The sketched landing method for large-scale optimization under orthogonality constraints
Pith reviewed 2026-06-28 21:25 UTC · model grok-4.3
The pith
Random sketch matrices lower the cost of each landing step in orthogonality-constrained optimization while preserving expected convergence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The sketched landing method computes approximate normal and tangent directions via random sketch matrices of reduced dimension. Both Gaussian and subsampling sketches yield expected descent in a merit function that combines objective value and constraint violation, so that the iterates converge in expectation to a stationary point of the constrained problem under standard step-size rules.
What carries the argument
Low-dimensional random sketch matrices that approximate the normal and tangent directions within each landing step.
If this is right
- Per-iteration cost scales with sketch dimension instead of full matrix size.
- Convergence holds in expectation for both Gaussian and subsampling sketches.
- The approach extends directly to large-scale orthogonality-constrained problems.
- Variance from randomization can be reduced by increasing sketch size while keeping cost savings.
Where Pith is reading between the lines
- Sketching the landing directions could transfer to other first-order methods on the orthogonal group.
- Practical speedups would appear in experiments on matrices with thousands of columns.
- Hardware characteristics may favor sparse sketches over dense ones for certain problem sizes.
Load-bearing premise
The random sketch matrices preserve enough of the geometric properties of the normal and tangent spaces for the expected decrease in the merit function to remain sufficient.
What would settle it
Running the sketched method on a known orthogonality-constrained test problem with fixed sketch dimension and observing that the sequence fails to approach a stationary point in expectation over repeated independent trials.
Figures

read the original abstract
We propose the \emph{sketched landing method}, a randomized variant of the landing method for optimization under orthogonality constraints. Each landing step consists of the sum of a \emph{normal} component, which reduces infeasibility, and a \emph{tangent} component, which decreases the objective function. Our main contribution is the introduction of low-dimensional random \emph{sketch matrices} to reduce the computational cost of these directions. We consider both dense (Gaussian) and sparse (subsampling) sketch matrices, and show how they reduce the per-iteration cost while preserving convergence guarantees in expectation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the sketched landing method, a randomized variant of the landing method for optimization under orthogonality constraints. Each iteration computes a landing step as the sum of a normal component (reducing infeasibility measured by ||X^T X - I||) and a tangent component (decreasing the objective); the main contribution is the use of low-dimensional random sketch matrices (dense Gaussian or sparse subsampling) to approximate these directions, lowering per-iteration cost while preserving convergence guarantees in expectation.
Significance. If the expectation analysis holds and the sketched directions can be shown to control variance sufficiently for practical use, the work would offer a useful complexity reduction for large-scale Stiefel-manifold problems. Credit is due for explicitly treating both Gaussian and subsampling sketches and for grounding the contribution in an existing landing-method framework rather than starting from scratch.
major comments (1)
- [Abstract and §4 (Convergence Analysis)] Abstract and §4 (Convergence Analysis): the claim that sketched normal directions preserve convergence 'in expectation' is load-bearing for the central contribution, yet the analysis only establishes E[decrease in infeasibility] > 0 without concentration inequalities or variance bounds on the sketched normal step. This leaves open the possibility that individual realizations increase ||X^T X - I|| by an arbitrary amount (especially for small sketch dimension k), undermining the deterministic descent property that the original landing method uses to stay near the manifold.
minor comments (2)
- [§2 (Background)] §2 (Background): the notation distinguishing the full landing direction from its sketched approximation could be introduced earlier and used consistently in the algorithm box.
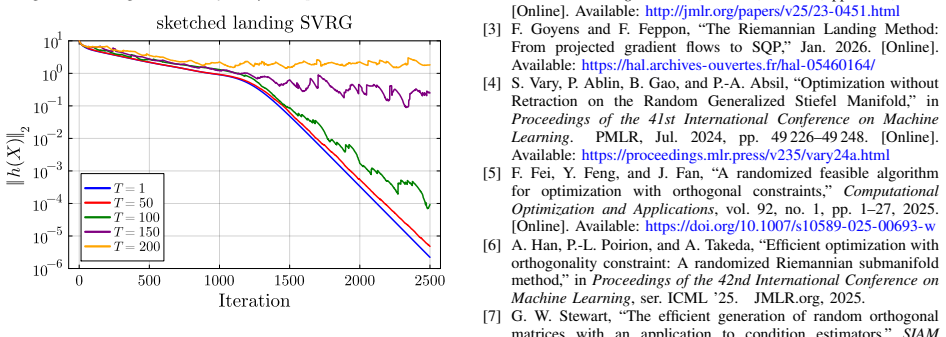
- [Figure 1] Figure 1: the caption should explicitly state the sketch dimension k relative to the matrix dimensions n and p so that the cost reduction is immediately quantifiable.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for identifying this key aspect of the convergence analysis. We respond to the major comment below.
read point-by-point responses
-
Referee: [Abstract and §4 (Convergence Analysis)] Abstract and §4 (Convergence Analysis): the claim that sketched normal directions preserve convergence 'in expectation' is load-bearing for the central contribution, yet the analysis only establishes E[decrease in infeasibility] > 0 without concentration inequalities or variance bounds on the sketched normal step. This leaves open the possibility that individual realizations increase ||X^T X - I|| by an arbitrary amount (especially for small sketch dimension k), undermining the deterministic descent property that the original landing method uses to stay near the manifold.
Authors: We agree that the analysis in §4 shows only that the expected change in infeasibility is strictly negative and does not supply concentration inequalities or variance bounds on the sketched normal direction. Consequently, unlike the deterministic landing method, a single realization of the sketched step may increase ||X^T X - I||. This is an inherent feature of the randomization we introduce. The manuscript's stated contribution is a method whose convergence guarantees hold in expectation; the analysis establishes precisely this property. We do not claim that the sketched iterates remain deterministically close to the manifold for finite k. The expectation result is sufficient to guarantee that the sequence of expected objective values converges and that the expected infeasibility tends to zero, which is the claim made in the abstract and §4. Stronger high-probability bounds would require additional technical work that lies outside the present scope. revision: no
Circularity Check
No significant circularity; sketching layer is independent of the landing method's core properties
full rationale
The paper introduces random sketch matrices (Gaussian or subsampling) as a computational reduction on top of the existing landing method, which decomposes steps into normal and tangent components. Convergence in expectation is shown by verifying that the sketched directions preserve the expected decrease properties of the original method, without any self-definitional re-use of the target result, fitted parameters renamed as predictions, or load-bearing self-citations that close the derivation loop. The analysis treats the sketch matrices as external random objects whose expectation properties are derived from standard concentration or linearity arguments, keeping the central claim self-contained against the prior landing method.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Absil, R
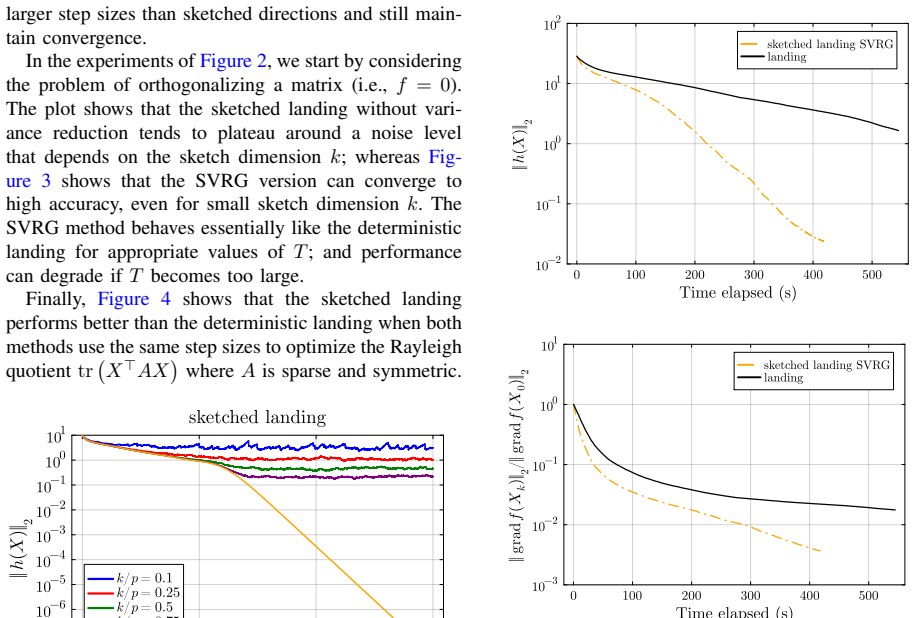
P.-A. Absil, R. Mahony, and R. Sepulchre,Optimization Algo- rithms on Matrix Manifolds. Princeton University Press, Dec. 2008. Figure 4. Rayleigh quotient: sketched landing SVRG vs landing with α= 10 −3,n= 1000,p= 900,k= 50, andT= 20
2008
-
[2]
Infeasible Deterministic, Stochastic, and Variance-Reduction Algorithms for Optimization under Orthogonality Constraints,
P. Ablin, S. Vary, B. Gao, and P.-A. Absil, “Infeasible Deterministic, Stochastic, and Variance-Reduction Algorithms for Optimization under Orthogonality Constraints,”Journal of Machine Learning Research, vol. 25, no. 389, pp. 1–38, 2024. [Online]. Available: http://jmlr.org/papers/v25/23-0451.html
2024
-
[3]
The Riemannian Landing Method: From projected gradient flows to SQP,
F. Goyens and F. Feppon, “The Riemannian Landing Method: From projected gradient flows to SQP,” Jan. 2026. [Online]. Available: https://hal.archives-ouvertes.fr/hal-05460164/
2026
-
[4]
Optimization without Retraction on the Random Generalized Stiefel Manifold,
S. Vary, P. Ablin, B. Gao, and P.-A. Absil, “Optimization without Retraction on the Random Generalized Stiefel Manifold,” in Proceedings of the 41st International Conference on Machine Learning. PMLR, Jul. 2024, pp. 49 226–49 248. [Online]. Available: https://proceedings.mlr.press/v235/vary24a.html
2024
-
[5]
A randomized feasible algorithm for optimization with orthogonal constraints,
F. Fei, Y . Feng, and J. Fan, “A randomized feasible algorithm for optimization with orthogonal constraints,”Computational Optimization and Applications, vol. 92, no. 1, pp. 1–27, 2025. [Online]. Available: https://doi.org/10.1007/s10589-025-00693-w
-
[6]
Efficient optimization with orthogonality constraint: A randomized Riemannian submanifold method,
A. Han, P.-L. Poirion, and A. Takeda, “Efficient optimization with orthogonality constraint: A randomized Riemannian submanifold method,” inProceedings of the 42nd International Conference on Machine Learning, ser. ICML ’25. JMLR.org, 2025
2025
-
[7]
The efficient generation of random orthogonal matrices with an application to condition estimators,
G. W. Stewart, “The efficient generation of random orthogonal matrices with an application to condition estimators,”SIAM Journal on Numerical Analysis, vol. 17, no. 3, pp. 403–409,
-
[8]
Available: https://doi.org/10.1137/0717034
[Online]. Available: https://doi.org/10.1137/0717034
-
[9]
F. Goyens, A. Eftekhari, and N. Boumal, “Computing Second- Order Points Under Equality Constraints: Revisiting Fletcher’s Augmented Lagrangian,”Journal of Optimization Theory and Applications, vol. 201, no. 3, pp. 1198–1228, Jun. 2024. [Online]. Available: https://doi.org/10.1007/s10957-024-02421-6 6 APPENDIX 7
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.