SOCO: Benchmarking Semantic Object Correspondence in Vision Foundation Models
Pith reviewed 2026-06-28 23:00 UTC · model grok-4.3
The pith
Semantic correspondence performance predicts dense downstream task success more strongly than ImageNet classification accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SOCO supplies a taxonomy of correspondence types together with consistent, functionally meaningful keypoint annotations and language descriptions. Experiments on this benchmark show that vision foundation backbones encode strong semantic structure but transfer correspondences poorly across related categories and capture object-part position only partially. Large vision-language models perform better at text-prompted part localization than at visual-reference cross-image matching. Correspondence performance predicts performance on dense downstream tasks including segmentation, tracking, 3D pose estimation, and 3D detection more strongly than ImageNet classification.
What carries the argument
The SOCO benchmark, which defines a taxonomy of correspondence types, supplies over one million consistent keypoint pairs across 100 categories, and adds language descriptions for evaluating part-level understanding.
Load-bearing premise
The keypoint annotations are functionally meaningful, consistent across instances and categories, and capture the relevant variations in appearance, viewpoint, and geometry needed for fair evaluation.
What would settle it
Finding a model that achieves high scores on SOCO correspondence pairs yet low accuracy on segmentation, tracking, or 3D pose estimation (or the reverse pattern) would undermine the claim that correspondence is the stronger predictor.
Figures


read the original abstract
Measuring structured object understanding in vision foundation models remains challenging due to inconsistent evaluation protocols and limited part-level supervision. Semantic correspondence (SC) evaluates this capability by testing whether object parts can be matched across instances and categories under large variations in appearance, viewpoint, and geometry. To enable a systematic SC evaluation, we introduce SOCO, a new benchmark for Semantic Object Correspondence that introduces a taxonomy of correspondence types and provides consistent, functionally meaningful keypoint annotations across 100 categories and over 1M correspondence pairs. In addition, SOCO includes keypoint language descriptions, enabling the evaluation of large vision-language models (LVLMs) and their fine-grained part-level understanding. Comprehensive experiments reveal that (i) vision foundation backbones encode strong semantic structure but transfer correspondences poorly across related categories and only partially capture object-part position, (ii) LVLMs are stronger at text-prompted part localization than at visual-reference cross-image matching, exposing a gap between language-grounded localization and fine-grained visual correspondence, and (iii) correspondence performance predicts performance on dense downstream tasks, including segmentation, tracking, 3D pose estimation, and 3D detection, more strongly than ImageNet classification. Together, these findings position SOCO as a benchmark for structured, part-level representation quality in vision and multimodal foundation models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the SOCO benchmark for semantic object correspondence, featuring a taxonomy of correspondence types, consistent keypoint annotations across 100 categories with over 1M pairs, and language descriptions for keypoints. It evaluates vision foundation models and LVLMs, reporting three findings: backbones encode semantic structure but transfer correspondences poorly across categories and only partially capture part positions; LVLMs perform better at text-prompted part localization than visual-reference matching; and correspondence performance predicts results on dense downstream tasks (segmentation, tracking, 3D pose, 3D detection) more strongly than ImageNet classification accuracy.
Significance. If the keypoint annotations and correlations prove robust, SOCO would provide a useful large-scale benchmark for part-level structured understanding in foundation models, with the predictive relation to downstream dense tasks offering a concrete alternative to ImageNet-centric evaluation. The inclusion of both visual and language-grounded evaluations and the scale of the dataset are clear strengths that could influence model assessment practices.
major comments (2)
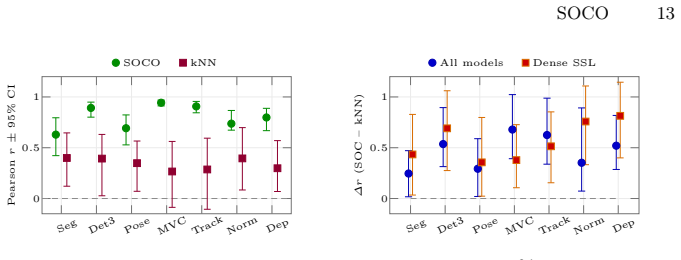
- [§3] §3 (SOCO Benchmark): The central claim that SC performance predicts downstream task performance more strongly than ImageNet accuracy (finding iii) rests on the reliability of the 1M+ keypoint pairs being functionally meaningful and consistent. The manuscript states these properties but reports no inter-annotator agreement, expert validation study, or ablation perturbing the annotations to test sensitivity of the reported correlations. This is load-bearing for the strongest empirical claim.
- [§5.3] §5.3 (Downstream Correlation Analysis): The stronger predictive power of SC scores versus ImageNet accuracy is presented without details on pre-specification of category subsets, aggregation method across the 100 categories, or controls for category difficulty. Post-hoc selection could inflate the reported advantage; a concrete test (e.g., fixed held-out category split) is needed to support the claim.
minor comments (2)
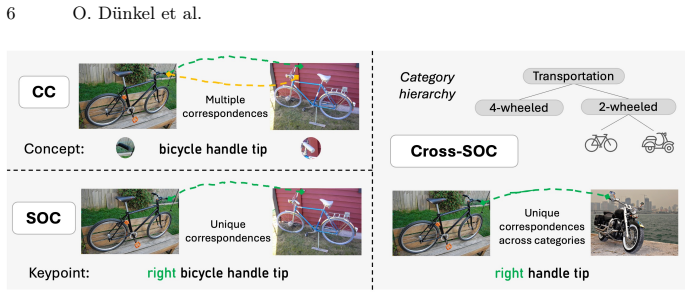
- [§3.2] Figure 2 and §3.2: The taxonomy of correspondence types is introduced but the distribution of the 1M pairs across types is not quantified, making it hard to interpret transfer results across related categories.
- [§4.1] §4.1: Notation for SC metrics (e.g., PCK thresholds) should be defined before the first table of results for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and will incorporate revisions to strengthen the empirical foundations of our claims regarding annotation reliability and correlation analysis.
read point-by-point responses
-
Referee: [§3] §3 (SOCO Benchmark): The central claim that SC performance predicts downstream task performance more strongly than ImageNet accuracy (finding iii) rests on the reliability of the 1M+ keypoint pairs being functionally meaningful and consistent. The manuscript states these properties but reports no inter-annotator agreement, expert validation study, or ablation perturbing the annotations to test sensitivity of the reported correlations. This is load-bearing for the strongest empirical claim.
Authors: We agree that the absence of inter-annotator agreement metrics, expert validation, and sensitivity ablations represents a gap for a load-bearing claim. The annotations were created by multiple trained annotators using a detailed taxonomy and functional guidelines to promote consistency across the 100 categories. However, these validation steps were not included in the original manuscript. In the revised version, we will report inter-annotator agreement on a sampled subset of categories, include results from an expert validation study, and add a perturbation ablation that randomly alters a fraction of keypoints before recomputing the downstream correlations to assess sensitivity. revision: yes
-
Referee: [§5.3] §5.3 (Downstream Correlation Analysis): The stronger predictive power of SC scores versus ImageNet accuracy is presented without details on pre-specification of category subsets, aggregation method across the 100 categories, or controls for category difficulty. Post-hoc selection could inflate the reported advantage; a concrete test (e.g., fixed held-out category split) is needed to support the claim.
Authors: We acknowledge that the original manuscript lacked explicit details on category subset selection, aggregation procedures, and controls for category difficulty, which could raise concerns about post-hoc analysis. The subsets were chosen based on the intersection of categories with available downstream annotations, and correlations were aggregated via mean Pearson coefficients across categories. To address this rigorously, the revision will document the exact aggregation method, include controls for category difficulty (e.g., via regression with difficulty proxies), and report results from a pre-specified held-out split: a predictive model trained on 70 categories and evaluated on the remaining 30 to verify that SC scores retain stronger predictive power than ImageNet accuracy. revision: yes
Circularity Check
No circularity: purely empirical benchmark with independent measurements
full rationale
The paper introduces a new benchmark (SOCO) with keypoint annotations and reports empirical correlations between SC scores and downstream task performance. No derivation chain, equations, fitted parameters, or self-citation load-bearing steps exist that reduce any claimed result to its inputs by construction. The reported correlations are computed from separate evaluations on external tasks and models, rendering the analysis self-contained.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.