How Far Do Auto-Interpretation Labels Generalize: A Controlled Study Across Languages, Scripts, and Rewordings
Pith reviewed 2026-06-28 21:59 UTC · model grok-4.3
The pith
Auto-interpretation labels for SAE features track semantic concepts less reliably in underrepresented scripts and languages.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
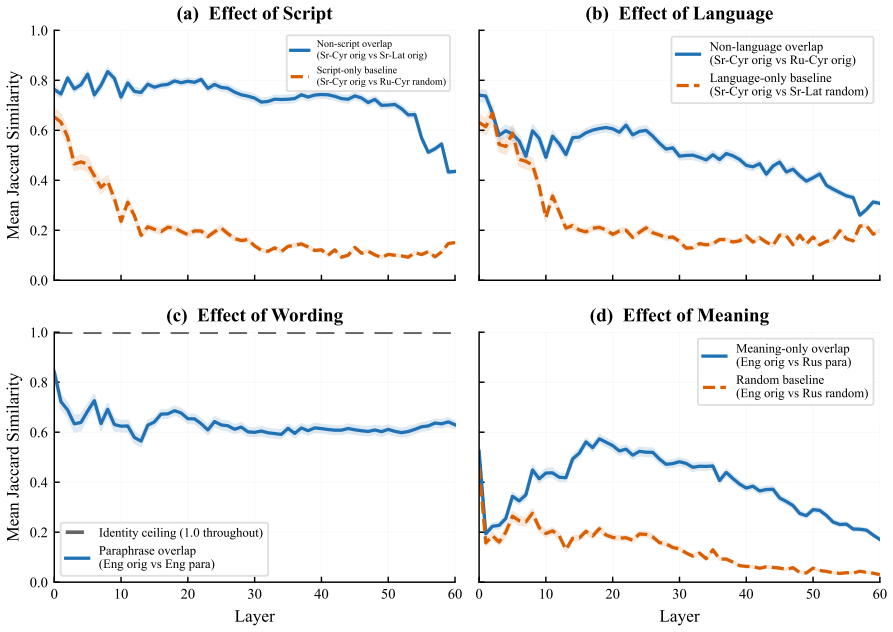
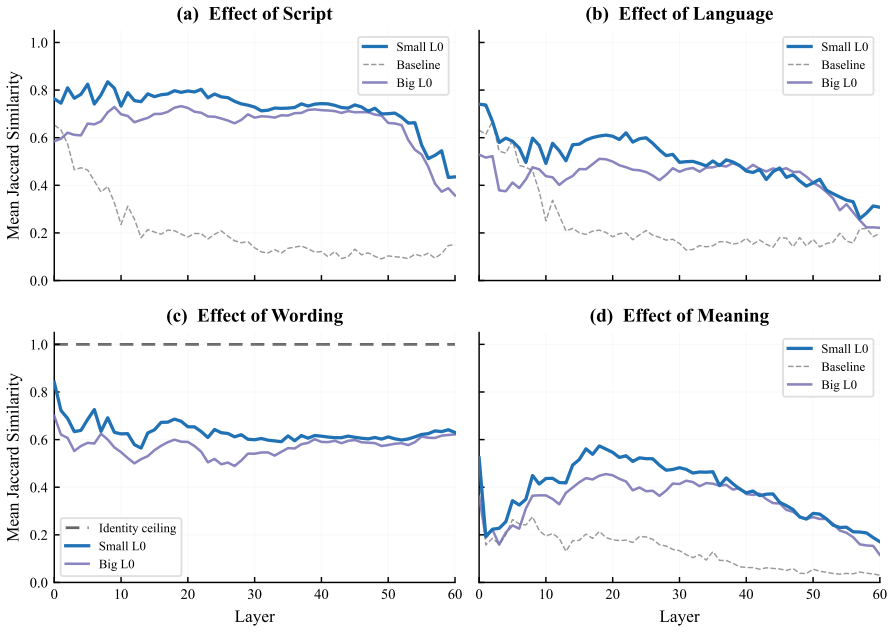
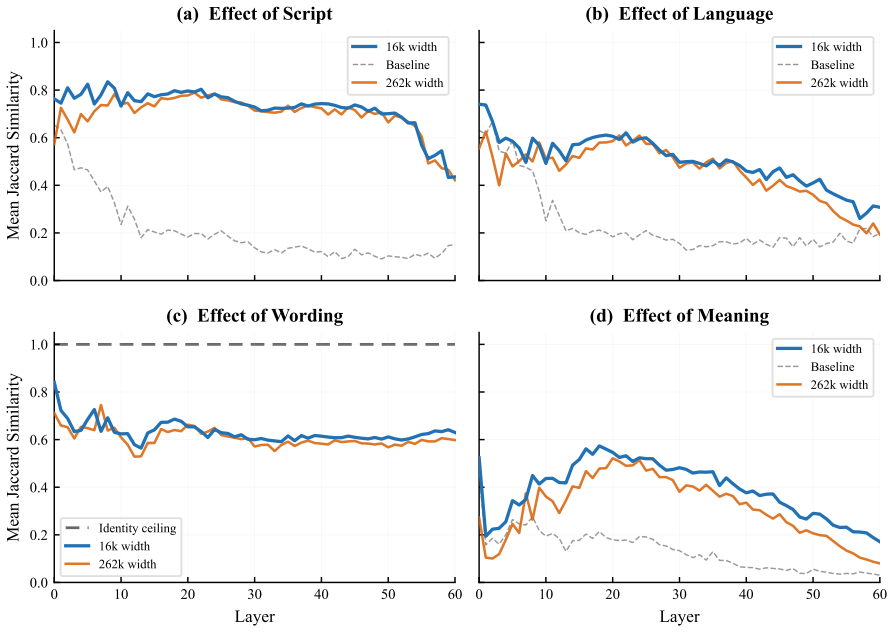
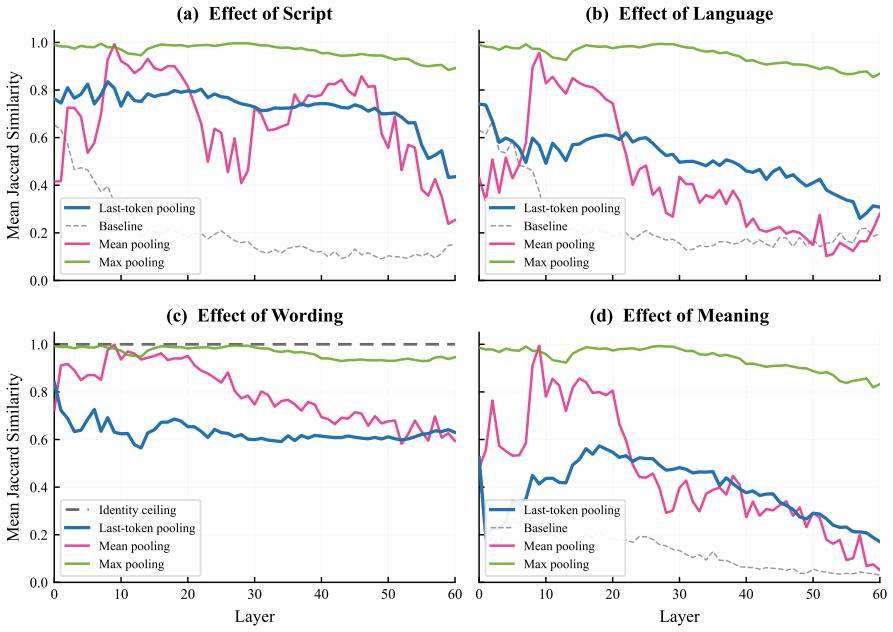
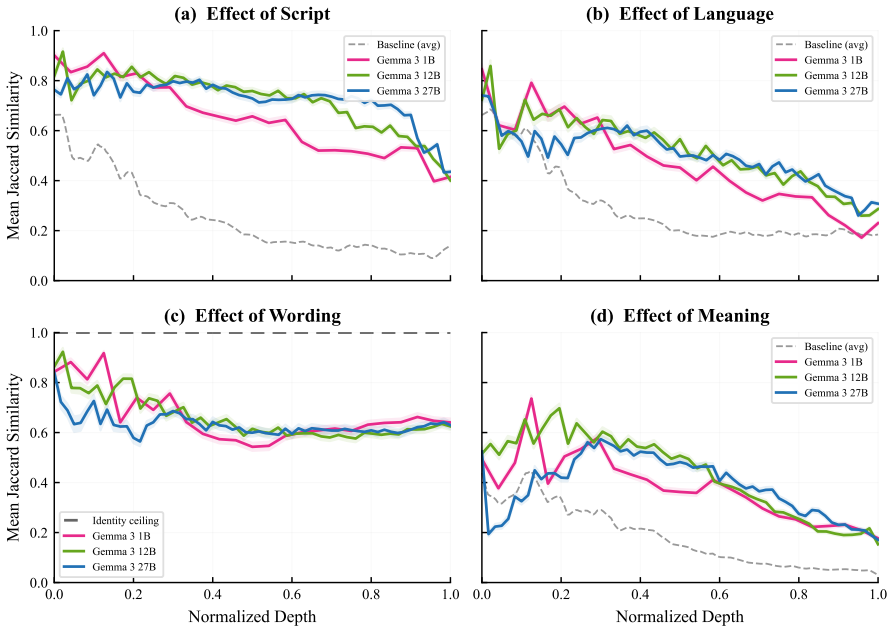
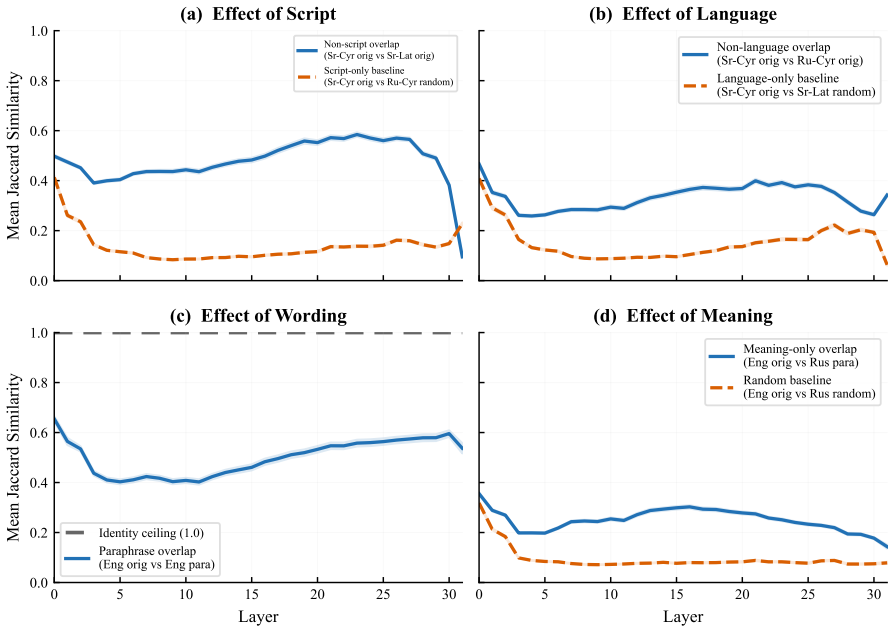
Using Serbian digraphia as a controlled testbed where the same language is written in Latin and Cyrillic scripts through deterministic transliteration, sparse autoencoder features activated by identical semantic content across scripts exhibit substantial Jaccard overlap of 0.39 compared to a 0.13 random baseline. Despite this, auto-generated interpretation labels for these features fail to identify the same meaning in Serbian up to four times more frequently than in English, miss Cyrillic more often than Latin, and show increasing failure rates with greater network depth without any indication in the labels themselves of these shortcomings.
What carries the argument
Serbian digraphia serving as a natural experiment to isolate the effect of script and representation frequency on feature activations versus label accuracy.
If this is right
- Features capture semantic concepts that activate similarly across different scripts for the same content.
- Auto-interpretation labels are less accurate for content in scripts that appear less frequently in training data.
- The discrepancy between feature behavior and label accuracy increases in deeper layers of the network.
- Labels do not provide any signal when they fail to generalize to less represented forms.
- Interpretation quality depends on how well the input form matches the model's training distribution.
Where Pith is reading between the lines
- If labels are tied to representation frequency, then balancing training data across scripts and languages could improve label reliability.
- This testbed approach could be extended to other pairs of equivalent scripts or languages to check generalization.
- Interpretability work might benefit from verifying labels against multiple surface forms of the same concept rather than single examples.
- The finding raises the possibility that current auto-labeling methods prioritize common patterns over true conceptual understanding.
Load-bearing premise
The assumption that higher overlap in feature activations for the same content across scripts means the features encode exactly the same semantic concept, rather than similar but distinct patterns.
What would settle it
An experiment showing that the Jaccard overlap for feature activations on Serbian Latin and Cyrillic is equal to that for unrelated texts would indicate the features do not encode shared semantic concepts.
Figures

read the original abstract
Sparse autoencoder (SAE) features are increasingly used to interpret language models, with auto-generated natural-language labels serving as the primary interface for understanding what each feature represents. We ask whether these labels generalize: does a feature labeled for a concept actually track that concept across languages and scripts? Using Serbian digraphia as a controlled testbed--the same language written in both Latin and Cyrillic via deterministic transliteration--we first find that SAE feature sets activated by the same content in different languages, scripts, and wordings share substantial overlap (mean Jaccard 0.39 vs. 0.13 random baseline, peaking at 0.57), suggesting genuine cross-lingual semantic features. We then test whether auto-interpretation labels keep pace. They often do not: features whose labels describe semantic content miss the same meaning in Serbian up to 4x more often thanwithin English, and miss Serbian Cyrillic more than Serbian Latin--two scripts that are deterministic transliterations of each other--suggesting the failures align with how well each form is represented in training. The gap grows with network depth, yet the labels give no indication that they fail. These results suggest that auto-interpretation labels may reflect a feature's behavior on well-represented inputs rather than the concept itself.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper examines whether auto-interpretation labels for SAE features generalize across languages, scripts, and rewordings. Using Serbian digraphia (Latin and Cyrillic via deterministic transliteration) as a controlled testbed, it reports mean Jaccard overlap of 0.39 (vs. 0.13 random baseline) in feature activation sets for equivalent content, then shows that labels for semantic content miss the same meaning up to 4x more often in Serbian than English and more in Cyrillic than Latin, with the gap increasing by network depth. The results suggest labels track behavior on well-represented inputs rather than the underlying concept.
Significance. If the results hold, the work provides a valuable empirical demonstration of limitations in auto-interpretation reliability for mechanistic interpretability, using a natural controlled experiment (digraphia) to isolate script and frequency effects. The concrete metrics and cross-script design are strengths for a measurement study; the findings would usefully caution against over-reliance on labels without frequency controls.
major comments (2)
- [Abstract/Results] Abstract/Results: The claim that Jaccard overlap of 0.39 demonstrates features encode the same semantic concept across scripts (as opposed to correlated but non-identical patterns from subword statistics or model internals) is load-bearing for interpreting label failures as evidence that labels track input frequency rather than concepts. No causal tests (steering, ablation, or counterfactual activation) are described to confirm identical downstream effects on equivalent meaning.
- [Abstract/Methods] Abstract/Methods: Concrete metrics (Jaccard 0.39, up to 4x miss rate) are reported without error bars, activation thresholds, dataset sizes, or full details on how 'miss the same meaning' is operationalized from activation sets; this makes it difficult to assess robustness or whether post-hoc choices affect the central claim about representation-frequency alignment.
minor comments (1)
- [Title/Abstract] The title references rewordings but the provided abstract focuses exclusively on scripts and languages; clarify whether rewording results are included and how they interact with the script findings.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our work. We address each of the major comments below.
read point-by-point responses
-
Referee: [Abstract/Results] Abstract/Results: The claim that Jaccard overlap of 0.39 demonstrates features encode the same semantic concept across scripts (as opposed to correlated but non-identical patterns from subword statistics or model internals) is load-bearing for interpreting label failures as evidence that labels track input frequency rather than concepts. No causal tests (steering, ablation, or counterfactual activation) are described to confirm identical downstream effects on equivalent meaning.
Authors: The Jaccard overlap is measured between activation sets for the same semantic content expressed in different scripts via deterministic transliteration, which provides a strong control for meaning. This overlap (0.39 vs. 0.13 baseline) is presented as evidence that the features are responding to semantic content rather than surface form alone. We agree, however, that this is not a causal demonstration of identical downstream effects. In the revised manuscript, we will adjust the language in the abstract and results to describe the findings as 'suggestive of' shared semantic features and will add a discussion of the limitations, including the lack of causal tests such as steering or ablation. revision: yes
-
Referee: [Abstract/Methods] Abstract/Methods: Concrete metrics (Jaccard 0.39, up to 4x miss rate) are reported without error bars, activation thresholds, dataset sizes, or full details on how 'miss the same meaning' is operationalized from activation sets; this makes it difficult to assess robustness or whether post-hoc choices affect the central claim about representation-frequency alignment.
Authors: We will include error bars for all quantitative results, specify the activation thresholds employed, report the sizes of the datasets used, and provide a precise description of the operationalization of missing the same meaning based on activation sets in the methods section of the revised version. revision: yes
Circularity Check
No significant circularity: direct empirical measurements
full rationale
The paper is a controlled empirical study that measures Jaccard overlaps between SAE feature activation sets on deterministically transliterated Serbian content and compares auto-interpretation label failure rates across scripts and languages. All quantities (mean Jaccard 0.39 vs. 0.13 random, up to 4x higher miss rates on Serbian) are computed directly from observed activations and labels with no fitted parameters, predictions, or derivations that reduce outputs to inputs by construction. No self-citation chains or uniqueness theorems are invoked as load-bearing premises. The work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Jaccard index is an appropriate measure of overlap between sets of activated SAE features
- domain assumption Deterministic transliteration between Serbian Latin and Cyrillic holds all semantic content fixed while varying only script
Reference graph
Works this paper leans on
-
[3]
2025 , eprint =
Gemma 3 Technical Report , author =. 2025 , eprint =
2025
-
[4]
2025 , month = sep, url =
Gemma Scope 2: Technical Paper , author =. 2025 , month = sep, url =
2025
-
[5]
2024 , eprint =
Jumping Ahead: Improving Reconstruction Fidelity with JumpReLU Sparse Autoencoders , author =. 2024 , eprint =
2024
-
[6]
Tenney, Ian and Das, Dipanjan and Pavlick, Ellie. BERT Rediscovers the Classical NLP Pipeline. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019. doi:10.18653/v1/P19-1452
-
[7]
What Does BERT Learn about the Structure of Language?
Jawahar, Ganesh and Sagot, Beno \^i t and Seddah, Djam \'e. What Does BERT Learn about the Structure of Language?. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019. doi:10.18653/v1/P19-1356
-
[8]
International Conference on Learning Representations (ICLR) , year =
The Semantic Hub Hypothesis: Language Models Share Semantic Representations Across Languages and Modalities , author =. International Conference on Learning Representations (ICLR) , year =
-
[13]
Residual Stream Analysis with Multi-Layer SAE s
Lawson, Tim and Farnik, Lucy and Houghton, Conor and Aitchison, Laurence. Residual Stream Analysis with Multi-Layer SAE s. arXiv preprint arXiv:2409.04185. 2024
arXiv 2024
-
[14]
Statistics of Common Crawl Monthly Archives: Distribution of Languages , year =
-
[15]
Xue, Linting and Constant, Noah and Roberts, Adam and Kale, Mihir and Al-Rfou, Rami and Siddhant, Aditya and Barua, Aditya and Raffel, Colin , booktitle =
-
[16]
Cyrbusters Panel Debate Held: Busting Myths About Cyrillic on the Internet , year =
-
[17]
2023 , howpublished =
Neuronpedia , author =. 2023 , howpublished =
2023
-
[19]
International Conference on Learning Representations (ICLR) , year =
LinguaMap: Which Layers of LLMs Speak Your Language and How to Tune Them? , author =. International Conference on Learning Representations (ICLR) , year =
-
[21]
2023 , howpublished =
Language Models Can Explain Neurons in Language Models , author =. 2023 , howpublished =
2023
-
[23]
Proceedings of the 64th Annual Meeting of the Association for Computational Linguistics (ACL 2026) , year =
Multilingual Language Models Encode Script Over Linguistic Structure , author =. Proceedings of the 64th Annual Meeting of the Association for Computational Linguistics (ACL 2026) , year =
2026
-
[25]
Ameisen, Emmanuel and Lindsey, Jack and Pearce, Adam and Gurnee, Wes and Turner, Nicholas L. and Chen, Brian and Citro, Craig and Abrahams, David and Carter, Shan and Hosmer, Basil and Marcus, Jonathan and Sklar, Michael and Templeton, Adly and Bricken, Trenton and McDougall, Callum and Cunningham, Hoagy and Henighan, Thomas and Jermyn, Adam and Jones, An...
-
[26]
Transformer Circuits Thread , year =
Natural Language Autoencoders Produce Unsupervised Explanations of LLM Activations , author =. Transformer Circuits Thread , year =
-
[27]
Transformer Circuits Thread , year =
Towards Monosemanticity: Decomposing Language Models With Dictionary Learning , author =. Transformer Circuits Thread , year =
-
[28]
International Conference on Learning Representations (ICLR) , year =
Sparse Autoencoders Find Highly Interpretable Features in Language Models , author =. International Conference on Learning Representations (ICLR) , year =
-
[29]
Transformer Circuits Thread , year =
Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet , author =. Transformer Circuits Thread , year =
-
[32]
Large Language Models Share Representations of Latent Grammatical Concepts Across Typologically Diverse Languages
Brinkmann, Jannik and Wendler, Chris and Bartelt, Christian and Mueller, Aaron. Large Language Models Share Representations of Latent Grammatical Concepts Across Typologically Diverse Languages. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1:...
2025
-
[33]
Unveiling language-specific features in large language models via sparse autoencoders
Deng, Boyi and Wan, Yu and Yang, Baosong and Zhang, Yidan and Feng, Fuli. Unveiling language-specific features in large language models via sparse autoencoders. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025
2025
-
[34]
Emmanuel Ameisen, Jack Lindsey, Adam Pearce, Wes Gurnee, Nicholas L. Turner, Brian Chen, Craig Citro, David Abrahams, Shan Carter, Basil Hosmer, Jonathan Marcus, Michael Sklar, Adly Templeton, Trenton Bricken, Callum McDougall, Hoagy Cunningham, Thomas Henighan, Adam Jermyn, Andy Jones, and 8 others. 2025. https://transformer-circuits.pub/2025/attribution...
2025
-
[35]
Nora Belrose, Zach Furman, Logan Smith, Danny Halawi, Igor Ostrovsky, Lev McKinney, Stella Biderman, and Jacob Steinhardt. 2023. https://arxiv.org/abs/2303.08112 Eliciting latent predictions from transformers with the tuned lens . arXiv preprint arXiv:2303.08112
Pith/arXiv arXiv 2023
-
[36]
Steven Bills, Nick Cammarata, Dan Mossing, Henk Tillman, Leo Gao, Gabriel Goh, Ilya Sutskever, Jan Leike, Jeff Wu, and William Saunders. 2023. Language models can explain neurons in language models. https://openaipublic.blob.core.windows.net/neuron-explainer/paper/index.html
2023
-
[37]
Trenton Bricken, Adly Templeton, Joshua Batson, Brian Chen, Adam Jermyn, Shan Carter, and Chris Olah. 2023. https://transformer-circuits.pub/2023/monosemantic-features Towards monosemanticity: Decomposing language models with dictionary learning . Transformer Circuits Thread
2023
-
[38]
Jannik Brinkmann, Chris Wendler, Christian Bartelt, and Aaron Mueller. 2025. Large language models share representations of latent grammatical concepts across typologically diverse languages. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1:...
2025
-
[39]
Common Crawl Foundation . 2026. https://commoncrawl.github.io/cc-crawl-statistics/plots/languages.html Statistics of common crawl monthly archives: Distribution of languages . Accessed 2026-06-01
2026
-
[40]
Hoagy Cunningham, Aidan Ewart, Logan Riggs, Robert Huben, and Lee Sharkey. 2024. https://arxiv.org/abs/2309.08600 Sparse autoencoders find highly interpretable features in language models . International Conference on Learning Representations (ICLR)
Pith/arXiv arXiv 2024
-
[41]
Boyi Deng, Yu Wan, Baosong Yang, Yidan Zhang, and Fuli Feng. 2025. Unveiling language-specific features in large language models via sparse autoencoders. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics
2025
-
[42]
Fangxiaoyu Feng, Yinfei Yang, Daniel Cer, Naveen Arivazhagan, and Wei Wang. 2022. https://doi.org/10.18653/v1/2022.acl-long.62 Language-agnostic BERT sentence embedding . In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 878--891, Dublin, Ireland. Association for Computational Linguistics
-
[43]
Bogdan, Emmanuel Ameisen, James Chen, Dzmitry Kishylau, Adam Pearce, Julius Tarng, Alex Wu, Jeff Wu, Yang Zhang, Daniel M
Kit Fraser-Taliente, Subhash Kantamneni, Euan Ong, Dan Mossing, Christina Lu, Paul C. Bogdan, Emmanuel Ameisen, James Chen, Dzmitry Kishylau, Adam Pearce, Julius Tarng, Alex Wu, Jeff Wu, Yang Zhang, Daniel M. Ziegler, Evan Hubinger, Joshua Batson, Jack Lindsey, Samuel Zimmerman, and Samuel Marks. 2026. https://transformer-circuits.pub/2026/nla/index.html ...
2026
-
[44]
Leo Gao, Tom Dupr \'e la Tour, Henk Tillman, Gabriel Goh, Rajan Tow, Igor Babuschkin, Ilya Sutskever, Jan Leike, and Jeff Wu. 2024. Scaling and evaluating sparse autoencoders. arXiv preprint arXiv:2406.04093
Pith/arXiv arXiv 2024
-
[45]
Gemma Team . 2025. https://arxiv.org/abs/2503.19786 Gemma 3 technical report . Preprint, arXiv:2503.19786
Pith/arXiv arXiv 2025
-
[46]
Mor Geva, Avi Caciularu, Kevin Wang, and Yoav Goldberg. 2022. https://doi.org/10.18653/v1/2022.emnlp-main.3 Transformer feed-forward layers build predictions by promoting concepts in the vocabulary space . In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 30--45, Abu Dhabi, United Arab Emirates. Association f...
-
[47]
Zhengfu He, Wentao Shu, Xuyang Ge, Lingjie Chen, Junxuan Wang, Yunhua Zhou, Frances Liu, Qipeng Guo, Xuanjing Huang, Zuxuan Wu, Yu-Gang Jiang, and Xipeng Qiu. 2024. Llama scope: Extracting millions of features from llama-3.1-8b with sparse autoencoders. arXiv preprint arXiv:2410.20526
arXiv 2024
-
[48]
Jing Huang, Atticus Geiger, Karel D'Oosterlinck, Zhengxuan Wu, and Christopher Potts. 2023. Rigorously assessing natural language explanations of neurons. arXiv preprint arXiv:2309.10312
arXiv 2023
-
[49]
Georges Labrèche. 2025. https://doi.org/10.5281/zenodo.17663256 Cyrtranslit . Python package for bidirectional Cyrillic--Latin transliteration
-
[50]
Zihao Li, Yucheng Shi, Zirui Liu, Fan Yang, Ali Payani, Ninghao Liu, and Mengnan Du. 2024. https://arxiv.org/abs/2404.11553 Language ranker: A metric for quantifying llm performance across high and low-resource languages . arXiv preprint arXiv:2404.11553
arXiv 2024
-
[51]
Johnny Lin and Joseph Bloom. 2023. Neuronpedia. https://www.neuronpedia.org. Interactive platform for sparse autoencoder and neuron interpretability
2023
-
[52]
Danni Liu and Jan Niehues. 2025. https://doi.org/10.18653/v1/2025.acl-long.778 Middle-layer representation alignment for cross-lingual transfer in fine-tuned LLM s . In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 15979--15996, Vienna, Austria. Association for Computational Linguistics
-
[53]
Weiqi Liu, Yongliang Miao, Haiyan Zhao, Yanguang Liu, and Mengnan Du. 2026. https://arxiv.org/abs/2601.03671 Neuronscope: A multi-agent framework for explaining polysemantic neurons in language models . arXiv preprint arXiv:2601.03671
arXiv 2026
-
[54]
Callum McDougall, Arthur Conmy, J \'a nos Kram \'a r, Tom Lieberum, Senthooran Rajamanoharan, and Neel Nanda. 2025. https://storage.googleapis.com/deepmind-media/DeepMind.com/Blog/gemma-scope-2-helping-the-ai-safety-community-deepen-understanding-of-complex-language-model-behavior/Gemma_Scope_2_Technical_Paper.pdf Gemma scope 2: Technical paper . Technica...
2025
-
[55]
NLLB Team , Marta R. Costa-juss \`a , James Cross, Onur C elebi, Maha Elbayad, Kenneth Heafield, Kevin Heffernan, Elahe Kalbassi, Janice Lam, Daniel Licht, Jean Maillard, Anna Sun, Skyler Wang, Guillaume Wenzek, Al Youngblood, Bapi Akula, Lo \"i c Barrault, Gabriel Mejia Gonzalez, Prangthip Hansanti, and 20 others. 2024. https://doi.org/10.1038/s41586-024...
-
[56]
Senthooran Rajamanoharan, Tom Lieberum, Nicolas Sonnerat, Arthur Conmy, Vikrant Varma, J \'a nos Kram \'a r, and Neel Nanda. 2024. https://arxiv.org/abs/2407.14435 Jumping ahead: Improving reconstruction fidelity with jumprelu sparse autoencoders . Preprint, arXiv:2407.14435
Pith/arXiv arXiv 2024
-
[57]
RNIDS . 2016. https://www.rnids.rs/en/news/cyrbusters-panel-debate-held-busting-myths-about-cyrillic-on-the-internet-2 Cyrbusters panel debate held: Busting myths about cyrillic on the internet . Reports an estimated 70:30 Latin-to-Cyrillic ratio in the Serbian market
2016
-
[58]
Adly Templeton, Trenton Bricken, Joshua Batson, Brian Chen, Adam Jermyn, Shan Carter, Chris Olah, and 1 others. 2024. https://transformer-circuits.pub/2024/scaling-monosemanticity Scaling monosemanticity: Extracting interpretable features from claude 3 sonnet . Transformer Circuits Thread
2024
-
[59]
Aastha A. K. Verma, Anwoy Chatterjee, Mehak Gupta, and Tanmoy Chakraborty. 2026. https://openreview.net/forum?id=QHR4upgkCV Multilingual language models encode script over linguistic structure . In Proceedings of the 64th Annual Meeting of the Association for Computational Linguistics (ACL 2026). ACL 2026 Main Conference
2026
-
[60]
Chris Wendler, Veniamin Veselovsky, Giovanni Monea, and Robert West. 2024. https://doi.org/10.18653/v1/2024.acl-long.820 Do llamas work in E nglish? on the latent language of multilingual transformers . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 15366--15394, Bangkok, Thailand....
-
[61]
Zhaofeng Wu, Xinyan Velocity Yu, Dani Yogatama, Jiasen Lu, and Yoon Kim. 2025. https://arxiv.org/abs/2411.04986 The semantic hub hypothesis: Language models share semantic representations across languages and modalities . In International Conference on Learning Representations (ICLR)
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.