APE: Agentic Prompt Enhancer for Image Generation and Editing
Pith reviewed 2026-06-28 22:56 UTC · model grok-4.3
The pith
Post-training small language models as prompt enhancers narrows the gap to closed-source systems for image generation and editing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
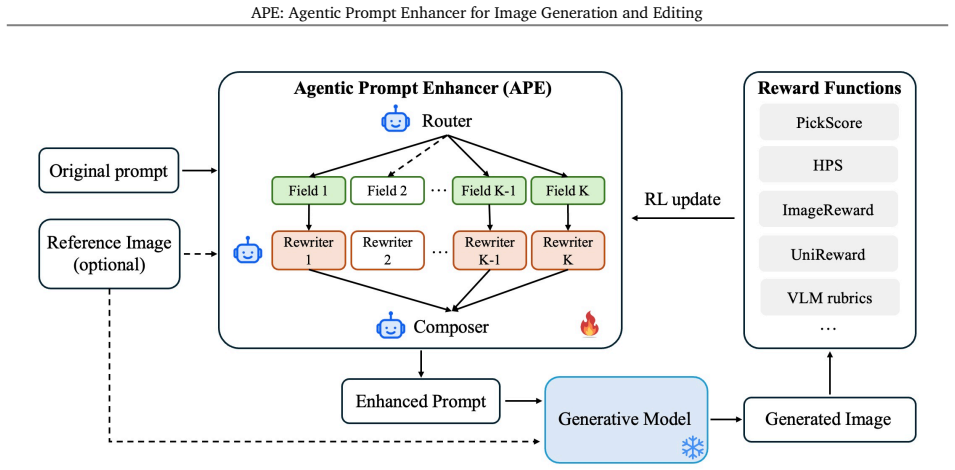
APE is a lightweight framework that post-trains small language models as prompt-enhancement agents. Its single-agent form rewrites the input prompt in one pass; its multi-agent form decomposes the task into router, rewriter, and composer stages to handle objects, attributes, spatial relations, and edits. With task-aware rewards and post-training, both versions improve visual alignment and prompt following on image generation and editing benchmarks while leaving the visual model untouched.
What carries the argument
The Agentic Prompt Enhancer (APE) framework, which post-trains small language models with task-aware rewards to act as prompt-rewriting agents, either singly or in a router-rewriter-composer multi-agent setup.
If this is right
- Small prompt enhancers become viable alternatives to large proprietary ones after post-training.
- Multi-agent decomposition improves handling of complex object-attribute-spatial constraints.
- Prompt enhancement can be added to any text-guided visual system without retraining or accessing the visual model.
- Single-pass and multi-agent variants offer trade-offs between simplicity and compositional strength.
Where Pith is reading between the lines
- The approach could be extended to other text-to-visual domains such as video or 3D generation by swapping the reward signals.
- Open deployment of such enhancers might reduce latency and cost in production image pipelines that currently call external LLMs.
- If the reward design generalizes, similar post-training could improve prompt following in non-visual domains like code generation.
Load-bearing premise
Task-aware rewards and post-training on small language models can produce reliable gains in visual alignment and compositional prompt following without access to the visual model's parameters or gradients.
What would settle it
A controlled experiment showing that post-trained small enhancers produce no measurable improvement over base models on the same image generation and editing benchmarks used in the paper.
Figures

read the original abstract
Natural language has become a powerful interface for image generation and editing, yet text-guided visual systems remain highly sensitive to prompt formulation. Semantically similar requests can produce different outputs depending on wording, specificity, and how explicitly visual constraints are stated, motivating prompt enhancement as a trainable component rather than a peripheral user choice. Existing strong enhancers often rely on large, proprietary LLMs such as ChatGPT or Gemini, adding cost, latency, and deployment dependence to the visual generation pipeline. We propose Agentic Prompt Enhancer (APE), a lightweight framework that post-trains small language models (SLMs) as prompt-enhancement agents. APE supports both single-agent rewriting and role-specialized multi-agent enhancement. Its single-agent instantiation, SAPE, rewrites the prompt in one pass, while its multi-agent instantiation, MAPE, decomposes enhancement into a router--rewriter--composer process for handling compositional constraints over objects, attributes, spatial relations, and edits. With task-aware rewards and post-training protocols, APE improves visual alignment and prompt following without modifying the downstream visual model. Experiments on challenging image generation and editing benchmarks demonstrate that post-trained small prompt enhancers reliably outperform their base counterparts, narrowing the gap to closed-source prompt enhancers; in addition, MAPE proves particularly strong on complex compositional tasks within these benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the Agentic Prompt Enhancer (APE) framework, which post-trains small language models (SLMs) to serve as prompt enhancers for image generation and editing. It describes a single-agent version (SAPE) that rewrites prompts in one pass and a multi-agent version (MAPE) that decomposes the task into router, rewriter, and composer roles to handle compositional constraints. The approach relies on task-aware rewards and post-training to improve visual alignment and prompt following without access to the visual model's parameters or gradients, claiming superior performance over base SLMs and closer parity with closed-source enhancers on relevant benchmarks.
Significance. If substantiated, the results would demonstrate that lightweight, post-trained SLMs can effectively serve as prompt enhancers, offering a cost-effective and low-latency alternative to large proprietary models in visual generation pipelines. The agentic, role-specialized design for handling complex compositional tasks represents a structured approach to prompt optimization. The paper's emphasis on not modifying the downstream visual model is a practical strength for compatibility.
major comments (1)
- Abstract: The central claim that post-trained small prompt enhancers 'reliably outperform their base counterparts' and narrow the gap to closed-source enhancers is asserted without any supporting quantitative results, baselines, error bars, dataset details, or experimental controls in the provided manuscript text. This absence makes the primary empirical contribution impossible to evaluate.
minor comments (1)
- The abstract mentions 'challenging image generation and editing benchmarks' but does not name them or provide references to the specific datasets used.
Simulated Author's Rebuttal
We thank the referee for the review and the identification of this issue with the abstract. We address the comment below.
read point-by-point responses
-
Referee: Abstract: The central claim that post-trained small prompt enhancers 'reliably outperform their base counterparts' and narrow the gap to closed-source enhancers is asserted without any supporting quantitative results, baselines, error bars, dataset details, or experimental controls in the provided manuscript text. This absence makes the primary empirical contribution impossible to evaluate.
Authors: We agree that the abstract as submitted summarizes the primary claims without embedding specific quantitative results, baselines, or controls, which limits its standalone evaluability. The body of the manuscript contains the full experimental details (benchmarks, metrics, comparisons to base SLMs and closed-source enhancers). To directly address the concern, we will revise the abstract to include a concise summary of the key quantitative outcomes (e.g., relative gains on visual alignment metrics and benchmark names) while preserving its length constraints. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper is an empirical ML contribution describing a post-training framework for small language models as prompt enhancers. No equations, derivations, or first-principles claims appear in the abstract or referenced structure. Claims of improvement rest on benchmark experiments rather than any reduction of outputs to fitted inputs or self-citations by construction. The absence of mathematical content places all enumerated circularity patterns outside applicability; the work is self-contained as an applied method with external evaluation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Improvingimagegenerationwithbettercaptions.ComputerScience.https://cdn
James Betker, Gabriel Goh, Li Jing, Tim Brooks, Jianfeng Wang, Linjie Li, Long Ouyang, Juntang Zhuang, JoyceLee,YufeiGuo,etal. Improvingimagegenerationwithbettercaptions.ComputerScience.https://cdn. openai. com/papers/dall-e-3. pdf, 2(3):8, 2023. 4, 6, 37 37 APE: Agentic Prompt Enhancer for Image Generation and Editing
2023
-
[2]
Z-Image: An Efficient Image Generation Foundation Model with Single-Stream Diffusion Transformer
Huanqia Cai, Sihan Cao, Ruoyi Du, Peng Gao, Steven Hoi, Zhaohui Hou, Shijie Huang, Dengyang Jiang, Xin Jin, Liangchen Li, et al. Z-image: An efficient image generation foundation model with single-stream diffusion transformer.arXiv preprint arXiv:2511.22699, 2025. 6, 10, 37
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Agentverse: Facilitating multi-agent collaboration and exploring emergent behaviors
Weize Chen, Yusheng Su, Jingwei Zuo, Cheng Yang, Chenfei Yuan, Chi-Min Chan, Heyang Yu, Yaxi Lu, Yi-Hsin Hung, Chen Qian, et al. Agentverse: Facilitating multi-agent collaboration and exploring emergent behaviors. InThe Twelfth International Conference on Learning Representations, 2023. 6, 37
2023
-
[4]
Scaling rectified flow transformers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow transformers for high-resolution image synthesis. InForty-first international conference on machine learning, 2024. 6, 37
2024
-
[5]
Promptbreeder: Self-referential self-improvement via prompt evolution
Chrisantha Fernando, Dylan Sunil Banarse, Henryk Michalewski, Simon Osindero, and Tim Rocktäschel. Promptbreeder: Self-referential self-improvement via prompt evolution. InForty-first International Conference on Machine Learning. 6, 37
-
[6]
Generative adversarial networks.Communications of the ACM, 63(11):139– 144, 2020
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial networks.Communications of the ACM, 63(11):139– 144, 2020. 6, 36
2020
-
[7]
Gemini 3.1 Pro.https://gemini.google.com/, 2026
Google. Gemini 3.1 Pro.https://gemini.google.com/, 2026. Accessed: April 28, 2026. 11
2026
-
[8]
Large language model based multi-agents: A survey of progress and challenges
T Guo, X Chen, Y Wang, R Chang, S Pei, NV Chawla, O Wiest, and X Zhang. Large language model based multi-agents: A survey of progress and challenges. In33rd International Joint Conference on Artificial Intelligence (IJCAI 2024). IJCAI; Cornell arxiv, 2024. 6, 37
2024
-
[9]
Eyal Gutflaish, Eliran Kachlon, Hezi Zisman, Tal Hacham, Nimrod Sarid, Alexander Visheratin, Saar Huberman, Gal Davidi, Guy Bukchin, Kfir Goldberg, et al. Generating an image from 1,000 words: Enhancing text-to-image with structured captions.arXiv preprint arXiv:2511.06876, 2025. 4, 6, 8, 37
-
[10]
Mahmood Hegazy. Diversity of thought elicits stronger reasoning capabilities in multi-agent debate frameworks.arXiv preprint arXiv:2410.12853, 2024. 6, 37
-
[11]
Clipscore: A reference-free evaluation metric for image captioning
Jack Hessel, Ari Holtzman, Maxwell Forbes, Ronan Le Bras, and Yejin Choi. Clipscore: A reference-free evaluation metric for image captioning. InProceedings of the 2021 conference on empirical methods in natural language processing, pages 7514–7528, 2021. 10
2021
-
[12]
Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020. 6, 37
2020
-
[13]
Metagpt: Meta programming for a multi-agent collaborative framework
Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, et al. Metagpt: Meta programming for a multi-agent collaborative framework. InThe twelfth international conference on learning representations, 2023. 6, 37
2023
-
[14]
Tianyu Hu, Zhen Tan, Song Wang, Huaizhi Qu, and Tianlong Chen. Multi-agent debate for llm judges with adaptive stability detection.arXiv preprint arXiv:2510.12697, 2025. 6, 37
-
[15]
A style-based generator architecture for generative adversarial networks
Tero Karras, Samuli Laine, and Timo Aila. A style-based generator architecture for generative adversarial networks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4401–4410, 2019. 6, 36
2019
-
[16]
Pick-a-pic: An open dataset of user preferences for text-to-image generation.Advances in neural information processing systems, 36:36652–36663, 2023
Yuval Kirstain, Adam Polyak, Uriel Singer, Shahbuland Matiana, Joe Penna, and Omer Levy. Pick-a-pic: An open dataset of user preferences for text-to-image generation.Advances in neural information processing systems, 36:36652–36663, 2023. 10
2023
-
[17]
FLUX.2: Frontier Visual Intelligence.https://bfl.ai/blog/flux-2, 2025
Black Forest Labs. FLUX.2: Frontier Visual Intelligence.https://bfl.ai/blog/flux-2, 2025. 6, 10, 37 38 APE: Agentic Prompt Enhancer for Image Generation and Editing
2025
-
[18]
Black Forest Labs, Stephen Batifol, Andreas Blattmann, Frederic Boesel, Saksham Consul, Cyril Diagne, Tim Dockhorn, Jack English, Zion English, Patrick Esser, et al. Flux. 1 kontext: Flow matching for in-context image generation and editing in latent space.arXiv preprint arXiv:2506.15742, 2025. 6, 37
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Camel: Communicative agents for" mind" exploration of large language model society.Advances in neural information processing systems, 36:51991–52008, 2023
GuohaoLi,HasanHammoud,HaniItani,DmitriiKhizbullin,andBernardGhanem. Camel: Communicative agents for" mind" exploration of large language model society.Advances in neural information processing systems, 36:51991–52008, 2023. 6, 37
2023
-
[20]
A survey on llm-based multi-agent systems: workflow, infrastructure, and challenges.Vicinagearth, 1(1):9, 2024
Xinyi Li, Sai Wang, Siqi Zeng, Yu Wu, and Yi Yang. A survey on llm-based multi-agent systems: workflow, infrastructure, and challenges.Vicinagearth, 1(1):9, 2024. 6, 37
2024
-
[21]
Llm-grounded diffusion: Enhancing prompt under- standing of text-to-image diffusion models with large language models.Transactions on Machine Learning Research
Long Lian, Boyi Li, Adam Yala, and Trevor Darrell. Llm-grounded diffusion: Enhancing prompt under- standing of text-to-image diffusion models with large language models.Transactions on Machine Learning Research. 6, 37
-
[22]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022. 6, 37
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[23]
Flow-grpo: Training flow matching models via online rl
Jie Liu, Gongye Liu, Jiajun Liang, Yangguang Li, Jiaheng Liu, Xintao Wang, Pengfei Wan, Di ZHANG, and Wanli Ouyang. Flow-grpo: Training flow matching models via online rl. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems. 10
-
[24]
GDPO: Group reward-Decoupled Normalization Policy Optimization for Multi-reward RL Optimization
Shih-Yang Liu, Xin Dong, Ximing Lu, Shizhe Diao, Peter Belcak, Mingjie Liu, Min-Hung Chen, Hongxu Yin, Yu-Chiang Frank Wang, Kwang-Ting Cheng, et al. Gdpo: Group reward-decoupled normalization policy optimization for multi-reward rl optimization.arXiv preprint arXiv:2601.05242, 2026. 6
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[25]
Improved denoising diffusion probabilistic models
Alexander Quinn Nichol and Prafulla Dhariwal. Improved denoising diffusion probabilistic models. In International conference on machine learning, pages 8162–8171. PMLR, 2021. 6, 37
2021
-
[26]
Gpt-4.1, 2026
OpenAI. Gpt-4.1, 2026. 13
2026
-
[27]
Image transformer
Niki Parmar, Ashish Vaswani, Jakob Uszkoreit, Lukasz Kaiser, Noam Shazeer, Alexander Ku, and Dustin Tran. Image transformer. InInternational conference on machine learning, pages 4055–4064. PMLR, 2018. 6, 36
2018
-
[28]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023. 6, 37
2023
-
[29]
Sdxl: Improving latent diffusion models for high-resolution image synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis. InThe Twelfth International Conference on Learning Representations. 4
-
[30]
Chatdev: Communicative agents for software development
Chen Qian, Wei Liu, Hongzhang Liu, Nuo Chen, Yufan Dang, Jiahao Li, Cheng Yang, Weize Chen, Yusheng Su, Xin Cong, et al. Chatdev: Communicative agents for software development. InProceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers), pages 15174–15186,
-
[31]
Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks
Alec Radford, Luke Metz, and Soumith Chintala. Unsupervised representation learning with deep convolutional generative adversarial networks.arXiv preprint arXiv:1511.06434, 2015. 6, 36
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[32]
Zero-shot text-to-image generation
Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea Voss, Alec Radford, Mark Chen, and Ilya Sutskever. Zero-shot text-to-image generation. InInternational conference on machine learning, pages 8821–8831. Pmlr, 2021. 6, 36 39 APE: Agentic Prompt Enhancer for Image Generation and Editing
2021
-
[33]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022. 4, 6, 37
2022
-
[34]
Photorealistic text- to-image diffusion models with deep language understanding.Advances in neural information processing systems, 35:36479–36494, 2022
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, et al. Photorealistic text- to-image diffusion models with deep language understanding.Advances in neural information processing systems, 35:36479–36494, 2022. 10
2022
-
[35]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024. 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling llm test-time compute optimally can be more effective than scaling model parameters.arXiv preprint arXiv:2408.03314, 2024. 13
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
Score-Based Generative Modeling through Stochastic Differential Equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations.arXiv preprint arXiv:2011.13456, 2020. 6, 37
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[38]
Multi-Agent Collaboration Mechanisms: A Survey of LLMs
Khanh-Tung Tran, Dung Dao, Minh-Duong Nguyen, Quoc-Viet Pham, Barry O’Sullivan, and Hoang D Nguyen. Multi-agent collaboration mechanisms: A survey of llms.arXiv preprint arXiv:2501.06322, 2025. 6, 37
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Conditional image generation with pixelcnn decoders.Advances in neural information processing systems, 29, 2016
Aaron Van den Oord, Nal Kalchbrenner, Lasse Espeholt, Oriol Vinyals, Alex Graves, et al. Conditional image generation with pixelcnn decoders.Advances in neural information processing systems, 29, 2016. 6, 36
2016
-
[40]
Linqing Wang, Ximing Xing, Yiji Cheng, Zhiyuan Zhao, Donghao Li, Tiankai Hang, Jiale Tao, Qixun Wang, Ruihuang Li, Comi Chen, et al. Promptenhancer: A simple approach to enhance text-to-image models via chain-of-thought prompt rewriting.arXiv preprint arXiv:2509.04545, 2025. 6, 37
-
[41]
Unigenbench++: A unified semantic evaluation benchmark for text-to-image generation
Yibin Wang, Zhimin Li, Yuhang Zang, Jiazi Bu, Yujie Zhou, Yi Xin, Junjun He, Chunyu Wang, Qinglin Lu, Cheng Jin, et al. Unigenbench++: A unified semantic evaluation benchmark for text-to-image generation. arXiv preprint arXiv:2510.18701, 2025. 11
-
[42]
Unified Reward Model for Multimodal Understanding and Generation
Yibin Wang, Yuhang Zang, Hao Li, Cheng Jin, and Jiaqi Wang. Unified reward model for multimodal understanding and generation.arXiv preprint arXiv:2503.05236, 2025. 10
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng-ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, et al. Qwen-image technical report.arXiv preprint arXiv:2508.02324, 2025. 6, 10, 37
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
arXiv preprint arXiv:2510.04290 (2025) 2, 5, 9, 10, 11 PhyEditBench 19
Jay Zhangjie Wu, Xuanchi Ren, Tianchang Shen, Tianshi Cao, Kai He, Yifan Lu, Ruiyuan Gao, Enze Xie, Shiyi Lan, Jose M Alvarez, et al. Chronoedit: Towards temporal reasoning for image editing and world simulation.arXiv preprint arXiv:2510.04290, 2025. 6, 37
-
[45]
Autogen: Enablingnext-genllmapplicationsviamulti-agentconversations
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, ShaokunZhang, JialeLiu, etal. Autogen: Enablingnext-genllmapplicationsviamulti-agentconversations. InFirst conference on language modeling, 2024. 6, 37
2024
-
[46]
Xiaoshi Wu, Yiming Hao, Keqiang Sun, Yixiong Chen, Feng Zhu, Rui Zhao, and Hongsheng Li. Human preference score v2: A solid benchmark for evaluating human preferences of text-to-image synthesis. arXiv preprint arXiv:2306.09341, 2023. 10 40 APE: Agentic Prompt Enhancer for Image Generation and Editing
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[47]
Imagereward: Learning and evaluating human preferences for text-to-image generation.Advances in Neural Information Processing Systems, 36:15903–15935, 2023
Jiazheng Xu, Xiao Liu, Yuchen Wu, Yuxuan Tong, Qinkai Li, Ming Ding, Jie Tang, and Yuxiao Dong. Imagereward: Learning and evaluating human preferences for text-to-image generation.Advances in Neural Information Processing Systems, 36:15903–15935, 2023. 10
2023
-
[48]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025. 10
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
Imgedit: A unified image editing dataset and benchmark
Yang Ye, Xianyi He, Zongjian Li, Bin Lin, Shenghai Yuan, Zhiyuan Yan, Bohan Hou, and Li Yuan. Imgedit: A unified image editing dataset and benchmark. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track. 13
-
[50]
DiffusionNFT: Online diffusion reinforcement with forward process
Kaiwen Zheng, Huayu Chen, Haotian Ye, Haoxiang Wang, Qinsheng Zhang, Kai Jiang, Hang Su, Stefano Ermon, Jun Zhu, and Ming-Yu Liu. DiffusionNFT: Online diffusion reinforcement with forward process. InThe Fourteenth International Conference on Learning Representations, 2026. 10
2026
-
[51]
Large language models are human-level prompt engineers
Yongchao Zhou, Andrei Ioan Muresanu, Ziwen Han, Keiran Paster, Silviu Pitis, Harris Chan, and Jimmy Ba. Large language models are human-level prompt engineers. InThe eleventh international conference on learning representations, 2022. 6, 37 41
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.