KG-Guard: Graph-Based Hallucination Detection for Knowledge Base Question Answering
Pith reviewed 2026-06-28 23:09 UTC · model grok-4.3
The pith
A graph-based detector classifies hallucinated answer nodes in KBQA by encoding an augmented knowledge graph, achieving highest F1 scores on three benchmarks with far fewer parameters than baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
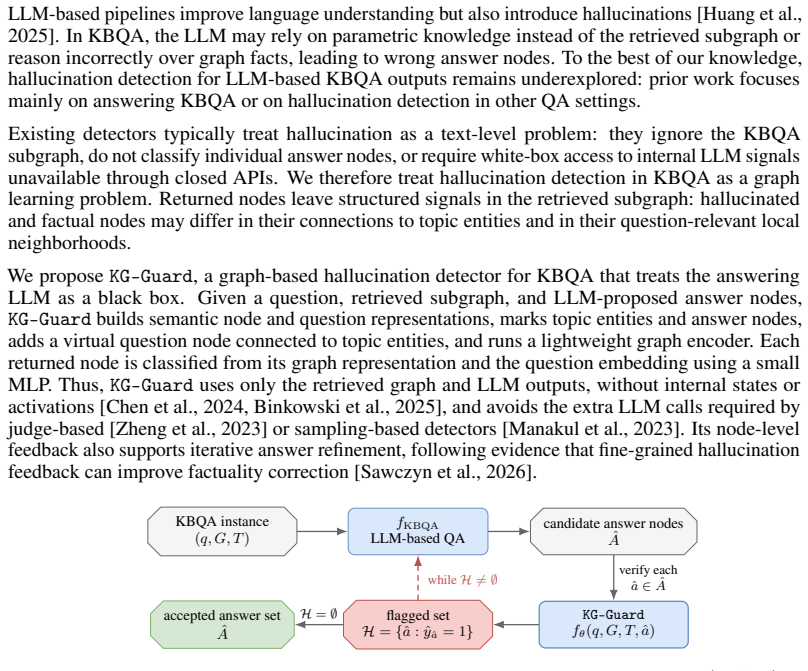
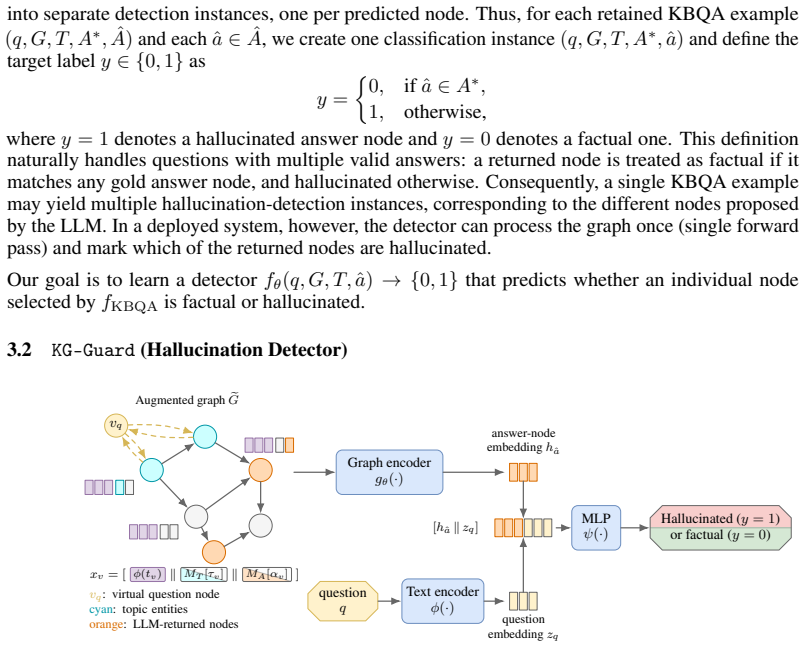
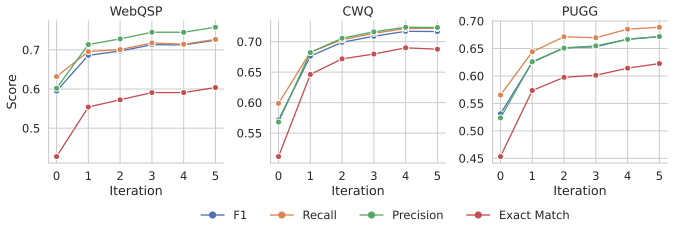
KG-Guard represents each KBQA instance as an augmented graph where node features come from semantic embeddings of KG entities, topic entities and LLM answers are marked with learned vectors, and a virtual question node connects to topics. A graph encoder produces node representations, and an MLP classifies each proposed answer node using its representation and the question embedding. This detects hallucinations without accessing the LLM's reasoning, leading to top F1 scores of 82.0 on WebQSP, 87.4 on ComplexWebQuestions, and 84.3 on PUGG, plus downstream improvements of 13.0-14.5 F1 points when used for refinement.
What carries the argument
The augmented knowledge graph with a virtual question node connected to topic entities, combined with learned marking vectors on topic and answer nodes, processed by a graph encoder to produce verification-oriented representations for MLP classification.
If this is right
- Achieves the highest F1 scores of 82.0, 87.4, and 84.3 on the WebQSP, ComplexWebQuestions, and PUGG benchmarks.
- Outperforms LLM-as-judge and sampling-based baselines while having approximately 305 times fewer parameters.
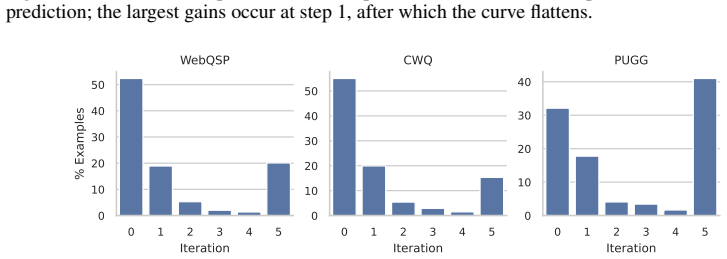
- Node-level feedback improves downstream KBQA F1 by 13.0-14.5 points and Exact Match by 16.9-17.6 points when fed back for iterative refinement.
Where Pith is reading between the lines
- The black-box nature allows the detector to work with any LLM-based KBQA system without requiring access to internal states.
- The node classification approach might generalize to detecting invalid reasoning in other structured knowledge tasks.
- Iterative refinement using the detector could be applied in a loop to further boost performance on complex questions.
Load-bearing premise
The assumption that initializing node features with semantic representations of KG entities and marking with learned vectors, then using a graph encoder on the augmented graph with a virtual question node, will produce representations sufficient for accurate classification of hallucinated answer nodes without needing access to the LLM's reasoning process.
What would settle it
A new experiment showing that the graph encoder's node representations do not allow the MLP to classify hallucinations better than baselines, or that feedback fails to improve KBQA metrics, would falsify the approach.
Figures
read the original abstract
Large language models (LLMs) are increasingly used for knowledge base question answering (KBQA), where answering requires selecting entities from a question-specific knowledge-graph subgraph. Yet LLMs are known to hallucinate across tasks, and KBQA is no exception: even when we provide a graph as the knowledge source, the model may rely on parametric knowledge instead of graph evidence or perform invalid reasoning over the given relations. Such hallucinated answer nodes can limit the practical deployment of KBQA systems, especially in high-stakes domains such as healthcare. We formulate hallucination detection in KBQA as an answer-node classification problem and propose a lightweight graph-based framework that treats the answering LLM as a black box. \methodname represents each KBQA instance as an augmented graph. It initializes node features with semantic representations of KG entities, marks topic entities and LLM-proposed answer nodes with learned vectors, and connect a virtual question node to the topic entities. A graph encoder then produces verification-oriented node representations, and a small MLP classifies each proposed answer node using its graph representation together with the question embedding. Experiments on WebQSP, ComplexWebQuestions, and PUGG show that our detector achieves the highest F1 on all three benchmarks ($82.0$, $87.4$, and $84.3$), outperforming LLM-as-judge and sampling-based baselines, while having $\sim305\times$ fewer parameters than the reference approaches. Beyond detection, the node-level feedback is actionable: when flagged answers are fed back to the KBQA system for iterative refinement, downstream KBQA F1 improves by $13.0$--$14.5$ points and Exact Match by $16.9$--$17.6$ points.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes KG-Guard, a lightweight graph-based detector for hallucinations in KBQA. It treats the LLM as a black box and formulates detection as node classification on an augmented subgraph: nodes are initialized with semantic KG embeddings, topic entities and LLM-proposed answers are marked with learned vectors, a virtual question node is connected to topic entities, a graph encoder produces node representations, and a small MLP classifies each proposed answer node (using its representation plus the question embedding). Experiments on WebQSP, ComplexWebQuestions, and PUGG report F1 scores of 82.0/87.4/84.3, outperforming LLM-as-judge and sampling baselines with ~305× fewer parameters; feeding flagged nodes back for iterative refinement yields 13.0–14.5 point F1 and 16.9–17.6 point Exact-Match gains on the downstream KBQA task.
Significance. If the empirical claims hold, the work supplies a practical, parameter-efficient black-box method that exploits the explicit graph structure of KBQA subgraphs for hallucination detection. The node-level feedback loop that demonstrably improves downstream KBQA performance is a concrete strength, and the approach avoids reliance on LLM internals or sampling, which is useful for high-stakes settings.
minor comments (3)
- The abstract states precise F1 numbers and downstream gains; the full paper should include the corresponding tables (with per-baseline scores, standard deviations, and statistical significance tests) so readers can verify the magnitude of the reported improvements.
- Clarify the exact graph-encoder architecture (layer count, message-passing type, aggregation) and the source of the semantic node initializations; these choices are central to reproducibility but are only sketched in the abstract.
- Add an ablation that isolates the contribution of the learned marker vectors versus the virtual question node; without it the necessity of each design element remains unquantified.
Simulated Author's Rebuttal
We thank the referee for their positive summary of KG-Guard, recognition of its practical strengths in black-box hallucination detection, and recommendation for minor revision. No specific major comments were provided in the report.
Circularity Check
No significant circularity
full rationale
The paper describes an empirical ML framework for node classification on augmented KGs to detect hallucinated answers. It initializes features from entity semantics, adds learned markers and a virtual question node, runs a graph encoder, and classifies with an MLP. These steps are standard supervised components trained on labeled data; the reported F1 scores and downstream improvements are measured outcomes on held-out benchmarks, not quantities forced by construction from the inputs or prior self-citations. No equations or claims reduce the detector output to a re-labeling of its own training signals.
Axiom & Free-Parameter Ledger
free parameters (1)
- learned vectors for marking topic entities and LLM-proposed answer nodes
axioms (1)
- domain assumption Graph structure augmented with virtual question node connected to topic entities can capture verification information for answer nodes
Reference graph
Works this paper leans on
-
[1]
Huang, Lei and Yu, Weijiang and Ma, Weitao and Zhong, Weihong and Feng, Zhangyin and Wang, Haotian and Chen, Qianglong and Peng, Weihua and Feng, Xiaocheng and Qin, Bing and Liu, Ting , title =. ACM Trans. Inf. Syst. , month = jan, articleno =. 2025 , issue_date =. doi:10.1145/3703155 , abstract =
-
[2]
Semantic Parsing on F reebase from Question-Answer Pairs
Berant, Jonathan and Chou, Andrew and Frostig, Roy and Liang, Percy. Semantic Parsing on F reebase from Question-Answer Pairs. Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing. 2013
2013
-
[3]
Complex Knowledge Base Question Answering: A Survey , year=
Lan, Yunshi and He, Gaole and Jiang, Jinhao and Jiang, Jing and Zhao, Wayne Xin and Wen, Ji-Rong , journal=. Complex Knowledge Base Question Answering: A Survey , year=
-
[4]
Large Language Models Meet Knowledge Graphs for Question Answering: Synthesis and Opportunities
Ma, Chuangtao and Chen, Yongrui and Wu, Tianxing and Khan, Arijit and Wang, Haofen. Large Language Models Meet Knowledge Graphs for Question Answering: Synthesis and Opportunities. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.1249
-
[5]
The Value of Semantic Parse Labeling for Knowledge Base Question Answering
Yih, Wen-tau and Richardson, Matthew and Meek, Chris and Chang, Ming-Wei and Suh, Jina. The Value of Semantic Parse Labeling for Knowledge Base Question Answering. Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). 2016. doi:10.18653/v1/P16-2033
-
[6]
Proceedings of the 22nd National Conference on Artificial Intelligence - Volume 2 , pages =
Bollacker, Kurt and Cook, Robert and Tufts, Patrick , title =. Proceedings of the 22nd National Conference on Artificial Intelligence - Volume 2 , pages =. 2007 , isbn =
2007
-
[7]
The Web as a Knowledge-Base for Answering Complex Questions
Talmor, Alon and Berant, Jonathan. The Web as a Knowledge-Base for Answering Complex Questions. Proceedings of the 2018 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers). 2018. doi:10.18653/v1/N18-1059
-
[8]
Developing PUGG for P olish: A Modern Approach to KBQA , MRC , and IR Dataset Construction
Sawczyn, Albert and Viarenich, Katsiaryna and Wojtasik, Konrad and Domoga a, Aleksandra and Oleksy, Marcin and Piasecki, Maciej and Kajdanowicz, Tomasz. Developing PUGG for P olish: A Modern Approach to KBQA , MRC , and IR Dataset Construction. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.652
-
[9]
Knowledge-Augmented Language Model Prompting for Zero-Shot Knowledge Graph Question Answering
Baek, Jinheon and Aji, Alham Fikri and Saffari, Amir. Knowledge-Augmented Language Model Prompting for Zero-Shot Knowledge Graph Question Answering. Proceedings of the 1st Workshop on Natural Language Reasoning and Structured Explanations (NLRSE). 2023. doi:10.18653/v1/2023.nlrse-1.7
-
[10]
doi: 10.18653/v1/2021.naacl-main.45
Yasunaga, Michihiro and Ren, Hongyu and Bosselut, Antoine and Liang, Percy and Leskovec, Jure. QA - GNN : Reasoning with Language Models and Knowledge Graphs for Question Answering. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2021. doi:10.18653/v1/2021.naac...
-
[11]
International Conference on Learning Representations , year=
GreaseLM: Graph REASoning Enhanced Language Models , author=. International Conference on Learning Representations , year=
-
[12]
SelfCheckGPT: Zero-resource black- box hallucination detection for generative large language models
Manakul, Potsawee and Liusie, Adian and Gales, Mark. S elf C heck GPT : Zero-Resource Black-Box Hallucination Detection for Generative Large Language Models. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.557
-
[13]
F act S elf C heck: Fact-Level Black-Box Hallucination Detection for LLM s
Sawczyn, Albert and Binkowski, Jakub and Janiak, Denis and Gabrys, Bogdan and Kajdanowicz, Tomasz Jan. F act S elf C heck: Fact-Level Black-Box Hallucination Detection for LLM s. Findings of the A ssociation for C omputational L inguistics: EACL 2026. 2026. doi:10.18653/v1/2026.findings-eacl.296
-
[14]
GraphEval:
Hannah Sansford and Nicholas Richardson and Hermina Petric Maretic and Juba Nait Saada , editor =. GraphEval:. Proceedings of the Workshop on Knowledge-infused Learning co-located with 30th. 2024 , url =
2024
-
[15]
Hallucination Detection in LLM s Using Spectral Features of Attention Maps
Binkowski, Jakub and Janiak, Denis and Sawczyn, Albert and Gabrys, Bogdan and Kajdanowicz, Tomasz Jan. Hallucination Detection in LLM s Using Spectral Features of Attention Maps. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.1239
-
[16]
Open Domain Question Answering Using Early Fusion of Knowledge Bases and Text
Sun, Haitian and Dhingra, Bhuwan and Zaheer, Manzil and Mazaitis, Kathryn and Salakhutdinov, Ruslan and Cohen, William. Open Domain Question Answering Using Early Fusion of Knowledge Bases and Text. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 2018. doi:10.18653/v1/D18-1455
-
[17]
and Laurent, Thomas and LeCun, Yann and Bresson, Xavier and Hooi, Bryan , booktitle =
He, Xiaoxin and Tian, Yijun and Sun, Yifei and Chawla, Nitesh V. and Laurent, Thomas and LeCun, Yann and Bresson, Xavier and Hooi, Bryan , booktitle =. G-Retriever: Retrieval-Augmented Generation for Textual Graph Understanding and Question Answering , url =. doi:10.52202/079017-4224 , editor =
-
[18]
Rashad, Mohamed and Zahran, Ahmed and Amin, Abanoub and Abdelaal, Amr and Altantawy, Mohamed. F act A lign: Fact-Level Hallucination Detection and Classification Through Knowledge Graph Alignment. Proceedings of the 4th Workshop on Trustworthy Natural Language Processing (TrustNLP 2024). 2024. doi:10.18653/v1/2024.trustnlp-1.8
-
[19]
International Conference on Learning Representations , year=
Graph Attention Networks , author=. International Conference on Learning Representations , year=
-
[20]
Kipf and Max Welling , title =
Thomas N. Kipf and Max Welling , title =. 5th International Conference on Learning Representations,. 2017 , url =
2017
-
[21]
and Ying, Rex and Leskovec, Jure , title =
Hamilton, William L. and Ying, Rex and Leskovec, Jure , title =. Proceedings of the 31st International Conference on Neural Information Processing Systems , pages =. 2017 , isbn =
2017
-
[22]
International Conference on Learning Representations , year=
How Powerful are Graph Neural Networks? , author=. International Conference on Learning Representations , year=
-
[23]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena , url =
Zheng, Lianmin and Chiang, Wei-Lin and Sheng, Ying and Zhuang, Siyuan and Wu, Zhanghao and Zhuang, Yonghao and Lin, Zi and Li, Zhuohan and Li, Dacheng and Xing, Eric and Zhang, Hao and Gonzalez, Joseph and Stoica, Ion , booktitle =. Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena , url =
-
[24]
Introducing
Meta AI , year=. Introducing
-
[25]
2026 , eprint=
OpenAI GPT-5 System Card , author=. 2026 , eprint=
2026
-
[26]
Ian Davidson, Michael Livanos, Antoine Gourru, Peter Walker, Julien Velcin, and S
Farquhar, Sebastian and Kossen, Jannik and Kuhn, Lorenz and Gal, Yarin , title=. Nature , year=. doi:10.1038/s41586-024-07421-0 , url=
-
[27]
LLM-Check: Investigating Detection of Hallucinations in Large Language Models , url =
Sriramanan, Gaurang and Bharti, Siddhant and Sadasivan, Vinu Sankar and Saha, Shoumik and Kattakinda, Priyatham and Feizi, Soheil , booktitle =. LLM-Check: Investigating Detection of Hallucinations in Large Language Models , url =. doi:10.52202/079017-1077 , editor =
-
[28]
2024 , url=
Chao Chen and Kai Liu and Ze Chen and Yi Gu and Yue Wu and Mingyuan Tao and Zhihang Fu and Jieping Ye , booktitle=. 2024 , url=
2024
-
[29]
2024 , eprint=
Semantic Entropy Probes: Robust and Cheap Hallucination Detection in LLMs , author=. 2024 , eprint=
2024
-
[30]
The internal state of an LLM knows when it’s lying
Azaria, Amos and Mitchell, Tom. The Internal State of an LLM Knows When It`s Lying. Findings of the Association for Computational Linguistics: EMNLP 2023. 2023. doi:10.18653/v1/2023.findings-emnlp.68
-
[31]
Chuang, Yung-Sung and Qiu, Linlu and Hsieh, Cheng-Yu and Krishna, Ranjay and Kim, Yoon and Glass, James R. Lookback Lens: Detecting and Mitigating Contextual Hallucinations in Large Language Models Using Only Attention Maps. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.84
-
[32]
Knowledge-Centric Hallucination Detection
Hu, Xiangkun and Ru, Dongyu and Qiu, Lin and Guo, Qipeng and Zhang, Tianhang and Xu, Yang and Luo, Yun and Liu, Pengfei and Zhang, Yue and Zhang, Zheng. Knowledge-Centric Hallucination Detection. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.395
-
[33]
The Twelfth International Conference on Learning Representations , year=
Think-on-Graph: Deep and Responsible Reasoning of Large Language Model on Knowledge Graph , author=. The Twelfth International Conference on Learning Representations , year=
-
[34]
International Conference on Learning Representations , year=
Reasoning on Graphs: Faithful and Interpretable Large Language Model Reasoning , author=. International Conference on Learning Representations , year=
-
[35]
doi: 10.18653/v1/2025.findings-acl.856
Mavromatis, Costas and Karypis, George. GNN - RAG : Graph Neural Retrieval for Efficient Large Language Model Reasoning on Knowledge Graphs. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.856
-
[36]
Min, Sewon and Krishna, Kalpesh and Lyu, Xinxi and Lewis, Mike and Yih, Wen-tau and Koh, Pang and Iyyer, Mohit and Zettlemoyer, Luke and Hajishirzi, Hannaneh. FA ct S core: Fine-grained Atomic Evaluation of Factual Precision in Long Form Text Generation. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.1...
-
[37]
G raph C heck: Breaking Long-Term Text Barriers with Extracted Knowledge Graph-Powered Fact-Checking
Chen, Yingjian and Liu, Haoran and Liu, Yinhong and Xie, Jinxiang and Yang, Rui and Yuan, Han and Fu, Yanran and Zhou, Peng Yuan and Chen, Qingyu and Caverlee, James and Li, Irene. G raph C heck: Breaking Long-Term Text Barriers with Extracted Knowledge Graph-Powered Fact-Checking. Proceedings of the 63rd Annual Meeting of the Association for Computationa...
-
[38]
Guan, Xinyan and Liu, Yanjiang and Lin, Hongyu and Lu, Yaojie and He, Ben and Han, Xianpei and Sun, Le , title =. Proceedings of the Thirty-Eighth AAAI Conference on Artificial Intelligence and Thirty-Sixth Conference on Innovative Applications of Artificial Intelligence and Fourteenth Symposium on Educational Advances in Artificial Intelligence , article...
-
[39]
Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =
Madaan, Aman and Tandon, Niket and Gupta, Prakhar and Hallinan, Skyler and Gao, Luyu and Wiegreffe, Sarah and Alon, Uri and Dziri, Nouha and Prabhumoye, Shrimai and Yang, Yiming and Gupta, Shashank and Majumder, Bodhisattwa Prasad and Hermann, Katherine and Welleck, Sean and Yazdanbakhsh, Amir and Clark, Peter , title =. Proceedings of the 37th Internatio...
2023
-
[40]
Dhuliawala, Shehzaad and Komeili, Mojtaba and Xu, Jing and Raileanu, Roberta and Li, Xian and Celikyilmaz, Asli and Weston, Jason. Chain-of-Verification Reduces Hallucination in Large Language Models. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.212
-
[41]
Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence,
Masked Label Prediction: Unified Message Passing Model for Semi-Supervised Classification , author =. Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence,. 2021 , month =. doi:10.24963/ijcai.2021/214 , url =
-
[42]
Reimers, Nils and Gurevych, Iryna. Sentence- BERT : Sentence Embeddings using S iamese BERT -Networks. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019. doi:10.18653/v1/D19-1410
-
[43]
PIRB : A Comprehensive Benchmark of P olish Dense and Hybrid Text Retrieval Methods
Dadas, Slawomir and Pere kiewicz, Micha and Po \'s wiata, Rafa. PIRB : A Comprehensive Benchmark of P olish Dense and Hybrid Text Retrieval Methods. Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024). 2024
2024
-
[44]
AAAI Workshop on Deep Learning on Graphs: Methods and Applications , year=
A Generalization of Transformer Networks to Graphs , author=. AAAI Workshop on Deep Learning on Graphs: Methods and Applications , year=
-
[45]
, booktitle=
Fey, Matthias and Lenssen, Jan E. , booktitle=. Fast Graph Representation Learning with
-
[46]
Transformers: State-of-the-Art Natural Language Processing
Wolf, Thomas and Debut, Lysandre and Sanh, Victor and Chaumond, Julien and Delangue, Clement and Moi, Anthony and Cistac, Pierric and Rault, Tim and Louf, Remi and Funtowicz, Morgan and Davison, Joe and Shleifer, Sam and von Platen, Patrick and Ma, Clara and Jernite, Yacine and Plu, Julien and Xu, Canwen and Le Scao, Teven and Gugger, Sylvain and Drame, M...
-
[47]
doi:10.5281/zenodo.3828935 , license =
Falcon, William and. doi:10.5281/zenodo.3828935 , license =
-
[48]
doi:10.1145/2629489 , journaltitle =
Vrande. Wikidata: A Free Collaborative Knowledgebase , url =. Commun. ACM , keywords =. doi:10.1145/2629489 , interhash =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.