Adaptive Order Policies for Masked Diffusion
Pith reviewed 2026-06-28 23:31 UTC · model grok-4.3
The pith
A lightweight policy network learns the unmasking order in masked diffusion models by reweighting the training loss to favor positions the denoiser is likely to predict correctly.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We propose a scheme for learning the unmasking order using an additional lightweight policy network on top of a diffusion model. Our proposed loss reweights terms in the masked diffusion loss according to policy probabilities, and results in a policy that prefers positions where the denoiser is more likely to be correct. We study this loss in two settings: (i) training solely the policy while using a frozen pre-trained denoiser, and (ii) training the policy and denoiser jointly with the weighted loss to allow for mutual adaptation. We demonstrate that our approach outperforms common heuristics on problems that are sensitive to token ordering, such as combinatorial tasks and proteins.
What carries the argument
Lightweight policy network whose probabilities reweight the masked diffusion loss to select an adaptive unmasking order.
If this is right
- The policy produces higher-quality samples than random or probability-based heuristics on combinatorial problems.
- Protein sequence generation quality rises when the unmasking order adapts to the strengths of the current denoiser.
- Joint training lets the denoiser and policy co-adapt, which can produce more internally consistent sequences than separate training.
- The same reweighting approach applies to any discrete sequence domain in which generation order influences final accuracy.
Where Pith is reading between the lines
- The method could be tested on text generation benchmarks to measure whether learned orders reduce exposure bias compared with fixed schedules.
- If the policy is allowed to optimize a downstream reward instead of the reweighted likelihood, it might discover orders tailored to specific applications such as molecule design.
- Scaling experiments could check whether the policy needs to grow with the denoiser size or remains effective as a small auxiliary network.
Load-bearing premise
Reweighting the masked diffusion loss terms according to the policy probabilities will produce a policy preferring positions where the denoiser is more likely correct, without introducing training instability or degrading the denoiser's performance.
What would settle it
If the learned policy yields no improvement over random ordering on a combinatorial task such as TSP or sorting when both are trained to the same compute budget, the central claim would be falsified.
Figures
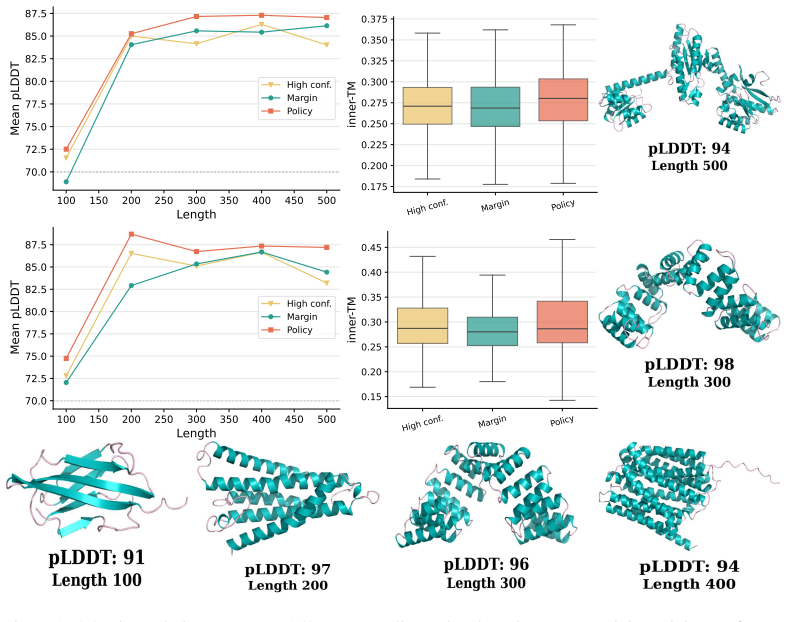
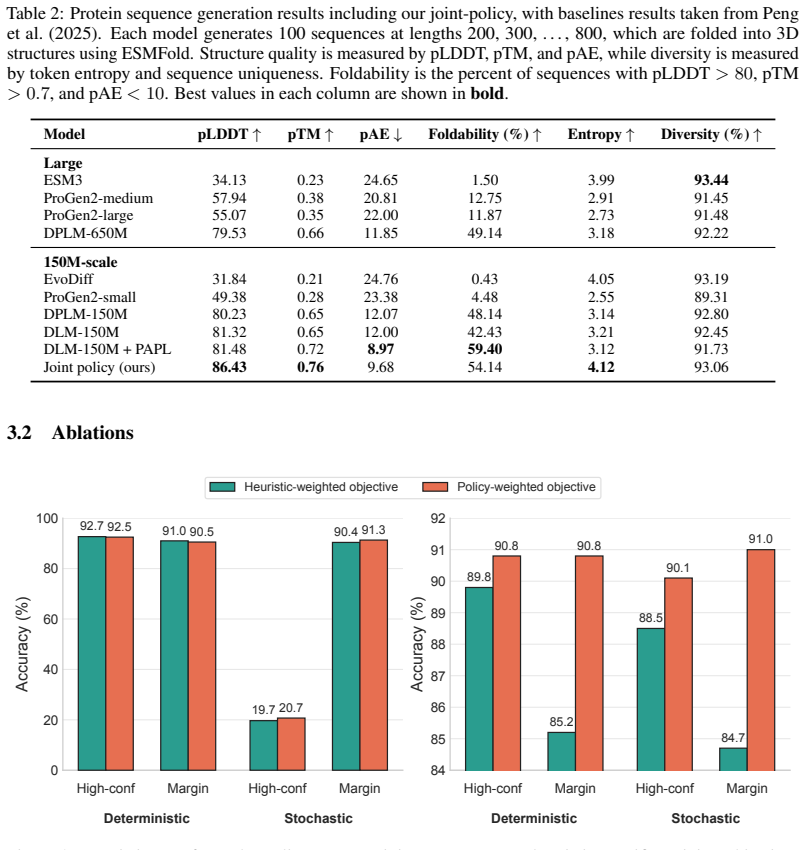
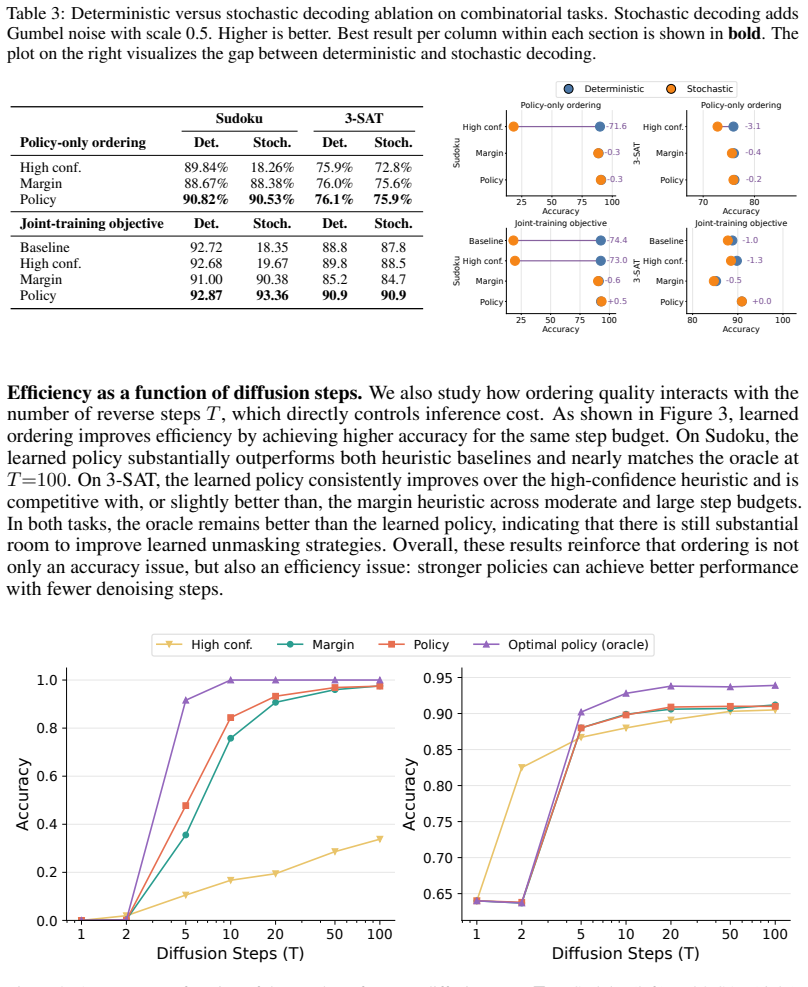
read the original abstract
Masked diffusion models have seen great success in capturing data distributions over discrete sequences in domains such as text and proteins. These models generate data by iteratively unmasking tokens starting from a fully masked sequence, with the unmasking order typically chosen at random or using a heuristic based on denoiser probabilities. In this work, we propose a scheme for learning the unmasking order using an additional lightweight policy network on top of a diffusion model. Our proposed loss reweights terms in the masked diffusion loss according to policy probabilities, and results in a policy that prefers positions where the denoiser is more likely to be correct. We study this loss in two settings: (i) training solely the policy while using a frozen pre-trained denoiser, and (ii) training the policy and denoiser jointly with the weighted loss to allow for mutual adaptation. We demonstrate that our approach outperforms common heuristics on problems that are sensitive to token ordering, such as combinatorial tasks and proteins.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes learning the unmasking order in masked diffusion models via an additional lightweight policy network whose probabilities reweight terms in the masked diffusion loss. This is examined in two regimes—policy training with a frozen pre-trained denoiser, and joint training of policy and denoiser—and is claimed to yield policies that prefer positions where the denoiser is more likely correct, outperforming random or heuristic ordering on ordering-sensitive tasks such as combinatorial problems and proteins.
Significance. If the reweighting scheme produces the claimed ordering preference without instability or denoiser degradation, the method would offer a practical improvement to discrete diffusion generation pipelines. The explicit comparison of frozen versus joint training regimes is a positive design choice that permits direct assessment of mutual adaptation.
major comments (2)
- [Method (loss reweighting)] The central claim that reweighting the masked diffusion objective by policy probabilities produces a policy preferring positions where the denoiser is more likely correct lacks any derivation or gradient analysis. No equation demonstrates that the gradient of the reweighted loss necessarily increases the probability of correct denoiser predictions at the sampled positions (as opposed to increasing policy entropy or correlating with unrelated statistics).
- [Joint training experiments] In the joint-training regime the implicit feedback loop created by the reweighting is not analyzed for stability. If early errors are amplified or effective batch diversity is reduced, denoiser performance can degrade even while the policy metric improves; this directly affects the mutual-adaptation claim.
minor comments (2)
- [Abstract] The abstract states outperformance on combinatorial tasks and proteins but supplies no metrics, baselines, or dataset sizes; these details should appear in the abstract or be cross-referenced to the experiments section.
- [Notation] Notation for the policy network and the reweighting factor should be introduced once and used consistently; several passages reuse symbols without explicit definition.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on the method and joint-training regime. We address each point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Method (loss reweighting)] The central claim that reweighting the masked diffusion objective by policy probabilities produces a policy preferring positions where the denoiser is more likely correct lacks any derivation or gradient analysis. No equation demonstrates that the gradient of the reweighted loss necessarily increases the probability of correct denoiser predictions at the sampled positions (as opposed to increasing policy entropy or correlating with unrelated statistics).
Authors: We agree that the manuscript lacks an explicit derivation. The reweighting is designed so that the policy objective encourages higher probability on positions with lower denoiser loss. In revision we will add a gradient analysis of the policy parameters under the reweighted objective (with frozen denoiser), showing that the update increases the probability of sampling positions where the instantaneous denoiser loss is smaller. We will also note the assumptions required for this to correspond specifically to correctness rather than other loss-correlated statistics. revision: yes
-
Referee: [Joint training experiments] In the joint-training regime the implicit feedback loop created by the reweighting is not analyzed for stability. If early errors are amplified or effective batch diversity is reduced, denoiser performance can degrade even while the policy metric improves; this directly affects the mutual-adaptation claim.
Authors: We acknowledge that stability of the joint-training feedback loop was not analyzed. Our current experiments report final performance but do not track intermediate dynamics. In the revision we will add training curves for denoiser loss/accuracy, policy entropy, and effective batch diversity in the joint regime to check for error amplification or diversity collapse. If degradation is observed we will qualify the mutual-adaptation claim accordingly. revision: yes
Circularity Check
No circularity; proposed reweighting scheme is an independent design choice with no self-referential reduction
full rationale
The paper introduces an auxiliary policy network and a reweighting of the masked diffusion loss as a novel training procedure. The statement that this produces a policy preferring positions where the denoiser is more likely correct is presented as an empirical or design consequence rather than a derived equality that reduces to the inputs by construction. No equations, self-citations, or uniqueness theorems are invoked in a load-bearing manner that would make the central claim tautological. The method remains self-contained against external benchmarks and does not rely on any of the enumerated circular patterns.
Axiom & Free-Parameter Ledger
invented entities (1)
-
lightweight policy network
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems , editor =
Riemannian Diffusion Models , author =. Advances in Neural Information Processing Systems , editor =. 2022 , url =
2022
-
[2]
The Twelfth International Conference on Learning Representations , year =
Flow Matching on General Geometries , author =. The Twelfth International Conference on Learning Representations , year =
-
[3]
Advances in Neural Information Processing Systems , editor =
Structured Denoising Diffusion Models in Discrete State-Spaces , author =. Advances in Neural Information Processing Systems , editor =. 2021 , url =
2021
-
[4]
Scaling Learning Algorithms Towards
Bengio, Yoshua and LeCun, Yann , booktitle =. Scaling Learning Algorithms Towards
-
[5]
and Osindero, Simon and Teh, Yee Whye , journal =
Hinton, Geoffrey E. and Osindero, Simon and Teh, Yee Whye , journal =. A Fast Learning Algorithm for Deep Belief Nets , volume =
-
[6]
2016 , publisher =
Deep learning , author =. 2016 , publisher =
2016
-
[7]
International Conference on Learning Representations , year =
Denoising Diffusion Samplers , author =. International Conference on Learning Representations , year =
-
[8]
Proceedings of the Fortieth Conference on Uncertainty in Artificial Intelligence , articleno =
Deleu, Tristan and Nouri, Padideh and Malkin, Nikolay and Precup, Doina and Bengio, Yoshua , title =. Proceedings of the Fortieth Conference on Uncertainty in Artificial Intelligence , articleno =. 2024 , publisher =
2024
-
[9]
arXiv preprint arXiv:2510.05725 , url =
Improving Discrete Diffusion Unmasking Policies Beyond Explicit Reference Policies , author =. arXiv preprint arXiv:2510.05725 , url =. 2025 , eprint =
-
[10]
arXiv preprint arXiv:2503.05979 , url =
Learning-Order Autoregressive Models with Application to Molecular Graph Generation , author =. arXiv preprint arXiv:2503.05979 , url =. 2025 , eprint =
-
[11]
Learning Unmasking Policies for Diffusion Language Models
Learning Unmasking Policies for Diffusion Language Models , author =. arXiv preprint arXiv:2512.09106 , url =. 2025 , eprint =
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
arXiv preprint arXiv:2509.23405 , url =
Planner Aware Path Learning in Diffusion Language Models Training , author =. arXiv preprint arXiv:2509.23405 , url =. 2025 , eprint =
-
[13]
arXiv preprint arXiv:2509.23653 , url =
Don't Settle Too Early: Self-Reflective Remasking for Diffusion Language Models , author =. arXiv preprint arXiv:2509.23653 , url =. 2025 , eprint =
-
[14]
arXiv preprint arXiv:2510.08369 , url =
Guided Star-Shaped Masked Diffusion , author =. arXiv preprint arXiv:2510.08369 , url =. 2025 , eprint =
-
[15]
2021 , journal =
Evaluating Large Language Models Trained on Code , author =. 2021 , journal =
2021
-
[16]
2021 , journal =
Program Synthesis with Large Language Models , author =. 2021 , journal =
2021
-
[17]
2024 , journal =
Self-Improvement in Language Models: The Sharpening Mechanism , author =. 2024 , journal =
2024
-
[18]
arXiv preprint arXiv:2308.03686 , year =
Nearly d -linear convergence bounds for diffusion models via stochastic localization , author =. arXiv preprint arXiv:2308.03686 , year =
-
[19]
arXiv preprint arXiv:2505.17741 , year =
Discrete Neural Flow Samplers with Locally Equivariant Transformer , author =. arXiv preprint arXiv:2505.17741 , year =
-
[20]
arXiv preprint arXiv:2502.08696 , year =
Scalable discrete diffusion samplers: Combinatorial optimization and statistical physics , author =. arXiv preprint arXiv:2502.08696 , year =
-
[21]
arXiv preprint arXiv:2410.03601 , year =
How discrete and continuous diffusion meet: Comprehensive analysis of discrete diffusion models via a stochastic integral framework , author =. arXiv preprint arXiv:2410.03601 , year =
-
[22]
International Conference on Machine Learning (ICML) , year =
Discrete Markov Probabilistic Models: An Improved Discrete Score-Based Framework with sharp convergence bounds under minimal assumptions , author =. International Conference on Machine Learning (ICML) , year =
-
[23]
International Conference on Learning Representations (ICLR) , year =
Protein Language Model Fitness is a Matter of Preference , author =. International Conference on Learning Representations (ICLR) , year =
-
[24]
Physical review letters , volume =
Nonuniversal critical dynamics in Monte Carlo simulations , author =. Physical review letters , volume =. 1987 , publisher =
1987
-
[25]
2025 , journal =
Reasoning with Sampling: Your Base Model is Smarter Than You Think , author =. 2025 , journal =
2025
-
[26]
International Conference on Machine Learning (ICML) , year =
Diffusion Language Models Are Versatile Protein Learners , author =. International Conference on Machine Learning (ICML) , year =
-
[27]
2025 , journal =
Progressive Inference-Time Annealing of Diffusion Models for Sampling from Boltzmann Densities , author =. 2025 , journal =
2025
-
[28]
2024 , journal =
Diffusion Language Models Are Versatile Protein Learners , author =. 2024 , journal =
2024
-
[29]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
Language models are few-shot learners , author =. Advances in Neural Information Processing Systems (NeurIPS) , volume =
-
[30]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
Photorealistic text-to-image diffusion models with deep language understanding , author =. Advances in Neural Information Processing Systems (NeurIPS) , volume =
-
[31]
International Conference on Machine Learning (ICML) , year =
A General Framework for Inference-time Scaling and Steering of Diffusion Models , author =. International Conference on Machine Learning (ICML) , year =
-
[32]
arXiv preprint arXiv:2406.01572 , year =
Unlocking guidance for discrete state-space diffusion and flow models , author =. arXiv preprint arXiv:2406.01572 , year =
-
[33]
ProteinGym: Large-Scale Benchmarks for Protein Fitness Prediction and Design , year =
Notin, Pascal and Kollasch, Aaron and Ritter, Daniel and van Niekerk, Lood and Paul, Steffanie and Spinner, Han and Rollins, Nathan and Shaw, Ada and Orenbuch, Rose and Weitzman, Ruben and Frazer, Jonathan and Dias, Mafalda and Franceschi, Dinko and Gal, Yarin and Marks, Debora , journal =. ProteinGym: Large-Scale Benchmarks for Protein Fitness Prediction...
-
[34]
Zeming Lin and Halil Akin and Roshan Rao and Brian Hie and Zhongkai Zhu and Wenting Lu and Nikita Smetanin and Robert Verkuil and Ori Kabeli and Yaniv Shmueli and Allan dos Santos Costa and Maryam Fazel-Zarandi and Tom Sercu and Salvatore Candido and Alexander Rives , title =. Science , volume =. 2023 , doi =. https://www.science.org/doi/pdf/10.1126/scien...
-
[35]
and Subramanian, Subu and Mohr, Benjamin P
Madani, Ali and Krause, Ben and Greene, Eric R. and Subramanian, Subu and Mohr, Benjamin P. and Holton, James M. and Olmos, Jose Luis and Xiong, Caiming and Sun, Zachary Z. and Socher, Richard and Fraser, James S. and Naik, Nikhil , title =. Nature Biotechnology , year =. doi:10.1038/s41587-022-01618-2 , url =
-
[36]
International Conference on Artificial Neural Networks (ICANN) , volume =
Products of experts , author =. International Conference on Artificial Neural Networks (ICANN) , volume =. 1999 , organization =
1999
-
[37]
1931 , publisher =
Kolmogoroff, Andrei , journal =. 1931 , publisher =
1931
-
[38]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
Discrete flow matching , author =. Advances in Neural Information Processing Systems (NeurIPS) , volume =
-
[39]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume =
From denoising diffusions to denoising markov models , author =. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume =. 2024 , publisher =
2024
-
[40]
International Conference on Machine Learning (ICML) , year =
Discrete diffusion language modeling by estimating the ratios of the data distribution , author =. International Conference on Machine Learning (ICML) , year =
-
[41]
2014 , journal =
Generative Adversarial Networks , author =. 2014 , journal =
2014
-
[42]
2001 , publisher =
Monte Carlo Strategies in Scientific Computing , author =. 2001 , publisher =
2001
-
[43]
Science , volume =
Boltzmann generators: Sampling equilibrium states of many-body systems with deep learning , author =. Science , volume =. 2019 , publisher =
2019
-
[44]
Iterated
Akhound-Sadegh, Tara and Rector-Brooks, Jarrid and Bose, Avishek Joey and Mittal, Sarthak and Lemos, Pablo and Liu, Cheng-Hao and Sendera, Marcin and Ravanbakhsh, Siamak and Gidel, Gauthier and Bengio, Yoshua and Malkin, Nikolay and Tong, Alexander , year =. Iterated
-
[45]
arXiv preprint arXiv:2302.13834 , year =
Denoising diffusion samplers , author =. arXiv preprint arXiv:2302.13834 , year =
-
[46]
2015 , publisher =
Molecular Dynamics: With Deterministic and Stochastic Numerical Methods , author =. 2015 , publisher =
2015
-
[47]
International Conference on Machine Learning (ICML) , year =
Variational inference with normalizing flows , author =. International Conference on Machine Learning (ICML) , year =
-
[48]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
Improved variational inference with inverse autoregressive flow , author =. Advances in Neural Information Processing Systems (NeurIPS) , volume =
-
[49]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
Masked autoregressive flow for density estimation , author =. Advances in Neural Information Processing Systems (NeurIPS) , volume =
-
[50]
arXiv preprint arXiv:2410.02711 , year =
Nets: A non-equilibrium transport sampler , author =. arXiv preprint arXiv:2410.02711 , year =
-
[51]
The Journal of chemical physics , volume =
Escorted free energy simulations , author =. The Journal of chemical physics , volume =. 2011 , publisher =
2011
-
[52]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
Neural ordinary differential equations , author =. Advances in Neural Information Processing Systems (NeurIPS) , volume =
-
[53]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
Timewarp: Transferable acceleration of molecular dynamics by learning time-coarsened dynamics , author =. Advances in Neural Information Processing Systems (NeurIPS) , volume =
-
[54]
Statistics and computing , volume =
Annealed importance sampling , author =. Statistics and computing , volume =. 2001 , publisher =
2001
-
[55]
Physical Review Letters , volume =
Nonequilibrium equality for free energy differences , author =. Physical Review Letters , volume =. 1997 , publisher =
1997
-
[56]
Monographs on Statistics and Applied Probability , volume =
Mean field simulation for Monte Carlo integration , author =. Monographs on Statistics and Applied Probability , volume =. 2013 , publisher =
2013
-
[57]
Exponential convergence of Langevin distributions and their discrete approximations , author =
-
[58]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
Glow: Generative flow with invertible 1x1 convolutions , author =. Advances in Neural Information Processing Systems (NeurIPS) , volume =
-
[59]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Flow straight and fast: Learning to generate and transfer data with rectified flow , author =. arXiv preprint arXiv:2209.03003 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[60]
Rectified Flow: A Marginal Preserving Approach to Optimal Transport , author =
-
[61]
2023 , journal =
Improving and Generalizing Flow-Based Generative Models with Minibatch Optimal Transport , author =. 2023 , journal =
2023
-
[62]
Flow Matching for Generative Modeling , author =
-
[63]
2023 , journal =
Stochastic Interpolants: A Unifying Framework for Flows and Diffusions , author =. 2023 , journal =
2023
-
[64]
Density estimation using Real NVP
Density estimation using real nvp , author =. arXiv preprint arXiv:1605.08803 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[65]
2018 , primaryclass =
Glow: Generative Flow with Invertible 1x1 Convolutions , author =. 2018 , primaryclass =
2018
-
[66]
arXiv preprint arXiv:2412.15129 , year =
Jet: A Modern Transformer-Based Normalizing Flow , author =. arXiv preprint arXiv:2412.15129 , year =
-
[67]
FFJORD: Free-form Continuous Dynamics for Scalable Reversible Generative Models , author =
-
[68]
and Ojoawo, Adebayo and Otten, Ren
Wayment-Steele, Hannah K. and Ojoawo, Adebayo and Otten, Ren. Predicting multiple conformations via sequence clustering and AlphaFold2 , journal =. 2024 , doi =
2024
-
[69]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
Neural spline flows , author =. Advances in Neural Information Processing Systems (NeurIPS) , volume =
-
[70]
2021 , journal =
Score-Based Generative Modeling through Stochastic Differential Equations , author =. 2021 , journal =
2021
-
[71]
Scalable emulation of protein equilibrium ensembles with generative deep learning , elocation-id =
Lewis, Sarah and Hempel, Tim and Jim. Scalable emulation of protein equilibrium ensembles with generative deep learning , elocation-id =. 2025 , doi =. https://www.biorxiv.org/content/early/2025/02/25/2024.12.05.626885.full.pdf , journal =
2025
-
[72]
2025 , journal =
The Open Molecules 2025 (OMol25) Dataset, Evaluations, and Models , author =. 2025 , journal =
2025
-
[73]
2020 , journal =
Denoising Diffusion Probabilistic Models , author =. 2020 , journal =
2020
-
[74]
Accurate structure prediction of biomolecular interactions with. Nature , author =. 2024 , note =. doi:10.1038/s41586-024-07487-w , abstract =
-
[75]
Temperature steerable flows and
Dibak, Manuel and Klein, Leon and Kr\"amer, Andreas and No\'e, Frank , journal =. Temperature steerable flows and. 2022 , month =
2022
-
[76]
Large Language Diffusion Models
Large Language Diffusion Models , author =. arXiv preprint arXiv:2502.09992 , url =. 2025 , eprint =
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[77]
International Conference on Machine Learning (ICML) , year =
Peter Holderrieth and Michael Samuel Albergo and Tommi Jaakkola , booktitle =. International Conference on Machine Learning (ICML) , year =
-
[78]
arXiv preprint arXiv:2502.06079 , year =
Debiasing Guidance for Discrete Diffusion with Sequential Monte Carlo , author =. arXiv preprint arXiv:2502.06079 , year =
-
[79]
RNE: plug-and-play diffusion inference-time control and energy-based training
RNE: a plug-and-play framework for diffusion density estimation and inference-time control , author =. arXiv preprint arXiv:2506.05668 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[80]
arXiv preprint arXiv:2412.17780 , year =
Peptune: De novo generation of therapeutic peptides with multi-objective-guided discrete diffusion , author =. arXiv preprint arXiv:2412.17780 , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.