Adversarially Robust Control of Conditional Value-at-Risk via Rockafellar-Uryasev Conformal Inference
Pith reviewed 2026-06-28 23:17 UTC · model grok-4.3
The pith
An online conformal procedure controls CVaR at a target level under any adversarial non-stationary process.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central discovery is a procedure that leverages the Rockafellar-Uryasev representation to cast CVaR control as a problem solvable by conformal inference in an online fashion, delivering asymptotic control of the empirical CVaR at the target level for any data-generating process, with the control being asymptotically tight apart from a finite-sample conservatism gap.
What carries the argument
The Rockafellar-Uryasev variational representation of CVaR, which reduces the risk measure to an optimization problem that conformal tail risk control can handle online.
If this is right
- The framework applies directly to portfolio risk management under non-stationary market conditions.
- It enables toxicity mitigation in LLMs by controlling the risk of rare but severe failures.
- Safety guarantees hold for any non-stationary or strategically shifting data process.
- The control achieves asymptotic tightness, avoiding unnecessary conservatism in the long run.
Where Pith is reading between the lines
- The method could generalize to controlling other tail-based risk measures in adversarial settings.
- It suggests a way to maintain safety in deployed systems without assuming the environment remains fixed after training.
- Practical tests on drifting real-world data streams would quantify the size of the finite-sample gap.
Load-bearing premise
The Rockafellar-Uryasev representation allows the transfer of conformal tail risk control guarantees to the fully adversarial non-stationary case.
What would settle it
An experiment in which an adversary manipulates the data sequence so that the long-run empirical CVaR stays strictly above the target level by more than the predicted gap would falsify the asymptotic control claim.
Figures

read the original abstract
We present an online, distribution-free framework for controlling the Conditional Value-at-Risk (CVaR), extending conformal tail risk control to non-stationary and adversarial environments. Unlike classical risk control methods, which rely on stationarity or linearity of expectation, our approach provides provable safety guarantees for a nonlinear tail risk functional under arbitrary data-generating processes that may drift or shift strategically over time. By leveraging deep connections between conformal tail risk control, online learning, and the variational representation of CVaR introduced by Rockafellar and Uryasev, we develop a novel procedure for online CVaR control with adversarial regret guarantees. The proposed method operates without assumptions on the underlying data-generating process, making it broadly applicable in modern high-stakes deployment settings. We prove that the realized empirical CVaR is asymptotically controlled at the target level, and that the resulting control is asymptotically tight up to a finite-sample conservatism gap. We demonstrate the effectiveness of our approach on portfolio risk management and toxicity mitigation for Large Language Models (LLMs), where rare but catastrophic failures dominate system risk.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an online, distribution-free method for controlling Conditional Value-at-Risk (CVaR) in non-stationary adversarial settings. It extends conformal tail-risk control by combining it with online learning and the Rockafellar-Uryasev variational representation of CVaR, claiming provable safety under arbitrary data-generating processes, asymptotic control of the realized empirical CVaR at the target level, and asymptotic tightness up to a finite-sample gap. Applications to portfolio risk management and LLM toxicity mitigation are mentioned.
Significance. If the central guarantees hold without hidden assumptions on the loss or process, the result would extend conformal methods to nonlinear tail functionals with regret bounds under adversarial shifts, offering a concrete tool for high-stakes risk control where stationarity cannot be assumed.
major comments (1)
- [Abstract (proof claims) and the section deriving the online procedure] The abstract asserts that sublinear regret on the auxiliary online problem yields asymptotic control of the realized empirical CVaR under arbitrary adversarial shifts, yet no explicit construction, uniform convergence argument, or error bound is supplied showing how the variational minimum of the RU representation is tracked when the data-generating process is chosen adversarially at each step. This step is load-bearing for the strongest claim.
minor comments (2)
- Notation for the target level α and the auxiliary online problem should be introduced with explicit definitions before the regret analysis.
- The finite-sample conservatism gap is mentioned but not quantified with explicit rates or dependence on dimension or horizon.
Simulated Author's Rebuttal
We thank the referee for the careful review and constructive feedback on the proof structure. We address the single major comment below and will revise the manuscript to provide the requested explicit arguments.
read point-by-point responses
-
Referee: [Abstract (proof claims) and the section deriving the online procedure] The abstract asserts that sublinear regret on the auxiliary online problem yields asymptotic control of the realized empirical CVaR under arbitrary adversarial shifts, yet no explicit construction, uniform convergence argument, or error bound is supplied showing how the variational minimum of the RU representation is tracked when the data-generating process is chosen adversarially at each step. This step is load-bearing for the strongest claim.
Authors: We agree that the manuscript would benefit from a more explicit derivation connecting the sublinear regret of the auxiliary online convex program to the asymptotic CVaR control. While Section 3 derives the online update rule using the Rockafellar-Uryasev representation and Section 4 states the main asymptotic theorem, the chaining argument via uniform convergence of the variational objective under adversarial shifts is only outlined rather than fully expanded with an error bound. In the revised version we will add a dedicated lemma (and supporting proof) that (i) uses the o(T) regret to show that the time-averaged RU objective converges to its infimum, (ii) invokes the conformal threshold update to control the deviation of the empirical tail, and (iii) supplies an explicit finite-sample gap term that vanishes asymptotically even when the data-generating process is chosen adversarially at each step. This will make the load-bearing step fully rigorous without altering the stated claims. revision: yes
Circularity Check
No circularity; derivation relies on external variational representation and conformal methods without self-referential reduction.
full rationale
The provided abstract and context cite the Rockafellar-Uryasev representation as an external input and describe an online procedure combining conformal tail control with regret bounds. No equations, self-citations, or fitted parameters are shown that reduce the asymptotic CVaR control claim to a tautology or prior author result by construction. The central guarantee is presented as a proof combining independent components rather than a renaming or self-definition. Without explicit load-bearing self-citations or fitted-input predictions in the given material, the derivation is treated as self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Angelopoulos, A. N., Bates, S., Cand`es, E. J., Jordan, M. I., and Lei, L. Learn then test: Calibrating predictive al- gorithms to achieve risk control.The Annals of Applied Statistics, 19(2):1641–1662, 2025a. Angelopoulos, A. N., Bates, S., Fisch, A., Lei, L., and Schuster, T. Conformal risk control. InThe Twelfth International Conference on Learning Rep...
-
[2]
doi: 10.1111/j.1467-9965.2007.00311
ISSN 1467-9965. doi: 10.1111/j.1467-9965.2007.00311. x. URL https://onlinelibrary.wiley.com/ doi/10.1111/j.1467-9965.2007.00311.x. Chen, C. Y .-C., Shen, J., Deng, Z., and Lei, L. Conformal tail risk control for large language model alignment,
-
[3]
URLhttps://arxiv.org/abs/2502.20285. cjadams, andinversion, D. B., Sorensen, J., Dixon, L., Vasserman, L., and nithum. Jigsaw unintended bias in toxicity classification,
-
[4]
P., Eyre, B., Inamdar, A., Madras, D., and Zemel, R
Deng, Z., Zollo, T. P., Eyre, B., Inamdar, A., Madras, D., and Zemel, R. Quest: Enhancing estimates of quantile- based distributional measures using model predictions. arXiv preprint arXiv:2507.05220,
-
[5]
RealToxicityPrompts: Evaluating Neural Toxic Degeneration in Language Models
Accessed via public API. Gehman, S., Gururangan, S., Sap, M., Choi, Y ., and Smith, N. A. Realtoxicityprompts: Evaluating neural toxic degeneration in language models.arXiv preprint arXiv:2009.11462,
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[6]
Crafting papers on machine learning
Langley, P. Crafting papers on machine learning. In Langley, P. (ed.),Proceedings of the 17th International Conference on Machine Learning (ICML 2000), pp. 1207–1216, Stan- ford, CA,
2000
-
[7]
Lei, L., Sahoo, R., and Wager, S
Morgan Kaufmann. Lei, L., Sahoo, R., and Wager, S. Policy learning under bi- ased sample selection.arXiv preprint arXiv:2304.11735,
-
[8]
URLhttps://arxiv.org/abs/2310.05921. McMahan, H. B. Follow-the-regularized-leader and mirror descent: Equivalence theorems and l1 regularization. In Proceedings of the 14th International Conference on Arti- ficial Intelligence and Statistics (AISTATS), volume 15 of JMLR Workshop and Conference Proceedings, pp. 525– 533,
-
[9]
Red Teaming Language Models with Language Models
URL https://arxiv.org/abs/2202.03286. Rockafellar, R. T. and Uryasev, S. Optimization of conditional value-at-risk.Journal of Risk, 2(3):21–42,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Tyrrell Rockafellar and Stanislav Uryasev
doi: 10.21314/JOR.2000.038. URL https: //www.risk.net/journal-risk/2161159/ optimization-conditional-value-risk. Sahoo, R., Lei, L., and Wager, S. Learning from a biased sample,
-
[11]
URL https://arxiv.org/abs/ 2209.01754. Shalev-Shwartz, S. Online learning and online convex opti- mization.Foundations and Trends in Machine Learning, 4(2):107–194,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
URL https://arxiv.org/abs/2212.13629. 10 Adversarially Robust Control of Conditional Value-at-Risk via Rockafellar-Uryasev Conformal Inference Yang, Z., Cand `es, E., and Lei, L. Bellman conformal inference: Calibrating prediction intervals for time se- ries,
-
[13]
Zollo, T., Morrill, T., Deng, Z., Snell, J., Pitassi, T., and Zemel, R
URL https://arxiv.org/ abs/2510.08748. Zollo, T., Morrill, T., Deng, Z., Snell, J., Pitassi, T., and Zemel, R. Prompt risk control: A rigorous framework for responsible deployment of large language models. In International Conference on Learning Representations, volume 2024, pp. 4045–4067, 2024a. Zollo, T. P., Morrill, T., Deng, Z., Snell, J. C., Pitassi,...
-
[14]
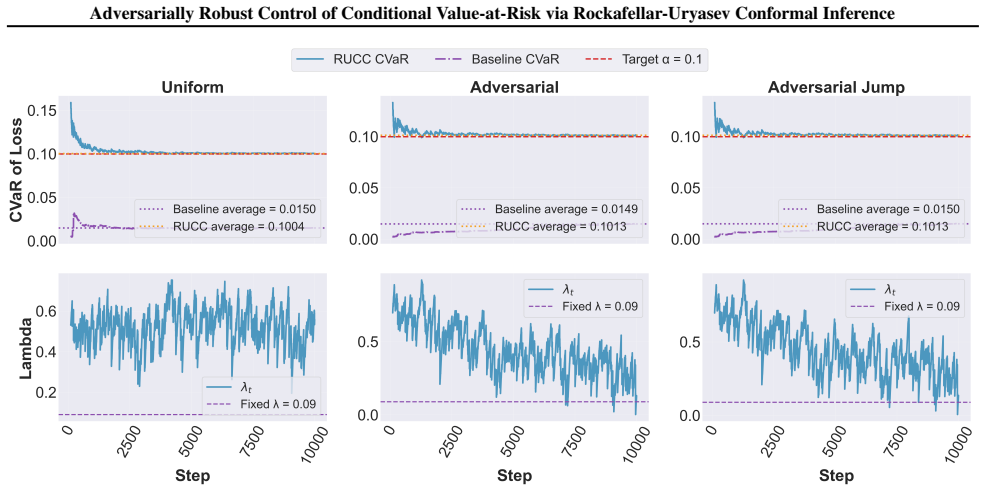
Initially, λt remains large, corresponding to less aggressive filtering
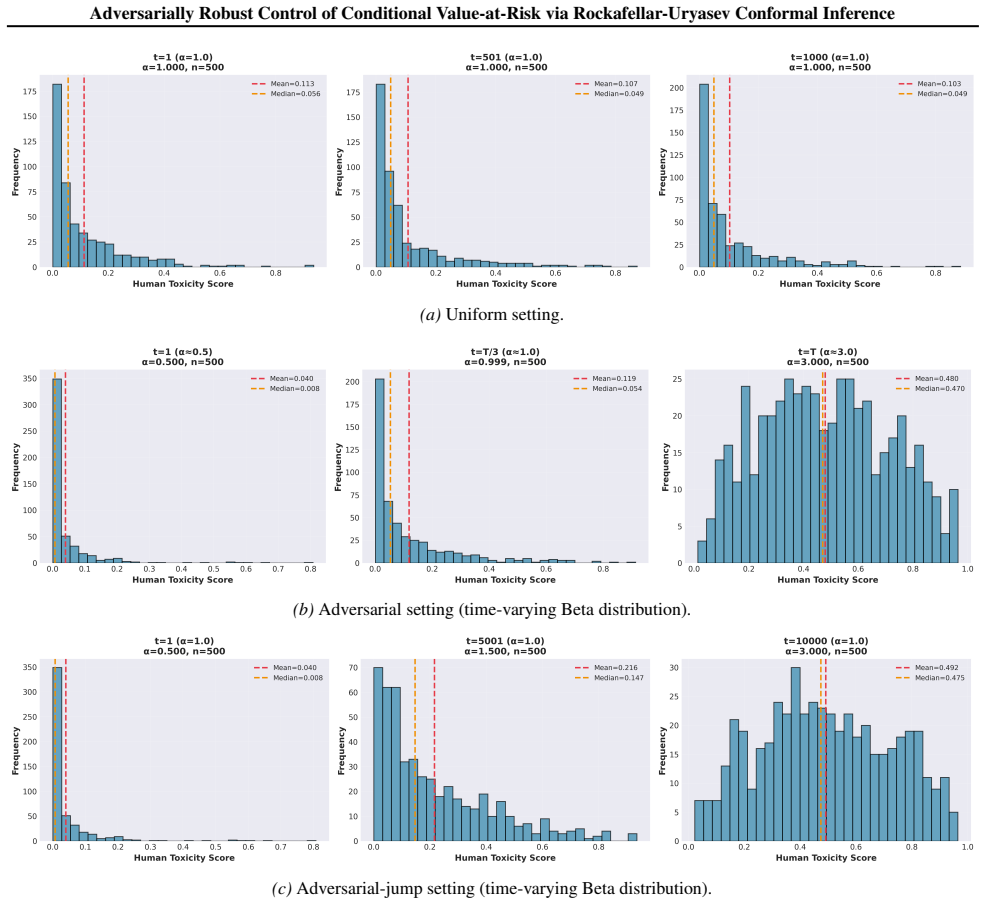
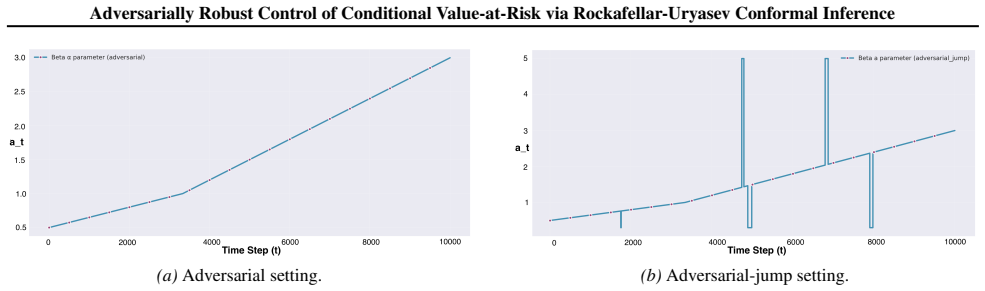
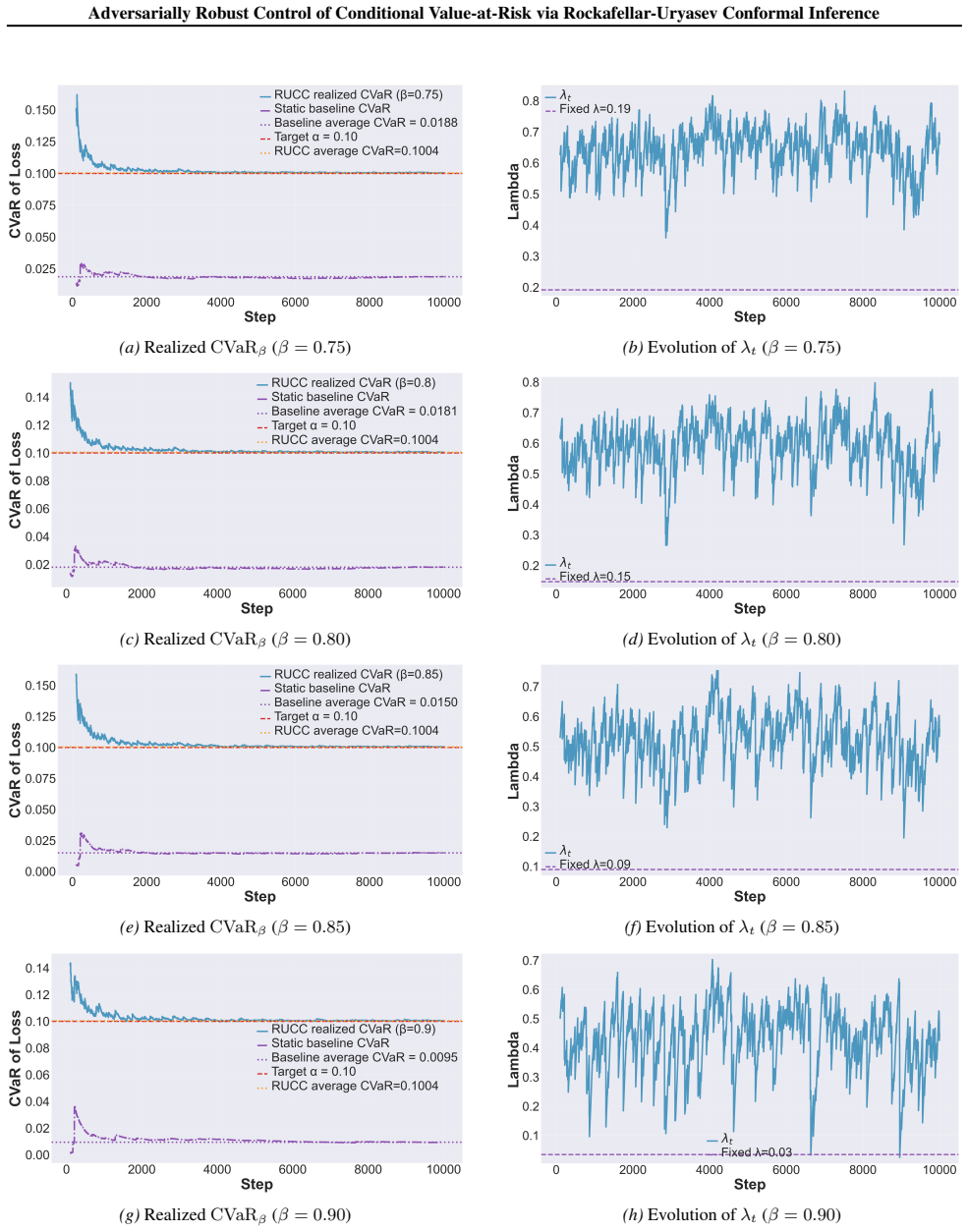
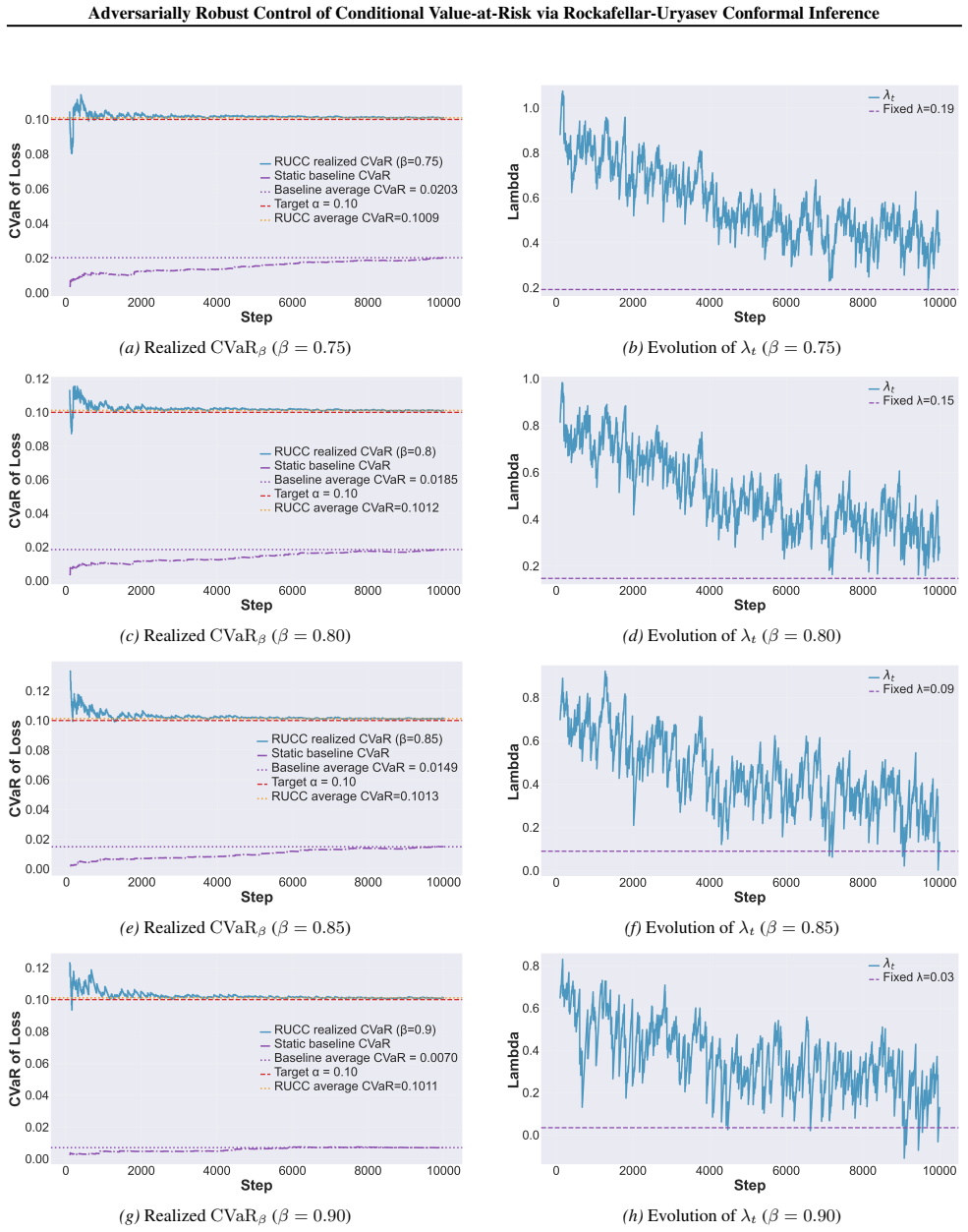
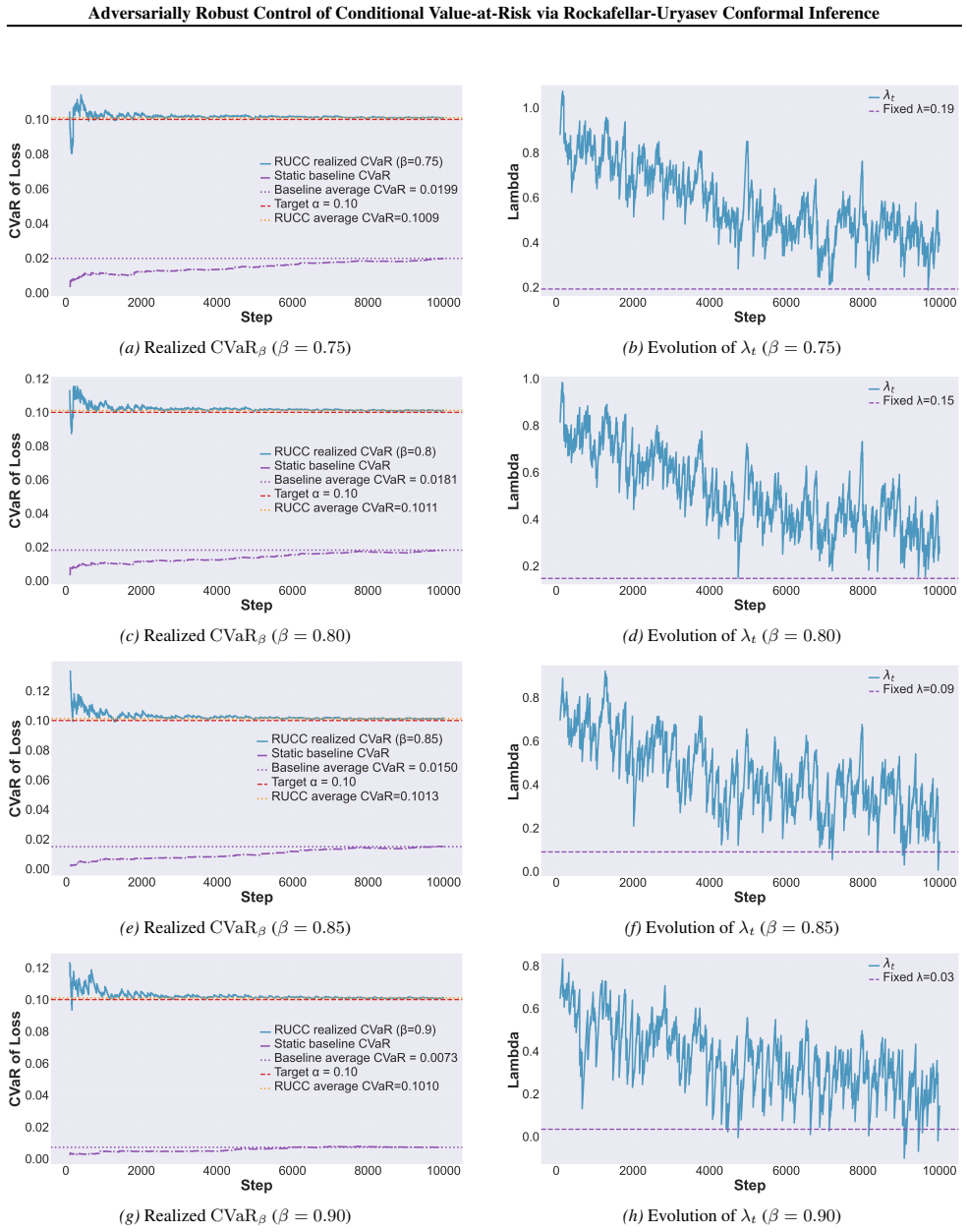
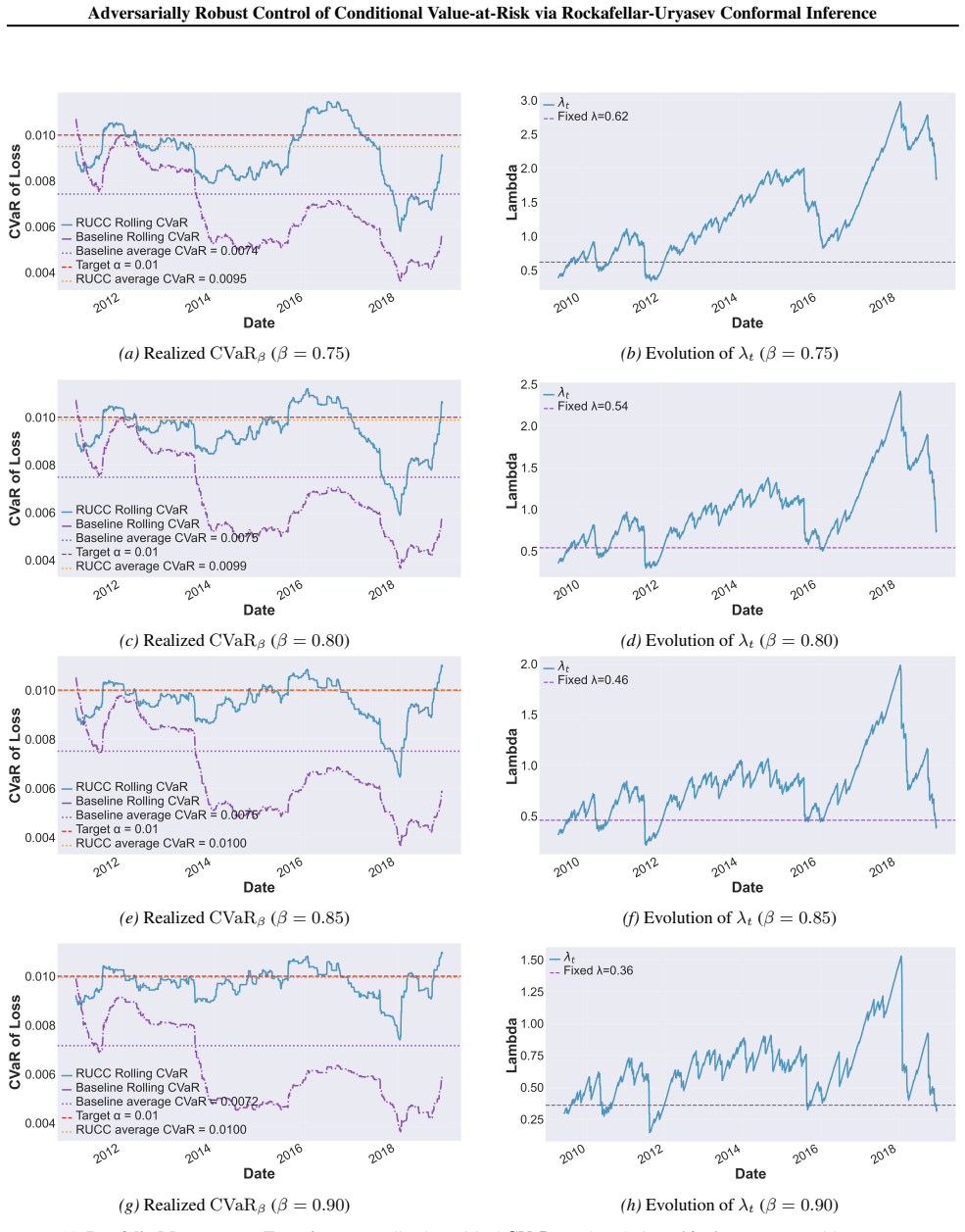
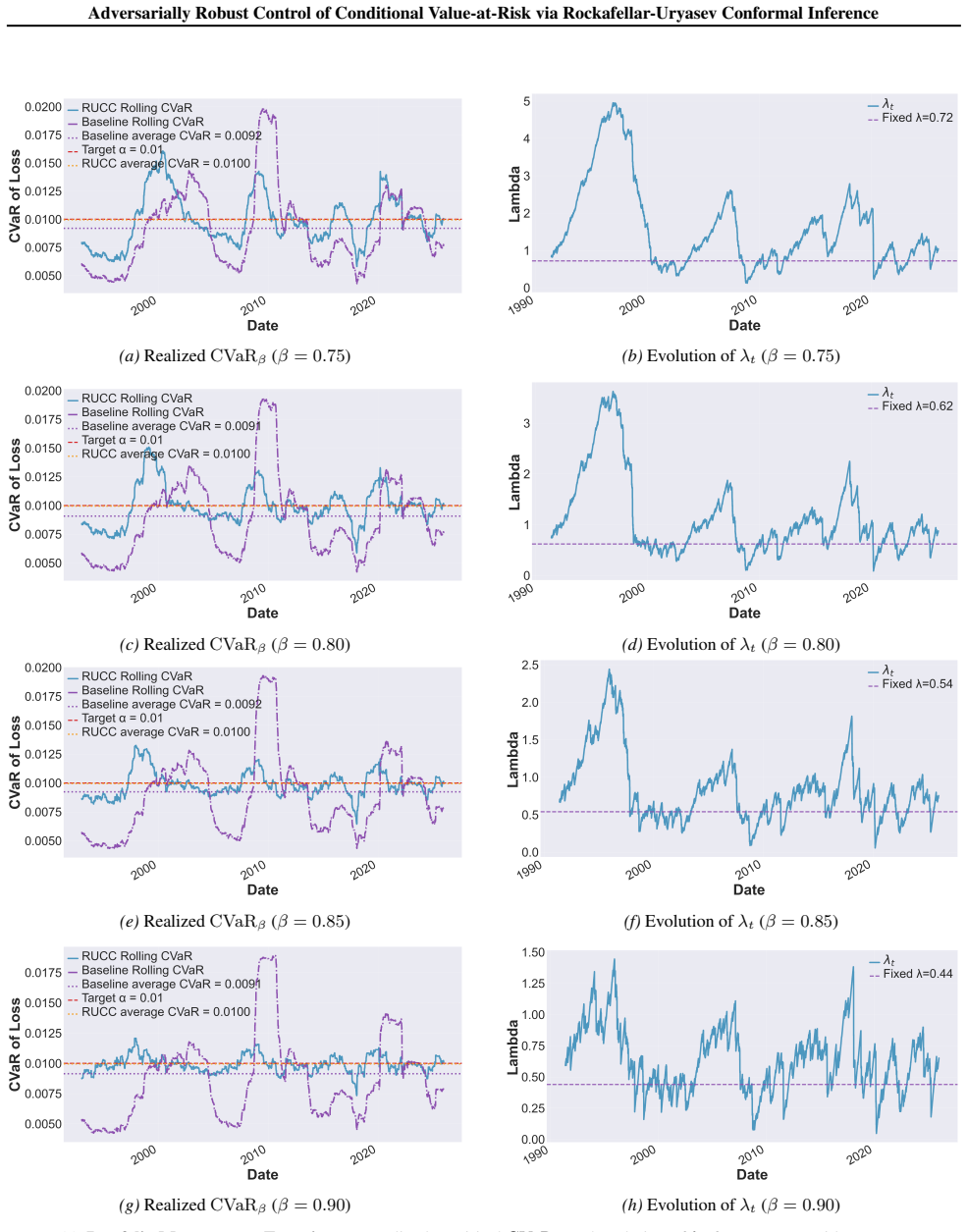
and theadversarial-jumpsetting (Figure 8), λt exhibits a clear decreasing trend over time for all β. Initially, λt remains large, corresponding to less aggressive filtering. As the controller accumulates evidence and adapts to the realized tail distribution, λt is gradually reduced, reflecting an increasingly strict control of the risky region. Larger β v...
1991
-
[15]
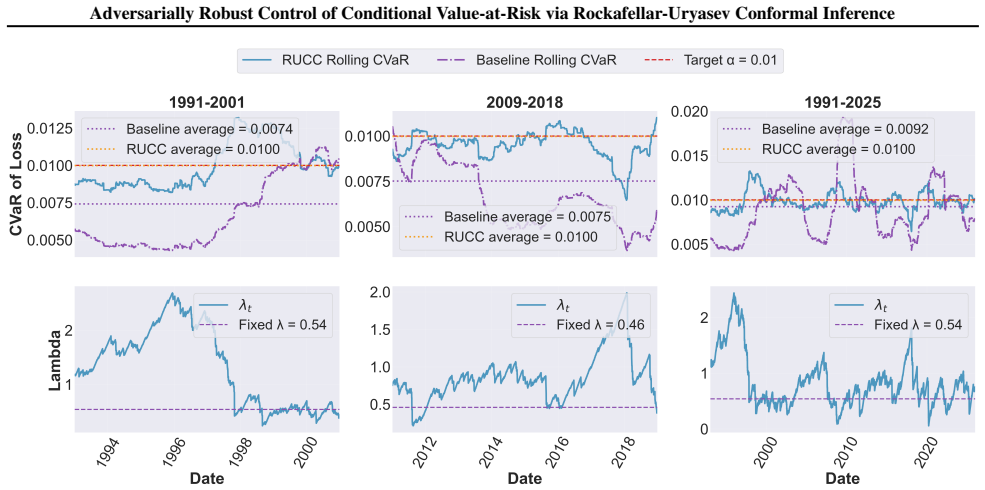
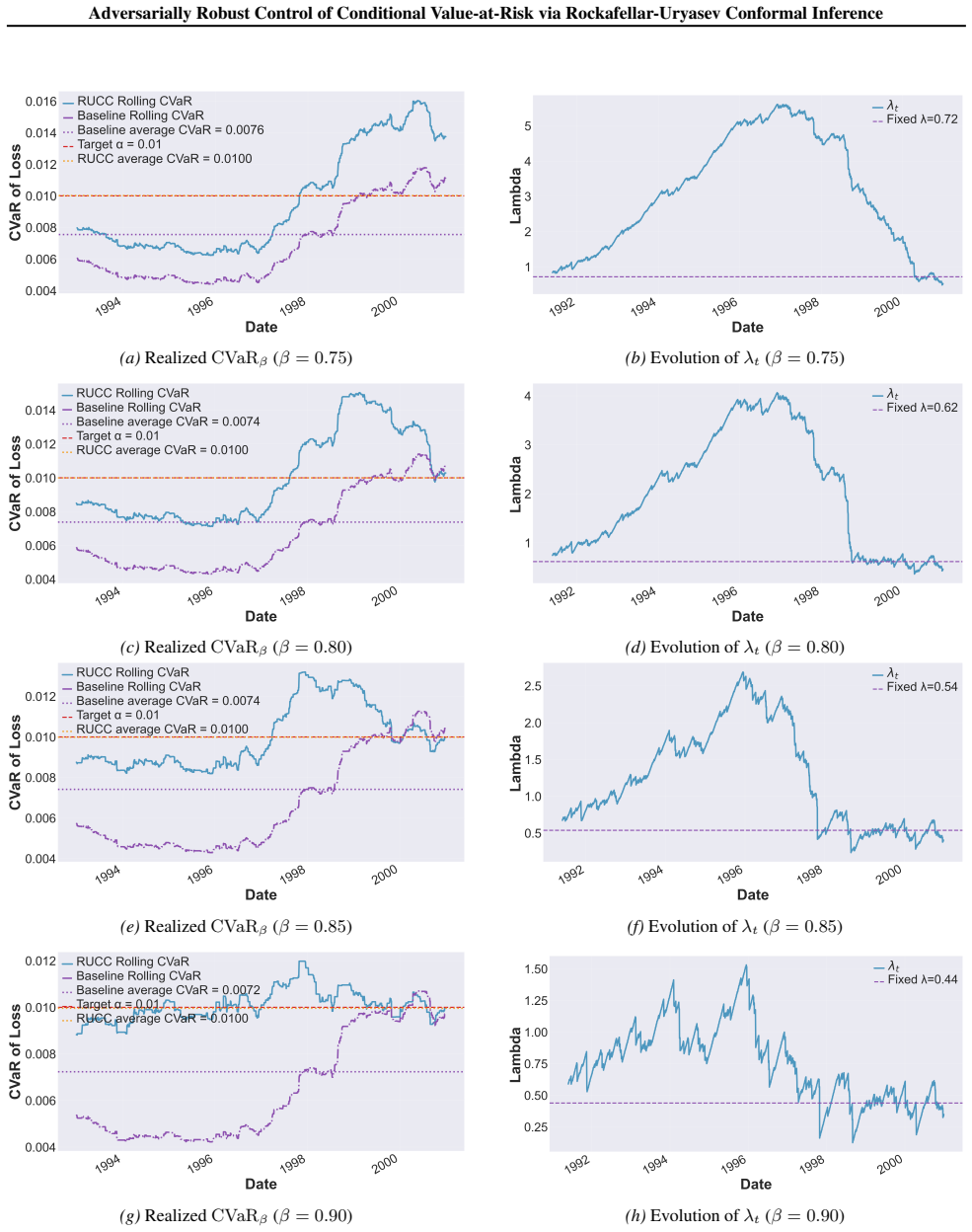
Accordingly, as the baseline controller has a fixed λt, its associated realized CVaRβ grows beyond the target level over time. In contrast, the realized tail risk of the RUCC controller initially starts below the target level and steadily increases over time as the controller adapts, and moves tightly around the target level as time passes. During 2009–20...
2009
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.