Score-Control for Hallucination Reduction in Diffusion Models
Pith reviewed 2026-06-28 22:42 UTC · model grok-4.3
The pith
Variance-guided modulation of the score Jacobian reduces hallucinations in diffusion models by lowering the Lipschitz constant of the learned score.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Hallucinations arise because the learned score function is smoother than the ground-truth score; the probability mass of such hallucinations scales with the Lipschitz constant of the learned score. Variance-Guided Score Modulation controls the score Jacobian during sampling to reduce this constant, thereby decreasing hallucination mass without new artifacts.
What carries the argument
Variance-Guided Score Modulation (VSM), a strategy that adjusts the score estimate using local variance to control the Jacobian and lower the Lipschitz constant of the score function.
If this is right
- Hallucination rate scales directly with the Lipschitz constant of the score function.
- Reducing score smoothness improves approximation to the true data distribution.
- New benchmarks with extreme semantic variation enable repeatable measurement of hallucination reduction.
- The modulation can be applied during sampling without retraining the underlying model.
Where Pith is reading between the lines
- The same smoothness-hallucination link may appear in diffusion models for modalities other than images.
- Controlling the score Jacobian offers a route to reliability improvements in safety-critical image generation uses.
- The density-based view of hallucinations could be used to diagnose other failure modes such as mode collapse.
Load-bearing premise
Lowering the Lipschitz constant of the learned score will reduce hallucination probability mass without creating new artifacts or lowering sample quality.
What would settle it
A controlled experiment in which a diffusion model with measurably lower Lipschitz constant after modulation still produces the same hallucination rate as the baseline, or produces visibly degraded samples.
Figures



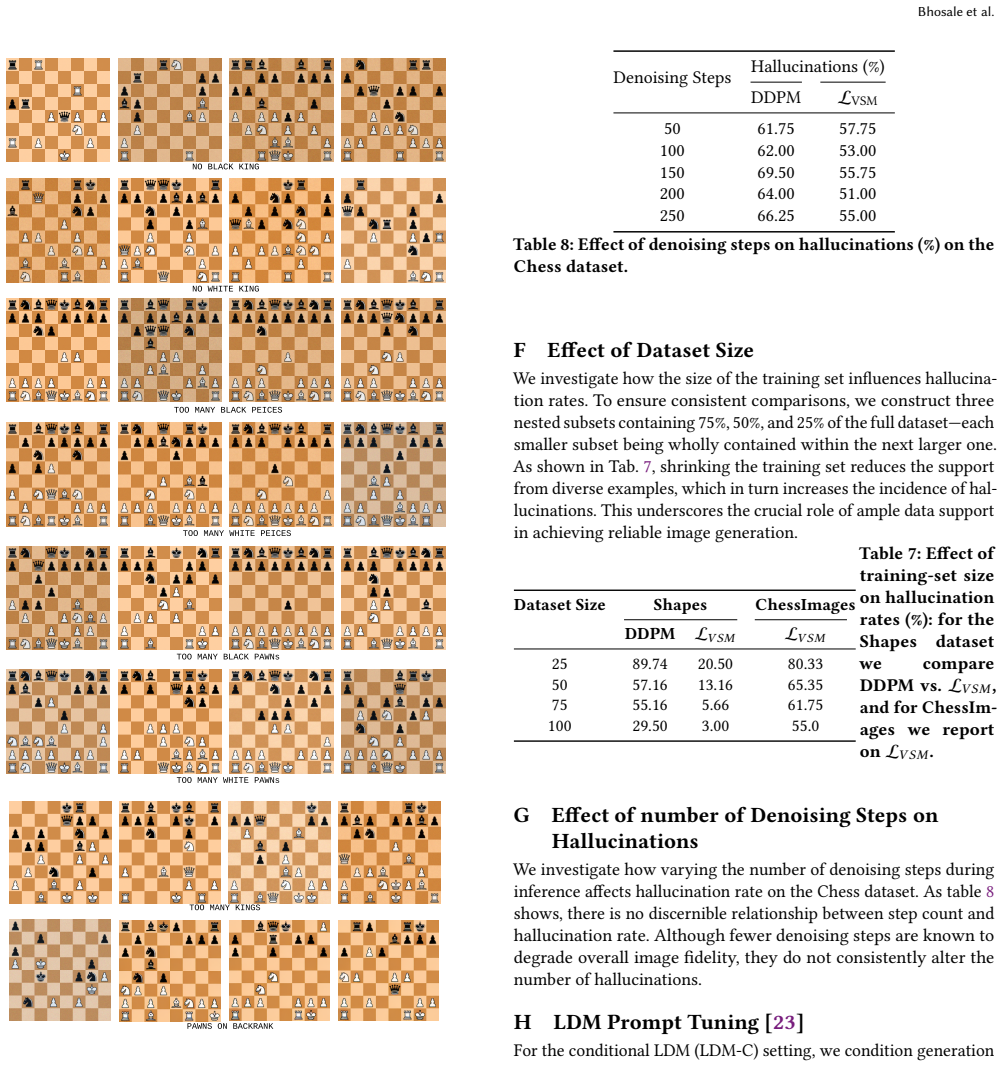


read the original abstract
Diffusion models have emerged as the backbone of modern generative AI, powering advances in vision, language, audio and other modalities. Despite their success, they suffer from hallucinations, implausible samples that lie outside the support of true data distribution, which degrade reliability and trust. In this work, we first empirically confirm previously proposed hypothesis that score smoothness causes hallucinations in Image Generation diffusion models and provide a density-based perspective. We further formalize this notion by linking the hallucinations probability mass to lipschitz constant of the learned score function. Motivated by this, we introduce a Variance-Guided Score Modulation (VSM) strategy that controls the score Jacobian, in turn reducing score smoothness and better approximating the ground truth score that decreases hallucinations. Empirical results on synthetic and real-world datasets demonstrate that our approach reduces hallucinations (up to ~25%) while maintaining high fidelity and diversity, providing a principled step toward more reliable diffusion-based image generation. We also propose two benchmark datasets with extreme semantic variation for systematic hallucination evaluation. Code and Datasets are publicly available at https://github.com/bhosalems/VSM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper empirically confirms the hypothesis that score smoothness causes hallucinations in diffusion-based image generation and provides a density-based perspective. It formalizes the connection by linking hallucination probability mass to the Lipschitz constant of the learned score function. Motivated by this, it introduces Variance-Guided Score Modulation (VSM) to control the score Jacobian, thereby reducing smoothness and better approximating the ground-truth score. Experiments on synthetic and real-world datasets report up to ~25% hallucination reduction while preserving fidelity and diversity; two new benchmark datasets with extreme semantic variation are also proposed, with code and data released publicly.
Significance. If the formalization yields a quantitative bound and VSM demonstrably reduces the relevant Lipschitz constant without introducing new artifacts, the work would provide a principled, controllable mechanism for improving reliability of diffusion models. Public code and datasets are a clear strength that supports reproducibility and further testing of the empirical claims.
major comments (3)
- [Formalization (abstract and motivating sections)] The abstract states that the hallucinations probability mass is linked to the Lipschitz constant of the learned score, but provides neither an equation nor a proof sketch establishing a quantitative relationship (e.g., an inequality bounding P(hallucination) by Lip(s) or a related quantity). Without this, it is unclear whether the link is tight enough for VSM to guarantee reduction rather than merely correlate with it.
- [VSM strategy description] The variance-guided modulation mechanism is described only at high level; it is not shown whether the Jacobian control is uniform, local, or could increase the Lipschitz constant in other regions of the score function, potentially trading one form of hallucination for another or altering out-of-support mass.
- [Empirical evaluation and benchmarks] Empirical results claim up to ~25% reduction, yet the abstract supplies no information on hallucination measurement protocol, data exclusion rules, statistical error bars, or how the new benchmarks avoid circularity with the evaluation metric.
minor comments (2)
- [Abstract] The abstract refers to a 'previously proposed hypothesis' without a citation; adding the reference would clarify the novelty of the empirical confirmation.
- [Method section] Notation for the score function, Jacobian, and variance guidance should be introduced consistently before the VSM definition to aid readability.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. The comments highlight opportunities to improve clarity in the formalization, the description of VSM, and the presentation of empirical details. We address each point below and commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Formalization (abstract and motivating sections)] The abstract states that the hallucinations probability mass is linked to the Lipschitz constant of the learned score, but provides neither an equation nor a proof sketch establishing a quantitative relationship (e.g., an inequality bounding P(hallucination) by Lip(s) or a related quantity). Without this, it is unclear whether the link is tight enough for VSM to guarantee reduction rather than merely correlate with it.
Authors: We agree that the abstract and motivating sections would benefit from an explicit statement of the quantitative link. The density-based perspective in the paper connects hallucination mass to score smoothness via the Lipschitz constant, but we will revise to include the key inequality (P(hallucination) bounded in terms of Lip(s)) together with a short derivation sketch in both the abstract and Section 3. This will make the motivation for controlling the Jacobian via VSM more precise. revision: yes
-
Referee: [VSM strategy description] The variance-guided modulation mechanism is described only at high level; it is not shown whether the Jacobian control is uniform, local, or could increase the Lipschitz constant in other regions of the score function, potentially trading one form of hallucination for another or altering out-of-support mass.
Authors: The VSM modulation is constructed to act locally by scaling the score update according to per-sample variance estimates, which targets regions of high uncertainty without uniform application across the entire function. We will expand the method section with the explicit update rule, a brief analysis of the resulting local Lipschitz behavior, and additional diagnostics confirming that the global Lip constant does not increase and that out-of-support mass is not inflated. If the current experiments do not fully address this, we will add targeted ablations. revision: partial
-
Referee: [Empirical evaluation and benchmarks] Empirical results claim up to ~25% reduction, yet the abstract supplies no information on hallucination measurement protocol, data exclusion rules, statistical error bars, or how the new benchmarks avoid circularity with the evaluation metric.
Authors: The measurement protocol (including semantic outlier detection, exclusion criteria, and error bars from multiple seeds) is fully specified in the experimental section, and the new benchmarks use held-out semantic categories disjoint from training data to avoid circularity. We will revise the abstract to include a concise statement of the evaluation protocol and benchmark construction. This addresses the presentation concern while leaving the underlying results unchanged. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper empirically confirms a prior external hypothesis on score smoothness and hallucinations, asserts a formal link between hallucination probability mass and the Lipschitz constant of the score function, and introduces a new VSM modulation strategy motivated by that link. No equations, self-citations, or fitted parameters are shown reducing the central claims to inputs by construction. The derivation chain rests on new empirical validation and a proposed control mechanism rather than self-referential definitions or renamings, making the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Score smoothness (Lipschitz constant of learned score) causes hallucinations in diffusion models
Reference graph
Works this paper leans on
-
[1]
2025.Adobe Firefly: The next evolution of creative AI is here
Adobe. 2025.Adobe Firefly: The next evolution of creative AI is here. https://blog.adobe.com/en/publish/2025/04/24/adobe-firefly-next- evolution-creative-ai-is-here Adobe reports 22B+ Firefly-generated assets world- wide
2025
-
[2]
Mahmoud Afifi. 2019. 11K Hands: Gender recognition and biometric identifica- tion using a large dataset of hand images.Multimedia Tools Appl.78, 15 (Aug. 2019), 20835–20854. doi:10.1007/s11042-019-7424-8
-
[3]
Lipton, and J
Sumukh K Aithal, Pratyush Maini, Zachary C. Lipton, and J. Zico Kolter. 2024. Understanding Hallucinations in Diffusion Models through Mode Interpolation. InAdvances in Neural Information Processing Systems, A. Globerson, L. Mackey, Figure 11: We observe that our method corrects the deformed objects, incompletely denoised images on the ImageNet-1K dataset...
2024
-
[4]
Ahmed Alaa, Boris Van Breugel, Evgeny S Saveliev, and Mihaela Van Der Schaar
-
[5]
InInternational conference on machine learning
How faithful is your synthetic data? sample-level metrics for evaluating and auditing generative models. InInternational conference on machine learning. PMLR, 290–306
-
[6]
Nick Alger, Tucker Hartland, Noemi Petra, and Omar Ghattas. 2024. Point spread function approximation of high-rank Hessians with locally supported nonnegative integral kernels.SIAM Journal on Scientific Computing46, 3 (2024), A1658–A1689
2024
-
[7]
Mahesh Bhosale, Abdul Wasi, Yuanhao Zhai, Yunjie Tian, Samuel Border, Nan Xi, Pinaki Sarder, Junsong Yuan, David Doermann, and Xuan Gong. 2025. PathDiff: Histopathology Image Synthesis with Unpaired Text and Mask Conditions. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). 22415–22424
2025
-
[8]
Bradley C. A. Brown, Anthony L. Caterini, Brendan Leigh Ross, Jesse C. Cresswell, and Gabriel Loaiza-Ganem. 2023. Verifying the Union of Manifolds Hypothesis for Image Data. arXiv:2207.02862 [stat.ML] https://arxiv.org/abs/2207.02862
arXiv 2023
-
[9]
Zhengdao Chen. 2025. On the Interpolation Effect of Score Smoothing.arXiv preprint arXiv:2502.19499(2025)
Pith/arXiv arXiv 2025
-
[10]
Naresh Kumar Devulapally, Mingzhen Huang, Vishal Asnani, Shruti Agarwal, Siwei Lyu, and Vishnu Suresh Lokhande. 2025. Your Text Encoder Can Be An Object-Level Watermarking Controller. arXiv:2503.11945 [cs.CV] https: //arxiv.org/abs/2503.11945
arXiv 2025
-
[11]
Gerald B. Folland. 1999.Real Analysis: Modern Techniques and Their Applications (2nd ed.). John Wiley & Sons, New York
1999
-
[12]
Zhiye Guo, Jian Liu, Yanli Wang, Mengrui Chen, Duolin Wang, Dong Xu, and Jianlin Cheng. 2024. Diffusion models in bioinformatics and computational biology.Nature reviews bioengineering2, 2 (2024), 136–154
2024
-
[13]
Susan Hao, Piyush Kumar, Sarah Laszlo, Shivani Poddar, Bhaktipriya Radharapu, and Renee Shelby. 2023. Safety and fairness for content moderation in generative models.arXiv preprint arXiv:2306.06135(2023)
arXiv 2023
-
[14]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. 2020. Denoising diffusion probabilistic models.Advances in neural information processing systems33 (2020), 6840–6851
2020
-
[15]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. 2020. Denoising Diffusion Probabilistic Models.NeurIPS(2020). https://arxiv.org/abs/2006.11239 Score-Control for Hallucination Reduction in Diffusion Models
Pith/arXiv arXiv 2020
-
[16]
Chawla, Jian Pei, Jianfeng Gao, Michael Backes, Philip S
Yue Huang, Chujie Gao, Siyuan Wu, Haoran Wang, Xiangqi Wang, Yujun Zhou, Yanbo Wang, Jiayi Ye, Jiawen Shi, Qihui Zhang, Yuan Li, Han Bao, Zhaoyi Liu, Tianrui Guan, Dongping Chen, Ruoxi Chen, Kehan Guo, Andy Zou, Bryan Hooi Kuen-Yew, Caiming Xiong, Elias Stengel-Eskin, Hongyang Zhang, Hongzhi Yin, Huan Zhang, Huaxiu Yao, Jaehong Yoon, Jieyu Zhang, Kai Shu,...
Pith/arXiv arXiv 2025
-
[17]
Marco Jiralerspong, Joey Bose, Ian Gemp, Chongli Qin, Yoram Bachrach, and Gauthier Gidel. 2023. Feature likelihood divergence: evaluating the generalization of generative models using samples.Advances in Neural Information Processing Systems36 (2023), 33095–33119
2023
-
[18]
Seunghoi Kim, Chen Jin, Tom Diethe, Matteo Figini, Henry F. J. Tregidgo, Asher Mullokandov, Philip Teare, and Daniel C. Alexander. 2024. Tack- ling Structural Hallucination in Image Translation with Local Diffusion. arXiv:2404.05980 [cs.CV] https://arxiv.org/abs/2404.05980
arXiv 2024
-
[19]
Saksham Singh Kushwaha, Jianbo Ma, Mark RP Thomas, Yapeng Tian, and Avery Bruni. 2025. Diff-SAGe: End-to-End Spatial Audio Generation Using Diffusion Models. InICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 1–5
2025
-
[20]
Tuomas Kynkäänniemi, Tero Karras, Samuli Laine, Jaakko Lehtinen, and Timo Aila. 2019. Improved Precision and Recall Metric for Assessing Generative Models. arXiv:1904.06991 [stat.ML] https://arxiv.org/abs/1904.06991
arXiv 2019
-
[21]
Lecun, L
Y. Lecun, L. Bottou, Y. Bengio, and P. Haffner. 1998. Gradient-based learning applied to document recognition.Proc. IEEE86, 11 (1998), 2278–2324. doi:10. 1109/5.726791
1998
-
[22]
Xiang Li, John Thickstun, Ishaan Gulrajani, Percy S Liang, and Tatsunori B Hashimoto. 2022. Diffusion-lm improves controllable text generation.Advances in neural information processing systems35 (2022), 4328–4343
2022
-
[23]
Rui Lu, Runzhe Wang, Kaifeng Lyu, Xitai Jiang, Gao Huang, and Mengdi Wang
-
[24]
InThe Thirteenth International Conference on Learning Represen- tations
Towards understanding text hallucination of diffusion models via local generation bias. InThe Thirteenth International Conference on Learning Represen- tations
-
[25]
Shweta Mahajan, Tanzila Rahman, Kwang Moo Yi, and Leonid Sigal. 2024. Prompting hard or hardly prompting: Prompt inversion for text-to-image diffu- sion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 6808–6817
2024
-
[26]
Chenlin Meng, Yang Song, Wenzhe Li, and Stefano Ermon. 2021. Estimating High Order Gradients of the Data Distribution by Denoising. InNeurIPS. 12477–12488
2021
-
[27]
Alexander Quinn Nichol and Prafulla Dhariwal. 2021. Improved denoising diffusion probabilistic models. InInternational conference on machine learning. PMLR, 8162–8171
2021
-
[28]
Trevine Oorloff, Yaser Yacoob, and Abhinav Shrivastava. 2025. Mitigating Hallu- cinations in Diffusion Models through Adaptive Attention Modulation.arXiv preprint arXiv:2502.16872(2025)
arXiv 2025
-
[29]
Zaki, Luca Ambrogioni, and Dmitry Krotov
Bao Pham, Gabriel Raya, Matteo Negri, Mohammed J. Zaki, Luca Ambrogioni, and Dmitry Krotov. 2025. Memorization to Generalization: Emergence of Diffusion Models from Associative Memory.arXiv preprint arXiv:2505.21777(2025)
arXiv 2025
-
[30]
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. 2022. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 10684–10695
2022
-
[31]
1976.Principles of Mathematical Analysis(3rd ed.)
Walter Rudin. 1976.Principles of Mathematical Analysis(3rd ed.). McGraw-Hill, New York. Extreme Value Theorem: a continuous function on a compact set attains a minimum and maximum
1976
-
[32]
Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, Alexan- der C. Berg, and Li Fei-Fei. 2015. ImageNet Large Scale Visual Recognition Challenge. arXiv:1409.0575 [cs.CV] https://arxiv.org/abs/1409.0575
Pith/arXiv arXiv 2015
-
[33]
Soumadeep Saha, Saptarshi Saha, and Utpal Garain. 2023. VALUED–Vision and Logical Understanding Evaluation Dataset.arXiv preprint arXiv:2311.12610 (2023)
arXiv 2023
-
[34]
Chitwan Saharia, William Chan, Huiwen Chang, Chris Lee, Jonathan Ho, Tim Salimans, David Fleet, and Mohammad Norouzi. 2022. Palette: Image-to-image diffusion models. InACM SIGGRAPH 2022 conference proceedings. 1–10
2022
-
[35]
Xudong Shen, Chao Du, Tianyu Pang, Min Lin, Yongkang Wong, and Mohan Kankanhalli. 2023. Finetuning text-to-image diffusion models for fairness.arXiv preprint arXiv:2311.07604(2023)
arXiv 2023
-
[36]
Jiaming Song, Chenlin Meng, and Stefano Ermon. 2020. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502(2020)
Pith/arXiv arXiv 2020
-
[37]
Yang Song and Stefano Ermon. 2019. Generative modeling by estimating gradi- ents of the data distribution.Advances in neural information processing systems 32 (2019)
2019
-
[39]
Kingma, Abhishek Kumar, Ste- fano Ermon, and Ben Poole
Yang Song, Jascha Sohl-Dickstein, Diederik P. Kingma, Abhishek Kumar, Ste- fano Ermon, and Ben Poole. 2021. Score-Based Generative Modeling through Stochastic Differential Equations.ICLR(2021). https://arxiv.org/abs/2011.13456
Pith/arXiv arXiv 2021
-
[40]
2024.Introducing Stable Diffusion 3.5
Stability AI. 2024.Introducing Stable Diffusion 3.5. https://stability.ai/news/ introducing-stable-diffusion-3-5 Official announcement of the SD 3.5 model family
2024
-
[41]
2025.The 2025 AI Index Report
Stanford HAI. 2025.The 2025 AI Index Report. https://hai.stanford.edu/ai- index/2025-ai-index-report Reports 78% of organizations using AI in 2024
2025
-
[42]
Kostas Triaridis, Alexandros Graikos, Aggelina Chatziagapi, Grigorios G. Chrysos, and Dimitris Samaras. 2025. Mitigating Diffusion Model Hallucinations with Dynamic Guidance. arXiv:2510.05356 [cs.CV] https://arxiv.org/abs/2510. 05356
Pith/arXiv arXiv 2025
-
[43]
Christopher Wewer, Bart Pogodzinski, Bernt Schiele, and Jan Eric Lenssen. 2025. Spatial reasoning with denoising models.arXiv preprint arXiv:2502.21075(2025)
arXiv 2025
-
[44]
Tong Wu, Zhihao Fan, Xiao Liu, Hai-Tao Zheng, Yeyun Gong, Jian Jiao, Juntao Li, Jian Guo, Nan Duan, Weizhu Chen, et al. 2023. Ar-diffusion: Auto-regressive diffusion model for text generation.Advances in Neural Information Processing Systems36 (2023), 39957–39974
2023
-
[45]
Zhantao Yang, Ruili Feng, Han Zhang, Yujun Shen, Kai Zhu, Lianghua Huang, Yifei Zhang, Yu Liu, Deli Zhao, Jingren Zhou, and Fan Cheng. 2024. Lipschitz Singularities in Diffusion Models. arXiv:2306.11251 [cs.CV] https://arxiv.org/ abs/2306.11251
arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.