Model-Based Quality Assessment for Massively Multilingual Parallel Data
Pith reviewed 2026-06-28 22:13 UTC · model grok-4.3
The pith
Assessment of massively multilingual parallel data requires direction-aware routing because no model performs reliably across all translation directions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
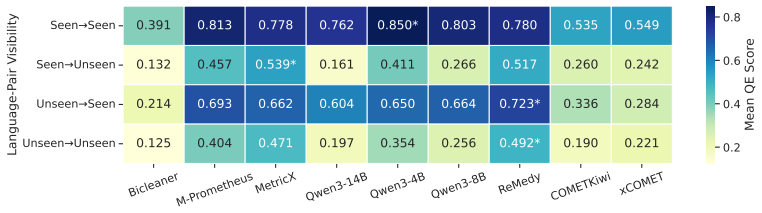
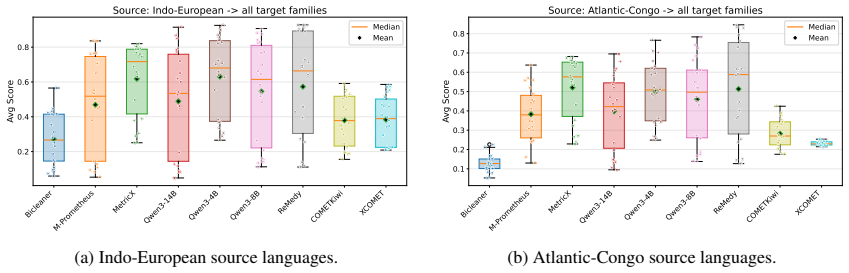
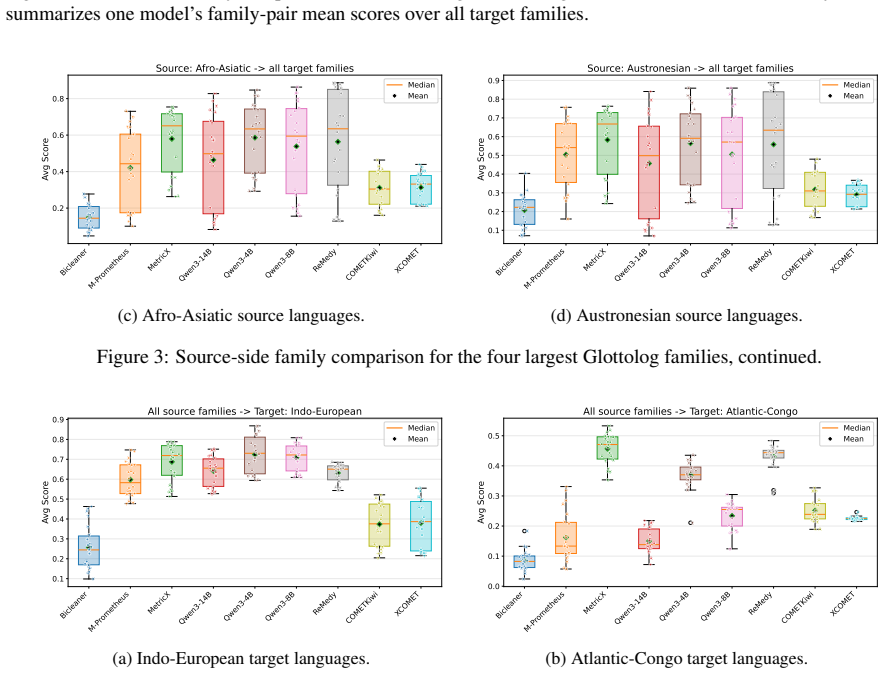
No model is universally reliable across translation directions for either parallelism assessment or reference-free quality estimation. Separate benchmarking on FLORES-200 and BOUQuET retrieval tasks plus professional translations shows that naive ensembles dilute strong signals and that target-language coverage correlates with higher scores. Therefore multilingual parallel-data assessment is best approached as a direction-aware routing and calibration problem where no single universal metric is expected to suffice across all languages.
What carries the argument
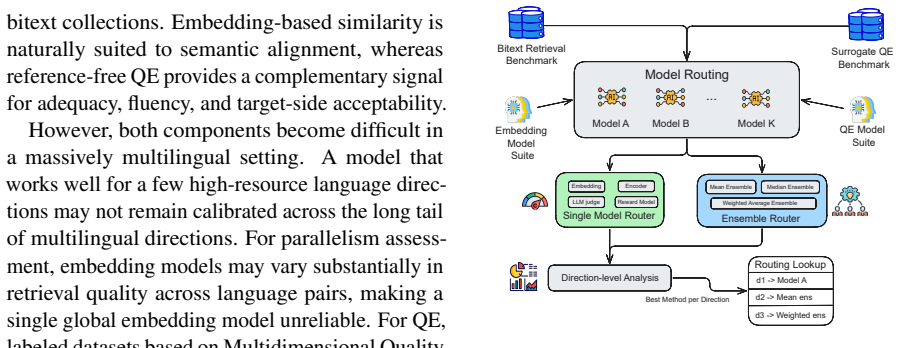
Decomposition into parallelism assessment via multilingual embeddings and reference-free quality estimation, evaluated separately across thousands of ordered source-target directions to reveal direction-specific reliability patterns.
Load-bearing premise
The chosen benchmarks on FLORES-200 retrieval tasks and professional translations sufficiently represent the non-parallel and low-quality issues present in real-world massively multilingual bitext scraped from the web.
What would settle it
An independent test set of real web-scraped bitext in which one embedding model or quality estimator maintains top performance across a wide range of previously unseen translation directions would falsify the claim that direction-aware routing is required.
Figures
read the original abstract
Large-scale multilingual bitext often contains two distinct problems: non-parallel sentence pairs and low-quality translations. We decompose model-based assessment for such data into two independent components: parallelism assessment with multilingual embeddings and reference-free quality estimation (QE). For parallelism, we benchmark four embedding models on FLORES-200 and BOUQuET retrieval tasks, covering 6,654 source--target directions in our target language-pair inventory. For QE, we evaluate nine reference-free evaluators on professional FLORES-200 translations across 41,412 ordered source--target directions. Results show that no model is universally reliable across translation directions. Naive QE ensembles dilute strong model signals, while documented target-language coverage is strongly associated with higher QE scores. Overall, these findings suggest that multilingual parallel-data assessment is best approached as a direction-aware routing and calibration problem, where no single universal metric is expected to suffice across all languages.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper decomposes model-based assessment of massively multilingual bitext into two tasks—parallelism detection via multilingual embeddings and reference-free quality estimation (QE)—and benchmarks four embedding models on FLORES-200/BOUQuET retrieval across 6,654 directions plus nine QE models on professional FLORES-200 translations across 41,412 directions. Its central claim is that no model is universally reliable across directions, that naive ensembles weaken signals, and that assessment is therefore best treated as a direction-aware routing and calibration problem rather than a search for a single universal metric.
Significance. The scale of the direction-level evaluation is a clear strength and supplies concrete evidence of performance heterogeneity. If the observed variability generalizes beyond clean professional data, the result would usefully caution against one-size-fits-all filtering pipelines and motivate per-direction model selection in large-scale bitext curation.
major comments (2)
- [Abstract / Evaluation Setup] Abstract and evaluation sections: the motivating problems are explicitly non-parallel pairs and low-quality translations scraped from the web, yet all reported experiments use only professional, high-quality FLORES-200 translations and retrieval tasks on BOUQuET/FLORES-200. Because these datasets are parallel and clean by construction, the documented direction-specific gaps may reflect coverage or alignment differences rather than the noise types the method is intended to handle; without direct evaluation on noisy web bitext, the recommendation that “no single universal metric is expected to suffice” does not follow from the presented evidence.
- [Results] Results and discussion: the claim that target-language coverage is “strongly associated with higher QE scores” is presented as a key finding, but the manuscript does not report the statistical test, effect size, or control for confounding factors (e.g., script family, data volume) that would establish the association as load-bearing for the routing recommendation.
minor comments (1)
- The manuscript would benefit from an explicit limitations paragraph that states the scope is restricted to clean professional data and notes the open question of transfer to noisy web-scraped bitext.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address each major comment below and describe the revisions we will incorporate.
read point-by-point responses
-
Referee: [Abstract / Evaluation Setup] Abstract and evaluation sections: the motivating problems are explicitly non-parallel pairs and low-quality translations scraped from the web, yet all reported experiments use only professional, high-quality FLORES-200 translations and retrieval tasks on BOUQuET/FLORES-200. Because these datasets are parallel and clean by construction, the documented direction-specific gaps may reflect coverage or alignment differences rather than the noise types the method is intended to handle; without direct evaluation on noisy web bitext, the recommendation that “no single universal metric is expected to suffice” does not follow from the presented evidence.
Authors: We appreciate the referee highlighting the distinction between our motivating use cases and the experimental data. The clean professional translations were deliberately chosen to isolate direction-specific model behavior without the confounding effects of variable noise. The substantial performance heterogeneity observed even in this controlled setting already indicates that direction-aware approaches are warranted. We nevertheless agree that the general claim would be strengthened by direct evidence on noisy web bitext. We will revise the abstract, evaluation setup, and discussion sections to explicitly acknowledge this limitation and qualify the scope of the routing recommendation. revision: yes
-
Referee: [Results] Results and discussion: the claim that target-language coverage is “strongly associated with higher QE scores” is presented as a key finding, but the manuscript does not report the statistical test, effect size, or control for confounding factors (e.g., script family, data volume) that would establish the association as load-bearing for the routing recommendation.
Authors: We agree that the association requires more rigorous statistical support to serve as a basis for the routing recommendation. In the revised manuscript we will add the relevant statistical tests, report effect sizes, and include controls for potential confounders such as script family and data volume. revision: yes
Circularity Check
Empirical benchmarking study on external datasets; no circular derivations or self-referential reductions.
full rationale
The paper is a benchmarking study that evaluates four embedding models on FLORES-200 and BOUQuET retrieval tasks and nine QE evaluators on professional FLORES-200 translations. All claims, including that no model is universally reliable and that assessment requires direction-aware routing, are presented as direct outcomes of these external evaluations across thousands of directions. No equations, fitted parameters, predictions, or self-citations are used to derive the central results; the datasets are independent benchmarks, and the findings do not reduce to inputs by construction. This is a standard empirical analysis with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
and Le, Quoc V
Wei, Jason and Wang, Xuezhi and Schuurmans, Dale and Bosma, Maarten and Ichter, Brian and Xia, Fei and Chi, Ed H. and Le, Quoc V. and Zhou, Denny , title =. 2022 , booktitle =
2022
-
[2]
The State and Fate of Linguistic Diversity and Inclusion in the NLP World
Joshi, Pratik and Santy, Sebastin and Budhiraja, Amar and Bali, Kalika and Choudhury, Monojit. The State and Fate of Linguistic Diversity and Inclusion in the NLP World. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.560
-
[3]
Brookings Institution , year =
Closing the Gap: A Call for More Inclusive Language Technologies , author =. Brookings Institution , year =
-
[4]
Recommendation concerning the Promotion and Use of Multilingualism and Universal Access to Cyberspace , year =
-
[5]
UNESCO and G20 promote Linguistic Diversity in Digital Age , year =
-
[6]
Multilingua , doi =
Linguistic diversity in a time of crisis: Language challenges of the COVID-19 pandemic , author =. Multilingua , doi =. 2020 , lastchecked =
2020
-
[7]
European Journal of Public Health , volume =
Multilingual Covid-19 Communication and Linguistic Minorities in Finland: A Qualitative Study , author =. European Journal of Public Health , volume =. 2023 , pages =
2023
-
[8]
Survey of Low-Resource Machine Translation
Haddow, Barry and Bawden, Rachel and Miceli Barone, Antonio Valerio and Helcl, Jind r ich and Birch, Alexandra. Survey of Low-Resource Machine Translation. Computational Linguistics. 2022. doi:10.1162/coli_a_00446
-
[9]
Koehn, Philipp , title =. 2020 , publisher =. doi:10.1017/9781108608480 , isbn =
-
[10]
Informative Manual Evaluation of Machine Translation Output
Popovi \'c , Maja. Informative Manual Evaluation of Machine Translation Output. Proceedings of the 28th International Conference on Computational Linguistics. 2020. doi:10.18653/v1/2020.coling-main.444
-
[11]
2016 , publisher =
Goodfellow, Ian and Bengio, Yoshua and Courville, Aaron , title =. 2016 , publisher =
2016
-
[12]
Natural Language Engineering , author=
Neural machine translation of low-resource languages using SMT phrase pair injection , volume=. Natural Language Engineering , author=. 2021 , pages=. doi:10.1017/S1351324920000303 , number=
-
[13]
m T 5: A Massively Multilingual Pre-trained Text-to-Text Transformer
Xue, Linting and Constant, Noah and Roberts, Adam and Kale, Mihir and Al-Rfou, Rami and Siddhant, Aditya and Barua, Aditya and Raffel, Colin. m T 5: A Massively Multilingual Pre-trained Text-to-Text Transformer. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2...
-
[14]
Quality at a Glance: An Audit of Web-Crawled Multilingual Datasets
Kreutzer, Julia and Caswell, Isaac and Wang, Lisa and Wahab, Ahsan and van Esch, Daan and Ulzii-Orshikh, Nasanbayar and Tapo, Allahsera and Subramani, Nishant and Sokolov, Artem and Sikasote, Claytone and Setyawan, Monang and Sarin, Supheakmungkol and Samb, Sokhar and Sagot, Beno. Quality at a Glance: An Audit of Web-Crawled Multilingual Datasets. Transac...
-
[15]
Findings of the WMT 2018 Shared Task on Parallel Corpus Filtering
Koehn, Philipp and Khayrallah, Huda and Heafield, Kenneth and Forcada, Mikel L. Findings of the WMT 2018 Shared Task on Parallel Corpus Filtering. Proceedings of the Third Conference on Machine Translation: Shared Task Papers. 2018. doi:10.18653/v1/W18-6453
-
[16]
Peter, Jan-Thorsten and Vilar, David and Deutsch, Daniel and Finkelstein, Mara and Juraska, Juraj and Freitag, Markus , booktitle =. There. 2023 , address =
2023
-
[17]
FineOPUS: A Massively Multilingual Translation Corpus and Pipeline , year =
-
[18]
Parallel Data, Tools and Interfaces in OPUS
Tiedemann, J. Parallel Data, Tools and Interfaces in OPUS. Proceedings of the Eighth International Conference on Language Resources and Evaluation ( LREC '12). 2012
2012
-
[19]
Language-agnostic BERT Sentence Embedding
Feng, Fangxiaoyu and Yang, Yinfei and Cer, Daniel and Arivazhagan, Naveen and Wang, Wei. Language-agnostic BERT Sentence Embedding. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022. doi:10.18653/v1/2022.acl-long.62
-
[20]
International Conference on Learning Representations , year=
Efficient Estimation of Word Representations in Vector Space , author=. International Conference on Learning Representations , year=
-
[21]
Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers) , year =
Deep Contextualized Word Representations , author =. Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers) , year =
2018
-
[22]
North American Chapter of the Association for Computational Linguistics , year=
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding , author=. North American Chapter of the Association for Computational Linguistics , year=
-
[23]
Conneau, Alexis and Khandelwal, Kartikay and Goyal, Naman and Chaudhary, Vishrav and Wenzek, Guillaume and Guzm \'a n, Francisco and Grave, Edouard and Ott, Myle and Zettlemoyer, Luke and Stoyanov, Veselin. Unsupervised Cross-lingual Representation Learning at Scale. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. ...
-
[24]
Massively Multilingual Sentence Embeddings for Zero-Shot Cross-Lingual Transfer and Beyond
Artetxe, Mikel and Schwenk, Holger. Massively Multilingual Sentence Embeddings for Zero-Shot Cross-Lingual Transfer and Beyond. Transactions of the Association for Computational Linguistics. 2019. doi:10.1162/tacl_a_00288
-
[25]
Guerreiro, Nuno M. and Alves, Duarte M. and Waldendorf, Jonas and Haddow, Barry and Birch, Alexandra and Colombo, Pierre and Martins, Andr \'e F. T. Hallucinations in Large Multilingual Translation Models. Transactions of the Association for Computational Linguistics. 2023. doi:10.1162/tacl_a_00615
-
[26]
Bicleaner AI : Bicleaner Goes Neural
Zaragoza-Bernabeu, Jaume and Ram \'i rez-S \'a nchez, Gema and Ba \ n \'o n, Marta and Ortiz Rojas, Sergio. Bicleaner AI : Bicleaner Goes Neural. Proceedings of the Thirteenth Language Resources and Evaluation Conference. 2022
2022
-
[27]
arXiv preprint arXiv:2403.14118 , year =
From Handcrafted Features to LLMs: A Brief Survey for Machine Translation Quality Estimation , author =. arXiv preprint arXiv:2403.14118 , year =. 2403.14118 , archivePrefix=
-
[28]
Proceedings of the 7th Conference of the Association for Machine Translation in the Americas: Technical Papers , year =
A Study of Translation Edit Rate with Targeted Human Annotation , author =. Proceedings of the 7th Conference of the Association for Machine Translation in the Americas: Technical Papers , year =
-
[29]
Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , year =
Neural Machine Translation of Rare Words with Subword Units , author =. Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , year =
-
[30]
2004 , address =
Confidence Estimation for Machine Translation , author =. 2004 , address =
2004
-
[31]
Proceedings of Translating and the Computer 35 , year =
Multidimensional quality metrics: a flexible system for assessing translation quality , author =. Proceedings of Translating and the Computer 35 , year =
-
[32]
Combining Quality Estimation and Automatic Post-editing to Enhance Machine Translation output
Chatterjee, Rajen and Negri, Matteo and Turchi, Marco and Blain, Fr \'e d \'e ric and Specia, Lucia. Combining Quality Estimation and Automatic Post-editing to Enhance Machine Translation output. Proceedings of the 13th Conference of the Association for Machine Translation in the A mericas (Volume 1: Research Track). 2018
2018
-
[33]
2014 , address =
Specia, Lucia and Shah, Kashif , booktitle =. 2014 , address =
2014
-
[34]
Proceedings of the 7th Linguistic Annotation Workshop and Interoperability with Discourse , year =
Continuous Measurement Scales in Human Evaluation of Machine Translation , author =. Proceedings of the 7th Linguistic Annotation Workshop and Interoperability with Discourse , year =
-
[35]
Proceedings of
Is all that Glitters in Machine Translation Quality Estimation really Gold? , author =. Proceedings of. 2016 , address =
2016
-
[36]
Proceedings of the Second Conference on Machine Translation , year =
Predictor-Estimator using Multilevel Task Learning with Stack Propagation for Neural Quality Estimation , author =. Proceedings of the Second Conference on Machine Translation , year =
-
[37]
T rans Q uest: Translation Quality Estimation with Cross-lingual Transformers
Ranasinghe, Tharindu and Orasan, Constantin and Mitkov, Ruslan. T rans Q uest: Translation Quality Estimation with Cross-lingual Transformers. Proceedings of the 28th International Conference on Computational Linguistics. 2020. doi:10.18653/v1/2020.coling-main.445
-
[38]
COMET : A Neural Framework for MT Evaluation
Rei, Ricardo and Stewart, Craig and Farinha, Ana C and Lavie, Alon. COMET : A Neural Framework for MT Evaluation. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020. doi:10.18653/v1/2020.emnlp-main.213
-
[39]
Kepler, Fabio and Tr \'e nous, Jonay and Treviso, Marcos and Vera, Miguel and Martins, Andr \'e F. T. O pen K iwi: An Open Source Framework for Quality Estimation. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics: System Demonstrations. 2019. doi:10.18653/v1/P19-3020
-
[40]
and Zerva, Chrysoula and Farinha, Ana C and Maroti, Christine and C
Rei, Ricardo and Treviso, Marcos and Guerreiro, Nuno M. and Zerva, Chrysoula and Farinha, Ana C and Maroti, Christine and C. de Souza, Jos \'e G. and Glushkova, Taisiya and Alves, Duarte and Coheur, Luisa and Lavie, Alon and Martins, Andr \'e F. T. C omet K iwi: IST -Unbabel 2022 Submission for the Quality Estimation Shared Task. Proceedings of the Sevent...
-
[41]
and Pombal, Jos \'e and van Stigt, Daan and Treviso, Marcos and Coheur, Luisa and C
Rei, Ricardo and Guerreiro, Nuno M. and Pombal, Jos \'e and van Stigt, Daan and Treviso, Marcos and Coheur, Luisa and C. de Souza, Jos \'e G. and Martins, Andr \'e F. T. Scaling up C omet K iwi: Unbabel- IST 2023 Submission for the Quality Estimation Shared Task. Proceedings of the Eighth Conference on Machine Translation. 2023. doi:10.18653/v1/2023.wmt-1.73
-
[42]
and Rei, Ricardo and Stigt, Daan van and Coheur, Luisa and Colombo, Pierre and Martins, Andr \'e F
Guerreiro, Nuno M. and Rei, Ricardo and Stigt, Daan van and Coheur, Luisa and Colombo, Pierre and Martins, Andr \'e F. T. x COMET : Transparent Machine Translation Evaluation through Fine-grained Error Detection. Transactions of the Association for Computational Linguistics. 2024. doi:10.1162/tacl_a_00683
-
[43]
Reference-Less Evaluation of Machine Translation: Navigating Through the Resource-Scarce Scenarios , JOURNAL =
Sindhujan, Archchana and Kanojia, Diptesh and Or. Reference-Less Evaluation of Machine Translation: Navigating Through the Resource-Scarce Scenarios , JOURNAL =. 2025 , NUMBER =
2025
-
[44]
Are LLM s Breaking MT Metrics? Results of the WMT 24 Metrics Shared Task
Freitag, Markus and Mathur, Nitika and Deutsch, Daniel and Lo, Chi-Kiu and Avramidis, Eleftherios and Rei, Ricardo and Thompson, Brian and Blain, Frederic and Kocmi, Tom and Wang, Jiayi and Adelani, David Ifeoluwa and Buchicchio, Marianna and Zerva, Chrysoula and Lavie, Alon. Are LLM s Breaking MT Metrics? Results of the WMT 24 Metrics Shared Task. Procee...
-
[45]
M etric X -23: The G oogle Submission to the WMT 2023 Metrics Shared Task
Juraska, Juraj and Finkelstein, Mara and Deutsch, Daniel and Siddhant, Aditya and Mirzazadeh, Mehdi and Freitag, Markus. M etric X -23: The G oogle Submission to the WMT 2023 Metrics Shared Task. Proceedings of the Eighth Conference on Machine Translation. 2023. doi:10.18653/v1/2023.wmt-1.63
-
[46]
Juraska, Juraj and Domhan, Tobias and Finkelstein, Mara and Nakagawa, Tetsuji and Kovacs, Geza and Deutsch, Daniel and Wang, Pidong and Freitag, Markus. M etric X -25 and G em S pan E val: G oogle T ranslate Submissions to the WMT 25 Evaluation Shared Task. Proceedings of the Tenth Conference on Machine Translation. 2025. doi:10.18653/v1/2025.wmt-1.70
-
[47]
Proceedings of the 24th Annual Conference of the European Association for Machine Translation , year =
Kocmi, Tom and Federmann, Christian , title =. Proceedings of the 24th Annual Conference of the European Association for Machine Translation , year =
-
[48]
TASER : Translation Assessment via Systematic Evaluation and Reasoning
Maheswaran, Monishwaran and Carini, Marco and Federmann, Christian. TASER : Translation Assessment via Systematic Evaluation and Reasoning. Proceedings of the Tenth Conference on Machine Translation. 2025. doi:10.18653/v1/2025.wmt-1.76
-
[49]
R e M edy: Learning Machine Translation Evaluation from Human Preferences with Reward Modeling
Tan, Shaomu and Monz, Christof. R e M edy: Learning Machine Translation Evaluation from Human Preferences with Reward Modeling. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.217
-
[50]
2025 , eprint=
M-Prometheus: A Suite of Open Multilingual LLM Judges , author=. 2025 , eprint=
2025
-
[51]
arXiv preprint arXiv:2505.09388 , year=
Qwen3 Technical Report , author=. arXiv preprint arXiv:2505.09388 , year=
-
[52]
Zerva, Chrysoula and Blain, Frederic and C. De Souza, Jos \'e G. and Kanojia, Diptesh and Deoghare, Sourabh and Guerreiro, Nuno M. and Attanasio, Giuseppe and Rei, Ricardo and Orasan, Constantin and Negri, Matteo and Turchi, Marco and Chatterjee, Rajen and Bhattacharyya, Pushpak and Freitag, Markus and Martins, Andr \'e. Findings of the Quality Estimation...
-
[53]
Error Span Annotation: A Balanced Approach for Human Evaluation of Machine Translation
Kocmi, Tom and Zouhar, Vil \'e m and Avramidis, Eleftherios and Grundkiewicz, Roman and Karpinska, Marzena and Popovi \'c , Maja and Sachan, Mrinmaya and Shmatova, Mariya. Error Span Annotation: A Balanced Approach for Human Evaluation of Machine Translation. Proceedings of the Ninth Conference on Machine Translation. 2024. doi:10.18653/v1/2024.wmt-1.131
-
[54]
Specia, Lucia and Blain, Fr \'e d \'e ric and Fomicheva, Marina and Zerva, Chrysoula and Li, Zhenhao and Chaudhary, Vishrav and Martins, Andr \'e F. T. Findings of the WMT 2021 Shared Task on Quality Estimation. Proceedings of the Sixth Conference on Machine Translation. 2021
2021
-
[55]
Blain, Frederic and Zerva, Chrysoula and Rei, Ricardo and Guerreiro, Nuno M. and Kanojia, Diptesh and C. de Souza, Jos \'e G. and Silva, Beatriz and Vaz, T \^a nia and Jingxuan, Yan and Azadi, Fatemeh and Orasan, Constantin and Martins, Andr \'e. Findings of the WMT 2023 Shared Task on Quality Estimation. Proceedings of the Eighth Conference on Machine Tr...
-
[56]
Fomicheva, Marina and Sun, Shuo and Fonseca, Erick and Zerva, Chrysoula and Blain, Fr \'e d \'e ric and Chaudhary, Vishrav and Guzm \'a n, Francisco and Lopatina, Nina and Specia, Lucia and Martins, Andr \'e F. T. MLQE - PE : A Multilingual Quality Estimation and Post-Editing Dataset. Proceedings of the Thirteenth Language Resources and Evaluation Confere...
2022
-
[57]
Chaplynskyi, Dmytro and Zakharov, Kyrylo. A Framework for Large-Scale Parallel Corpus Evaluation: Ensemble Quality Estimation Models Versus Human Assessment. Proceedings of the Fourth Ukrainian Natural Language Processing Workshop (UNLP 2025). 2025. doi:10.18653/v1/2025.unlp-1.9
-
[58]
Lavie, Alon and Hanneman, Greg and Agrawal, Sweta and Kanojia, Diptesh and Lo, Chi-Kiu and Zouhar, Vil \'e m and Blain, Frederic and Zerva, Chrysoula and Avramidis, Eleftherios and Deoghare, Sourabh and Sindhujan, Archchana and Wang, Jiayi and Adelani, David Ifeoluwa and Thompson, Brian and Kocmi, Tom and Freitag, Markus and Deutsch, Daniel. Findings of t...
-
[59]
Attention is All you Need , url =
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, ukasz and Polosukhin, Illia , booktitle =. Attention is All you Need , url =
-
[60]
Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing , year =
Zipporah: a Fast and Scalable Data Cleaning System for Noisy Web-Crawled Parallel Corpora , author =. Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing , year =
2017
-
[61]
Proceedings of the 38th International Conference on Machine Learning , series =
Calibrate Before Use: Improving Few-shot Performance of Language Models , author =. Proceedings of the 38th International Conference on Machine Learning , series =. 2021 , publisher =
2021
-
[62]
Batch Prompting: Efficient Inference with Large Language Model
Cheng, Zhoujun and Kasai, Jungo and Yu, Tao , booktitle =. Batch Prompting: Efficient Inference with Large Language Model. 2023 , address =
2023
-
[63]
2024 , url =
Lin, Jianzhe and Diesendruck, Maurice and Du, Liang and Abraham, Robin , booktitle =. 2024 , url =
2024
-
[64]
Proceedings of the Conference on Language Modeling (COLM) , year=
ALOPE: Adaptive Layer Optimization for Translation Quality Estimation using Large Language Models , author=. Proceedings of the Conference on Language Modeling (COLM) , year=
-
[65]
arXiv preprint arXiv:2207.04672 , year=
No Language Left Behind: Scaling Human-Centered Machine Translation , author=. arXiv preprint arXiv:2207.04672 , year=
-
[66]
The Twelfth International Conference on Learning Representations , year=
MT-Ranker: Reference-free machine translation evaluation by inter-system ranking , author=. The Twelfth International Conference on Learning Representations , year=
-
[67]
M etric X -24: The G oogle Submission to the WMT 2024 Metrics Shared Task
Juraska, Juraj and Deutsch, Daniel and Finkelstein, Mara and Freitag, Markus. M etric X -24: The G oogle Submission to the WMT 2024 Metrics Shared Task. Proceedings of the Ninth Conference on Machine Translation. 2024. doi:10.18653/v1/2024.wmt-1.35
-
[68]
NTREX -128 -- News Test References for MT Evaluation of 128 Languages
Federmann, Christian and Kocmi, Tom and Xin, Ying. NTREX -128 -- News Test References for MT Evaluation of 128 Languages. Proceedings of the First Workshop on Scaling Up Multilingual Evaluation. 2022. doi:10.18653/v1/2022.sumeval-1.4
-
[69]
Andrews, Pierre and Artetxe, Mikel and Meglioli, Mariano Coria and Costa-juss \`a , Marta R. and Chuang, Joe and Dale, David and Duppenthaler, Mark and Ekberg, Nathanial Paul and Gao, Cynthia and Licht, Daniel Edward and Maillard, Jean and Mourachko, Alexandre and Ropers, Christophe and Saleem, Safiyyah and S \'a nchez, Eduardo and Tsiamas, Ioannis and Tu...
-
[70]
Kwon, Woosuk and Li, Zhuohan and Zhuang, Siyuan and Sheng, Ying and Zheng, Lianmin and Yu, Cody Hao and Gonzalez, Joseph and Zhang, Hao and Stoica, Ion , title =. Proceedings of the 29th Symposium on Operating Systems Principles , pages =. 2023 , isbn =. doi:10.1145/3600006.3613165 , abstract =
-
[71]
Machine Translation Meta Evaluation through Translation Accuracy Challenge Sets
Moghe, Nikita and Fazla, Arnisa and Amrhein, Chantal and Kocmi, Tom and Steedman, Mark and Birch, Alexandra and Sennrich, Rico and Guillou, Liane. Machine Translation Meta Evaluation through Translation Accuracy Challenge Sets. Computational Linguistics. 2025. doi:10.1162/coli_a_00537
-
[72]
arXiv preprint arXiv:2402.05672 , year=
Multilingual e5 text embeddings: A technical report , author=. arXiv preprint arXiv:2402.05672 , year=
-
[73]
Zhang, Xin and Zhang, Yanzhao and Long, Dingkun and Xie, Wen and Dai, Ziqi and Tang, Jialong and Lin, Huan and Yang, Baosong and Xie, Pengjun and Huang, Fei and Zhang, Meishan and Li, Wenjie and Zhang, Min. mGTE : Generalized Long-Context Text Representation and Reranking Models for Multilingual Text Retrieval. Proceedings of the 2024 Conference on Empiri...
-
[74]
Jina Embeddings V3: Multilingual Text Encoder with Low-Rank Adaptations , year =
Sturua, Saba and Mohr, Isabelle and Kalim Akram, Mohammad and G\". Jina Embeddings V3: Multilingual Text Encoder with Low-Rank Adaptations , year =. Advances in Information Retrieval: 47th European Conference on Information Retrieval, ECIR 2025, Lucca, Italy, April 6–10, 2025, Proceedings, Part V , pages =. doi:10.1007/978-3-031-88720-8_21 , abstract =
-
[75]
2026 , howpublished =
Microsoft , title =. 2026 , howpublished =
2026
-
[76]
and Tice, Dawn M
Voorhees, Ellen M. and Tice, Dawn M. The TREC -8 Question Answering Track. Proceedings of the Second International Conference on Language Resources and Evaluation ( LREC ' 00). 2000
2000
-
[77]
Filtering and Mining Parallel Data in a Joint Multilingual Space
Schwenk, Holger. Filtering and Mining Parallel Data in a Joint Multilingual Space. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). 2018. doi:10.18653/v1/P18-2037
-
[78]
Margin-based Parallel Corpus Mining with Multilingual Sentence Embeddings
Artetxe, Mikel and Schwenk, Holger. Margin-based Parallel Corpus Mining with Multilingual Sentence Embeddings. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019. doi:10.18653/v1/P19-1309
-
[79]
W iki M atrix: Mining 135 M Parallel Sentences in 1620 Language Pairs from W ikipedia
Schwenk, Holger and Chaudhary, Vishrav and Sun, Shuo and Gong, Hongyu and Guzm \'a n, Francisco. W iki M atrix: Mining 135 M Parallel Sentences in 1620 Language Pairs from W ikipedia. Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume. 2021. doi:10.18653/v1/2021.eacl-main.115
-
[80]
Unsupervised Bitext Mining and Translation via Self-Trained Contextual Embeddings
Keung, Phillip and Salazar, Julian and Lu, Yichao and Smith, Noah A. Unsupervised Bitext Mining and Translation via Self-Trained Contextual Embeddings. Transactions of the Association for Computational Linguistics. 2020. doi:10.1162/tacl_a_00348
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.