KISS: Keeping it Simple and Slotted when Learning to Communicate over Wireless
Pith reviewed 2026-06-28 19:35 UTC · model grok-4.3
The pith
Decentralized machine learning agents learn to achieve near-optimal efficiency and fairness in wireless random channel access.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
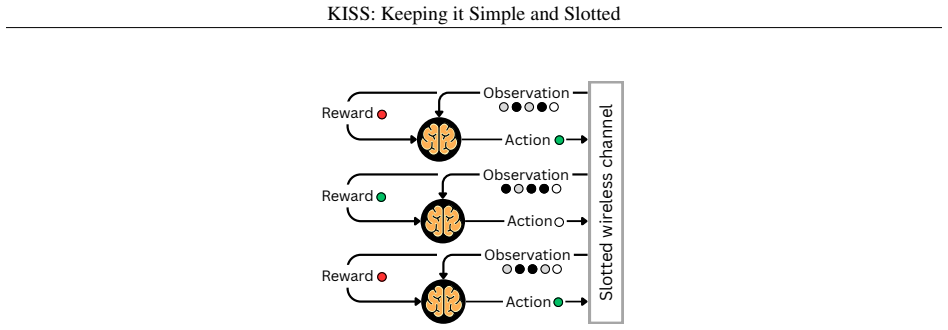
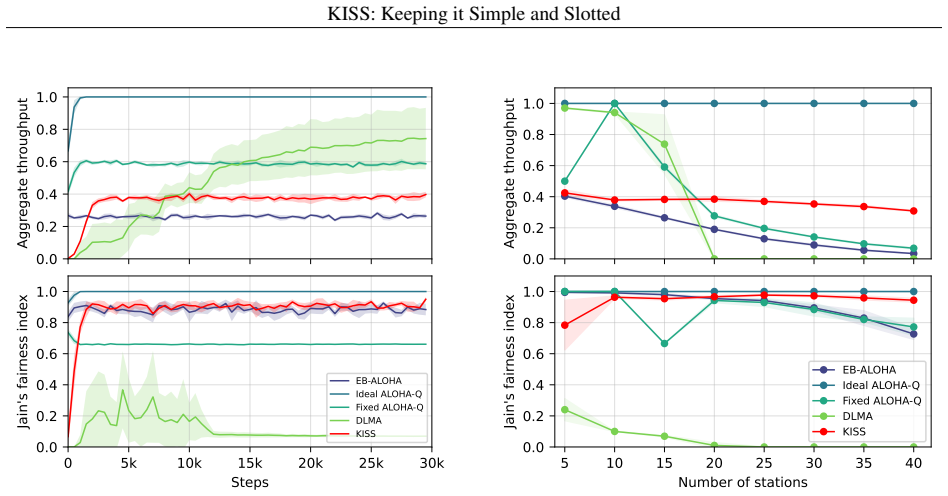
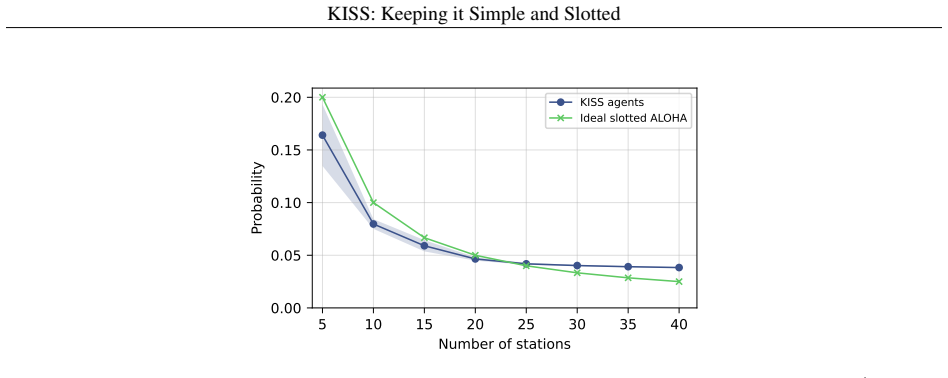
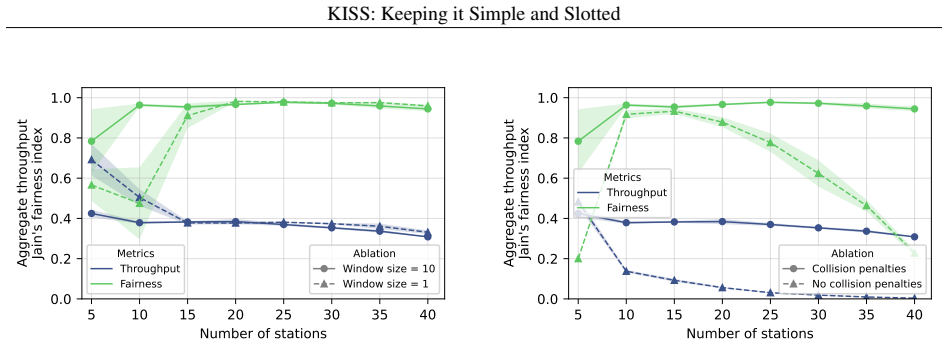
Fully online, independent DDQN agents with Bayesian inference, operating over a slotted channel without any coordination, learn access strategies that approach theoretical efficiency limits while maintaining fairness; ablation studies show this behavior reduces to slotted ALOHA with a dynamically tuned transmission probability.
What carries the argument
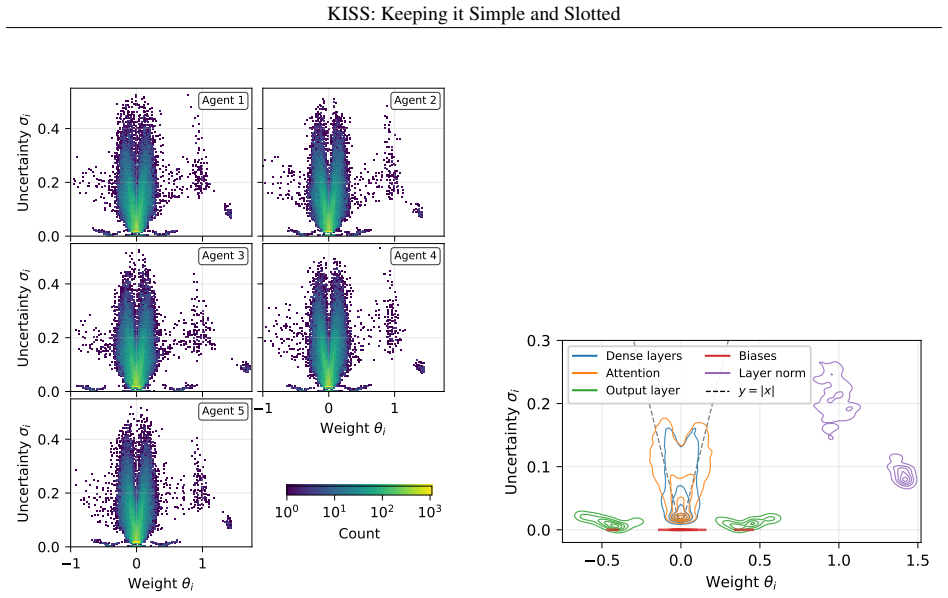
Off-policy Double Deep Q-Network with Bayesian inference that lets each agent estimate its own transmission probability from local observations alone.
If this is right
- No pre-training, central controller, or inter-agent messages are required for the method to operate.
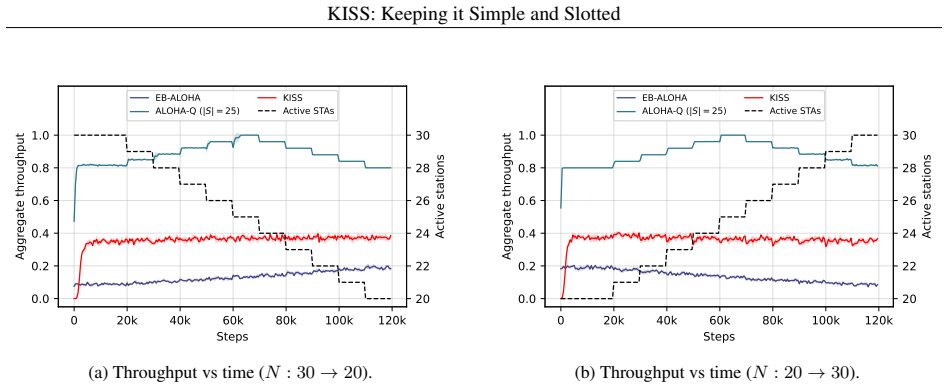
- The learned policy automatically adjusts its transmission probability as the number of active nodes changes.
- Fairness and efficiency hold across a range of network loads in the simulated environment.
- The final behavior is simple enough to be described as dynamic slotted ALOHA rather than an opaque neural policy.
Where Pith is reading between the lines
- If the simulation model is extended with realistic timing jitter, the same training procedure might produce a different adjustment rule.
- The resemblance to slotted ALOHA suggests the learning process rediscovers a known optimum rather than inventing an entirely new mechanism.
- Deployment on real radios would first require verifying that local observations remain sufficient when collisions are not perfectly observable.
Load-bearing premise
The slotted-channel simulation used for training captures all essential dynamics of real wireless random access.
What would settle it
Running the learned policy on hardware or in a simulator that includes hidden terminals and capture effects, then measuring whether throughput or fairness drops below the simulated levels.
Figures
read the original abstract
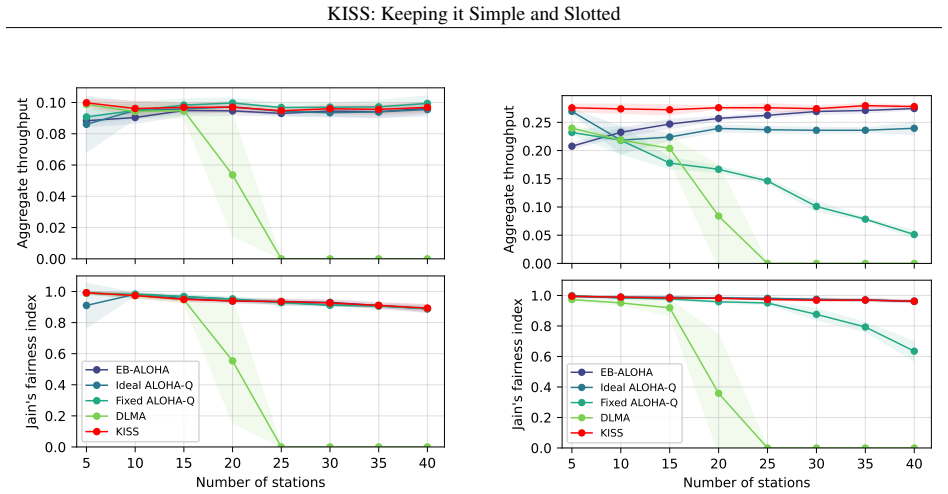
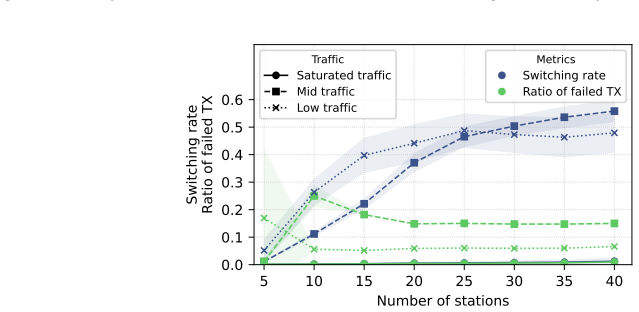
A long-standing challenge in distributed wireless systems is ensuring efficient and fair random channel access. Existing solutions often address specific constraints related to timing, periodicity, or centralization, but they typically rely on fixed heuristics. Motivated by recent advances in machine learning (ML), we investigate whether ML agents can autonomously learn efficient and fair access strategies, and whether such learning can offer new insights into medium access control (MAC) design. Rather than proposing a deployable protocol, our aim is to examine whether decentralized learning can rediscover or approximate theoretically efficient random-access mechanisms under minimal assumptions. To this end, we deploy an off-policy Double Deep Q-Network (DDQN) with Bayesian inference to train agents operating over a slotted channel. The resulting method is fully online (no pre-training), fully distributed (independent multi-agent learners), stochastic (non-periodic), and requires no coordination or explicit communication. Extensive simulations show that the learned strategy adapts to varying network conditions and achieves near-theoretical efficiency while maintaining fairness. Ablation studies further reveal that the learned behavior resembles slotted ALOHA with a dynamically adjusted transmission probability, leading us to refer to the method as KISS: Keeping It Simple and Slotted.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript investigates whether decentralized machine learning agents can learn efficient and fair random channel access strategies in a minimal slotted wireless channel model. Using an off-policy Double Deep Q-Network (DDQN) augmented with Bayesian inference, the agents operate fully online and distributed without pre-training, coordination, or explicit communication. Simulations indicate that the learned policy adapts to varying network conditions, achieves near-theoretical efficiency while preserving fairness, and observationally resembles slotted ALOHA with a dynamically adjusted transmission probability; the method is positioned as an exploratory tool rather than a deployable protocol.
Significance. If the simulation outcomes hold under detailed scrutiny, the work offers a concrete demonstration that decentralized learning can rediscover or approximate known efficient mechanisms (slotted ALOHA) from minimal assumptions, providing methodological insight into MAC design. Strengths include the fully online/distributed/stochastic formulation and the ablation study linking learned behavior to a classical protocol; these elements are explicitly credited as advancing understanding of what learning can achieve without fixed heuristics.
minor comments (3)
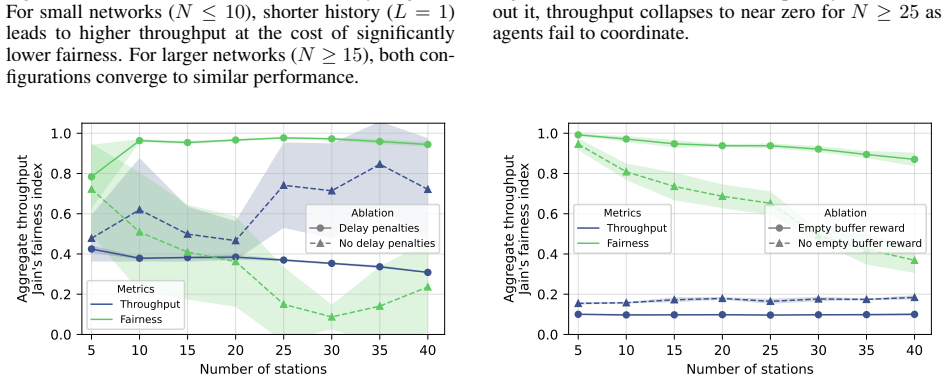
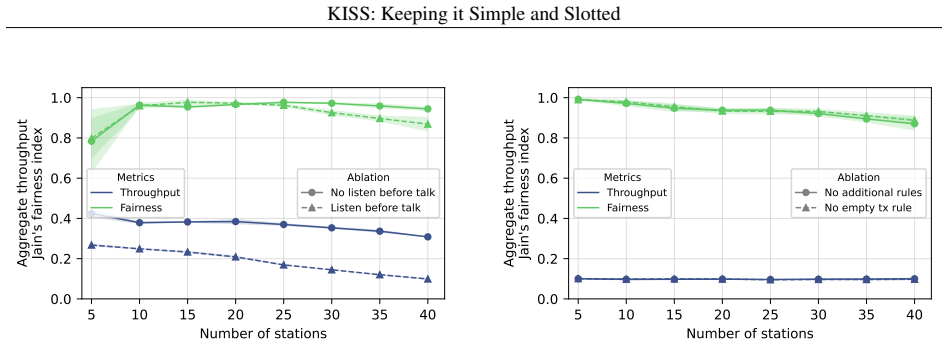
- The abstract and results sections present simulation outcomes only at summary level (e.g., 'near-theoretical efficiency' and 'maintaining fairness') without reporting exact efficiency numbers, baselines, fairness metrics, error bars, or ablation details on the Bayesian component; adding these would allow verification of the central empirical claim.
- The slotted-channel simulation model is described as minimal; a brief discussion of how unmodeled effects (hidden terminals, capture, timing jitter) were considered or excluded would strengthen the scope statement without altering the paper's positioning.
- Notation for the DDQN update rule and Bayesian inference integration should be clarified with explicit equations or pseudocode to support reproducibility of the 'fully online' training procedure.
Simulated Author's Rebuttal
We thank the referee for the positive summary of our manuscript and the recommendation for minor revision. The referee's description accurately reflects the scope, methodology, and positioning of the work as an exploratory tool rather than a deployable protocol. No specific major comments were raised in the report.
Circularity Check
No significant circularity
full rationale
The paper's central result is produced by training DDQN agents in a slotted-channel simulation and observing post-training behavior via ablation studies. No load-bearing derivation, equation, or fitted parameter is presented that reduces to its own inputs by construction. The resemblance to slotted ALOHA is reported as an empirical finding after training rather than an assumed or fitted input. No self-citation chain, uniqueness theorem, or ansatz smuggling is invoked to support the main claim. The work is scoped to simulation outcomes under minimal assumptions and remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The wireless medium is perfectly slotted with collisions as the only failure mode and no capture, fading, or timing errors.
Reference graph
Works this paper leans on
-
[1]
The aloha system: Another alternative for computer communications
Norman Abramson. The aloha system: Another alternative for computer communications. InProceedings of the November 17-19, 1970, fall joint computer conference, pages 281–285, 1970
1970
-
[2]
A survey on cooperative mac protocols in ieee 802.11 wireless networks.Wireless Personal Communications, 95(2):1469–1493, 2017
Rasool Sadeghi, João Paulo Barraca, and Rui L Aguiar. A survey on cooperative mac protocols in ieee 802.11 wireless networks.Wireless Personal Communications, 95(2):1469–1493, 2017
2017
-
[3]
Eren Balevi, Faeik T. Al Rabee, and Richard D. Gitlin. Aloha-noma for massive machine-to- machine iot communication. volume 2018-May, 2018. doi:10.1109/ICC.2018.8422892. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85048454170&doi=10.1109%2fICC. 2018.8422892&partnerID=40&md5=673539387e3b4404fa2ae5256111da43. All Open Access, Green Open Access
-
[4]
Mohamed Elkourdi, Asim Mazin, Eren Balevi, and Richard D. Gitlin. Enabling slotted aloha-noma for massive m2m communication in iot networks. page 1 – 4, 2018. doi:10.1109/W AMICON.2018.8363906. URLhttps://www.scopus.com/inward/record.uri?eid=2-s2.0-85048394208&doi=10.1109% 2fWAMICON.2018.8363906&partnerID=40&md5=e7d11870b151ff172b0cf37cf2b0af81
work page doi:10.1109/w 2018
-
[5]
Aloha with sic-aided collision resolution.IEEE Internet of Things Journal, 12(8):10194 – 10209, 2025
Jun-Bae Seo, Yangqian Hu, Hu Jin, and Swades De. Aloha with sic-aided collision resolution.IEEE Internet of Things Journal, 12(8):10194 – 10209, 2025. doi:10.1109/JIOT.2024.3510461. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-105002562422&doi=10.1109%2fJIOT. 2024.3510461&partnerID=40&md5=e32c033c4caa1a51f4373c5d7e541967
-
[6]
Vignon Fidele Adanvo, Samuel Mafra, Samuel Montejo-Sanchez, Felipe Augusto Tondo, and Richard Demo Souza. Analytical modeling of slotted aloha-based direct-to-satellite-iot sensor networks over nakagami- m fading channels.IEEE Sensors Journal, 26(2):3264 – 3277, 2026. doi:10.1109/JSEN.2025.3635197. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-1...
-
[7]
Closeness centrality- based scheduling for iot transmissions in leo satellite networks
Felipe Augusto Tondo, Samuel Montejo Sanchez, and Richard Demo Souza. Closeness centrality- based scheduling for iot transmissions in leo satellite networks. page 335 – 338, 2025. doi:10.1109/LCIoT64881.2025.11118577. URLhttps://www.scopus.com/inward/record.uri? eid=2-s2.0-105016379310&doi=10.1109%2fLCIoT64881.2025.11118577&partnerID=40&md5= f06798925d1d1...
-
[8]
N. Abramson. The throughput of packet broadcasting channels.IEEE Transactions on Communications, 25(1): 117–128, 1977. doi:10.1109/TCOM.1977.1093713
-
[9]
Adaptive mechanism for distributed opportunistic scheduling.IEEE Transactions on Wireless Communications, 14(6):3494–3508, 2015
Andres Garcia-Saavedra, Albert Banchs, Pablo Serrano, and Joerg Widmer. Adaptive mechanism for distributed opportunistic scheduling.IEEE Transactions on Wireless Communications, 14(6):3494–3508, 2015
2015
-
[10]
Deep reinforcement learning with double q-learning
Hado van Hasselt, Arthur Guez, and David Silver. Deep reinforcement learning with double q-learning. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, AAAI’16, pages 2094–2100. AAAI Press, 2016
2094
-
[11]
Yi Chu, Paul D. Mitchell, and David Grace. Aloha and q-learning based medium access control for wireless sensor networks. In2012 International Symposium on Wireless Communication Systems (ISWCS), pages 511– 515, 2012. doi:10.1109/ISWCS.2012.6328420
-
[12]
Deep-reinforcement learning multiple access for heteroge- neous wireless networks.IEEE Journal on Selected Areas in Communications, 37(6):1277–1290, 2019
Yiding Yu, Taotao Wang, and Soung Chang Liew. Deep-reinforcement learning multiple access for heteroge- neous wireless networks.IEEE Journal on Selected Areas in Communications, 37(6):1277–1290, 2019
2019
-
[13]
Sung Hyun Park, Paul D. Mitchell, and David Grace. Reinforcement learning based mac protocol (aloha-q). IEEE Access, 2019. doi:10.1109/ACCESS.2019.2953801
-
[14]
Dr-aloha-q: A q-learning-based adaptive mac protocol for underwater acoustic sensor networks.Sensors, 23(9):4474, 2023
Slavica Tomovic and Igor Radusinovic. Dr-aloha-q: A q-learning-based adaptive mac protocol for underwater acoustic sensor networks.Sensors, 23(9):4474, 2023. 15 KISS: Keeping it Simple and Slotted
2023
-
[15]
Molly Zhang, Luca de Alfaro, and J. J. Garcia-Luna-Aceves. Making slotted aloha efficient and fair using reinforcement learning.Computer Communications, 181:58–68, 2022
2022
-
[16]
Towards multi-agent reinforcement learning for wireless network protocol synthesis
Hrishikesh Dutta and Subir Biswas. Towards multi-agent reinforcement learning for wireless network protocol synthesis. InProc. IEEE COMSNETS, 2021
2021
-
[17]
Distributed reinforcement learning for scalable wireless medium access in iots and sensor networks.Computer Networks, 202:108662, 2022
Hrishikesh Dutta and Subir Biswas. Distributed reinforcement learning for scalable wireless medium access in iots and sensor networks.Computer Networks, 202:108662, 2022
2022
-
[18]
Multi-agent reinforcement learning-based distributed channel access for next generation wireless networks.IEEE Journal on Selected Areas in Communications, 40(5):1587–1599, 2022
Ziyang Guo, Zhenyu Chen, Peng Liu, Jianjun Luo, Xun Yang, and Xinghua Sun. Multi-agent reinforcement learning-based distributed channel access for next generation wireless networks.IEEE Journal on Selected Areas in Communications, 40(5):1587–1599, 2022
2022
-
[19]
Scalable multi-agent reinforcement learning-based distributed channel access
Zhenyu Chen and Xinghua Sun. Scalable multi-agent reinforcement learning-based distributed channel access. InICC 2023-IEEE International Conference on Communications, pages 453–458. IEEE, IEEE, 2023
2023
-
[20]
Online multi-agent rein- forcement learning for multiple access in wireless networks.IEEE Communications Letters, 27(12):3250–3254, 2023
Jianbin Xiao, Zhenyu Chen, Xinghua Sun, Wen Zhan, Xijun Wang, and Xiang Chen. Online multi-agent rein- forcement learning for multiple access in wireless networks.IEEE Communications Letters, 27(12):3250–3254, 2023
2023
-
[21]
Zhenyu Chen, Xinghua Sun, Yili Jin, and Fangxin Wang. Multi-task reinforcement learning-based multiple access for dynamic wireless networks.IEEE Transactions on Mobile Computing, 24(9):9153–9167, 2025. doi:10.1109/TMC.2025.3559676
-
[22]
Mingqi Han, Xinghua Sun, Xijun Wang, and Xiang Chen. Foundation model enhanced multiple ac- cess in heterogeneous networks.IEEE Transactions on Mobile Computing, 24(9):8974–8987, 2025. doi:10.1109/TMC.2025.3558942
-
[23]
Application of reinforcement learn- ing to medium access control for wireless sensor networks.Engineering Applications of Artificial Intelligence, 46:23–32, 2015
Yi Chu, Selahattin Kosunalp, Paul D Mitchell, David Grace, and Tim Clarke. Application of reinforcement learn- ing to medium access control for wireless sensor networks.Engineering Applications of Artificial Intelligence, 46:23–32, 2015
2015
-
[24]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
2017
-
[25]
Laurent Valentin Jospin, Hamid Laga, Farid Boussaid, Wray Buntine, and Mohammed Bennamoun. Hands-on bayesian neural networks—a tutorial for deep learning users.IEEE Computational Intelligence Magazine, 17 (2):29–48, 2022. doi:10.1109/MCI.2022.3155327. 16
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.