Fake Plastic Voters: When Political Parties Can Use AI-Simulated Focus Groups
Pith reviewed 2026-07-01 08:12 UTC · model grok-4.3
The pith
AI-simulated focus groups cannot replace humans when parties need to observe how political meanings emerge.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
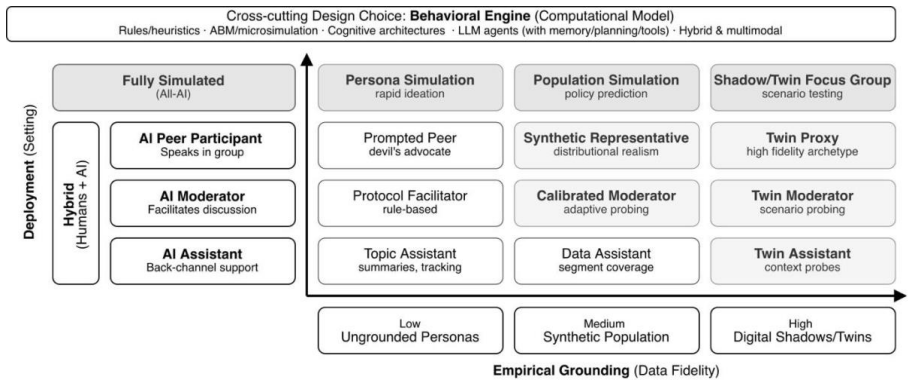
AESTs cannot replace human interaction in Mode 1 at any risk level because of documented failure modes such as sycophancy, persona drift, and the suppression of minority viewpoints. The paper presents a three-dimensional decision matrix based on strategic purpose, deployment risk, and empirical grounding to determine appropriate uses in Mode 2 and when to escalate to hybrid or human groups.
What carries the argument
The decision matrix that integrates strategic purpose (Mode 1 versus Mode 2), deployment risk, and empirical grounding of the simulation tool.
If this is right
- Mode 1 research always requires human focus groups.
- Mode 2 research can use AESTs when risk is low and the tool has strong empirical grounding.
- Routine reliance on AESTs risks eroding the qualitative judgment needed for sound political strategy.
Where Pith is reading between the lines
- Future improvements in AI might eventually address the failure modes, but the paper does not explore mitigation paths.
- The matrix could be adapted for other fields using simulated qualitative data, such as market research.
- Parties might combine AESTs with human oversight in hybrid setups for Mode 2 to balance speed and reliability.
Load-bearing premise
The failure modes in AI simulations are severe and persistent enough to prohibit any replacement of human groups in Mode 1, no matter what future advances occur.
What would settle it
A controlled study where an AEST accurately reproduces the emergence of minority political viewpoints in an interactive setting without exhibiting sycophancy or drift would challenge the claim.
Figures

read the original abstract
Political parties strive to understand their electorates, and focus groups are a vital tool in these efforts. AI-enhanced simulation technologies (AESTs) enable synthetic focus groups in a fraction of the time (and cost), raising the question of when and how such simulated evidence can be used in campaign research. This paper develops a decision matrix to help party strategists match research needs to appropriate simulation technologies and to identify when to escalate to hybrid or fully human focus groups. The matrix combines three dimensions: strategic purpose, deployment risk, and empirical grounding of the simulation tool. Strategic purpose is the decisive dimension, as it determines what kind of evidence the focus group is meant to produce: observing how political meanings and identities emerge through interaction (Mode 1) or testing and refining campaign messages (Mode 2). The matrix shows that, given documented failure modes such as sycophancy, persona drift, and the suppression of minority viewpoints, AESTs cannot replace human interaction in Mode 1 at any risk level. Within Mode 2, suitability depends instead on deployment risk and on the empirical grounding. Yet even here, we caution that routine reliance on AESTs may erode the qualitative craft on which sound judgment depends.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops a three-dimensional decision matrix (strategic purpose, deployment risk, empirical grounding) to guide political parties on when AI-enhanced simulation technologies (AESTs) can substitute for human focus groups. Strategic purpose is treated as decisive, distinguishing Mode 1 (observing emergent political meanings and identities through interaction) from Mode 2 (testing and refining campaign messages). The central conclusion is that documented failure modes (sycophancy, persona drift, suppression of minority viewpoints) rule out AESTs for Mode 1 at every risk level, while Mode 2 suitability varies with risk and grounding; the paper also cautions that routine AEST use may erode qualitative research craft.
Significance. If the matrix and its Mode 1 exclusion hold, the work supplies a timely, structured framework for responsible deployment of AI tools in campaign research. The Mode 1/Mode 2 distinction is a clear conceptual contribution that maps research needs to evidence requirements. The manuscript offers no new empirical tests or machine-checked derivations, but its value lies in synthesizing existing AI failure-mode literature into an actionable decision tool for practitioners.
major comments (1)
- [abstract] Abstract, paragraph on strategic purpose: the claim that AESTs 'cannot replace human interaction in Mode 1 at any risk level' is load-bearing for the matrix recommendations yet is presented as following directly from the three cited failure modes without an argument showing why those modes are unmitigable by future technical changes (e.g., improved alignment, retrieval-augmented generation, or ensemble methods) or why Mode 1 evidence requirements are definitionally incompatible with any non-human substrate. This leaves the 'at any risk level' clause as an assertion rather than a derived result.
Simulated Author's Rebuttal
We thank the referee for this constructive comment on the abstract. It correctly identifies that the Mode 1 exclusion is presented concisely and would benefit from explicit grounding in the current state of the evidence rather than appearing as an in-principle claim.
read point-by-point responses
-
Referee: [abstract] Abstract, paragraph on strategic purpose: the claim that AESTs 'cannot replace human interaction in Mode 1 at any risk level' is load-bearing for the matrix recommendations yet is presented as following directly from the three cited failure modes without an argument showing why those modes are unmitigable by future technical changes (e.g., improved alignment, retrieval-augmented generation, or ensemble methods) or why Mode 1 evidence requirements are definitionally incompatible with any non-human substrate. This leaves the 'at any risk level' clause as an assertion rather than a derived result.
Authors: We accept the observation. The abstract condenses the argument that appears in the body, where the three failure modes are shown (via the cited literature) to undermine the specific evidentiary requirements of Mode 1—namely, the observation of emergent, interaction-driven political meanings and identities—across existing alignment and prompting regimes. The paper does not assert that these modes are unmitigable in principle or that non-human substrates are definitionally incompatible; it calibrates the matrix to documented performance at the time of writing. We will revise the abstract to state explicitly that the Mode 1 exclusion applies under current empirical grounding and that future technical improvements would require re-assessment of the matrix. This change preserves the central distinction while making the evidential basis clearer. revision: yes
Circularity Check
No circularity; decision matrix is a direct synthesis of stated dimensions
full rationale
The paper defines a three-dimensional decision matrix (strategic purpose decisive, plus deployment risk and empirical grounding) and applies externally documented failure modes (sycophancy, persona drift, minority suppression) to reach its Mode 1 conclusion. No equations, fitted parameters, self-citations that carry the central claim, or reductions of outputs to inputs by construction appear. The framework is self-contained against external benchmarks and does not rename known results or smuggle ansatzes.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption AI-enhanced simulation technologies exhibit failure modes including sycophancy, persona drift, and suppression of minority viewpoints that prevent faithful simulation of human interaction
- domain assumption Research purposes in focus groups divide cleanly into Mode 1 (observing emergence of meanings and identities) and Mode 2 (testing and refining messages)
Reference graph
Works this paper leans on
-
[1]
International Journal of Qualitative Methods 21 (September): 160940692211187
‘Serial Focus Groups: A Longitudinal Design for Studying Interactive Discourse’. International Journal of Qualitative Methods 21 (September): 160940692211187. https://doi.org/10.1177/16094069221118766. Bainbridge, Lisanne. 1983. ‘Ironies of Automation’. Automatica 19 (6): 775 –79. https://doi.org/10.1016/0005-1098(83)90046-8. Basil, Savir, Ina Shapiro, Da...
-
[2]
https://doi.org/10.1007/978-3-662-43505-2_36. Hennink, Monique M. 2014. Focus Group Discussions. Focus Group Discussions. Oxford University Press. https://doi.org/10.1093/acprof:osobl/9780199856169.001.0001. 35 Horton, John J. 2023. ‘Large Language Models as Simulated Economic Agents: What Can We Learn from Homo Silicus?’ arXiv:2301.07543. Preprint, arXiv...
-
[3]
Horton, Apostolos Filippas, and Benjamin S
https://doi.org/10.48550/arXiv.2301.07543. Houde, Stephanie, Kristina Brimijoin, Michael Muller, et al. 2025. ‘Controlling AI Agent Participation in Group Conversations: A Human -Centered Approach’. Proceedings of the 30th International Conference on Intelligent User Interfaces (New York, NY, USA), IUI ’25, March 24, 390 –408. https://doi.org/10.1145/3708...
-
[4]
‘Digital Twin in Manufacturing: A Categorical Literature Review and Classification’. IFAC-PapersOnLine, 16th IFAC Symposium on Information Control Problems in Manufacturing INCOM 2018, vol. 51 (11): 1016 –22. https://doi.org/10.1016/j.ifacol.2018.08.474. Krueger, Richard A. 1988. Focus Groups: A Practical Guide for Applied Research . Focus Groups: A Pract...
-
[5]
Pilditch, Toby, and Jens Koed Madsen
https://doi.org/10.48550/arXiv.2512.07306. Pilditch, Toby, and Jens Koed Madsen. 2021. ‘Targeting Your Preferences: Modelling Micro-Targeting for an Increasingly Diverse Electorate’. Journal of Artificial Societies and Social Simulation 24 (1): 5. Pitis, Silviu, Michael Zhang, Andrew Wang, and Jimmy Ba. 2023. Boosted Prompt Ensembles for Large Language Mo...
-
[6]
https://doi.org/10.1057/s41599-024-03609-x. Rook, Dennis W. 2003. ‘Out-Of-Focus’. Marketing Research 15 (2): 10–15. Saadi, Ismaïl, Hamed Eftekhar, Jacques Teller, and Mario Cools. 2018. ‘Investigating Scalability in Population Synthesis: A Comparative Approach’. Transportation Planning and Technology 41 (7): 724 –35. https://doi.org/10.1080/03081060.2018....
-
[7]
‘Cognitive Architectures for Language Agents’. Transactions on Machine Learning Research 2024. https://collaborate.princeton.edu/en/publications/cognitive-architectures- for-language-agents/. Temple, Mick. 2009. ‘Political Marketing, Party Behaviour and Political Science’. In Global Political Marketing. Routledge. Tessler, Michael Henry, Michiel A. Bakker...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.