Dynamics and Representation Structure of Local Approximations to Gradient-Based Learning in Linear Recurrent Neural Networks
Pith reviewed 2026-06-28 19:16 UTC · model grok-4.3
The pith
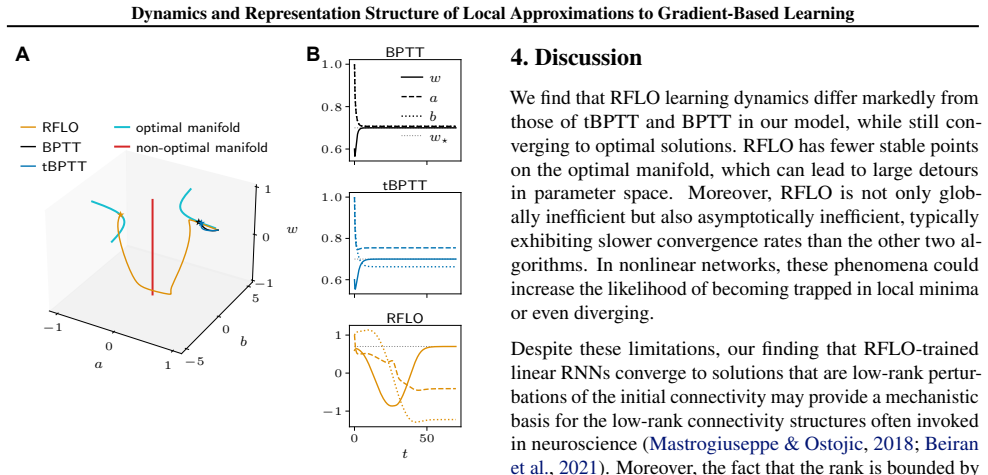
RFLO learning in linear RNNs restricts solutions to low-rank perturbations of initial parameters
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
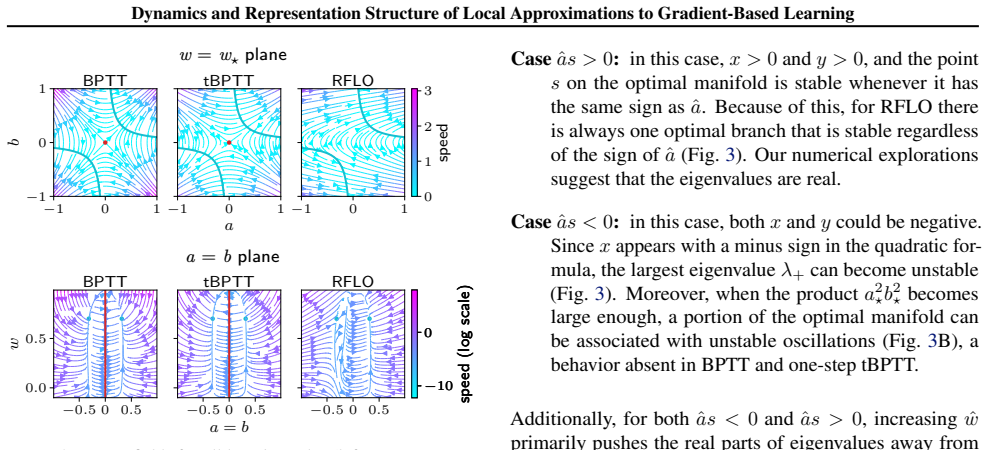
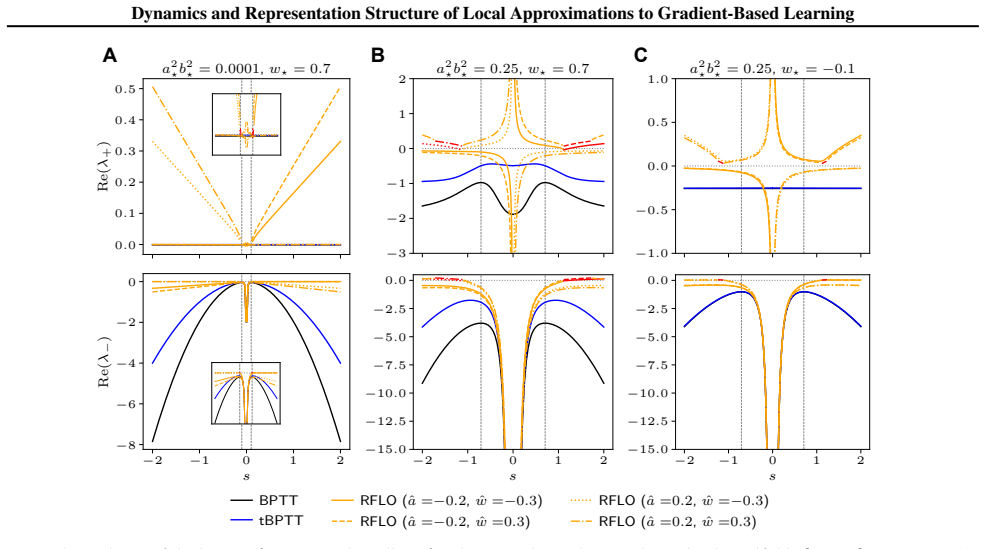
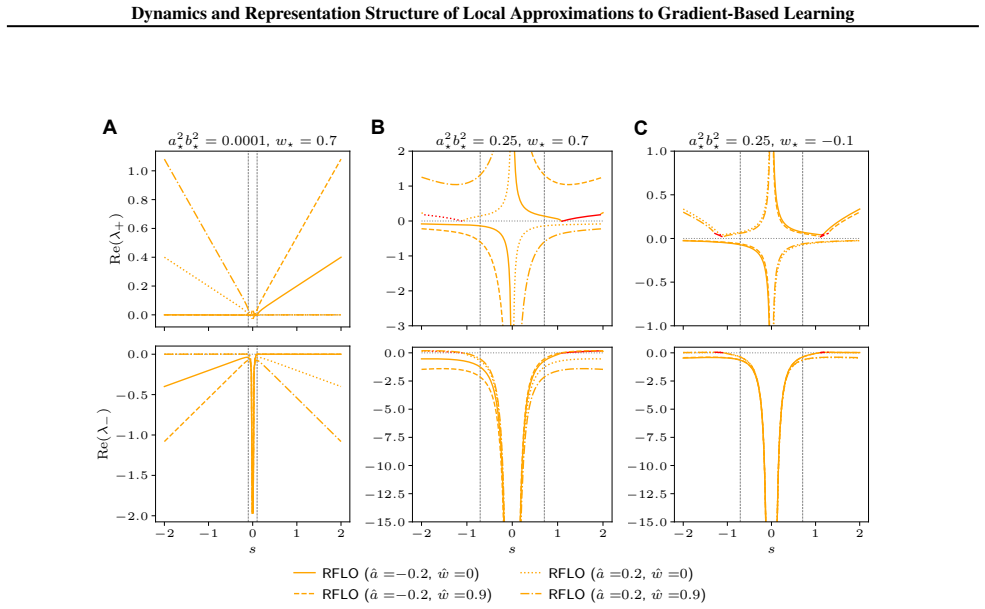
In data-aligned linear RNNs the learning dynamics under RFLO, BPTT and one-step tBPTT exhibit qualitatively distinct behaviour. The solutions learned by RFLO are restricted to low-rank perturbations of the initial parameters, a result which holds beyond the data-aligned setting.
What carries the argument
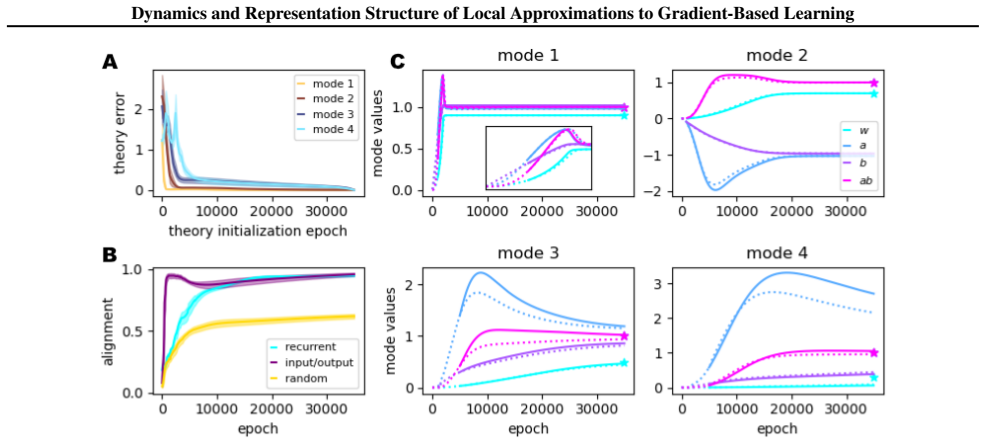
Separation of the RNN into orthogonal modes in the data-aligned linear case, which permits mode-by-mode analysis of the learning dynamics and reveals the low-rank restriction on RFLO solutions
If this is right
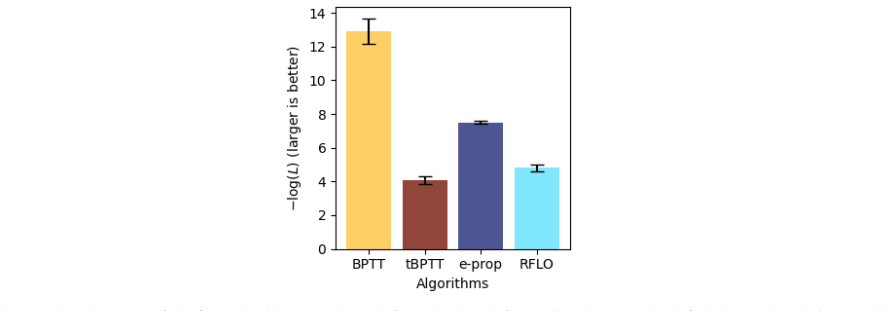
- RFLO exhibits different stability properties and convergence rates than BPTT and one-step tBPTT
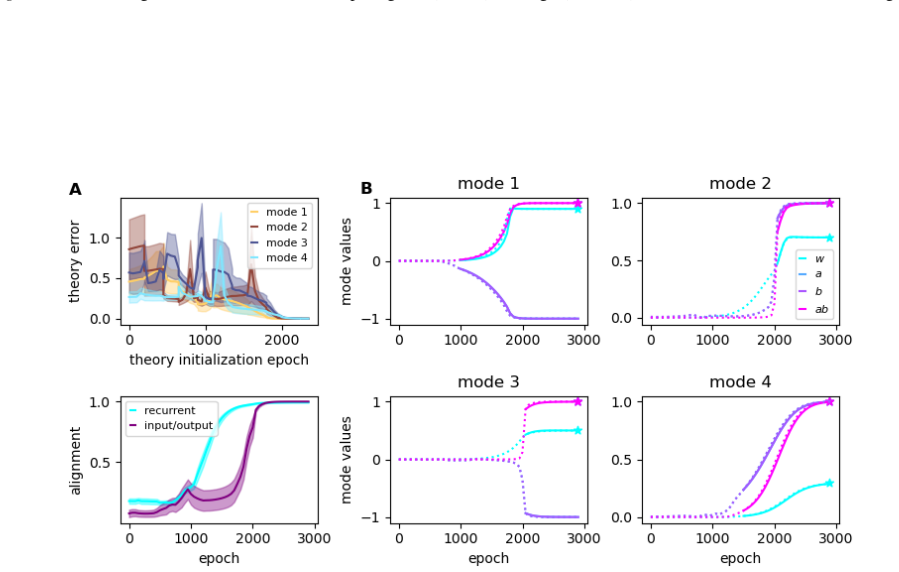
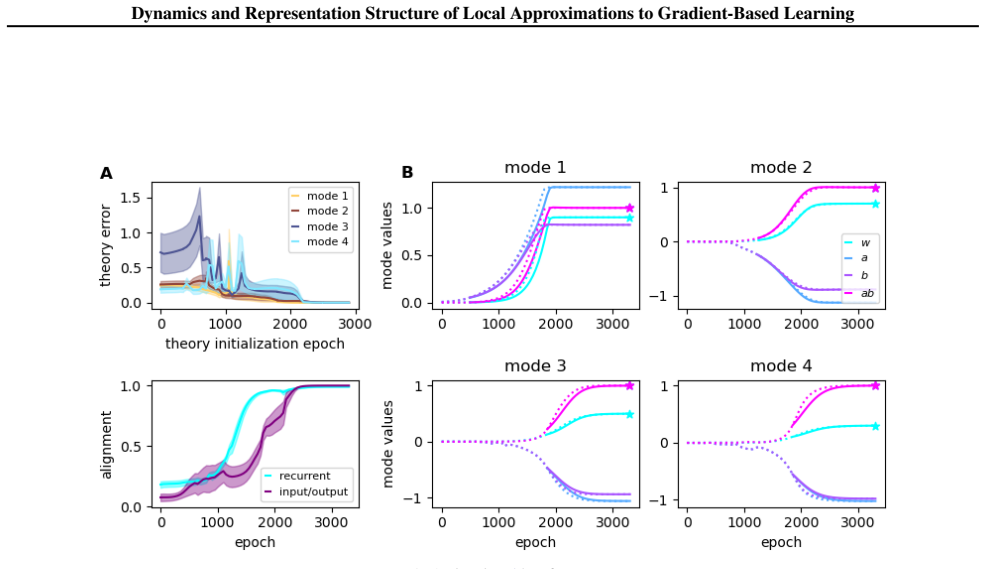
- RFLO solutions cannot reach arbitrary parameters but remain confined to low-rank perturbations around initialization
- The low-rank restriction applies more generally and is not limited to the data-aligned linear setting
- Locality constraints therefore shape both the dynamics and the final representation structure of the learned network
Where Pith is reading between the lines
- The low-rank restriction may limit the tasks that purely local rules can solve without additional mechanisms such as specific initializations
- Hybrid rules that occasionally allow non-local information could be tested to see whether they escape the low-rank constraint
- The result offers a possible explanation for why some biological learning models succeed only on restricted classes of problems
Load-bearing premise
The learning dynamics of these algorithms can be usefully analyzed by separating the RNN into orthogonal modes in the data-aligned linear case
What would settle it
A numerical simulation of RFLO on a data-aligned linear RNN that produces full-rank changes from the initial parameters would falsify the restriction claim
Figures


read the original abstract
Biological and neuromorphic recurrent neural networks (RNNs) are subject to spatial and temporal locality constraints on the information that can plausibly be used during learning. A common strategy to satisfy these constraints is to modify gradient descent by neglecting non-local terms to varying degrees, as in random feedback local online (RFLO) learning and truncated backpropagation through time (tBPTT). However, the learning dynamics of these algorithms, and how they compare with BPTT, remain poorly understood. We apply dynamical systems theory to data-aligned linear RNNs -- whose dynamics can be separated into orthogonal modes -- to compare stationary solutions, stability properties, and convergence rates, finding qualitatively distinct behaviour for RFLO versus BPTT and one-step tBPTT. We further observe that the solutions learned by RFLO are restricted to low-rank perturbations of initial parameters, a result which holds beyond the data-aligned setting. Our work provides analytical insight into how locality constraints shape learning dynamics, with implications for neuroscientific models of learning and alternative optimization approaches for RNNs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript applies dynamical systems theory to data-aligned linear RNNs (whose dynamics separate into orthogonal modes) to analyze and compare the stationary solutions, stability properties, and convergence rates of RFLO, one-step tBPTT, and BPTT. It further claims that RFLO solutions are restricted to low-rank perturbations of the initial parameters, with this low-rank result asserted to hold beyond the data-aligned setting.
Significance. If the dynamical analysis and the low-rank result are rigorously established, the work would provide useful analytical insight into how locality constraints in learning rules shape RNN dynamics, with implications for neuromorphic hardware and neuroscientific models of learning. The separation into orthogonal modes and comparison of qualitative behaviors across algorithms is a constructive application of dynamical systems tools.
major comments (1)
- [Abstract] Abstract: The claim that 'the solutions learned by RFLO are restricted to low-rank perturbations of initial parameters, a result which holds beyond the data-aligned setting' is load-bearing for the paper's contribution yet rests on an unshown extension. The mode-separation analysis is valid only when the input covariance is diagonal in the eigenbasis of the recurrent weights; no separate argument, relaxed derivation, numerical counter-example check, or explicit statement of the relaxed assumptions is supplied for non-aligned covariances or nonlinear networks.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive feedback. We address the single major comment below and will revise the manuscript to clarify the low-rank result.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that 'the solutions learned by RFLO are restricted to low-rank perturbations of initial parameters, a result which holds beyond the data-aligned setting' is load-bearing for the paper's contribution yet rests on an unshown extension. The mode-separation analysis is valid only when the input covariance is diagonal in the eigenbasis of the recurrent weights; no separate argument, relaxed derivation, numerical counter-example check, or explicit statement of the relaxed assumptions is supplied for non-aligned covariances or nonlinear networks.
Authors: The low-rank property follows directly from the structure of the RFLO learning rule itself: each update is a rank-1 perturbation (outer product of the local eligibility trace and the feedback signal) applied to the recurrent weights. This algebraic property of the update does not depend on the input covariance matrix or on the data-aligned assumption used for the orthogonal-mode decomposition. We will add an explicit, short derivation of this fact (valid for arbitrary input covariances in the linear case) to the revised manuscript. The mode-separation analysis is indeed limited to the data-aligned setting, which is already stated in the text; it is used only to obtain closed-form expressions for stability and convergence rates. The manuscript makes no claims about nonlinear networks. revision: yes
Circularity Check
No circularity: derivation applies standard dynamical systems analysis to learning rules without reduction to inputs by construction
full rationale
The paper applies dynamical systems theory to the equations governing RFLO, tBPTT, and BPTT in data-aligned linear RNNs, separating dynamics into orthogonal modes to derive stationary solutions, stability, and convergence rates. The low-rank perturbation observation for RFLO solutions is presented as a direct consequence of those dynamics in the aligned case and asserted to extend more generally, but the provided text contains no self-definitional loops, fitted parameters renamed as predictions, load-bearing self-citations, uniqueness theorems imported from prior author work, smuggled ansatzes, or renamings of known results. The central claims rest on explicit mode decomposition and comparison of the learning rules themselves rather than on quantities defined in terms of the target outputs. This is the most common honest finding for papers whose analysis is self-contained against external dynamical-systems benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Dynamical systems theory can be applied to derive stationary solutions, stability properties, and convergence rates of the learning algorithms in linear RNNs.
- domain assumption Data-aligned linear RNNs allow separation of dynamics into orthogonal modes.
Reference graph
Works this paper leans on
-
[1]
nature , volume=
Context-dependent computation by recurrent dynamics in prefrontal cortex , author=. nature , volume=. 2013 , publisher=
2013
-
[2]
2014 , publisher=
Neuronal dynamics: From single neurons to networks and models of cognition , author=. 2014 , publisher=
2014
-
[3]
Nature communications , volume=
Supervised learning in spiking neural networks with FORCE training , author=. Nature communications , volume=. 2017 , publisher=
2017
-
[4]
Acta Geophysica , volume=
Long short-term memory (LSTM) recurrent neural network for low-flow hydrological time series forecasting , author=. Acta Geophysica , volume=. 2019 , publisher=
2019
-
[5]
Computer Speech & Language , volume=
A survey on the application of recurrent neural networks to statistical language modeling , author=. Computer Speech & Language , volume=. 2015 , publisher=
2015
-
[6]
Nature Reviews Neuroscience , volume=
Reconstructing computational system dynamics from neural data with recurrent neural networks , author=. Nature Reviews Neuroscience , volume=. 2023 , publisher=
2023
-
[7]
Journal of Machine Learning Research , volume=
Approximation and optimization theory for linear continuous-time recurrent neural networks , author=. Journal of Machine Learning Research , volume=
-
[8]
Curl Descent: Non-Gradient Learning Dynamics with Sign-Diverse Plasticity
Curl Descent: Non-Gradient Learning Dynamics with Sign-Diverse Plasticity , author=. arXiv preprint arXiv:2510.02765 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
ArXiv , pages=
How connectivity structure shapes rich and lazy learning in neural circuits , author=. ArXiv , pages=
-
[10]
Advances in Neural Information Processing Systems , volume=
Beyond accuracy: generalization properties of bio-plausible temporal credit assignment rules , author=. Advances in Neural Information Processing Systems , volume=
-
[11]
International Conference on Learning Representations , year=
The influence of learning rule on representation dynamics in wide neural networks , author=. International Conference on Learning Representations , year=
-
[12]
Advances in neural information processing systems , volume=
On the convergence rate of training recurrent neural networks , author=. Advances in neural information processing systems , volume=
-
[13]
Advances in neural information processing systems , volume=
The interplay between randomness and structure during learning in RNNs , author=. Advances in neural information processing systems , volume=
-
[14]
arXiv preprint arXiv:2506.06904 , year=
Can Biologically Plausible Temporal Credit Assignment Rules Match BPTT for Neural Similarity? E-prop as an Example , author=. arXiv preprint arXiv:2506.06904 , year=
-
[15]
Nature Communications , year=
Backpropagation through space, time and the brain , author=. Nature Communications , year=
-
[16]
International Conference on Learning Representations , year=
Kernel rnn learning (kernl) , author=. International Conference on Learning Representations , year=
-
[17]
Advances in Neural Information Processing Systems , volume=
Recurrent neural networks: vanishing and exploding gradients are not the end of the story , author=. Advances in Neural Information Processing Systems , volume=
-
[18]
arXiv preprint arXiv:2111.00034 , year=
Neural networks as kernel learners: The silent alignment effect , author=. arXiv preprint arXiv:2111.00034 , year=
-
[19]
Nature communications , volume=
Neural heterogeneity promotes robust learning , author=. Nature communications , volume=. 2021 , publisher=
2021
-
[20]
Proceedings of the National Academy of Sciences , volume=
Neural heterogeneity controls computations in spiking neural networks , author=. Proceedings of the National Academy of Sciences , volume=. 2024 , publisher=
2024
-
[21]
Advances in neural information processing systems , volume=
Weighted sums of random kitchen sinks: Replacing minimization with randomization in learning , author=. Advances in neural information processing systems , volume=
-
[22]
science , volume=
Harnessing nonlinearity: Predicting chaotic systems and saving energy in wireless communication , author=. science , volume=. 2004 , publisher=
2004
-
[23]
Conference on Learning Theory , pages=
Kernel and rich regimes in overparametrized models , author=. Conference on Learning Theory , pages=. 2020 , organization=
2020
-
[24]
Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
Grokking: Generalization beyond overfitting on small algorithmic datasets , author=. arXiv preprint arXiv:2201.02177 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Advances in neural information processing systems , volume=
Formalizing locality for normative synaptic plasticity models , author=. Advances in neural information processing systems , volume=
-
[26]
Neural Computation , volume=
Winning the lottery with neural connectivity constraints: Faster learning across cognitive tasks with spatially constrained sparse rnns , author=. Neural Computation , volume=. 2023 , publisher=
2023
-
[27]
Proceedings of the National Academy of Sciences , volume=
Multitasking via baseline control in recurrent neural networks , author=. Proceedings of the National Academy of Sciences , volume=. 2023 , publisher=
2023
-
[28]
International Conference on Learning Representations , volume=
Expressivity of neural networks with random weights and learned biases , author=. International Conference on Learning Representations , volume=
-
[29]
Neuron , volume=
Linking connectivity, dynamics, and computations in low-rank recurrent neural networks , author=. Neuron , volume=. 2018 , publisher=
2018
-
[30]
Neural computation , volume=
Shaping dynamics with multiple populations in low-rank recurrent networks , author=. Neural computation , volume=. 2021 , publisher=
2021
-
[31]
Learning dynamics in linear recurrent neural networks , year =
Proca, Alexandra Maria and Domin. Learning dynamics in linear recurrent neural networks , year =. Forty-second International Conference on Machine Learning , date-added =
-
[32]
International Conference on Learning Representations , title =
Gu, Albert and Goel, Karan and R. International Conference on Learning Representations , title =. 2022 , bdsk-url-1 =
2022
-
[33]
Kunin, Daniel and Ravent. Get rich quick: exact solutions reveal how unbalanced initializations promote rapid feature learning , urldate =. 2024 , bdsk-url-1 =. doi:10.48550/arXiv.2406.06158 , file =
-
[34]
, date-added =
Zenke, Friedemann and Neftci, Emre O. , date-added =. Brain-. Proceedings of the IEEE , keywords =. 2021 , bdsk-url-1 =
2021
-
[35]
Backpropagation through time and the brain , urldate =
Lillicrap, Timothy P and Santoro, Adam , date-added =. Backpropagation through time and the brain , urldate =. Current Opinion in Neurobiology , language =. 2019 , bdsk-url-1 =
2019
-
[36]
Deep Learning , year =
Ian Goodfellow and Yoshua Bengio and Aaron Courville , date-added =. Deep Learning , year =
-
[37]
The study of plasticity has always been about gradients , urldate =
Richards, Blake Aaron and Kording, Konrad Paul , date-added =. The study of plasticity has always been about gradients , urldate =. The Journal of Physiology , keywords =. 2023 , bdsk-url-1 =
2023
-
[38]
and Gerstner, Wulfram , date-added =
Hennequin, Guillaume and Vogels, Tim P. and Gerstner, Wulfram , date-added =. Optimal. Neuron , language =. 2014 , bdsk-url-1 =
2014
-
[39]
Lara, A. H. and Cunningham, J. P. and Churchland, M. M. , copyright =. Different population dynamics in the supplementary motor area and motor cortex during reaching , urldate =. Nature Communications , keywords =. 2018 , bdsk-url-1 =
2018
-
[40]
Logiaco, Laureline and Abbott, L. F. and Escola, Sean , date-added =. Thalamic control of cortical dynamics in a model of flexible motor sequencing , urldate =. Cell Reports , keywords =. 2021 , bdsk-url-1 =
2021
-
[41]
A neural network that finds a naturalistic solution for the production of muscle activity , urldate =
Sussillo, David and Churchland, Mark M and Kaufman, Matthew T and Shenoy, Krishna V , date-added =. A neural network that finds a naturalistic solution for the production of muscle activity , urldate =. Nature Neuroscience , language =. 2015 , bdsk-url-1 =
2015
-
[42]
International Conference on Learning Representations , volume=
From lazy to rich: Exact learning dynamics in deep linear networks , author=. International Conference on Learning Representations , volume=
-
[43]
Exact learning dynamics of deep linear networks with prior knowledge , volume =
Braun, Lukas and Domin. Exact learning dynamics of deep linear networks with prior knowledge , volume =. Advances in Neural Information Processing Systems , language =. 2022 , bdsk-url-1 =
2022
-
[44]
Tran, Ke and Bisazza, Arianna and Monz, Christof , booktitle =. The. 2018 , bdsk-url-1 =
2018
-
[45]
Findings of the association for computational linguistics: EMNLP 2023 , pages=
Rwkv: Reinventing rnns for the transformer era , author=. Findings of the association for computational linguistics: EMNLP 2023 , pages=
2023
-
[46]
Transformers are
Katharopoulos, Angelos and Vyas, Apoorv and Pappas, Nikolaos and Fleuret, Fran. Transformers are. Proceedings of the 37th. 2020 , bdsk-url-1 =
2020
-
[47]
A solution to the learning dilemma for recurrent networks of spiking neurons , volume =
Bellec, Guillaume and Scherr, Franz and Subramoney, Anand and Hajek, Elias and Salaj, Darjan and Legenstein, Robert and Maass, Wolfgang , copyright =. A solution to the learning dilemma for recurrent networks of spiking neurons , volume =. Nature Communications , language =. 2020 , bdsk-url-1 =
2020
-
[48]
Zico and Tibshirani, Ryan J
Ali, Alnur and Kolter, J. Zico and Tibshirani, Ryan J. , booktitle =. A. 2019 , bdsk-url-1 =
2019
-
[49]
Grossberg, Stephen , date-added =. Competitive learning:. Cognitive Science , language =. 1987 , bdsk-url-1 =. doi:10.1016/S0364-0213(87)80025-3 , file =
-
[50]
Gradient
Hardt, Moritz and Ma, Tengyu and Recht, Benjamin , date-added =. Gradient. Journal of Machine Learning Research , number =. 2018 , bdsk-url-1 =
2018
-
[51]
and Cownden, Daniel and Tweed, Douglas B
Lillicrap, Timothy P. and Cownden, Daniel and Tweed, Douglas B. and Akerman, Colin J. , copyright =. Random synaptic feedback weights support error backpropagation for deep learning , urldate =. Nature Communications , language =. 2016 , bdsk-url-1 =
2016
-
[52]
and Santoro, Adam and Marris, Luke and Akerman, Colin J
Lillicrap, Timothy P. and Santoro, Adam and Marris, Luke and Akerman, Colin J. and Hinton, Geoffrey , date-added =. Backpropagation and the brain , urldate =. Nature Reviews Neuroscience , language =. 2020 , bdsk-url-1 =
2020
-
[53]
Exact learning dynamics of deep linear networks with prior knowledge , volume =
Domin. Exact learning dynamics of deep linear networks with prior knowledge , volume =. Journal of Statistical Mechanics: Theory and Experiment , language =. 2023 , bdsk-url-1 =
2023
-
[54]
Recurrent neural networks as versatile tools of neuroscience research , volume =
Barak, Omri , date-added =. Recurrent neural networks as versatile tools of neuroscience research , volume =. Current Opinion in Neurobiology , pages =. 2017 , bdsk-url-1 =
2017
-
[55]
Exact solutions to the nonlinear dynamics of learning in deep linear neural networks
Saxe, Andrew M. and McClelland, James L. and Ganguli, Surya , date-added =. Exact solutions to the nonlinear dynamics of learning in deep linear neural networks , urldate =. arXiv:1312.6120 [cond-mat, q-bio, stat] , keywords =. 2014 , bdsk-url-1 =
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[56]
and McClelland, James L
Saxe, Andrew M. and McClelland, James L. and Ganguli, Surya , date-added =. A mathematical theory of semantic development in deep neural networks , urldate =. Proceedings of the National Academy of Sciences , number =. 2019 , bdsk-url-1 =
2019
-
[57]
Local online learning in recurrent networks with random feedback , urldate =
Murray, James M , date-added =. Local online learning in recurrent networks with random feedback , urldate =. eLife , keywords =. 2019 , bdsk-url-1 =
2019
-
[58]
and Zipser, David , date-added =
Williams, Ronald J. and Zipser, David , date-added =. A. Neural Computation , language =. 1989 , bdsk-url-1 =
1989
-
[59]
, date-added =
Werbos, P.J. , date-added =. Backpropagation through time: what it does and how to do it , volume =. Proceedings of the IEEE , keywords =. 1990 , bdsk-url-1 =
1990
-
[60]
and Peng, Jing , date-added =
Williams, Ronald J. and Peng, Jing , date-added =. An. Neural Computation , language =. 1990 , bdsk-url-1 =
1990
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.