Personalize Your Large Vision-language Models With In-context Prompt Tuning
Pith reviewed 2026-06-28 22:58 UTC · model grok-4.3
The pith
ICPT personalizes large vision-language models using a lightweight projection module and geometric regularizations without inference-time training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
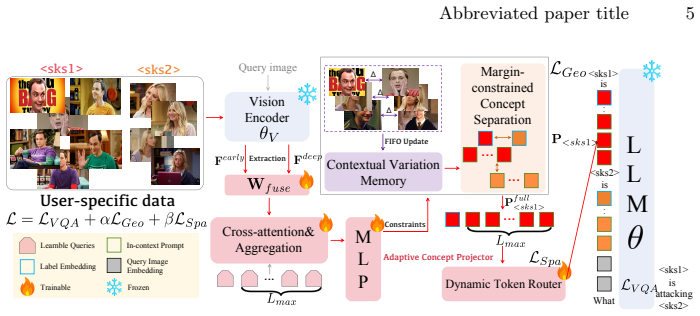
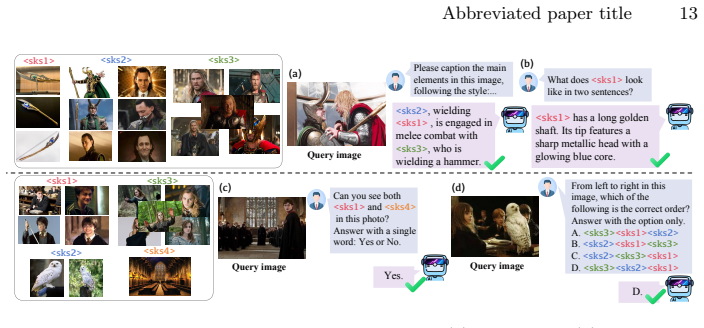
The central discovery is that a lightweight projection module combined with two novel geometric regularizations enables in-context prompt tuning that decouples key identities from transient environmental states and separates concepts to avoid semantic confusion, achieving state-of-the-art personalization accuracy in complex multi-image, multi-concept scenarios across diverse LVLM backbones.
What carries the argument
The lightweight projection module that adaptively determines prompt length based on visual complexity, together with geometric regularizations that refine prompt representations by decoupling identities and separating concepts.
If this is right
- LVLMs can learn out-of-distribution concepts quickly from multiple reference images without retraining at inference time.
- Personalization accuracy improves in settings with environmental changes and multiple concepts.
- The method works across various LVLM architectures.
- Computational efficiency increases by adapting prompt length to each concept's complexity.
Where Pith is reading between the lines
- If the regularizations hold, similar geometric constraints could be applied to other multimodal tasks like video understanding.
- The adaptive prompt length might generalize to text-only personalization in language models.
- Deployment in user-facing applications could reduce the need for model fine-tuning servers.
Load-bearing premise
The two geometric regularizations can reliably separate key identities from transient environmental biases and prevent cross-concept interference in real-world multi-image inputs.
What would settle it
A test set of multi-image inputs where environmental backgrounds vary significantly while identities stay the same, showing that the method's accuracy drops below baseline methods due to failure in decoupling.
Figures
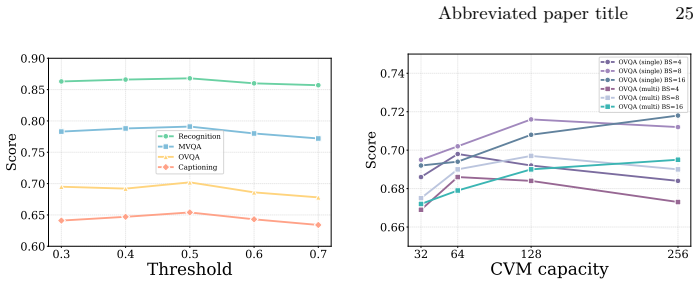
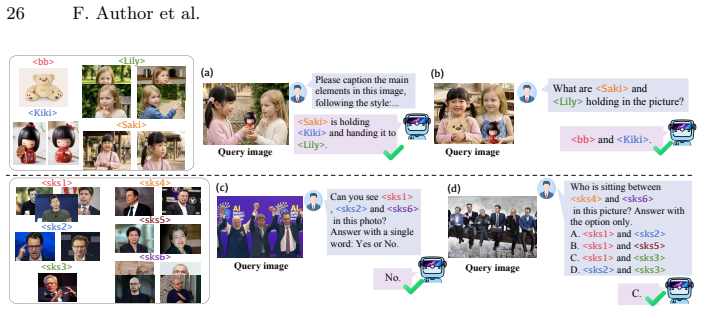
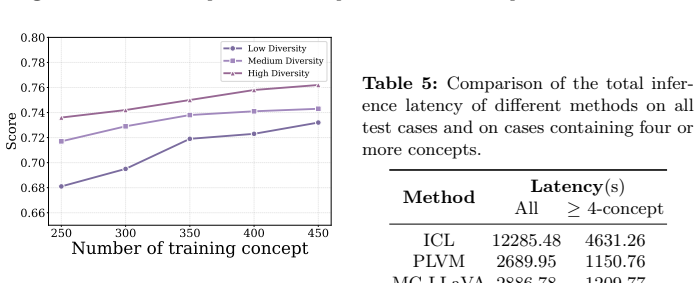
read the original abstract
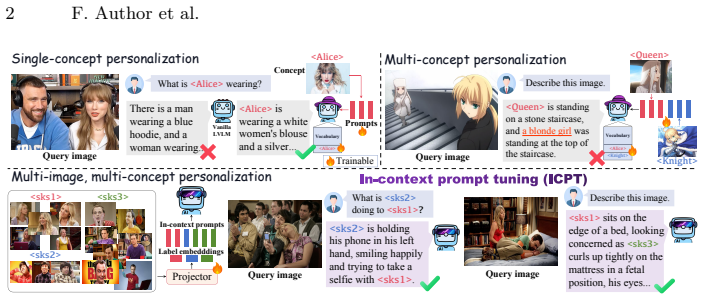
Large vision-language models (LVLMs) have demonstrated strong general multimodal capability and are increasingly deployed in downstream systems. This trend has driven growing interest in LVLM personalization, which aims to enable models to quickly and effectively learn out-of-distribution multimodal concepts to meet user-specific needs. However, many existing methods rely on inference-time training, which reduces efficiency. They also struggle to maintain accuracy in complex multi-image, multi-concept settings. These limitations restrict the broader deployment of LVLM-based systems. Therefore, this paper proposes in-context prompt tuning (ICPT). Specifically, ICPT employs a lightweight projection module capable of operating in complex scenarios to extract fine-grained visual semantics from multiple reference images, seamlessly transforming these features alongside identity-label mappings into continuous prompts. To maximize computational efficiency, this module adaptively determines the prompt length based on the intrinsic visual complexity of each concept. Crucially, to overcome the environmental biases and cross-concept interference prevalent in real-world applications, we introduce two novel geometric regularizations. These constraints refine prompt representations by decoupling key identities from transient environmental states and separating concepts to avoid semantic confusion. Extensive experiments show that ICPT achieves state-of-the-art personalization accuracy across diverse tasks and LVLM backbones.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes In-Context Prompt Tuning (ICPT) for LVLM personalization. It introduces a lightweight projection module that extracts fine-grained visual semantics from multiple reference images, maps them to continuous prompts with adaptive length based on visual complexity, and adds two novel geometric regularizations to decouple key identities from environmental states and separate concepts. The method is positioned as avoiding inference-time training while achieving SOTA personalization accuracy across tasks and backbones in complex multi-image, multi-concept settings.
Significance. If the experimental claims hold and the regularizations demonstrably enforce the claimed separations, the approach could offer an efficient alternative to training-based personalization methods for LVLMs. The adaptive prompt length and geometric constraints address real deployment issues like environmental bias and concept interference, but the current presentation provides no basis to evaluate whether these components deliver the asserted gains.
major comments (3)
- [Abstract] Abstract: The central claim of 'state-of-the-art personalization accuracy across diverse tasks and LVLM backbones' is asserted without any reference to experimental protocol, datasets, baselines, metrics, number of runs, or error bars. This renders the primary empirical contribution unsupported by evidence in the manuscript.
- [Method] Method section: The two novel geometric regularizations are described as 'refining prompt representations by decoupling key identities from transient environmental states and separating concepts,' yet no explicit loss terms, equations, or constraints (e.g., orthogonality penalties, inner-product terms, or embedding-space formulations) are supplied. Without these definitions it is impossible to verify that the regularizations avoid trivial solutions or leakage between identity and background features.
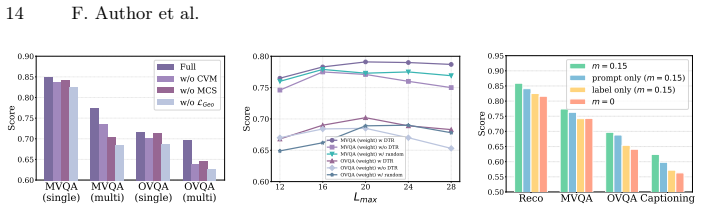
- [Experiments] Experiments section: No ablation results are referenced that isolate the contribution of the two geometric regularizations versus the projection module alone. If removing the regularizations yields negligible change in accuracy, the SOTA claim cannot be attributed to the claimed decoupling mechanism.
minor comments (1)
- [Abstract] The abstract mentions 'extensive experiments' but provides zero concrete details on evaluation settings; this should be expanded even in the abstract for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and commit to revisions that strengthen the empirical support and technical clarity of the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of 'state-of-the-art personalization accuracy across diverse tasks and LVLM backbones' is asserted without any reference to experimental protocol, datasets, baselines, metrics, number of runs, or error bars. This renders the primary empirical contribution unsupported by evidence in the manuscript.
Authors: We agree that the abstract would be strengthened by additional context on the supporting experiments. In the revision we will update the abstract to briefly reference the evaluation protocol, key datasets, baselines, metrics, and the use of multiple runs with error bars, while preserving its concise nature. revision: yes
-
Referee: [Method] Method section: The two novel geometric regularizations are described as 'refining prompt representations by decoupling key identities from transient environmental states and separating concepts,' yet no explicit loss terms, equations, or constraints (e.g., orthogonality penalties, inner-product terms, or embedding-space formulations) are supplied. Without these definitions it is impossible to verify that the regularizations avoid trivial solutions or leakage between identity and background features.
Authors: The referee correctly notes that the current manuscript presents the regularizations at a descriptive level without explicit formulations. We will add the precise loss equations (including orthogonality and separation terms in embedding space) together with a short analysis showing how the constraints avoid trivial solutions and limit identity-background leakage. revision: yes
-
Referee: [Experiments] Experiments section: No ablation results are referenced that isolate the contribution of the two geometric regularizations versus the projection module alone. If removing the regularizations yields negligible change in accuracy, the SOTA claim cannot be attributed to the claimed decoupling mechanism.
Authors: We acknowledge the absence of dedicated ablations isolating the regularizations. In the revised version we will include new ablation experiments that remove each regularization in turn, report the resulting accuracy changes relative to the projection module alone, and discuss the quantitative contribution of the decoupling mechanism. revision: yes
Circularity Check
No circularity detected; method proposal is self-contained
full rationale
The paper introduces ICPT as a new technique consisting of a lightweight projection module with adaptive prompt length and two novel geometric regularizations for decoupling identities and concepts. No equations, derivations, or predictions appear that reduce outputs to inputs by construction, nor are there load-bearing self-citations, uniqueness theorems imported from prior author work, or ansatzes smuggled via citation. The abstract and described approach frame the regularizations as original contributions rather than fitted parameters or renamed known results, making the central claims independent of any circular reduction.
Axiom & Free-Parameter Ledger
invented entities (2)
-
lightweight projection module
no independent evidence
-
two novel geometric regularizations
no independent evidence
Reference graph
Works this paper leans on
-
[1]
In: European Conference on Computer Vision
Alaluf, Y., Richardson, E., Tulyakov, S., Aberman, K., Cohen-Or, D.: Myvlm: Personalizing vlms for user-specific queries. In: European Conference on Computer Vision. pp. 73–91. Springer (2024) 2, 4, 11, 17, 20
2024
-
[2]
arXiv preprint arXiv:2411.11706 (2024) 4, 11, 8
An, R., Yang, S., Lu, M., Zhang, R., Zeng, K., Luo, Y., Cao, J., Liang, H., Chen, Y., She, Q., et al.: Mc-llava: Multi-concept personalized vision-language model. arXiv preprint arXiv:2411.11706 (2024) 2, 4, 11, 17, 20, 21
-
[3]
arXiv preprint arXiv:2505.14671 (2025) 4
An, R., Yang, S., Zhang, R., Shen, Z., Lu, M., Dai, G., Liang, H., Guo, Z., Yan, S., Luo, Y., et al.: Unictokens: Boosting personalized understanding and generation via unified concept tokens. arXiv preprint arXiv:2505.14671 (2025) 4
-
[4]
In: Synthetic Data for Computer Vision Workshop@ CVPR 2025 (2025) 4
An, R., Zeng, K., Lu, M., Yang, S., Zhang, R., Ji, H., Zhang, Q., Luo, Y., Liang, H., Zhang, W.: Concept-as-tree: Synthetic data is all you need for vlm personalization. In: Synthetic Data for Computer Vision Workshop@ CVPR 2025 (2025) 4
2025
-
[5]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., Ge, W., Guo, Z., Huang, Q., Huang, J., Huang, F., Hui, B., Jiang, S., Li, Z., Li, M., Li, M., Li, K., Lin, Z., Lin, J., Liu, X., Liu, J., Liu, C., Liu, Y., Liu, D., Liu, S., Lu, D., Luo, R., Lv, C., Men, R., Meng, L., Ren, X., Ren, X., Song, S., Sun, Y., Tang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
arXiv preprint arXiv:2306.08640 (2023) 4
Gao, D., Ji, L., Zhou, L., Lin, K.Q., Chen, J., Fan, Z., Shou, M.Z.: Assistgpt: A general multi-modal assistant that can plan, execute, inspect, and learn. arXiv preprint arXiv:2306.08640 (2023) 4
-
[7]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Hao, H., Han, J., Li, C., Li, Y.F., Yue, X.: Rap: Retrieval-augmented personal- ization for multimodal large language models. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 14538–14548 (2025) 4, 11, 21 16 F. Author et al
2025
-
[8]
He, P., Gao, J., Chen, W.: Debertav3: Improving deberta using electra- style pre-training with gradient-disentangled embedding sharing. arXiv preprint arXiv:2111.09543 (2021) 12
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[9]
arXiv preprint arXiv:2509.22820 (2025) 4, 10, 19
Kim, J., Kim, W., Park, W., Do, J.: Mmpb: It’s time for multi-modal personaliza- tion. arXiv preprint arXiv:2509.22820 (2025) 4, 10, 19
-
[10]
arXiv preprint arXiv:2509.21730 (2025) 4
Kim, J., Choi, J., Chay, W., Kyung, D., Kwon, Y., Jo, Y., Choi, E.: Propersim: De- veloping proactive and personalized ai assistants through user-assistant simulation. arXiv preprint arXiv:2509.21730 (2025) 4
-
[11]
International Journal of Human–Computer Interaction pp
Li, F., Han, S., Lee, C.H., Feng, S., Jiang, Z., Sun, Z.: A new era in human factors engineering:Asurveyoftheapplicationsandprospectsoflargemultimodalmodels. International Journal of Human–Computer Interaction pp. 1–14 (2025) 1
2025
-
[12]
In: Second Conference on Language Modeling (2025), https://openreview.net/forum?id=9ffYcEiNw92
Li, Y., Cao, Y., He, H., Cheng, Q., Fu, X., Xiao, X., Wang, T., Tang, R.: M²IV: Towards efficient and fine-grained multimodal in-context learning via rep- resentation engineering. In: Second Conference on Language Modeling (2025), https://openreview.net/forum?id=9ffYcEiNw92
2025
-
[13]
In: Pro- ceedings of the AAAI Conference on Artificial Intelligence
Li, Y., Yang, J., Shen, Z., Han, L., Xu, H., Tang, R.: Catp: Contextually adaptive token pruning for efficient and enhanced multimodal in-context learning. In: Pro- ceedings of the AAAI Conference on Artificial Intelligence. vol. 40, pp. 6619–6627 (2026) 2
2026
-
[14]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Li, Y., Yang, J., Yang, Z., Li, B., Han, L., He, H., Yao, Z., Chen, Y.V., Fei, S., Liu, D., et al.: Make lvlms focus: Context-aware attention modulation for better mul- timodal in-context learning. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 40, pp. 6610–6618 (2026) 2
2026
-
[15]
In: European conference on computer vision
Lin, T.Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L.: Microsoft coco: Common objects in context. In: European conference on computer vision. pp. 740–755. Springer (2014) 10
2014
-
[16]
Liu, H., Li, C., Li, Y., Li, B., Zhang, Y., Shen, S., Lee, Y.J.: Llava-next: Improved reasoning, ocr, and world knowledge (January 2024) 11
2024
-
[17]
Advances in neural information processing systems36, 34892–34916 (2023) 4
Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual instruction tuning. Advances in neural information processing systems36, 34892–34916 (2023) 4
2023
-
[18]
In: Findings of the Association for Computational Linguistics: NAACL 2024
Lyu, H., Jiang, S., Zeng, H., Xia, Y., Wang, Q., Zhang, S., Chen, R., Leung, C., Tang, J., Luo, J.: Llm-rec: Personalized recommendation via prompting large language models. In: Findings of the Association for Computational Linguistics: NAACL 2024. pp. 583–612 (2024) 2
2024
-
[19]
Ad- vances in Neural Information Processing Systems37, 23464–23487 (2024) 6
Meng, L., Yang, J., Tian, R., Dai, X., Wu, Z., Gao, J., Jiang, Y.G.: Deepstack: Deeply stacking visual tokens is surprisingly simple and effective for lmms. Ad- vances in Neural Information Processing Systems37, 23464–23487 (2024) 6
2024
-
[20]
Advances in Neural Information Processing Systems 37, 40913–40951 (2024) 2, 4, 11, 17, 20
Nguyen,T.,Liu,H.,Li,Y.,Cai,M.,Ojha,U.,Lee,Y.J.:Yo’llava:Yourpersonalized language and vision assistant. Advances in Neural Information Processing Systems 37, 40913–40951 (2024) 2, 4, 11, 17, 20
2024
-
[21]
DINOv2: Learning Robust Visual Features without Supervision
Oquab, M., Darcet, T., Moutakanni, T., Vo, H., Szafraniec, M., Khalidov, V., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., et al.: Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193 (2023) 22
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
In: Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems
Park, S., Song, Y., Lee, S., Kim, J., Seo, J.: Leveraging multimodal llm for inspira- tional user interface search. In: Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems. pp. 1–22 (2025) 4
2025
-
[23]
arXiv preprint arXiv:2412.17610 (2024) 4
Pham, C., Phan, H., Doermann, D., Tian, Y.: Personalized large vision-language models. arXiv preprint arXiv:2412.17610 (2024) 2, 4, 11, 21
-
[24]
arXiv preprint arXiv:2410.07113 (2024) 2, 4, 11, 21 Abbreviated paper title 17
Pi, R., Zhang, J., Han, T., Zhang, J., Pan, R., Zhang, T.: Personalized visual instruction tuning. arXiv preprint arXiv:2410.07113 (2024) 2, 4, 11, 21 Abbreviated paper title 17
-
[25]
In: International conference on machine learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PmLR (2021) 3
2021
-
[26]
Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks
Ren, T., Liu, S., Zeng, A., Lin, J., Li, K., Cao, H., Chen, J., Huang, X., Chen, Y., Yan, F., et al.: Grounded sam: Assembling open-world models for diverse visual tasks. arXiv preprint arXiv:2401.14159 (2024) 22
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
In: Proceedings of the 62nd Annual Meeting of the AssociationforComputationalLinguistics(Volume1:LongPapers).pp.7370–7392 (2024) 4
Salemi, A., Mysore, S., Bendersky, M., Zamani, H.: Lamp: When large language models meet personalization. In: Proceedings of the 62nd Annual Meeting of the AssociationforComputationalLinguistics(Volume1:LongPapers).pp.7370–7392 (2024) 4
2024
-
[28]
Personalization Toolkit: Training Free Personalization of Large Vision Language Models
Seifi, S., Dorovatas, V., Reino, D.O., Aljundi, R.: Personalization toolkit: Training free personalization of large vision language models. arXiv preprint arXiv:2502.02452 (2025) 11, 21
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Siméoni, O., Vo, H.V., Seitzer, M., Baldassarre, F., Oquab, M., Jose, C., Khali- dov, V., Szafraniec, M., Yi, S., Ramamonjisoa, M., et al.: Dinov3. arXiv preprint arXiv:2508.10104 (2025) 22
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
ScienceBoard: Evaluating Multimodal Autonomous Agents in Realistic Scientific Workflows
Sun, Q., Liu, Z., Ma, C., Ding, Z., Xu, F., Yin, Z., Zhao, H., Wu, Z., Cheng, K., Liu, Z., et al.: Scienceboard: Evaluating multimodal autonomous agents in realistic scientific workflows. arXiv preprint arXiv:2505.19897 (2025) 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Wang, W., Gao, Z., Gu, L., Pu, H., Cui, L., Wei, X., Liu, Z., Jing, L., Ye, S., Shao, J., et al.: Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency. arXiv preprint arXiv:2508.18265 (2025) 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
arXiv preprint arXiv:2510.22765 (2025) 4
Xu, B., Feng, J., Lu, S., Luo, Y., Yan, S., Liang, H., Lu, M., Zhang, W.: Jarvis: Towards personalized ai assistant via personal kv-cache retrieval. arXiv preprint arXiv:2510.22765 (2025) 4
-
[33]
National Science Review11(12), nwae403 (2024) 3
Yin, S., Fu, C., Zhao, S., Li, K., Sun, X., Xu, T., Chen, E.: A survey on multimodal large language models. National Science Review11(12), nwae403 (2024) 3
2024
- [34]
-
[35]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Zhu, J., Wang, W., Chen, Z., Liu, Z., Ye, S., Gu, L., Tian, H., Duan, Y., Su, W., Shao, J., et al.: Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models. arXiv preprint arXiv:2504.10479 (2025) 11 A Personalization Data A.1 Training data When constructing the multi-image, multi-concept personalization dataset, we f...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.