Is Zero-Shot Super-Resolution Possible in Operator Learning?
Pith reviewed 2026-06-28 19:50 UTC · model grok-4.3
The pith
Zero-shot super-resolution is information-theoretically impossible for some operator learning tasks, even with full-continuum inputs and rank-one linear ground truth.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
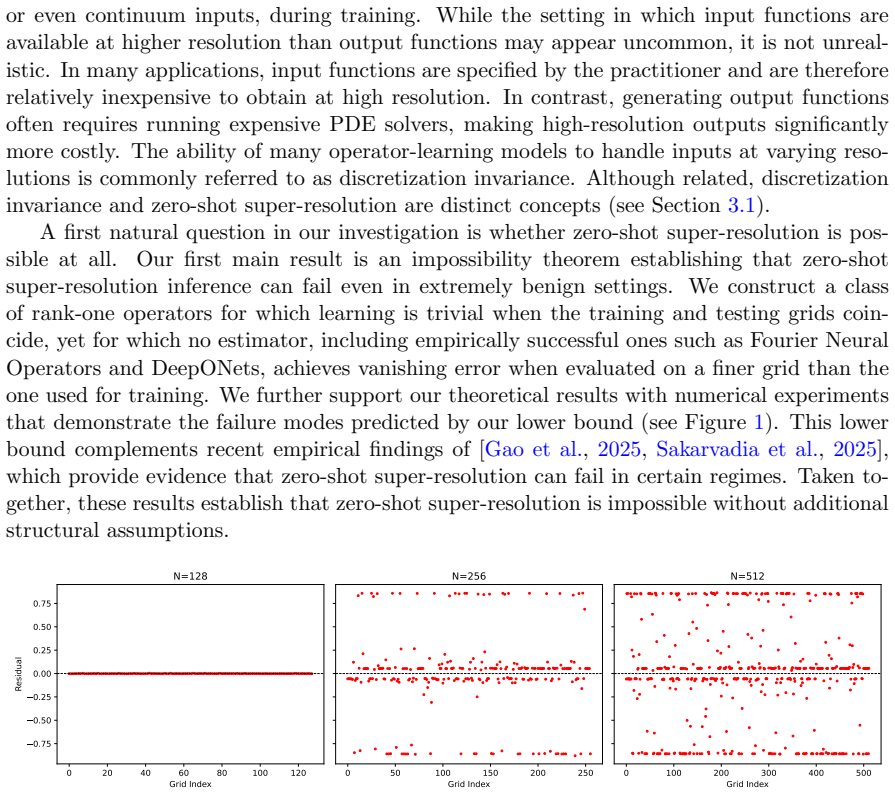
Zero-shot super-resolution can be impossible even in benign settings where input functions are defined over the entire continuum and the ground truth is a rank-one linear operator. Hölder smoothness of the output functions is a sufficient condition that enables zero-shot super-resolution, and corresponding generalization bounds are derived. The identified failure modes are validated experimentally.
What carries the argument
The rank-one linear operator construction that demonstrates information-theoretic impossibility, together with the Hölder smoothness condition that serves as a sufficient criterion for success.
If this is right
- Operator learning models may need task-specific retraining or additional data at finer resolutions in cases where the underlying operator lacks sufficient smoothness.
- Hölder smoothness of outputs guarantees that coarse-grid training transfers to finer grids with quantifiable error bounds.
- Failure modes identified for rank-one linear operators can appear in more complex settings that contain similar low-rank structure.
Where Pith is reading between the lines
- Empirical reports of zero-shot super-resolution in practice may be succeeding because real data distributions implicitly satisfy smoothness conditions stronger than the worst-case rank-one example.
- The same information-theoretic barrier could apply to other resolution-transfer problems in function approximation beyond neural operators.
Load-bearing premise
The ground truth operator is modeled as a rank-one linear operator whose inputs are available over the full continuum.
What would settle it
An explicit construction or numerical experiment in which a model trained only on coarse discretizations of a rank-one linear operator achieves low error on a finer discretization without any retraining would falsify the impossibility claim.
Figures

read the original abstract
Neural operators are often reported to exhibit zero-shot super-resolution, a phenomenon in which a model trained on coarse grids produces accurate predictions on finer testing grids without additional retraining. Despite strong empirical evidence, the theoretical foundations of this phenomenon remain unclear. In this work, we provide a systematic theoretical study of zero-shot super-resolution in operator learning. We first show that zero-shot super-resolution can be information-theoretically impossible even in benign settings such as when the input functions are available over the entire continuum and the ground truth is a simple rank-one linear operator. We then identify H{\" o}lder smoothness of the output functions as a sufficient condition for zero-shot super-resolution and derive corresponding generalization bounds. Finally, we also validate the identified failure modes through experimental results.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that zero-shot super-resolution can be information-theoretically impossible for neural operators even in benign settings where input functions are defined over the full continuum and the ground truth is a rank-one linear operator. It identifies Hölder smoothness of the output functions as a sufficient condition, derives corresponding generalization bounds, and validates the identified failure modes through experiments.
Significance. If the central claims hold, the work supplies a useful theoretical limit on zero-shot capabilities together with a sufficient condition and bounds; this is a meaningful contribution to the foundations of operator learning given the prevalence of empirical reports of the phenomenon.
major comments (2)
- [Impossibility result] The impossibility result is derived under the explicit modeling choice of a rank-one linear operator with continuum inputs; while the paper states this as the setting for the negative result, the load-bearing step is whether the information-theoretic argument extends beyond this construction or remains an existence result only for this narrow case (see the section presenting the impossibility argument).
- [Generalization bounds] The generalization bounds under the Hölder condition rely on function-space assumptions; verify that the discretization of the continuum inputs does not introduce additional approximation terms that would weaken the zero-shot claim (see the section deriving the bounds).
minor comments (2)
- [Experiments] Clarify the precise definition of 'zero-shot' in the experimental section to distinguish it from standard fine-grid testing.
- Add a short discussion contrasting the rank-one case with typical nonlinear operators encountered in applications.
Simulated Author's Rebuttal
We thank the referee for the constructive review and the recommendation of minor revision. We address each major comment below.
read point-by-point responses
-
Referee: [Impossibility result] The impossibility result is derived under the explicit modeling choice of a rank-one linear operator with continuum inputs; while the paper states this as the setting for the negative result, the load-bearing step is whether the information-theoretic argument extends beyond this construction or remains an existence result only for this narrow case (see the section presenting the impossibility argument).
Authors: The result is deliberately an existence proof showing that zero-shot super-resolution can be information-theoretically impossible even under the stated benign conditions (continuum inputs and rank-one linear operator). Its purpose is to demonstrate that the phenomenon is not guaranteed in general, thereby providing a theoretical limit rather than a universal negative claim. The argument is not asserted to extend to arbitrary operators. We will add a clarifying sentence in the impossibility section to emphasize the existence-result interpretation. revision: partial
-
Referee: [Generalization bounds] The generalization bounds under the Hölder condition rely on function-space assumptions; verify that the discretization of the continuum inputs does not introduce additional approximation terms that would weaken the zero-shot claim (see the section deriving the bounds).
Authors: The bounds are derived in the continuous function space, where the Hölder condition directly controls the modulus of continuity and thereby bounds the discretization error uniformly. Because the zero-shot claim concerns the operator learned on coarse grids generalizing to fine grids, the smoothness assumption ensures that any discretization discrepancy is absorbed into the existing Hölder term without introducing new factors that would invalidate the zero-shot guarantee. We will insert a short remark after the bound statement to make this discretization control explicit. revision: yes
Circularity Check
No significant circularity; derivation self-contained
full rationale
The paper's central results—an information-theoretic impossibility result for zero-shot super-resolution under the explicit modeling choice of rank-one linear operators with continuum inputs, plus a sufficient condition via Hölder smoothness and associated generalization bounds—are derived from standard function-space and information-theoretic arguments rather than any self-referential construction, fitted parameter renamed as prediction, or load-bearing self-citation. The modeling assumptions are stated as the specific setting in which the negative result holds, with no reduction of the claimed derivation to its own inputs by definition. Experiments serve as validation only and do not underpin the theoretical claims.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard properties of neural operators and Sobolev/Hölder function spaces used in operator learning theory
Reference graph
Works this paper leans on
-
[1]
The probabilistic method
Noga Alon and Joel H Spencer. The probabilistic method. John Wiley & Sons, 2016
2016
-
[2]
Neural operators for accelerating scientific simulations and design
Kamyar Azizzadenesheli, Nikola Kovachki, Zongyi Li, Miguel Liu-Schiaffini, Jean Kossaifi, and Anima Anandkumar. Neural operators for accelerating scientific simulations and design. Nature Reviews Physics, 6 0 (5): 0 320--328, 2024
2024
-
[3]
Representation equivalent neural operators: a framework for alias-free operator learning
Francesca Bartolucci, Emmanuel de Bezenac, Bogdan Raonic, Roberto Molinaro, Siddhartha Mishra, and Rima Alaifari. Representation equivalent neural operators: a framework for alias-free operator learning. Advances in Neural Information Processing Systems, 36: 0 69661--69672, 2023
2023
-
[4]
Model reduction and neural networks for parametric pdes
Kaushik Bhattacharya, Bamdad Hosseini, Nikola B Kovachki, and Andrew M Stuart. Model reduction and neural networks for parametric pdes. The SMAI journal of computational mathematics, 7: 0 121--157, 2021
2021
-
[6]
Partial differential equations, volume 19
Lawrence C Evans. Partial differential equations, volume 19. American Mathematical Society, 2022
2022
-
[7]
Real analysis: modern techniques and their applications
Gerald B Folland. Real analysis: modern techniques and their applications. John Wiley & Sons, 1999
1999
-
[8]
Discretization-invariance? on the discretization mismatch errors in neural operators
Wenhan Gao, Ruichen Xu, Yuefan Deng, and Yi Liu. Discretization-invariance? on the discretization mismatch errors in neural operators. In The Thirteenth International Conference on Learning Representations, 2025
2025
-
[9]
Elliptic partial differential equations of second order, volume 224
David Gilbarg and Neil S Trudinger. Elliptic partial differential equations of second order, volume 224. Springer, 1977
1977
-
[10]
Green's functions and finite elements
Friedel Hartmann. Green's functions and finite elements. Springer Science & Business Media, 2012
2012
-
[11]
Efficient super-resolution of near-surface climate modeling using the fourier neural operator
Peishi Jiang, Zhao Yang, Jiali Wang, Chenfu Huang, Pengfei Xue, TC Chakraborty, Xingyuan Chen, and Yun Qian. Efficient super-resolution of near-surface climate modeling using the fourier neural operator. Journal of Advances in Modeling Earth Systems, 15 0 (7): 0 e2023MS003800, 2023
2023
-
[12]
On universal approximation and error bounds for fourier neural operators
Nikola Kovachki, Samuel Lanthaler, and Siddhartha Mishra. On universal approximation and error bounds for fourier neural operators. Journal of Machine Learning Research, 22 0 (290): 0 1--76, 2021
2021
-
[13]
Neural operator: Learning maps between function spaces with applications to pdes
Nikola Kovachki, Zongyi Li, Burigede Liu, Kamyar Azizzadenesheli, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Neural operator: Learning maps between function spaces with applications to pdes. Journal of Machine Learning Research, 24 0 (89): 0 1--97, 2023
2023
-
[16]
Fourier neural operator for parametric partial differential equations
Zongyi Li, Nikola Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Fourier neural operator for parametric partial differential equations. International Conference on Learning Representations, 2021
2021
-
[17]
Physics-informed neural operator for learning partial differential equations
Zongyi Li, Hongkai Zheng, Nikola Kovachki, David Jin, Haoxuan Chen, Burigede Liu, Kamyar Azizzadenesheli, and Anima Anandkumar. Physics-informed neural operator for learning partial differential equations. ACM/IMS Journal of Data Science, 1 0 (3): 0 1--27, 2024
2024
-
[18]
Learning nonlinear operators via deeponet based on the universal approximation theorem of operators
Lu Lu, Pengzhan Jin, Guofei Pang, Zhongqiang Zhang, and George Em Karniadakis. Learning nonlinear operators via deeponet based on the universal approximation theorem of operators. Nature machine intelligence, 3 0 (3): 0 218--229, 2021
2021
-
[19]
Hierarchical neural operator transformer with learnable frequency-aware loss prior for arbitrary-scale super-resolution
Xihaier Luo, Xiaoning Qian, and Byung-Jun Yoon. Hierarchical neural operator transformer with learnable frequency-aware loss prior for arbitrary-scale super-resolution. In Proceedings of the 41st International Conference on Machine Learning, pages 33466--33485, 2024
2024
-
[20]
Scattering with neural operators
Sebastian Mizera. Scattering with neural operators. Physical Review D, 108 0 (10): 0 L101701, 2023
2023
-
[21]
The random feature model for input-output maps between banach spaces
Nicholas H Nelsen and Andrew M Stuart. The random feature model for input-output maps between banach spaces. SIAM Journal on Scientific Computing, 43 0 (5): 0 A3212--A3243, 2021
2021
-
[22]
Convolutional neural operators for robust and accurate learning of pdes
Bogdan Raonic, Roberto Molinaro, Tim De Ryck, Tobias Rohner, Francesca Bartolucci, Rima Alaifari, Siddhartha Mishra, and Emmanuel de B \'e zenac. Convolutional neural operators for robust and accurate learning of pdes. Advances in Neural Information Processing Systems, 36: 0 77187--77200, 2023
2023
-
[24]
On the effectiveness of neural operators at zero-shot weather downscaling
Saumya Sinha, Brandon Benton, and Patrick Emami. On the effectiveness of neural operators at zero-shot weather downscaling. Environmental Data Science, 4: 0 e21, 2025
2025
-
[25]
Operator learning: A statistical perspective
Unique Subedi and Ambuj Tewari. Operator learning: A statistical perspective. Annual Review of Statistics and Its Application, 13, 2025
2025
-
[27]
Scattered data approximation, volume 17
Holger Wendland. Scattered data approximation, volume 17. Cambridge university press, 2004
2004
-
[28]
Fourier neural operators for arbitrary resolution climate data downscaling
Qidong Yang, Alex Hernandez-Garcia, Paula Harder, Venkatesh Ramesh, Prasanna Sattigeri, Daniela Szwarcman, Campbell D Watson, and David Rolnick. Fourier neural operators for arbitrary resolution climate data downscaling. Journal of Machine Learning Research, 25 0 (420): 0 1--30, 2024
2024
-
[30]
1999 , publisher=
Real analysis: modern techniques and their applications , author=. 1999 , publisher=
1999
-
[31]
2016 , publisher=
The probabilistic method , author=. 2016 , publisher=
2016
-
[32]
Physical Review D , volume=
Scattering with neural operators , author=. Physical Review D , volume=. 2023 , publisher=
2023
-
[33]
On numerical solutions of the time-dependent Schr
van Dijk, Wytse , journal=. On numerical solutions of the time-dependent Schr. 2023 , publisher=
2023
-
[34]
Numerical resolution of the Schr
J. Numerical resolution of the Schr
-
[35]
Efficiency and accuracy of numerical solutions to the time-dependent Schr
van Dijk, W and Brown, J and Spyksma, K , journal=. Efficiency and accuracy of numerical solutions to the time-dependent Schr. 2011 , publisher=
2011
-
[36]
Numerical solutions of the time-dependent Schr\"odinger equation: Reduction of the error due to space discretization , author =. Phys. Rev. E , volume =. 2009 , month =. doi:10.1103/PhysRevE.79.056705 , url =
-
[37]
Accurate numerical solutions of the time-dependent Schr\"odinger equation , author =. Phys. Rev. E , volume =. 2007 , month =. doi:10.1103/PhysRevE.75.036707 , url =
-
[38]
2015 , publisher=
Theoretical foundations of functional data analysis, with an introduction to linear operators , author=. 2015 , publisher=
2015
-
[39]
2005 , publisher=
Functional Data Analysis , author=. 2005 , publisher=
2005
-
[40]
Journal of Machine Learning Research , volume=
Neural operator: Learning maps between function spaces with applications to pdes , author=. Journal of Machine Learning Research , volume=
-
[41]
International Conference on Learning Representations , year=
Fourier neural operator for parametric partial differential equations , author=. International Conference on Learning Representations , year=
-
[42]
2008 , publisher=
Classical fourier analysis , author=. 2008 , publisher=
2008
-
[43]
and Lanthaler, Samuel and Stuart, Andrew M
Operator Learning: Algorithms and Analysis , author=. arXiv preprint arXiv:2402.15715 , year=
-
[44]
Partial Differential Equations
Taylor, Michael E , publisher=. Partial Differential Equations
-
[45]
Advances in neural information processing systems , volume=
Multiwavelet-based operator learning for differential equations , author=. Advances in neural information processing systems , volume=
-
[46]
Computer Methods in Applied Mechanics and Engineering , volume=
Wavelet neural operator for solving parametric partial differential equations in computational mechanics problems , author=. Computer Methods in Applied Mechanics and Engineering , volume=. 2023 , publisher=
2023
-
[47]
Doklady Mathematics , volume=
Spectral neural operators , author=. Doklady Mathematics , volume=. 2023 , organization=
2023
-
[48]
arXiv preprint arXiv:2312.14688 , year=
A mathematical guide to operator learning , author=. arXiv preprint arXiv:2312.14688 , year=
-
[49]
Proceedings of the National Academy of Sciences , volume=
Elliptic PDE learning is provably data-efficient , author=. Proceedings of the National Academy of Sciences , volume=. 2023 , publisher=
2023
-
[50]
Journal of Machine Learning Research , volume=
On universal approximation and error bounds for Fourier neural operators , author=. Journal of Machine Learning Research , volume=
-
[51]
Machine Learning , volume=
Bounding the Rademacher complexity of Fourier neural operators , author=. Machine Learning , volume=. 2024 , publisher=
2024
-
[52]
arXiv preprint arXiv:2405.15992 , year=
Data Complexity Estimates for Operator Learning , author=. arXiv preprint arXiv:2405.15992 , year=
-
[53]
arXiv preprint arXiv:2405.02221 , year=
Discretization error of Fourier neural operators , author=. arXiv preprint arXiv:2405.02221 , year=
-
[54]
International Conference on Algorithmic Learning Theory , pages=
Online Infinite-Dimensional Regression: Learning Linear Operators , author=. International Conference on Algorithmic Learning Theory , pages=. 2024 , organization=
2024
-
[55]
Learning Schatten--von Neumann Operators
Learning Schatten--von Neumann Operators , author=. arXiv preprint arXiv:1901.10076 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[56]
SIAM/ASA Journal on Uncertainty Quantification , volume=
Convergence rates for learning linear operators from noisy data , author=. SIAM/ASA Journal on Uncertainty Quantification , volume=. 2023 , publisher=
2023
-
[57]
Annual Review of Statistics and its application , volume=
Functional data analysis , author=. Annual Review of Statistics and its application , volume=. 2016 , publisher=
2016
-
[58]
The Annals of Statistics , pages=
SINGLE AND MULTIPLE INDEX FUNCTIONAL REGRESSION MODELS WITH NONPARAMETRIC LINK , author=. The Annals of Statistics , pages=. 2011 , publisher=
2011
-
[59]
Scandinavian journal of statistics , volume=
A note on estimation in Hilbertian linear models , author=. Scandinavian journal of statistics , volume=. 2015 , publisher=
2015
-
[60]
arXiv preprint arXiv:2211.08875 , year=
Learning linear operators: Infinite-dimensional regression as a well-behaved non-compact inverse problem , author=. arXiv preprint arXiv:2211.08875 , year=
-
[61]
Statistics & Probability Letters , volume=
Functional regression with repeated eigenvalues , author=. Statistics & Probability Letters , volume=. 2015 , publisher=
2015
-
[62]
The Annals of Statistics , volume=
FUNCTIONAL LINEAR REGRESSION ANALYSIS FOR LONGITUDINAL DATA , author=. The Annals of Statistics , volume=
-
[63]
Advances in neural information processing systems , volume=
Neural tangent kernel: Convergence and generalization in neural networks , author=. Advances in neural information processing systems , volume=
-
[64]
Advances in Neural Information Processing Systems , volume=
Faster rates in regression via active learning , author=. Advances in Neural Information Processing Systems , volume=
-
[65]
Foundations and Trends in Machine Learning , pages=
A statistical theory of active learning , author=. Foundations and Trends in Machine Learning , pages=. 2013 , publisher=
2013
-
[66]
Dolomites Research Notes on Approximation , volume=
Positive definite kernels: past, present and future , author=. Dolomites Research Notes on Approximation , volume=
-
[67]
2006 , publisher=
Gaussian processes for machine learning , author=. 2006 , publisher=
2006
-
[68]
Journal of Applied Mechanics , volume=
The numerical treatment of integral equations , author=. Journal of Applied Mechanics , volume=
-
[69]
Nature machine intelligence , volume=
Learning nonlinear operators via DeepONet based on the universal approximation theorem of operators , author=. Nature machine intelligence , volume=. 2021 , publisher=
2021
-
[70]
The SMAI journal of computational mathematics , volume=
Model reduction and neural networks for parametric PDEs , author=. The SMAI journal of computational mathematics , volume=
-
[71]
arXiv preprint , year=
Error Bounds for Learning Fourier Linear Operators , author=. arXiv preprint , year=
-
[72]
Calcolo , volume=
Optimal approximation of infinite-dimensional holomorphic functions , author=. Calcolo , volume=. 2024 , publisher=
2024
-
[73]
SIAM Journal on Scientific Computing , volume=
The random feature model for input-output maps between banach spaces , author=. SIAM Journal on Scientific Computing , volume=. 2021 , publisher=
2021
-
[74]
Journal of Machine Learning Research , volume=
Deep nonparametric estimation of operators between infinite dimensional spaces , author=. Journal of Machine Learning Research , volume=
-
[75]
International Conference on Machine Learning (Tutorial) , year=
Neural Operator Learning , author=. International Conference on Machine Learning (Tutorial) , year=
-
[76]
2014 , publisher=
An introduction to computational stochastic PDEs , author=. 2014 , publisher=
2014
-
[77]
arXiv preprint arXiv:2408.01536 , year=
Active Learning for Neural PDE Solvers , author=. arXiv preprint arXiv:2408.01536 , year=
-
[78]
International Conference on Artificial Intelligence and Statistics , pages=
Multi-Resolution Active Learning of Fourier Neural Operators , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2024 , organization=
2024
-
[79]
Machine learning , volume=
Queries and concept learning , author=. Machine learning , volume=. 1988 , publisher=
1988
-
[80]
2009 , publisher=
Active learning literature survey , author=. 2009 , publisher=
2009
-
[81]
Algorithmic Learning Theory: 12th International Conference, ALT 2001 Washington, DC, USA, November 25--28, 2001 Proceedings 12 , pages=
Queries revisited , author=. Algorithmic Learning Theory: 12th International Conference, ALT 2001 Washington, DC, USA, November 25--28, 2001 Proceedings 12 , pages=. 2001 , organization=
2001
-
[82]
Advances in neural information processing systems , volume=
Training connectionist networks with queries and selective sampling , author=. Advances in neural information processing systems , volume=
-
[83]
SIGIR'94: Proceedings of the Seventeenth Annual International ACM-SIGIR Conference on Research and Development in Information Retrieval , pages=
A sequential algorithmfor training text classifiers , author=. SIGIR'94: Proceedings of the Seventeenth Annual International ACM-SIGIR Conference on Research and Development in Information Retrieval , pages=
-
[84]
Transactions of Mathematics and Its Applications , volume=
Error estimates for deeponets: A deep learning framework in infinite dimensions , author=. Transactions of Mathematics and Its Applications , volume=. 2022 , publisher=
2022
-
[85]
Journal of Machine Learning Research , volume=
Operator learning with PCA-Net: upper and lower complexity bounds , author=. Journal of Machine Learning Research , volume=
-
[86]
1977 , publisher=
Elliptic partial differential equations of second order , author=. 1977 , publisher=
1977
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.