Graph-Augmented Retrieval for Cross-Entity Financial Sentiment Analysis: A Comparative Study
Pith reviewed 2026-06-30 17:55 UTC · model grok-4.3
The pith
Graph-augmented retrieval raises entity recall by 6.4% and relevancy by 11.7% over vector RAG for multi-entity financial queries.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
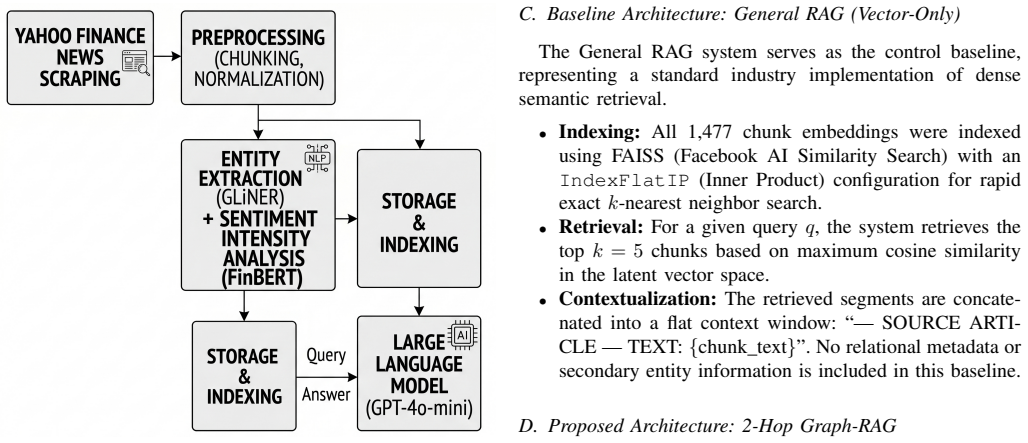
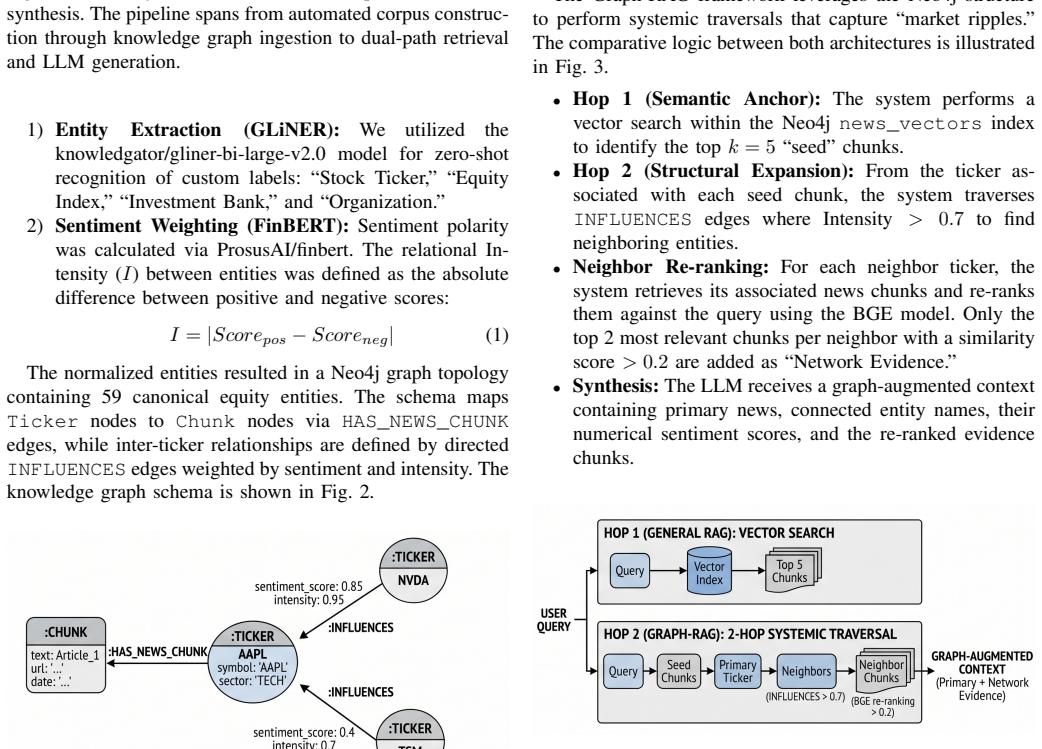
The two-hop Graph-RAG architecture augments dense retrieval with intensity-filtered graph traversal over INFLUENCES edges in a sentiment-weighted knowledge graph built from 255 articles on 10 technology stocks. This yields a statistically significant 6.4% improvement in entity recall and 11.7% higher answer relevancy on complex multi-entity queries compared to a vector-only baseline, with gains of 16.1% on relational questions and no meaningful drop in semantic similarity.
What carries the argument
Intensity-filtered two-hop graph traversal over INFLUENCES edges in the sentiment-weighted knowledge graph, which retrieves relational evidence between equity entities that pure vector search misses.
If this is right
- Improvements concentrate on relational question types with a 16.1% gain in answer relevancy.
- Semantic similarity remains essentially unchanged with a delta of +0.001.
- Graph traversal intensity shows an inverted-U effect on quality, optimized at threshold 0.5 rather than the default 0.7.
- Mean latency rises 22.6% while latency variance falls 80%.
- The architecture offers guidance for RAG systems handling multi-entity financial analysis.
Where Pith is reading between the lines
- Similar graph augmentation could benefit other domains with entity influence networks, such as regulatory filings or supply chain data.
- Lower latency variance may matter more for user experience than the modest increase in average time.
- Users should validate the optimal intensity threshold on their specific corpus instead of adopting published defaults.
- Testing on larger or more diverse article sets would clarify how the benefits scale with data volume.
Load-bearing premise
The 100 queries and the sentiment-weighted knowledge graph from the 255 articles represent real-world cross-entity financial relationships and query distributions accurately.
What would settle it
Conducting the same comparison on a fresh collection of articles and queries from a different market sector or time window and observing no significant gains in entity recall or relevancy would falsify the claim.
Figures


read the original abstract
Retrieval-Augmented Generation (RAG) has become foundational for grounding large language models in domain-specific corpora, yet conventional vector-based RAG systems are fundamentally limited in their ability to capture the structured, multi-entity relationships that underpin financial market analysis. This paper presents a comprehensive comparative study of a novel two-hop Graph-RAG architecture versus a standard vector-only baseline for cross-entity financial sentiment analysis. Our system constructs a sentiment-weighted knowledge graph of 59 equity entities from 255 news articles covering 10 major technology stocks, then augments dense retrieval with intensity-filtered graph traversal over INFLUENCES edges to surface relational evidence inaccessible to vector search alone. We evaluate both architectures on 100 grounded queries (30 Direct, 70 Relational) using semantic similarity, entity recall, RAGAS metrics, latency benchmarks, and ablation studies. Graph-RAG achieves a statistically significant improvement in entity recall (+6.4%, p < 0.001, Wilcoxon signed-rank) and delivers substantially more relevant answers for complex multi-entity queries (+11.7% Answer Relevancy), with gains concentrating in relational question types (+16.1%). Critically, these improvements come at no measurable cost to answer quality (delta = +0.001 semantic similarity, Cohen's d = 0.078), with a modest 22.6% increase in mean latency offset by an 80% reduction in latency variance. An ablation study on the graph traversal intensity threshold reveals an inverted-U relationship with answer quality, identifying tau = 0.5 as optimal over the production default of tau = 0.7. These findings characterize a precision-for-coverage trade-off inherent to graph-augmented retrieval and provide actionable architectural guidance for practitioners building RAG systems for multi-entity financial analysis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that a two-hop Graph-RAG architecture, which augments dense retrieval with intensity-filtered traversal over a sentiment-weighted INFLUENCES knowledge graph built from 255 articles on 10 tech stocks, outperforms a standard vector RAG baseline on cross-entity financial sentiment tasks. On 100 internally constructed queries (30 direct, 70 relational), Graph-RAG yields +6.4% entity recall (p<0.001, Wilcoxon), +11.7% Answer Relevancy (concentrated at +16.1% for relational queries), with negligible change in semantic similarity and reduced latency variance; an ablation identifies tau=0.5 as optimal.
Significance. If the reported gains prove robust, the work supplies concrete architectural guidance for financial RAG systems by quantifying the precision-coverage trade-off inherent to graph augmentation and demonstrating that relational query performance can be improved without sacrificing answer quality. The presence of statistical testing, RAGAS metrics, latency benchmarks, and a threshold ablation adds empirical rigor to the comparison.
major comments (1)
- [Evaluation] Evaluation section (query construction and test-set description): The 100 queries are drawn exclusively from the identical 255-article corpus used to build the sentiment-weighted graph; no external query logs, expert-authored test set, temporal hold-out, or independent validation corpus is described. Because the headline improvements (+6.4% entity recall, +11.7% Answer Relevancy, +16.1% on relational queries) rest entirely on this closed construction, the statistical significance and RAGAS deltas only establish superiority inside the authors' sampling procedure rather than under realistic analyst query distributions.
minor comments (2)
- [Abstract] Abstract and §3: the precise procedure for generating the 30 direct and 70 relational queries (e.g., template-based, human-authored, or LLM-generated) is summarized rather than fully specified, making reproducibility of the test distribution difficult.
- Figure or table reporting per-query-type breakdowns: the +16.1% relational gain is stated without accompanying per-metric tables or confidence intervals, which would help readers assess effect-size stability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the evaluation design. We address the concern point-by-point below and will revise the manuscript to improve transparency.
read point-by-point responses
-
Referee: The 100 queries are drawn exclusively from the identical 255-article corpus used to build the sentiment-weighted graph; no external query logs, expert-authored test set, temporal hold-out, or independent validation corpus is described. Because the headline improvements (+6.4% entity recall, +11.7% Answer Relevancy, +16.1% on relational queries) rest entirely on this closed construction, the statistical significance and RAGAS deltas only establish superiority inside the authors' sampling procedure rather than under realistic analyst query distributions.
Authors: We agree this is a genuine limitation. The queries were intentionally constructed from the same 255-article corpus to ensure they are fully grounded (i.e., the required entities and relations are verifiably present), which enables precise computation of entity recall and controlled comparison of relational vs. direct queries. This design isolates the contribution of graph traversal without external noise. However, we acknowledge that the resulting performance deltas are specific to this closed sampling procedure and do not directly demonstrate robustness under realistic analyst query distributions. In the revised manuscript we will (1) add an explicit Limitations subsection in the Evaluation section describing the closed-world construction, (2) qualify the generalizability claims, and (3) outline planned future work with external or temporally held-out query sets. These changes will be reflected in both the main text and the abstract if space permits. revision: yes
Circularity Check
No circularity: empirical head-to-head evaluation with external metrics
full rationale
The paper is a comparative empirical study of Graph-RAG versus vector RAG. It constructs a sentiment-weighted graph from 255 articles and evaluates both systems on 100 queries using RAGAS metrics, semantic similarity, entity recall, and Wilcoxon tests. No mathematical derivations, predictions, or first-principles results are claimed. No equations appear that reduce a claimed output to fitted inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems. The evaluation relies on standard external metrics rather than internal redefinitions. The shared corpus between graph construction and queries raises generalizability questions but does not match any enumerated circularity pattern (self-definitional, fitted-input-as-prediction, etc.). This is a self-contained empirical comparison against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- tau =
0.5
axioms (1)
- domain assumption The sentiment-weighted knowledge graph of 59 entities accurately captures cross-entity influences from the 255 news articles.
Reference graph
Works this paper leans on
-
[1]
Retrieval-augmented generation for knowledge-intensive NLP tasks,
P. Lewiset al., “Retrieval-augmented generation for knowledge-intensive NLP tasks,” inAdvances in Neural Information Processing Systems, vol. 33, 2020
2020
-
[2]
GraphRAG: Leveraging graph-based efficiency to minimize hallucinations in LLM-driven RAG for finance data,
M. Barryet al., “GraphRAG: Leveraging graph-based efficiency to minimize hallucinations in LLM-driven RAG for finance data,” Pre-print, 2025
2025
-
[3]
From Local to Global: A Graph RAG Approach to Query-Focused Summarization
D. Edgeet al., “From local to global: A GraphRAG approach to query-focused summarization,” Microsoft Research,arXiv preprint arXiv:2404.16130, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Ragas: Automated Evaluation of Retrieval Augmented Generation
S. Es, J. James, L. Espinosa-Anke, and S. Schockaert, “RAGAS: Au- tomated evaluation of retrieval augmented generation,”arXiv preprint arXiv:2309.15217, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Knowledge-augmented financial market analysis and report generation,
Y . Chenet al., “Knowledge-augmented financial market analysis and report generation,” Tongji University / Ant Group, 2024
2024
-
[6]
Financial sentiment analysis and classification: A comparative study of fine-tuned deep learning models,
D. K. Nasiopoulos, K. I. Roumeliotis, D. P. Sakas, K. Toudas, and P. Rek- litis, “Financial sentiment analysis and classification: A comparative study of fine-tuned deep learning models,”Int. J. Financial Stud., vol. 13, no. 2, p. 75, 2025
2025
-
[7]
Financial knowledge graph based financial report query system,
S. Zehraet al., “Financial knowledge graph based financial report query system,”IEEE Access, 2021
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.