What Am I Missing? Question-Answering as Hidden State Probing
Pith reviewed 2026-06-28 22:15 UTC · model grok-4.3
The pith
Probes on a model's hidden states before and after question generation can predict the correctness of its final reasoning answer.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
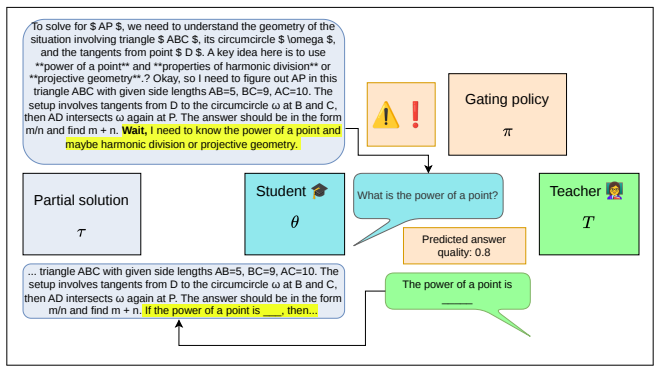
In the student-teacher framework, a probe applied to the student's hidden states immediately before and after it poses a question predicts the final correctness of the answer trajectory. This holds before the teacher provides any response, implying that the signal arises from the student's own process of articulating what it does not know rather than from transferred information.
What carries the argument
A binary classifier probe trained on concatenated hidden states from before and after question generation in the student model.
If this is right
- The probe indicates meaningful self-diagnosis occurs during question formulation.
- Question-asking can be treated as a decision process guided by the probe's output as a quality score.
- A gating policy based on the probe selects questions to improve correctness likelihood.
- Intervention success relies heavily on the underlying model's self-consistency.
- Diagnosis of incorrect trajectories succeeds more readily than their recovery through question interventions.
Where Pith is reading between the lines
- If this probing approach generalizes, models could monitor their own reasoning quality internally without external teachers.
- The observed gap between detection and recovery suggests limits in how language models can use internal signals to self-correct.
- Extending the method to other intervention types like self-critique might test whether the issue is specific to question-asking.
Load-bearing premise
The probe's predictive signal specifically reflects self-diagnosis during question generation rather than properties of the student-teacher training setup.
What would settle it
If retraining the probe on hidden states from question generation in a different model architecture or without the reasoning task context eliminates its predictive power for final correctness, the claim would be falsified.
Figures
read the original abstract
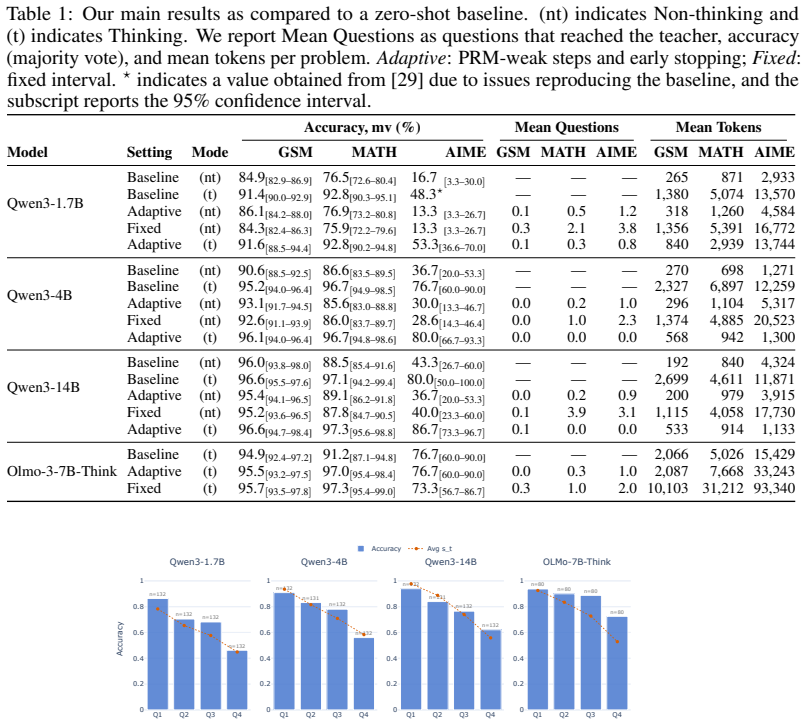
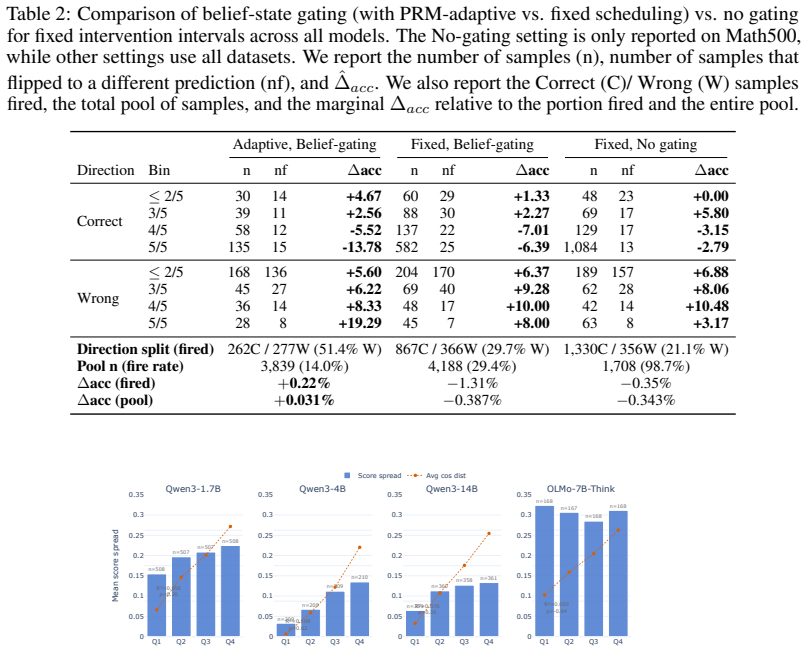
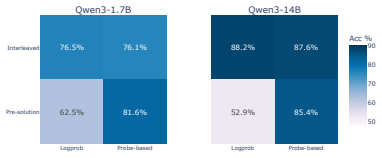
Test-time reasoning has become a significant field of study since the introduction of chain-of-thought reasoning in large language models (LLMs). However, the mechanisms of this reasoning process are still under-explored -- from the same input prompt, and even the same partial solution, LLMs can produce varied answers if sampled multiple times. We propose to leverage question-asking as an inference-time intervention that articulates information about the model's hidden state. To achieve that, we present a student-teacher setting where a student asks questions to a teacher. We train a probe on the student's hidden state before and after asking a question and find it is predictive of the trajectory's final correctness, even before generating the teacher's answer. This suggests there is a meaningful signal from the self-diagnosis that occurs during question generation rather than information transfer from the teacher. We then frame question-asking as a sequential decision problem, using this probe as a quality score, and define a gating policy to ask questions that maximize likelihood of correctness. We find that the success of question-asking as an intervention is largely dependent on the model's self-consistency. Our empirical results show a gap between detection and recovery; while our gating policy captures model correctness and uncertainty, interventions are equally likely to harm correct trajectories as they are to recover incorrect ones. This gap between diagnosis and correction has broader implications on language models' capacity for self-refinement under uncertainty.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a student-teacher framework in which a student model generates questions to articulate information from its hidden state during test-time reasoning. A probe is trained on the student's hidden states before and after question generation and is found to be predictive of the final correctness of the reasoning trajectory, even prior to the teacher's answer. This is interpreted as evidence of self-diagnosis during question generation. The probe is then used to define a gating policy for question-asking as a sequential decision problem. Empirical results indicate that the success of such interventions depends on the model's self-consistency, and while the policy captures correctness and uncertainty, interventions are equally likely to harm correct trajectories as to recover incorrect ones, revealing a gap between detection and recovery in self-refinement.
Significance. If the central claim holds after addressing the experimental design, the work would be significant for providing a method to extract self-diagnosis signals from hidden-state changes during question generation and for empirically documenting a gap between uncertainty detection and successful correction via interventions. The framing of question-asking as a sequential decision problem with a probe-based quality score is a clear contribution to test-time reasoning research.
major comments (2)
- [§3] §3 (Student-teacher setting): The setup collects states only inside a student-teacher loop where the student is explicitly prompted to generate questions; no control condition (e.g., student generating non-diagnostic text or a non-interactive forward pass) is described. Consequently the probe could be learning any systematic difference that the question-generation prompt induces in the student’s activations, independent of whether that difference reflects genuine internal uncertainty diagnosis. This is load-bearing for the claim that the predictive signal originates from self-diagnosis rather than architecture-specific correlations.
- [§5] §5 (Gating policy and empirical results): The abstract states that interventions are equally likely to harm correct trajectories as to recover incorrect ones and that success depends on self-consistency, but provides no details on probe architecture, training data, baselines, statistical controls, or how the gating policy is implemented. Without these, the reported gap between detection and recovery cannot be evaluated and may not isolate the probe's contribution.
minor comments (2)
- [Abstract] Abstract: the phrase 'trajectory's final correctness' is introduced without an explicit definition or reference to how correctness is measured across sampled trajectories.
- Notation for the probe input (before/after hidden-state difference) and the quality score used in the gating policy should be formalized with an equation or pseudocode for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below, acknowledging where additional experiments or clarifications are warranted.
read point-by-point responses
-
Referee: [§3] §3 (Student-teacher setting): The setup collects states only inside a student-teacher loop where the student is explicitly prompted to generate questions; no control condition (e.g., student generating non-diagnostic text or a non-interactive forward pass) is described. Consequently the probe could be learning any systematic difference that the question-generation prompt induces in the student’s activations, independent of whether that difference reflects genuine internal uncertainty diagnosis. This is load-bearing for the claim that the predictive signal originates from self-diagnosis rather than architecture-specific correlations.
Authors: We agree this is a substantive concern for isolating the source of the signal. The current design measures the change in hidden states triggered specifically by question generation and shows the probe remains predictive prior to any teacher response, which we interpret as evidence of an internal diagnostic process. However, without explicit controls for prompt effects, alternative explanations cannot be ruled out. In the revised manuscript we will add control conditions in which the student generates non-diagnostic text or performs a standard forward pass without question generation, allowing direct comparison of probe performance across conditions. revision: yes
-
Referee: [§5] §5 (Gating policy and empirical results): The abstract states that interventions are equally likely to harm correct trajectories as to recover incorrect ones and that success depends on self-consistency, but provides no details on probe architecture, training data, baselines, statistical controls, or how the gating policy is implemented. Without these, the reported gap between detection and recovery cannot be evaluated and may not isolate the probe's contribution.
Authors: The probe (a linear classifier trained on hidden-state differences labeled by final trajectory correctness) and the gating policy (thresholding the probe score within a sequential decision process) are specified in Sections 4 and 5, along with training data construction and self-consistency metrics. Baselines and statistical reporting appear in the experimental results. To improve evaluability we will expand the abstract with a concise description of the probe and policy, add an explicit ablation subsection comparing against random and uncertainty-only gating, and include statistical significance tests for the harm/recovery rates. revision: partial
Circularity Check
No significant circularity; derivation is self-contained empirical probing
full rationale
The paper describes training a probe on student hidden states before/after question generation to predict final trajectory correctness, then using the probe output as a gating score in a sequential decision setup. This is a standard supervised probing pipeline with no equations or claims that reduce the reported predictive performance to a self-definition, a fitted parameter renamed as an independent prediction, or a self-citation chain. The abstract and description contain no load-bearing self-citations, uniqueness theorems, or ansatzes smuggled via prior work; the central empirical finding (probe predictive before teacher response) follows directly from the supervised training objective on the collected states and does not collapse by construction to its inputs. The setup is externally falsifiable via control conditions or alternative architectures, satisfying the criteria for non-circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Aliannejadi, H
M. Aliannejadi, H. Zamani, F. Crestani, and W. B. Croft. Asking clarifying questions in open- domain information-seeking conversations. InProceedings of the 42nd international acm sigir conference on research and development in information retrieval, pages 475–484, 2019
2019
-
[2]
R. B. Ambati, T. Niu, A. Singh, S. Mishra, S. Chaturvedi, and S. Srivastava. Socratic students: Teaching language models to learn by asking questions.arXiv preprint arXiv:2512.13102, 2025
arXiv 2025
-
[3]
Probing Classifiers: Promises, Shortcomings, and Advances
Y . Belinkov. Probing classifiers: Promises, shortcomings, and advances.Computational Linguistics, 48(1):207–219, Mar. 2022. doi: 10.1162/coli_a_00422. URL https:// aclanthology.org/2022.cl-1.7/
work page internal anchor Pith review doi:10.1162/coli_a_00422 2022
-
[4]
Chang, Y
K. Chang, Y . Shi, C. Wang, H. Zhou, C. Hu, X. Liu, Y . Luo, Y . Ge, T. Xiao, and J. Zhu. Step- level verifier-guided hybrid test-time scaling for large language models. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 18473–18488, 2025
2025
-
[5]
X. Chen, J. Xu, T. Liang, Z. He, J. Pang, D. Yu, L. Song, Q. Liu, M. Zhou, Z. Zhang, et al. Do not think that much for 2+3=? on the overthinking of o1-like llms.arXiv preprint arXiv:2412.21187, 2024
Pith/arXiv arXiv 2024
-
[6]
K. Cobbe, V . Kosaraju, M. Bavarian, M. Chen, H. Jun, L. Kaiser, M. Plappert, J. Tworek, J. Hilton, R. Nakano, C. Hesse, and J. Schulman. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
Pith/arXiv arXiv 2021
-
[7]
Hendrycks, C
D. Hendrycks, C. Burns, S. Kadavath, A. Arora, S. Basart, E. Tang, D. Song, and J. Steinhardt. Measuring mathematical problem solving with the math dataset.NeurIPS, 2021
2021
-
[8]
Z. Hu, C. Liu, X. Feng, Y . Zhao, S.-K. Ng, A. T. Luu, J. He, P. W. Koh, and B. Hooi. Uncertainty of thoughts: Uncertainty-aware planning enhances information seeking in LLMs. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URL https://openreview.net/forum?id=CVpuVe1N22
2024
- [9]
-
[10]
J. Huang, X. Chen, S. Mishra, H. S. Zheng, A. W. Yu, X. Song, and D. Zhou. Large language models cannot self-correct reasoning yet.arXiv preprint arXiv:2310.01798, 2023
Pith/arXiv arXiv 2023
-
[11]
Kambhampati, K
S. Kambhampati, K. Stechly, K. Valmeekam, L. P. Saldyt, S. Bhambri, V . Palod, A. Gundawar, S. R. Samineni, D. Kalwar, and U. Biswas. Stop anthropomorphizing intermediate tokens as reasoning/thinking traces! InNeurIPS 2025 Workshop on Bridging Language, Agent, and World Models for Reasoning and Planning, 2025
2025
-
[12]
Kazemi, B
M. Kazemi, B. Fatemi, H. Bansal, J. Palowitch, C. Anastasiou, S. V . Mehta, L. K. Jain, V . Aglietti, D. Jindal, Y . P. Chen, et al. Big-bench extra hard. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 26473–26501, 2025
2025
-
[13]
D. Kumaran, S. M. Fleming, L. Markeeva, J. Heyward, A. Banino, M. Mathur, R. Pascanu, S. Osindero, B. De Martino, P. Velickovic, et al. How overconfidence in initial choices and underconfidence under criticism modulate change of mind in large language models.arXiv preprint arXiv:2507.03120, 2025
arXiv 2025
-
[14]
X. Li, E. Callanan, A. Ghassel, and X. Zhu. Entropy-gated branching for efficient test-time reasoning. In V . Demberg, K. Inui, and L. Marquez, editors,Proceedings of the 19th Con- ference of the European Chapter of the Association for Computational Linguistics (V olume 1: Long Papers), pages 5054–5069, Rabat, Morocco, Mar. 2026. Association for Computa- ...
-
[15]
Madaan, N
A. Madaan, N. Tandon, P. Gupta, S. Hallinan, L. Gao, S. Wiegreffe, U. Alon, N. Dziri, S. Prabhumoye, Y . Yang, et al. Self-refine: Iterative refinement with self-feedback.Advances in neural information processing systems, 36:46534–46594, 2023
2023
-
[16]
In Findings of the Association for Computational Lin- guistics: EMNLP 2025
N. Muennighoff, Z. Yang, W. Shi, X. L. Li, L. Fei-Fei, H. Hajishirzi, L. Zettlemoyer, P. Liang, E. Candès, and T. Hashimoto. s1: Simple test-time scaling. In C. Christodoulopoulos, T. Chakraborty, C. Rose, and V . Peng, editors,Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 20275–20321, Suzhou, China, Nov. 20...
-
[17]
T. Olmo, A. Ettinger, A. Bertsch, B. Kuehl, D. Graham, D. Heineman, D. Groeneveld, F. Brah- man, F. Timbers, H. Ivison, et al. Olmo 3.arXiv preprint arXiv:2512.13961, 2025
Pith/arXiv arXiv 2025
-
[18]
Press, M
O. Press, M. Zhang, S. Min, L. Schmidt, N. A. Smith, and M. Lewis. Measuring and narrowing the compositionality gap in language models. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 5687–5711, 2023
2023
-
[19]
S. Rao and H. Daumé III. Learning to ask good questions: Ranking clarification questions using neural expected value of perfect information. In I. Gurevych and Y . Miyao, editors, Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 2737–2746, Melbourne, Australia, July 2018. Association f...
-
[20]
Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y . Li, Y . Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
Pith/arXiv arXiv 2024
-
[21]
Shinn, F
N. Shinn, F. Cassano, A. Gopinath, K. Narasimhan, and S. Yao. Reflexion: Language agents with verbal reinforcement learning.Advances in neural information processing systems, 36: 8634–8652, 2023
2023
-
[22]
C. Snell, J. Lee, K. Xu, and A. Kumar. Scaling llm test-time compute optimally can be more effective than scaling model parameters.arXiv preprint arXiv:2408.03314, 2024
Pith/arXiv arXiv 2024
-
[23]
Y . Sui, Y .-N. Chuang, G. Wang, J. Zhang, T. Zhang, J. Yuan, H. Liu, A. Wen, S. Zhong, N. Zou, et al. Stop overthinking: A survey on efficient reasoning for large language models.arXiv preprint arXiv:2503.16419, 2025
Pith/arXiv arXiv 2025
- [24]
-
[25]
G. Tyen, H. Mansoor, V . C˘arbune, Y . P. Chen, and T. Mak. Llms cannot find reasoning errors, but can correct them given the error location. InFindings of the Association for Computational Linguistics: ACL 2024, pages 13894–13908, 2024
2024
-
[26]
X. Wang, J. Wei, D. Schuurmans, Q. Le, E. Chi, S. Narang, A. Chowdhery, and D. Zhou. Self-consistency improves chain of thought reasoning in language models.arXiv preprint arXiv:2203.11171, 2022
Pith/arXiv arXiv 2022
-
[27]
Z. Wang and C. Xu. ThoughtProbe: Classifier-guided LLM thought space exploration via probing representations. In C. Christodoulopoulos, T. Chakraborty, C. Rose, and V . Peng, editors,Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 6018–6039, Suzhou, China, Nov. 2025. Association for Computational Linguistics. ...
-
[28]
J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V . Le, D. Zhou, et al. Chain-of- thought prompting elicits reasoning in large language models.Advances in neural information processing systems, 35:24824–24837, 2022
2022
-
[29]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025. 11
Pith/arXiv arXiv 2025
-
[30]
Zelikman, Y
E. Zelikman, Y . Wu, J. Mu, and N. Goodman. Star: Bootstrapping reasoning with reasoning. Advances in Neural Information Processing Systems, 35:15476–15488, 2022
2022
-
[31]
Q. Zhang, F. Lyu, Z. Sun, L. Wang, W. Zhang, W. Hua, H. Wu, Z. Guo, Y . Wang, N. Muennighoff, et al. A survey on test-time scaling in large language models: What, how, where, and how well? arXiv preprint arXiv:2503.24235, 2025
Pith/arXiv arXiv 2025
-
[32]
Zhang and T
Y . Zhang and T. Math-AI. American invitational mathematics examination (aime) 2024, 2024
2024
-
[33]
Zhang, C
Z. Zhang, C. Zheng, Y . Wu, B. Zhang, R. Lin, B. Yu, D. Liu, J. Zhou, and J. Lin. The lessons of developing process reward models in mathematical reasoning. InFindings of the Association for Computational Linguistics: ACL 2025, pages 10495–10516, 2025
2025
-
[34]
Y . Zhu, D. Liu, Z. Lin, W. Tong, S. Zhong, and J. Shao. The llm already knows: Estimating llm- perceived question difficulty via hidden representations. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 1160–1176, 2025. 12 A Derivations We conceptualize the QA test-time intervention as a sequential decision p...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.