Disagreeing Rationales: Rethinking Classification and Explainability Evaluation in Hate Speech Detection
Pith reviewed 2026-06-28 22:10 UTC · model grok-4.3
The pith
Evaluation metrics for hate speech detection consistently favor softer label and rationale representations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By re-implementing models and metrics across hard, intermediate and soft rationale representation spaces together with hard and soft labels, both classification and explainability metrics consistently favor softer representations, which capture the variation in human reasoning and interpretations more effectively than hard majority-vote approaches in subjective NLP tasks such as hate speech detection.
What carries the argument
The unified supervision framework that systematically re-implements models, losses and metrics across three rationale representation spaces (hard, intermediate, soft) and two label spaces (hard, soft), with metrics organized into predictive/distributional for classification and plausibility/faithfulness/complexity for explainability.
Load-bearing premise
Re-implementing existing models and metrics across the three rationale representation spaces produces comparable and unbiased comparisons without artifacts from the unification protocol or from the specific hate speech datasets used.
What would settle it
A replication using different hate speech datasets or an alternative unification protocol in which the metrics no longer favor softer representations over hard ones.
Figures
read the original abstract
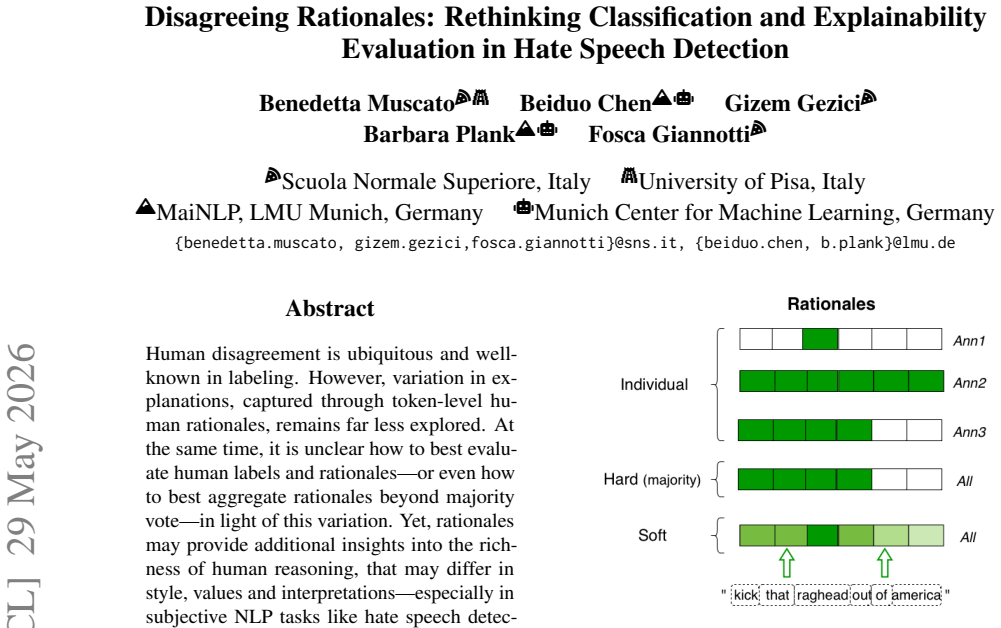
Human disagreement is ubiquitous and well-known in labeling. However, variation in explanations, captured through token-level human rationales, remains far less explored. At the same time, it is unclear how to best evaluate human labels and rationales -- or even how to best aggregate rationales beyond majority vote -- in light of this variation. Yet, rationales may provide additional insights into the richness of human reasoning, that may differ in style, values and interpretations -- especially in subjective NLP tasks like hate speech detection. In this work, we unify diverse models, training strategies, loss functions, and existing evaluation metrics under a single protocol by systematically re-implementing them across different label and rationale representation spaces. Classification metrics are organized around two key properties -- predictive and distributional -- while explainability metrics through three complementary dimensions: plausibility, faithfulness, and complexity. In this unified supervision framework, we evaluate model behavior across classification and explainability metrics, as well as metric sensitivity to the choice of label (hard and soft) and rationale representation space (hard, intermediate and soft). Results show that both hard and soft metrics favor softer representations, highlighting their effectiveness in capturing variation and the need to rethink evaluation in subjective NLP.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a unified supervision framework for hate speech detection that systematically re-implements diverse models, training strategies, loss functions, and evaluation metrics across hard, intermediate, and soft label/rationale representation spaces. Classification metrics are grouped by predictive and distributional properties; explainability metrics are assessed along plausibility, faithfulness, and complexity. The central empirical result is that both hard and soft metrics favor softer representations, which the authors interpret as evidence that soft spaces better capture human variation and that evaluation practices in subjective NLP tasks require rethinking.
Significance. If the unification protocol produces unbiased comparisons, the work offers a valuable systematic comparison of representation spaces in a high-disagreement domain and could encourage wider adoption of soft labels/rationale encodings. The explicit organization of metrics into complementary dimensions is a constructive contribution. The absence of machine-checked proofs or parameter-free derivations is expected for this empirical study; credit is due for the reproducible re-implementation protocol across three spaces.
major comments (2)
- [Methods (unification protocol)] Unification protocol (Methods section): the headline claim that both hard and soft metrics favor softer representations rests on the assumption that the single re-implementation protocol introduces no systematic bias when porting architectures, losses, and metrics to the three rationale spaces. No ablation or matched-baseline verification is described that would rule out artifacts (e.g., soft labels yielding lower complexity or better distributional match by construction). This is load-bearing for the central result.
- [Results (metric sensitivity)] Metric sensitivity analysis (Results section): the reported favoring of soft representations must be shown to be robust to the specific hate-speech datasets and to the concrete definitions of the predictive/distributional and plausibility/faithfulness/complexity metrics; without effect sizes, confidence intervals, or statistical tests comparing the three spaces, it is unclear whether the observed differences exceed what would be expected from the adaptation rules alone.
minor comments (2)
- [Abstract/Introduction] The abstract and introduction would benefit from an explicit statement of the three rationale spaces (hard, intermediate, soft) with one-sentence definitions before the unification claim is introduced.
- [Methods] Notation for the re-implemented losses and metrics should be introduced once in a table or dedicated subsection rather than scattered across the text.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below, providing our response and indicating planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Methods (unification protocol)] Unification protocol (Methods section): the headline claim that both hard and soft metrics favor softer representations rests on the assumption that the single re-implementation protocol introduces no systematic bias when porting architectures, losses, and metrics to the three rationale spaces. No ablation or matched-baseline verification is described that would rule out artifacts (e.g., soft labels yielding lower complexity or better distributional match by construction). This is load-bearing for the central result.
Authors: We appreciate the referee highlighting the centrality of the unification protocol. Our protocol systematically adapts the same model architectures, training strategies, and loss functions to each representation space using minimal, space-appropriate modifications (e.g., cross-entropy for hard, KL divergence for soft). This design aims to isolate representation effects rather than implementation differences. However, we acknowledge that explicit ablations with matched baselines would further rule out artifacts. In the revised manuscript, we will add a new subsection with such verifications, including controls that test whether soft spaces receive unintended advantages by construction. revision: yes
-
Referee: [Results (metric sensitivity)] Metric sensitivity analysis (Results section): the reported favoring of soft representations must be shown to be robust to the specific hate-speech datasets and to the concrete definitions of the predictive/distributional and plausibility/faithfulness/complexity metrics; without effect sizes, confidence intervals, or statistical tests comparing the three spaces, it is unclear whether the observed differences exceed what would be expected from the adaptation rules alone.
Authors: We agree that formal statistical analysis is required to establish robustness. While the manuscript already evaluates across multiple hate speech datasets and organizes metrics into predictive/distributional and plausibility/faithfulness/complexity dimensions, it does not report effect sizes, confidence intervals, or significance tests. In the revision, we will expand the Results section to include these (e.g., Cohen's d effect sizes, bootstrap confidence intervals, and paired statistical tests with corrections) comparing the three spaces, along with a brief sensitivity discussion to metric definitions and dataset choice. revision: yes
Circularity Check
No circularity: purely empirical re-implementation and metric comparison
full rationale
The paper performs an empirical study by re-implementing existing models, losses, and metrics across hard/intermediate/soft label and rationale spaces under a unified protocol, then reports observed performance differences on classification and explainability metrics. No equations, derivations, predictions, or fitted parameters are present that could reduce to inputs by construction. No self-citation chains or uniqueness theorems are invoked as load-bearing premises. The central claim (metrics favor softer representations) is an experimental outcome, not a definitional or fitted tautology. This matches the default expectation for non-circular empirical work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[2]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
\"O zge Alacam, Sanne Hoeken, and Sina Zarrie . 2024. Eyes don’t lie: Subjective hate annotation and detection with gaze. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 187--205
2024
-
[4]
Lora Aroyo and Chris Welty. 2015. Truth is a lie: Crowd truth and the seven myths of human annotation. AI magazine, 36(1):15--24
2015
-
[5]
Pepa Atanasova, Jakob Grue Simonsen, Christina Lioma, and Isabelle Augenstein. 2020. A diagnostic study of explainability techniques for text classification. In Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP), pages 3256--3274
2020
-
[6]
Valerio Basile, Michael Fell, Tommaso Fornaciari, Dirk Hovy, Silviu Paun, Barbara Plank, Massimo Poesio, and Alexandra Uma. 2021. We need to consider disagreement in evaluation. In Proceedings of the 1st workshop on benchmarking: past, present and future, pages 15--21
2021
-
[7]
Jacob Benesty, Jingdong Chen, Yiteng Huang, and Israel Cohen. 2009. Pearson correlation coefficient. In Noise reduction in speech processing, pages 1--4. Springer
2009
-
[8]
Umang Bhatt, Adrian Weller, and Jos \'e MF Moura. 2021. Evaluating and aggregating feature-based model explanations. In Proceedings of the Twenty-Ninth International Conference on International Joint Conferences on Artificial Intelligence, pages 3016--3022
2021
-
[9]
Federico Cabitza, Andrea Campagner, and Valerio Basile. 2023. Toward a perspectivist turn in ground truthing for predictive computing. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 37, pages 6860--6868
2023
-
[10]
Prasad Chalasani, Jiefeng Chen, Amrita Roy Chowdhury, Xi Wu, and Somesh Jha. 2020. Concise explanations of neural networks using adversarial training. In International conference on machine learning, pages 1383--1391. PMLR
2020
-
[11]
Beiduo Chen, Siyao Peng, Anna Korhonen, and Barbara Plank. 2025. https://doi.org/10.18653/v1/2025.findings-acl.562 A rose by any other name: LLM -generated explanations are good proxies for human explanations to collect label distributions on NLI . In Findings of the Association for Computational Linguistics: ACL 2025, pages 10777--10802, Vienna, Austria....
-
[12]
Beiduo Chen, Xinpeng Wang, Siyao Peng, Robert Litschko, Anna Korhonen, and Barbara Plank. 2024. https://doi.org/10.18653/v1/2024.findings-emnlp.842 ``seeing the big through the small'': Can LLM s approximate human judgment distributions on NLI from a few explanations? In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 14396--1...
-
[13]
Jacob Cohen. 2013. Statistical power analysis for the behavioral sciences. routledge
2013
-
[14]
Aida Davani, Mark Diaz, Dylan Baker, and Vinodkumar Prabhakaran. 2024. D3code: Disentangling disagreements in data across cultures on offensiveness detection and evaluation. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 18511--18526
2024
-
[15]
Thomas Davidson, Debasmita Bhattacharya, and Ingmar Weber. 2019. Racial bias in hate speech and abusive language detection datasets. In Proceedings of the third workshop on abusive language online, pages 25--35
2019
- [16]
-
[17]
Jay DeYoung, Sarthak Jain, Nazneen Fatema Rajani, Eric Lehman, Caiming Xiong, Richard Socher, and Byron C Wallace. 2020. Eraser: A benchmark to evaluate rationalized nlp models. In Proceedings of the 58th annual meeting of the association for computational linguistics, pages 4443--4458
2020
- [18]
-
[19]
Brage Eilertsen, R skva Bj rgfinsd \'o ttir, Francielle Vargas, and Ali Ramezani-Kebrya. 2025. Aligning attention with human rationales for self-explaining hate speech detection. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI). To appear
2025
-
[20]
Andy Field. 2013. Discovering Statistics Using IBM SPSS Statistics. SAGE
2013
-
[21]
Tommaso Fornaciari, Alexandra Uma, Silviu Paun, Barbara Plank, Dirk Hovy, and Massimo Poesio. 2021. Beyond black & white: Leveraging annotator disagreement via soft-label multi-task learning. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 2591--2597
2021
-
[22]
Antigoni Founta, Constantinos Djouvas, Despoina Chatzakou, Ilias Leontiadis, Jeremy Blackburn, Gianluca Stringhini, Athena Vakali, Michael Sirivianos, and Nicolas Kourtellis. 2018. Large scale crowdsourcing and characterization of twitter abusive behavior. In Proceedings of the international AAAI conference on web and social media, volume 12
2018
-
[23]
Mareike Hartmann and Daniel Sonntag. 2022. A survey on improving nlp models with human explanations. In Proceedings of the first workshop on learning with natural language supervision, pages 40--47
2022
-
[24]
Pingjun Hong, Beiduo Chen, Siyao Peng, Marie-Catherine de Marneffe, and Barbara Plank. 2025. Litex: A linguistic taxonomy of explanations for understanding within-label variation in natural language inference. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 34053--34073
2025
-
[25]
Sarthak Jain and Byron C Wallace. 2019. Attention is not explanation. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 3543--3556
2019
-
[26]
Nan-Jiang Jiang, Chenhao Tan, and Marie-Catherine de Marneffe. 2023. https://doi.org/10.18653/v1/2023.findings-emnlp.712 Ecologically valid explanations for label variation in NLI . In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 10622--10633, Singapore. Association for Computational Linguistics
-
[27]
Jiyun Kim, Byounghan Lee, and Kyung-Ah Sohn. 2022. Why is it hate speech? masked rationale prediction for explainable hate speech detection. In Proceedings of the 29th International Conference on Computational Linguistics, pages 6644--6655
2022
-
[28]
Kemal Kurniawan, Meladel Mistica, Timothy Baldwin, and Jey Han Lau. 2025. Training and evaluating with human label variation: An empirical study. Computational Linguistics, pages 1--27
2025
-
[29]
Jianhua Lin. 2002. Divergence measures based on the shannon entropy. IEEE Transactions on Information theory, 37(1):145--151
2002
-
[30]
Binny Mathew, Punyajoy Saha, Seid Muhie Yimam, Chris Biemann, Pawan Goyal, and Animesh Mukherjee. 2021. Hatexplain: A benchmark dataset for explainable hate speech detection. In Proceedings of the AAAI conference on artificial intelligence, volume 35, pages 14867--14875
2021
-
[31]
Erick Mendez Guzman, Viktor Schlegel, and Riza Batista-Navarro. 2024. From outputs to insights: a survey of rationalization approaches for explainable text classification. Frontiers in Artificial Intelligence, 7:1363531
2024
-
[32]
Benedetta Muscato, Lucia Passaro, Gizem Gezici, and Fosca Giannotti. 2025. Perspectives in play: a multi-perspective approach for more inclusive nlp systems. In Proceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence, pages 9827--9835
2025
-
[33]
Wallace, Sarah Wiegreffe, Eric Wong, Ian Tenney, and Mor Geva
Hadas Orgad, Fazl Barez, Tal Haklay, Isabelle Lee, Marius Mosbach, Anja Reusch, Naomi Saphra, Byron C. Wallace, Sarah Wiegreffe, Eric Wong, Ian Tenney, and Mor Geva. 2026. https://actionable-interpretability.github.io Interpretability can be actionable
2026
-
[34]
Barbara Plank. 2022. The “problem” of human label variation: On ground truth in data, modeling and evaluation. In Proceedings of the 2022 conference on empirical methods in natural language processing, pages 10671--10682
2022
-
[35]
Giulia Rizzi, Elisa Leonardelli, Massimo Poesio, Alexandra Uma, Maja Pavlovic, Silviu Paun, Paolo Rosso, and Elisabetta Fersini. 2024. Soft metrics for evaluation with disagreements: an assessment. In Proceedings of the 3rd Workshop on Perspectivist Approaches to NLP (NLPerspectives)@ LREC-COLING 2024, pages 84--94
2024
-
[36]
Filipe Rodrigues and Francisco Pereira. 2018. Deep learning from crowds. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 32. Association for the Advancement of Artificial Intelligence (AAAI)
2018
-
[37]
Pratik Sachdeva, Renata Barreto, Geoff Bacon, Alexander Sahn, Claudia Von Vacano, and Chris Kennedy. 2022. The measuring hate speech corpus: Leveraging rasch measurement theory for data perspectivism. In Proceedings of the 1st Workshop on Perspectivist Approaches to NLP@ LREC2022, pages 83--94
2022
-
[38]
Isadora Salles, Francielle Vargas, and Fabr \' cio Benevenuto. 2025. Hatebrxplain: A benchmark dataset with human-annotated rationales for explainable hate speech detection in brazilian portuguese. In Proceedings of the 31st international conference on computational linguistics, pages 6659--6669
2025
-
[39]
Marta Sandri, Elisa Leonardelli, Sara Tonelli, and Elisabetta Je z ek. 2023. Why don’t you do it right? analysing annotators’ disagreement in subjective tasks. In Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, pages 2428--2441
2023
-
[40]
Maarten Sap, Saadia Gabriel, Lianhui Qin, Dan Jurafsky, Noah A Smith, and Yejin Choi. 2020. Social bias frames: Reasoning about social and power implications of language. In Proceedings of the 58th annual meeting of the association for computational linguistics, pages 5477--5490
2020
-
[41]
Ceyhan Ceran Serdar, Murat Cihan, Do g an Y \"u cel, and Muhittin A Serdar. 2021. Sample size, power and effect size revisited: simplified and practical approaches in pre-clinical, clinical and laboratory studies. Biochemia medica, 31(1):27--53
2021
-
[42]
Samuel Sanford Shapiro and Martin B. Wilk. 1965. https://doi.org/10.1093/biomet/52.3-4.591 An analysis of variance test for normality (complete samples) . Biometrika, 52(3-4):591--611
-
[43]
Marina Sokolova and Guy Lapalme. 2009. A systematic analysis of performance measures for classification tasks. Information processing & management, 45(4):427--437
2009
-
[44]
Julia Strout, Ye Zhang, and Raymond Mooney. 2019. Do human rationales improve machine explanations? In Proceedings of the 2019 ACL Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, pages 56--62
2019
-
[45]
Gail M Sullivan and Richard Feinn. 2012. Using effect size—or why the p value is not enough. Journal of graduate medical education, 4(3):279--282
2012
-
[46]
Alexandra Uma, Tommaso Fornaciari, Dirk Hovy, Silviu Paun, Barbara Plank, and Massimo Poesio. 2020. A case for soft loss functions. In Proceedings of the AAAI Conference on Human Computation and Crowdsourcing, volume 8, pages 173--177
2020
-
[47]
Francielle Vargas, Isabelle Carvalho, Fabiana Rodrigues de G \'o es, Thiago Pardo, and Fabr \' cio Benevenuto. 2022. Hatebr: A large expert annotated corpus of brazilian instagram comments for offensive language and hate speech detection. In Proceedings of the Thirteenth Language Resources and Evaluation Conference, pages 7174--7183
2022
-
[48]
Frank Wilcoxon. 1945. Individual comparisons by ranking methods. Biometrics bulletin, 1(6):80--83
1945
-
[49]
Haiyan Zhao, Hanjie Chen, Fan Yang, Ninghao Liu, Huiqi Deng, Hengyi Cai, Shuaiqiang Wang, Dawei Yin, and Mengnan Du. 2024. Explainability for large language models: A survey. ACM Transactions on Intelligent Systems and Technology, 15(2):1--38
2024
-
[50]
Zhixue Zhao and Nikolaos Aletras. 2023. Incorporating attribution importance for improving faithfulness metrics. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 4732--4745
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.