MindZero: Learning Online Mental Reasoning With Zero Annotations
Pith reviewed 2026-06-28 21:55 UTC · model grok-4.3
The pith
MindZero trains multimodal language models to infer mental states from actions using only self-supervised rewards from an action planner.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
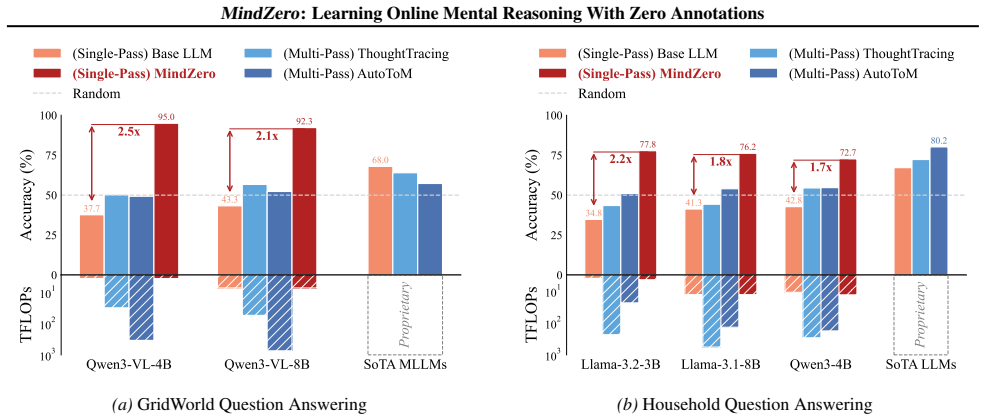
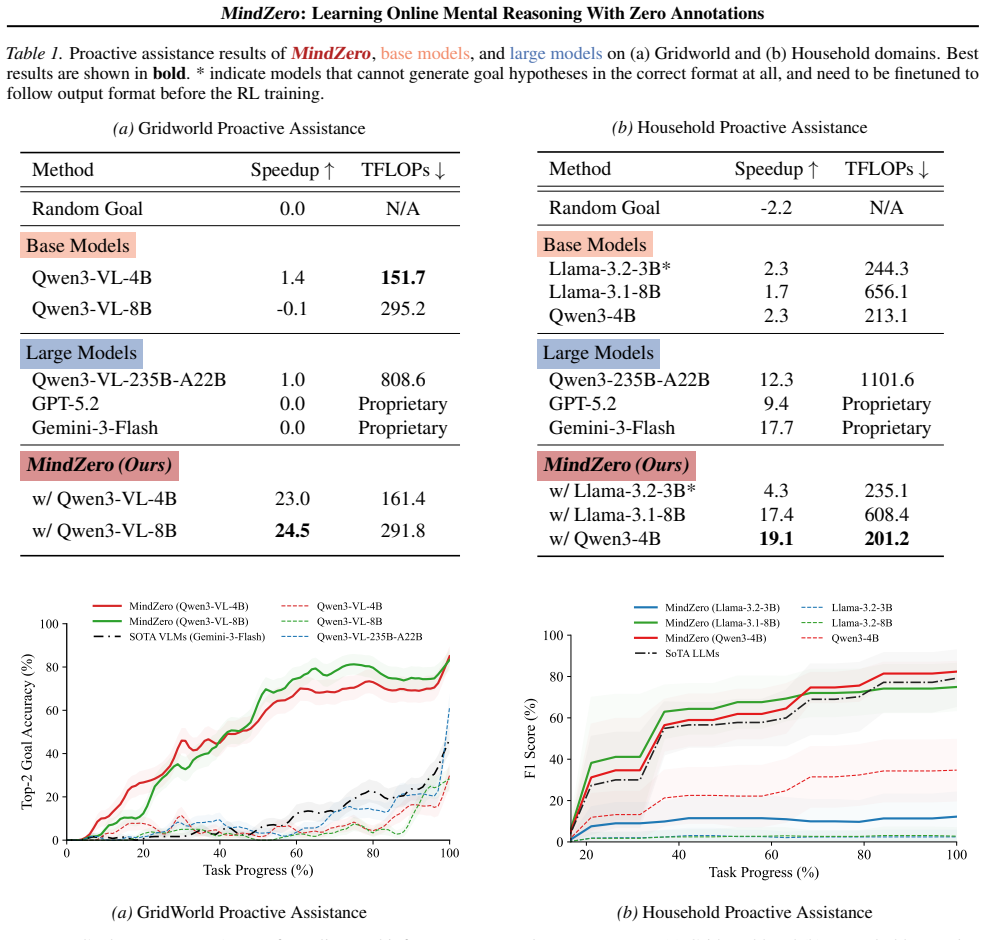
By rewarding an MLLM for producing mental-state hypotheses that maximize the likelihood of observed actions under an external planner, the model acquires the capacity for efficient, uncertainty-aware online Theory of Mind inference; after training it performs this reasoning in one pass and outperforms both base MLLMs and model-based baselines on accuracy and latency in gridworld navigation and household assistance tasks.
What carries the argument
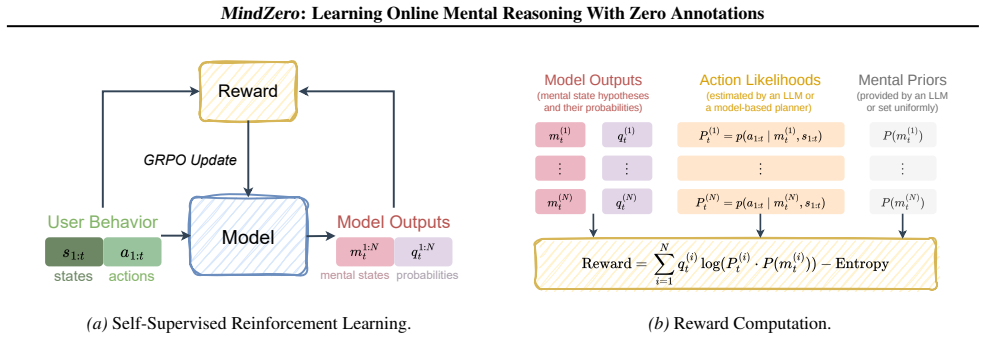
The self-supervised reward that scores each generated mental-state hypothesis by the likelihood it assigns to the observed action sequence under a fixed planner, thereby distilling model-based ToM into the language model parameters.
If this is right
- Model-based ToM search can be internalized into fast single-pass inference without loss of accuracy.
- Online mental-state inference with uncertainty updates becomes feasible at real-time speeds.
- Robust ToM performance is achievable in domains where ground-truth mental annotations are unavailable.
- Plain MLLMs alone remain insufficient for reliable mental reasoning in assistance settings.
Where Pith is reading between the lines
- The same reward structure could be applied to train models on other implicit-reasoning tasks that lack direct labels.
- Scaling the approach to larger models may reduce the annotation burden for aligning AI with human intentions.
- Success in simulated environments suggests testing whether the internalized reasoning transfers to physical robot assistance without retraining.
Load-bearing premise
That an external planner's likelihood estimates will steer the model toward correct mental inferences rather than simply copying the planner's own errors or biases.
What would settle it
Train MindZero with a deliberately inaccurate planner on a held-out domain and measure whether the resulting model predicts actions worse than the untrained MLLM or the model-based baseline.
Figures


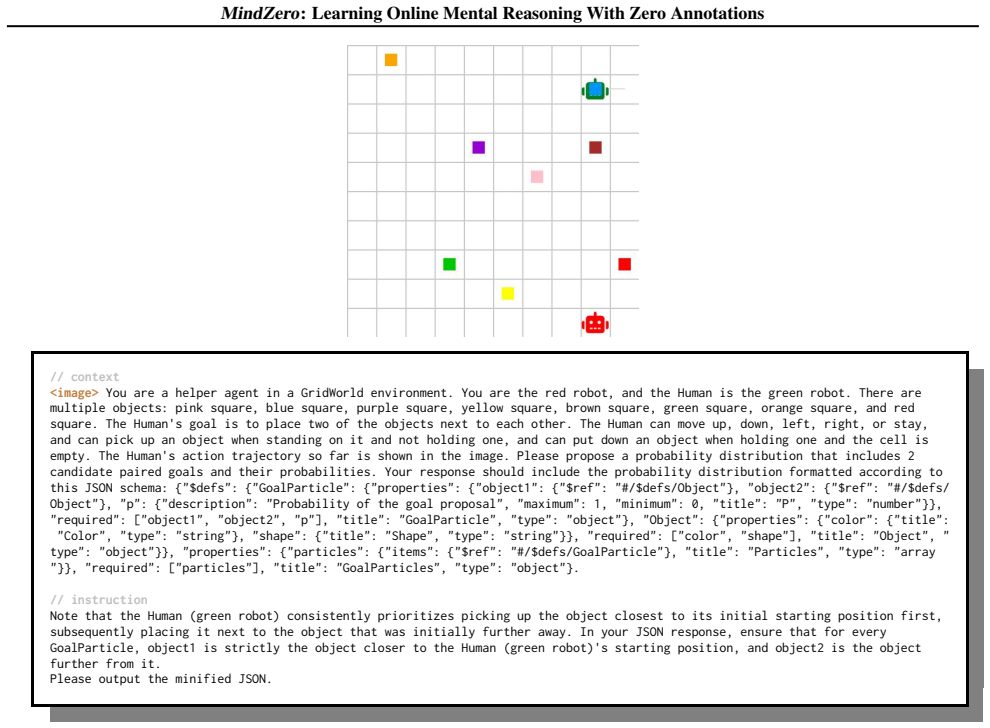


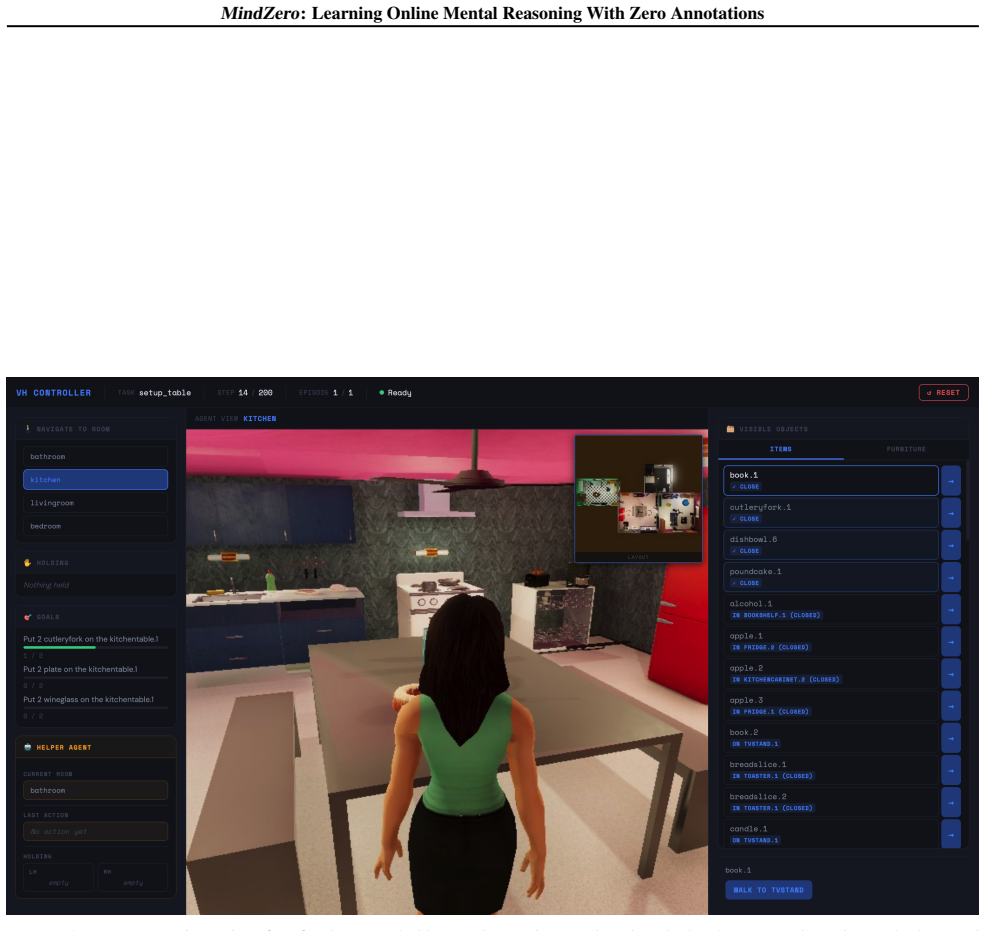

read the original abstract
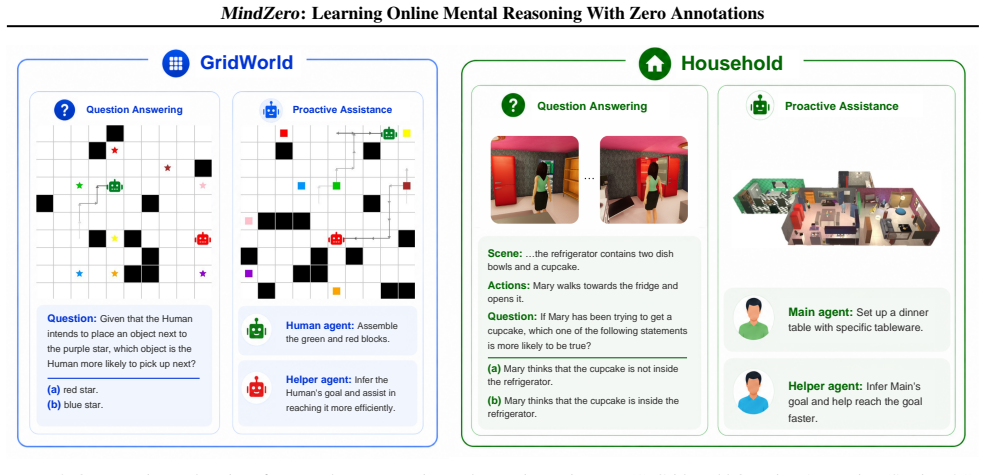
Effective real-world assistance requires AI agents with robust Theory of Mind (ToM): inferring human mental states from their behavior. Despite recent advances, several key challenges remain, including (1) online inference with robust uncertainty updates over multiple hypotheses; (2) efficient reasoning suitable for real-time assistance; and (3) the lack of ground-truth mental state annotations in real-world domains. We address these challenges by introducing MindZero, a self-supervised reinforcement learning framework that trains multimodal large language models (MLLMs) for efficient and robust online mental reasoning. During training, the model is rewarded for generating mental state hypotheses that maximize the likelihood of observed actions estimated by a planner, similar to model-based ToM reasoning. This method thus eliminates the need for explicit mental state annotations. After training, MindZero internalizes model-based reasoning into fast single-pass inference. We evaluate MindZero against baselines across challenging mental reasoning and AI assistance tasks in gridworld and household domains. We found that LLMs alone are insufficient; model-based methods improve accuracy but are slow, costly, and limited by backbone MLLM capacity. In contrast, MindZero enhances MLLMs' intrinsic ToM ability and significantly outperforms model-based methods in both accuracy and efficiency, showing that mental reasoning can be effectively learned as a self-supervised skill.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MindZero, a self-supervised reinforcement learning framework that trains multimodal LLMs for online Theory of Mind reasoning without ground-truth annotations. During training, the model generates mental-state hypotheses that are rewarded according to how well they maximize the likelihood of observed actions under an external planner; after training, this is internalized into fast single-pass inference. The paper claims that this approach enhances MLLMs' intrinsic ToM ability and significantly outperforms both standalone LLMs and model-based methods in accuracy and efficiency on gridworld and household mental-reasoning and assistance tasks.
Significance. If the empirical results hold with proper controls and the internalized policy demonstrably exceeds the planner on uncertain cases, the work would be significant for annotation-free, real-time ToM in AI assistance agents. It directly targets the three stated challenges (online multi-hypothesis uncertainty, efficiency, and lack of annotations) by converting model-based reasoning into a learned single-pass skill.
major comments (2)
- [Abstract] Abstract: the central claim that MindZero 'significantly outperforms model-based methods in both accuracy and efficiency' is unsupported by any metrics, baselines, statistical tests, error bars, or experimental controls, making the headline empirical result impossible to evaluate.
- [Abstract] Abstract (training-loop description): the reward is defined solely as maximization of observed-action likelihood under an external planner, with no described term that penalizes over-reliance on the planner or encourages explicit multi-hypothesis belief maintenance after the single forward pass; this is load-bearing for the claim of 'robust online uncertainty updates' and 'enhanced intrinsic ToM' rather than planner distillation.
minor comments (1)
- [Abstract] Abstract: the phrasing 'limited by backbone MLLM capacity' is unclear and should be expanded to specify whether this refers to context length, inference speed, or representational limits in the reported experiments.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below and have prepared revisions to improve clarity and strengthen the presentation of empirical support.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that MindZero 'significantly outperforms model-based methods in both accuracy and efficiency' is unsupported by any metrics, baselines, statistical tests, error bars, or experimental controls, making the headline empirical result impossible to evaluate.
Authors: The abstract summarizes results presented in Sections 4 and 5, which include direct quantitative comparisons of accuracy (task success rates on mental-reasoning and assistance tasks) and efficiency (inference latency and compute) against both standalone MLLM baselines and model-based planners, across gridworld and household environments. We agree the abstract would benefit from explicit reference to these controls. In revision we will add error bars, statistical significance tests, and a brief parenthetical note in the abstract directing readers to the experimental section. revision: yes
-
Referee: [Abstract] Abstract (training-loop description): the reward is defined solely as maximization of observed-action likelihood under an external planner, with no described term that penalizes over-reliance on the planner or encourages explicit multi-hypothesis belief maintenance after the single forward pass; this is load-bearing for the claim of 'robust online uncertainty updates' and 'enhanced intrinsic ToM' rather than planner distillation.
Authors: The reward is intentionally defined as the planner likelihood to supply a self-supervised training signal without annotations. The RL objective trains the MLLM to emit hypotheses that would have been useful to the planner; once internalized, the single forward pass produces outputs that exceed the planner on held-out cases, indicating the model has learned to maintain and select among hypotheses internally. We acknowledge the absence of an explicit penalty term for planner dependence. In revision we will add an ablation and analysis subsection demonstrating that the learned policy exhibits multi-hypothesis behavior and uncertainty calibration without access to the planner at inference time. revision: partial
Circularity Check
No circularity: external planner provides independent reward signal; internalization is standard distillation without self-referential reduction
full rationale
The described training loop rewards MLLM hypotheses using likelihoods from a separate external planner; after training the model performs single-pass inference. This does not match any enumerated circularity pattern: the planner is not defined in terms of the MLLM output, no parameter is fitted on a subset and then relabeled as a prediction of a closely related quantity, and no self-citation chain or imported uniqueness theorem is invoked to force the result. The derivation therefore remains self-contained against the external planner benchmark.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2407.07086 , year=
Hypothetical minds: Scaffolding theory of mind for multi-agent tasks with large language models , author=. arXiv preprint arXiv:2407.07086 , year=
-
[2]
2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , pages=
GOMA: Proactive embodied cooperative communication via goal-oriented mental alignment , author=. 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , pages=. 2024 , organization=
2024
-
[3]
arXiv preprint arXiv:2510.23495 , year=
Coopera: Continual open-ended human-robot assistance , author=. arXiv preprint arXiv:2510.23495 , year=
-
[4]
arXiv preprint arXiv:2407.06762 , year=
Explicit modelling of theory of mind for belief prediction in nonverbal social interactions , author=. arXiv preprint arXiv:2407.06762 , year=
-
[5]
Advances in neural information processing systems , volume=
On the utility of learning about humans for human-ai coordination , author=. Advances in neural information processing systems , volume=
-
[6]
arXiv preprint arXiv:2303.00413 , year=
Automated task-time interventions to improve teamwork using imitation learning , author=. arXiv preprint arXiv:2303.00413 , year=
-
[7]
2024 IEEE International Conference on Robotics and Automation (ICRA) , pages=
Risk-Bounded Online Team Interventions via Theory of Mind , author=. 2024 IEEE International Conference on Robotics and Automation (ICRA) , pages=. 2024 , organization=
2024
-
[8]
arXiv preprint arXiv:2509.05091 , year=
ProToM: Promoting Prosocial Behaviour via Theory of Mind-Informed Feedback , author=. arXiv preprint arXiv:2509.05091 , year=
-
[9]
Proceedings of the 13th Annual Meeting of the Special Interest Group on Discourse and Dialogue , pages=
Towards mediating shared perceptual basis in situated dialogue , author=. Proceedings of the 13th Annual Meeting of the Special Interest Group on Discourse and Dialogue , pages=
-
[10]
Proceedings of the 2014 ACM/IEEE international conference on Human-robot interaction , pages=
Collaborative effort towards common ground in situated human-robot dialogue , author=. Proceedings of the 2014 ACM/IEEE international conference on Human-robot interaction , pages=
2014
-
[11]
Executing instructions in situated collaborative interactions , author=. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP) , pages=
2019
-
[12]
Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , pages=
Collaborative dialogue in Minecraft , author=. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , pages=
-
[13]
Proceedings of the 58th annual meeting of the association for computational linguistics , pages=
Learning to execute instructions in a Minecraft dialogue , author=. Proceedings of the 58th annual meeting of the association for computational linguistics , pages=
-
[14]
Watch-And-Help: A Challenge for Social Perception and Human-AI Collaboration , author=
-
[15]
2023 , organization=
NOPA: Neurally-guided Online Probabilistic Assistance for Building Socially Intelligent Home Assistants , author=. 2023 , organization=
2023
-
[16]
arXiv preprint arXiv:2510.21903 , year=
Tom-swe: User mental modeling for software engineering agents , author=. arXiv preprint arXiv:2510.21903 , year=
-
[17]
Learning to cooperate with humans using generative agents , author=
-
[18]
Neural amortized inference for nested multi-agent reasoning , author=
-
[19]
Realwebassist: A benchmark for long-horizon web assistance with real-world users , author=
-
[20]
arXiv preprint arXiv:2402.17930 , year=
Pragmatic instruction following and goal assistance via cooperative language-guided inverse planning , author=. arXiv preprint arXiv:2402.17930 , year=
-
[21]
Towards mutual theory of mind in human-ai interaction: How language reflects what students perceive about a virtual teaching assistant , author=
-
[22]
2022 , organization=
Proactive robotic assistance via theory of mind , author=. 2022 , organization=
2022
-
[23]
Scaling Laws for Neural Language Models
Scaling laws for neural language models , author=. arXiv preprint arXiv:2001.08361 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[24]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Nature , volume=
DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning , author=. Nature , volume=. 2025 , publisher=
2025
-
[26]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Qwen3-vl technical report , author=. arXiv preprint arXiv:2511.21631 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
A neural probabilistic language model , author=
-
[29]
2018 , publisher=
Improving language understanding by generative pre-training , author=. 2018 , publisher=
2018
-
[30]
Decision transformer: Reinforcement learning via sequence modeling , author=
-
[31]
Auto-encoding variational bayes , author=
-
[32]
arXiv e-prints , pages=
The llama 3 herd of models , author=. arXiv e-prints , pages=
-
[33]
Pattern recognition and machine learning , author=
-
[34]
Autotom: Scaling model-based mental inference via automated agent modeling , author=
-
[35]
Mmtom-qa: Multimodal theory of mind question answering , author=
-
[36]
Muma-tom: Multi-modal multi-agent theory of mind , author=
-
[37]
Hypothesis-Driven Theory-of-Mind Reasoning for Large Language Models , author=
-
[38]
arXiv preprint arXiv:2412.12175 , year=
Explore theory of mind: Program-guided adversarial data generation for theory of mind reasoning , author=. arXiv preprint arXiv:2412.12175 , year=
-
[39]
Overcoming Multi-step Complexity in Multimodal Theory-of-Mind Reasoning: A Scalable Bayesian Planner , author=
-
[40]
2018 , organization=
Machine theory of mind , author=. 2018 , organization=
2018
-
[41]
Minding Language Models’(Lack of) Theory of Mind: A Plug-and-Play Multi-Character Belief Tracker , author=
-
[42]
Perceptions to Beliefs: Exploring Precursory Inferences for Theory of Mind in Large Language Models , author=
-
[43]
TimeToM: Temporal Space is the Key to Unlocking the Door of Large Language Models’ Theory-of-Mind , author=
-
[44]
Cognition , volume=
Action understanding as inverse planning , author=. Cognition , volume=. 2009 , publisher=
2009
-
[45]
Help or hinder: Bayesian models of social goal inference , author=
-
[46]
Nature Human Behaviour , volume=
Rational quantitative attribution of beliefs, desires and percepts in human mentalizing , author=. Nature Human Behaviour , volume=. 2017 , publisher=
2017
-
[47]
Online bayesian goal inference for boundedly rational planning agents , author=
-
[48]
Phase: Physically-grounded abstract social events for machine social perception , author=
-
[49]
2021 , organization=
Agent: A benchmark for core psychological reasoning , author=. 2021 , organization=
2021
-
[50]
arXiv preprint arXiv:2302.08399 , year=
Large language models fail on trivial alterations to theory-of-mind tasks , author=. arXiv preprint arXiv:2302.08399 , year=
-
[51]
Clever hans or neural theory of mind? stress testing social reasoning in large language models , author=
-
[52]
SoMi-ToM: Evaluating Multi-Perspective Theory of Mind in Embodied Social Interactions , author=
-
[53]
Think twice: Perspective-taking improves large language models’ theory-of-mind capabilities , author=
-
[54]
A notion of complexity for theory of mind via discrete world models , author=
-
[55]
The Essence of Contextual Understanding in Theory of Mind: A Study on Question Answering with Story Characters , author=
-
[56]
2024 , organization=
Few-Shot Character Understanding in Movies as an Assessment to Meta-Learning of Theory-of-Mind , author=. 2024 , organization=
2024
-
[57]
Revisiting the evaluation of theory of mind through question answering , author=
-
[58]
Understanding social reasoning in language models with language models , author=
-
[59]
FANToM: A benchmark for stress-testing machine theory of mind in interactions , author=
-
[60]
Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
Hi-tom: A benchmark for evaluating higher-order theory of mind reasoning in large language models , author=. Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
2023
-
[61]
OpenToM: A Comprehensive Benchmark for Evaluating Theory-of-Mind Reasoning Capabilities of Large Language Models , author=
-
[62]
Cognition , volume=
Beliefs about beliefs: Representation and constraining function of wrong beliefs in young children's understanding of deception , author=. Cognition , volume=. 1983 , publisher=
1983
-
[63]
arXiv preprint arXiv:2409.10849 , year=
Pragmatic Embodied Spoken Instruction Following in Human-Robot Collaboration with Theory of Mind , author=. arXiv preprint arXiv:2409.10849 , year=
-
[64]
Collins and Megan Wei and Cedegao E
Lance Ying and Katherine M. Collins and Megan Wei and Cedegao E. Zhang and Tan Zhi-Xuan and Adrian Weller and Joshua B. Tenenbaum and Lionel Wong , booktitle=. The Neuro-Symbolic Inverse Planning Engine (
-
[65]
Neural reasoning about agents’ goals, preferences, and actions , author=
-
[66]
Precog: Prediction conditioned on goals in visual multi-agent settings , author=
-
[67]
arXiv preprint arXiv:2504.01698 , year=
Do Theory of Mind Benchmarks Need Explicit Human-like Reasoning in Language Models? , author=. arXiv preprint arXiv:2504.01698 , year=
-
[68]
arXiv preprint arXiv:2509.19736 , year=
Userrl: Training interactive user-centric agent via reinforcement learning , author=. arXiv preprint arXiv:2509.19736 , year=
-
[69]
Sotopia-
Haofei Yu and Zhengyang Qi and Yining Zhao and Kolby Nottingham and Keyang Xuan and Bodhisattwa Prasad Majumder and Hao Zhu and Paul Pu Liang and Jiaxuan You , booktitle=. Sotopia-
-
[70]
MindCraft: Theory of mind modeling for situated dialogue in collaborative tasks , author=
-
[71]
ToM-SSI: Evaluating Theory of Mind in Situated Social Interactions , author=
-
[72]
arXiv preprint arXiv:2509.25137 , year=
The era of real-world human interaction: Rl from user conversations , author=. arXiv preprint arXiv:2509.25137 , year=
-
[73]
ThoughtTrace: Understanding User Thoughts in Real-World LLM Interactions
ThoughtTrace: Understanding User Thoughts in Real-World LLM Interactions , author=. arXiv preprint arXiv:2605.20087 , year=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.