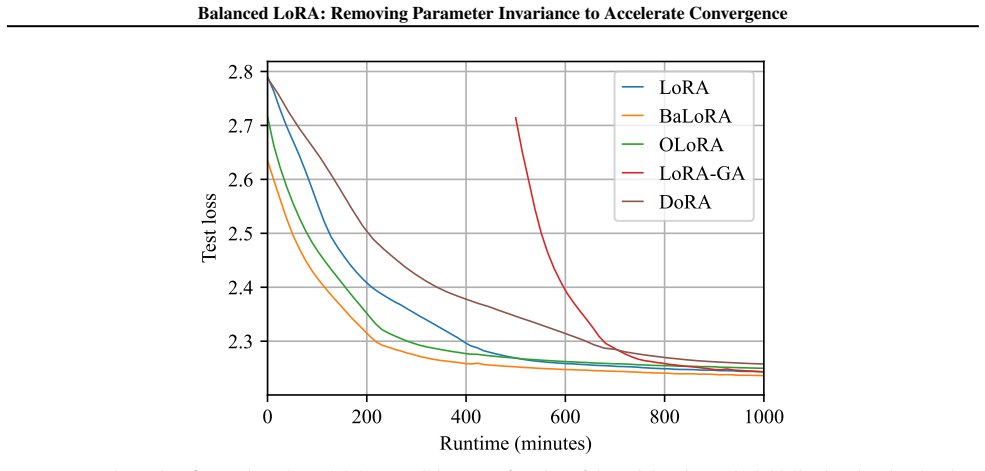
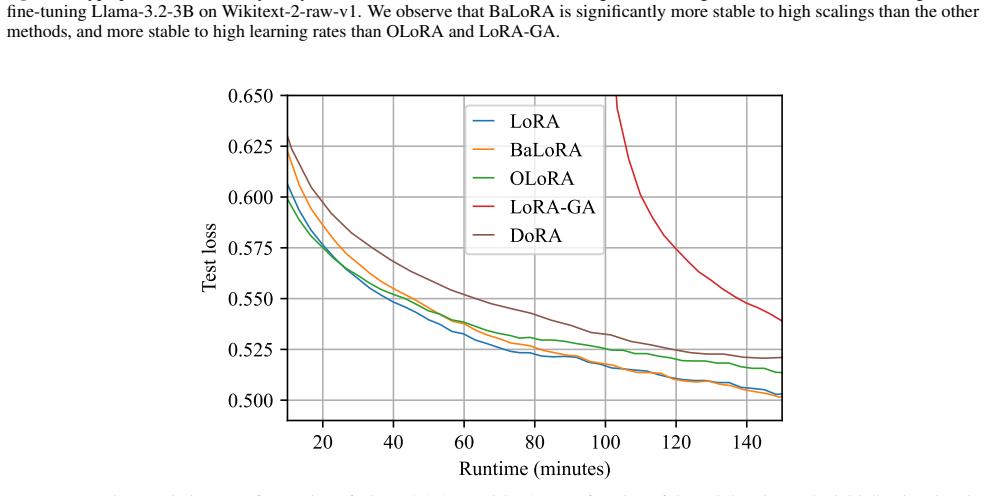
- BaLoRA converges faster than standard LoRA across fine-tuning tasks.
- BaLoRA reaches superior final performance on the same range of tasks.
- The added projection remains computationally lightweight and integrates into existing pipelines without code changes.
- Condition-number variation among equivalent factorizations is the mechanism that alters LoRA convergence rate.
Where Pith is reading between the lines
- The same balancing idea could be applied to other overparameterized low-rank adaptation schemes such as DoRA or VeRA.
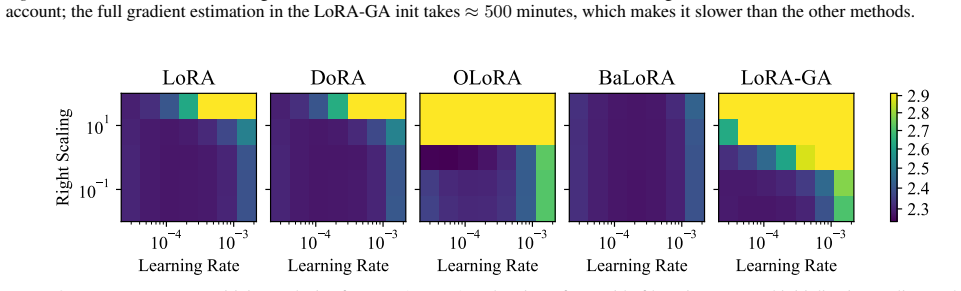
- Maintaining the balanced constraint throughout training might reduce sensitivity to random seed and learning-rate choices.
- If the projection can be fused into the optimizer step, wall-clock savings would become larger on large-scale runs.
Load-bearing premise
Differences in condition number among equivalent low-rank factorizations are the dominant driver of convergence speed differences, and the projection step does not introduce new optimization artifacts or change the effective solution set.
What would settle it
An experiment in which standard LoRA and BaLoRA are run from initializations engineered to share the same condition number and then observed to reach identical convergence curves and final accuracies.
Figures

read the original abstract
Low-Rank Adaptation (LoRA) is the most widely adopted method for fine-tuning large language models. Notably, LoRA is inherently overparameterized: multiple pairs of low-rank factors can yield the same adapted weight matrix. We show--both theoretically and empirically--that these pairs exhibit significantly different condition numbers. As a result, converging to different loss minimizers directly impacts the convergence rate of LoRA. Building on this observation, we introduce Balanced Low-Rank Adaptation (BaLoRA), a variant of LoRA that projects iterates onto a balanced manifold. This manifold improves the conditioning of the loss landscape while preserving the adapted matrix. The projection step is computationally lightweight and integrates seamlessly into existing fine-tuning pipelines. Empirically, BaLoRA converges faster than standard LoRA and achieves superior performance across a range of fine-tuning tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that standard LoRA is overparameterized, with different low-rank factor pairs (A, B) yielding identical adapted matrices but exhibiting substantially different condition numbers; this variation directly affects convergence speed. It introduces Balanced LoRA (BaLoRA), which adds a lightweight projection step onto a balanced manifold that improves conditioning while exactly preserving the product AB. Both a theoretical argument for the conditioning effect and empirical results across fine-tuning tasks are presented to show faster convergence and superior final performance relative to vanilla LoRA.
Significance. If the central claim holds, the work is significant because LoRA is the dominant parameter-efficient fine-tuning method; a simple, matrix-preserving projection that removes an invariance and demonstrably accelerates training would be immediately useful. The explicit identification of the overparameterization source and the claim of an exact-preservation projection are strengths that, if rigorously supported, distinguish the contribution from heuristic reparameterizations.
major comments (2)
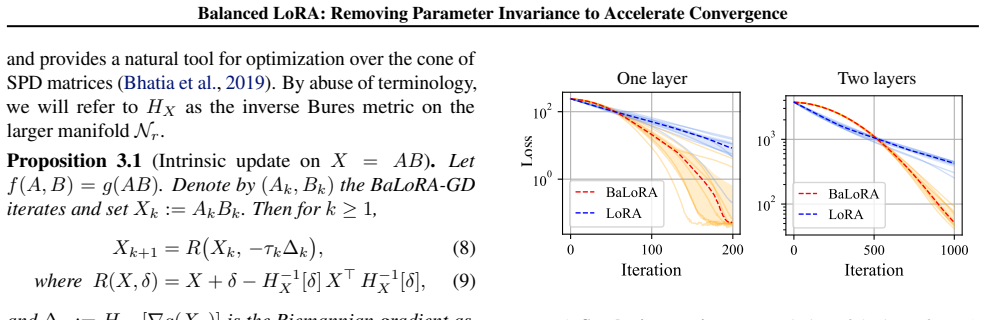
- [§3] §3 (theoretical analysis): the argument that condition-number differences among equivalent factorizations are the dominant driver of observed convergence-rate gaps requires an explicit link (e.g., via a local convergence bound or Lipschitz-constant argument) showing that the projection does not merely rescale the effective step size.
- [§4] §4 (projection operator): the claim that the projection exactly preserves the adapted matrix while strictly improving conditioning must be accompanied by a proof that the reachable solution set remains unchanged; without this, the faster convergence could be an artifact of altered optimization geometry rather than pure conditioning improvement.
minor comments (2)
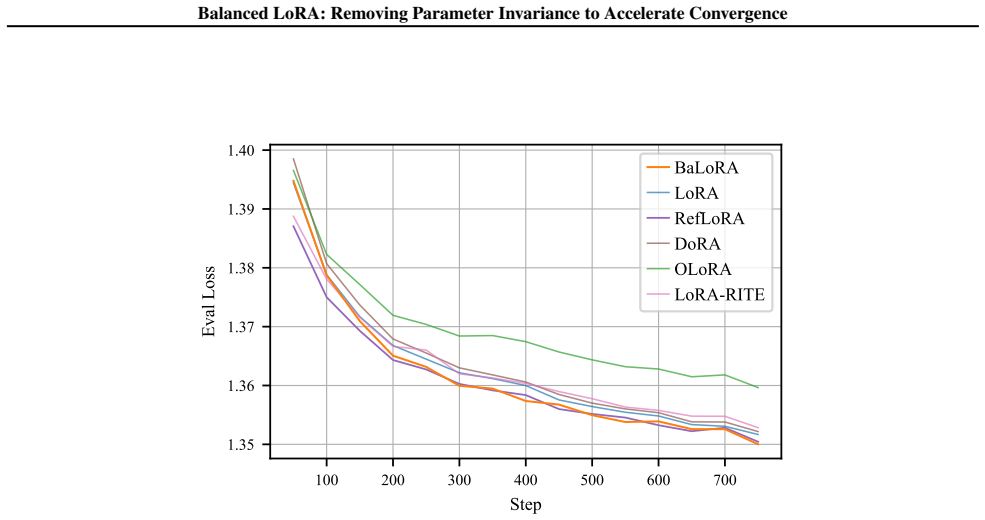
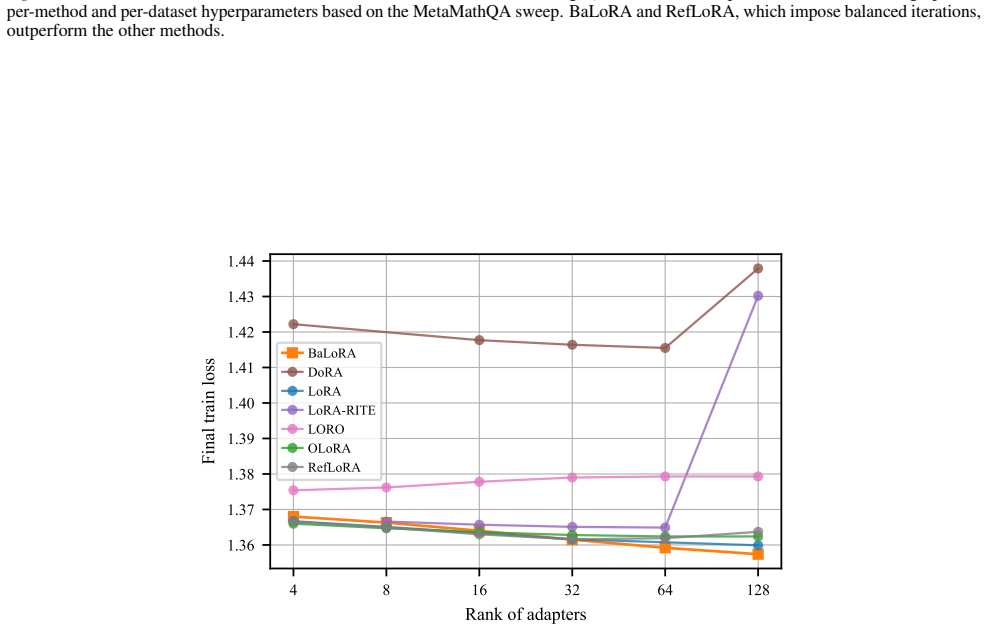
- [Figure 2] Figure 2 and the associated experimental protocol should report wall-clock time in addition to iteration count so that the overhead of the projection step can be assessed directly.
- The notation for the balanced manifold (e.g., the precise constraint ||A||_F = ||B||_F or equivalent) should be stated once in a single displayed equation rather than scattered across text.
Simulated Author's Rebuttal
We thank the referee for the constructive review and the recommendation of minor revision. The comments identify valuable opportunities to strengthen the theoretical justification, and we will incorporate the requested additions in the revised manuscript.
read point-by-point responses
-
Referee: [§3] §3 (theoretical analysis): the argument that condition-number differences among equivalent factorizations are the dominant driver of observed convergence-rate gaps requires an explicit link (e.g., via a local convergence bound or Lipschitz-constant argument) showing that the projection does not merely rescale the effective step size.
Authors: We appreciate the referee's request for a tighter connection between conditioning and convergence rate. Our current analysis shows that equivalent factor pairs produce different condition numbers that correlate with observed convergence differences, but we agree an explicit link is needed. In the revision we will augment §3 with a local convergence argument: we derive that the condition number of the factors upper-bounds the Lipschitz constant of the loss with respect to the low-rank updates, and that the balanced projection reduces this constant while leaving the gradient step in the space of the product AB unchanged. This establishes that the acceleration arises from improved conditioning rather than an implicit rescaling of the effective step size. revision: yes
-
Referee: [§4] §4 (projection operator): the claim that the projection exactly preserves the adapted matrix while strictly improving conditioning must be accompanied by a proof that the reachable solution set remains unchanged; without this, the faster convergence could be an artifact of altered optimization geometry rather than pure conditioning improvement.
Authors: We agree that a formal invariance proof is required to confirm the solution set is preserved. The projection is constructed so that the output factors (A', B') satisfy A'B' = AB for any input pair; consequently the set of attainable adapted weight matrices is identical to that of standard LoRA. In the revised manuscript we will add a concise proof of this exact preservation (placed in the appendix) together with a short argument that the only change to the optimization geometry is the reparameterization of the factors, thereby ruling out alterations to the reachable adapted matrices as the source of the observed gains. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The provided abstract and context describe a theoretical observation on condition numbers of equivalent LoRA factorizations, followed by an algorithmic projection onto a balanced manifold that preserves the adapted matrix exactly. No quoted equation or step reduces a claimed prediction or uniqueness result to a fitted input, self-citation chain, or definitional renaming. The central improvement is presented as an independent change whose validity rests on external empirical benchmarks and the preservation property, which is not tautological with the conditioning claim. This matches the default expectation of a non-circular paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Automatica49(11), 3222–3233 (2013)
URL https://aclanthology.org/2021. acl-long.568/. arXiv.org submitters. arxiv dataset, 2024. URL https: //www.kaggle.com/dsv/7548853. Awais, M., Naseer, M., Khan, S., Anwer, R. M., Cholakkal, H., Shah, M., Yang, M.-H., and Khan, F. S. Foundation models defining a new era in vision: a survey and outlook. IEEE Transactions on Pattern Analysis and Machine In...
work page doi:10.1016/j 2021
-
[2]
PMLR, 2019. Hu, E. J., Shen, Y ., Wallis, P., Allen-Zhu, Z., Li, Y ., Wang, S., Wang, L., Chen, W., et al. Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022. Jang, U., Lee, J. D., and Ryu, E. K. LoRA training in the NTK regime has no spurious local minima. InForty- first International Conference on Machine Learning,
2019
-
[3]
A Rank Stabilization Scaling Factor for Fine-Tuning with LoRA
URL https://openreview.net/forum? id=s1sdx6vNsU. Kalajdzievski, D. A rank stabilization scaling factor for fine-tuning with lora.arXiv preprint arXiv:2312.03732, 2023. Kingma, D. P. and Ba, J. Adam: A method for stochastic op- timization, 2017. URL https://arxiv.org/abs/ 1412.6980. Kopiczko, D. J., Blankevoort, T., and Asano, Y . M. Vera: Vector-based ran...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Li, J., Li, D., Xiong, C., and Hoi, S
URL https://openreview.net/forum? id=ryup8-WCW. Li, J., Li, D., Xiong, C., and Hoi, S. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. InInternational confer- ence on machine learning, pp. 12888–12900. PMLR, 2022. Li, S., Luo, X., Tang, X., Wang, H., Chen, H., Luo, W., Li, Y ., He, X., and Li, R. B...
-
[5]
URL https://openreview.net/forum? id=hphdX8WlcT. Ye, T. and Du, S. S. Global convergence of gradient de- scent for asymmetric low-rank matrix factorization.Ad- vances in Neural Information Processing Systems, 34: 1429–1439, 2021. Yen, J.-N., Si, S., Meng, Z., Yu, F., Duvvuri, S. S., Dhillon, I. S., Hsieh, C.-J., and Kumar, S. Lora done rite: Robust invari...
-
[6]
URL https://openreview.net/forum? id=LzLeAscHnj. Zeng, Y . and Lee, K. The expressive power of low- rank adaptation. InThe Twelfth International Confer- ence on Learning Representations, 2024. URL https: //openreview.net/forum?id=likXVjmh3E. Zhang, F. and Pilanci, M. Riemannian preconditioned loRA for fine-tuning foundation models. InForty- first Internat...
2024
-
[7]
URL https://openreview.net/forum? id=IwqE4QqBew. Zhang, T. and Fan, X. Projected gradient descent algo- rithm for low-rank matrix estimation.arXiv preprint arXiv:2403.02704, 2024. Zhang, Y ., Li, B., and Giannakis, G. B. Reflora: Refactored low-rank adaptation for efficient fine-tuning of large mod- els.arXiv preprint arXiv:2505.18877, 2025. Zheng, T., Zh...
-
[8]
Consider the scale-invariant ratio ϕ(z) :=∥Hz∥ 2 1/⟨Hz, z⟩ on ker(H)⊥ \ {0}
as t→+∞ . Consider the scale-invariant ratio ϕ(z) :=∥Hz∥ 2 1/⟨Hz, z⟩ on ker(H)⊥ \ {0}. Since ϕ is continuous on the Euclidean unit sphere of ker(H)⊥ and this sphere is compact, its minimum is exactlyµ ∞. Therefore, ifδ t,⊥ ̸= 0, ∥∇f(θ t)∥2 1 2(f(θ t)−f(θ ⋆)) =ϕ(δ t,⊥) +o(1)≥µ ∞ −ε for all t large enough, while if δt,⊥ = 0 then θt already lies on the local...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.