Multi-Objective Reference-Aligned Machine Unlearning
Pith reviewed 2026-06-28 22:59 UTC · model grok-4.3
The pith
RAUL achieves the closest performance to full retraining by bounding the forgetting objective with KL alignment to a reference distribution.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
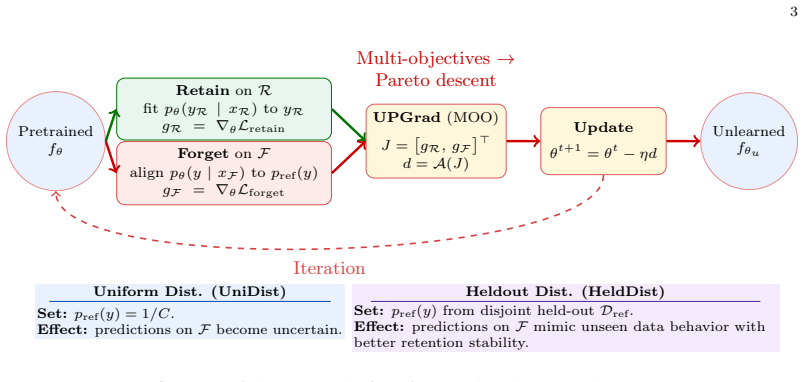
We propose Reference-Aligned UnLearning (RAUL), a multi-objective framework that jointly optimizes forgetting and retention by replacing unbounded loss maximization with a bounded KL alignment of predictions on forgotten samples toward a reference distribution representing unseen data, instantiated either as a uniform distribution or an empirical distribution from a held-out reference set, which constrains the forgetting objective and reduces gradient conflict with retention. The resulting multi-objective optimization problem is solved via Jacobian descent, which aggregates multiple gradients into a direction that does not conflict. Our results demonstrate that RAUL achieves the closest gap
What carries the argument
Bounded KL alignment of predictions on forgotten samples to a reference distribution (uniform or empirical from held-out data), solved jointly with retention via Jacobian descent.
If this is right
- Forgetting objectives remain bounded, limiting drift from the original pre-trained parameters.
- Gradient conflicts between forgetting and retention are reduced, preserving utility on retained data.
- Model performance after unlearning stays closer to the ideal of retraining from scratch on the remaining data.
- The same bounded alignment can be instantiated with either a uniform or an empirical reference without changing the overall optimization procedure.
Where Pith is reading between the lines
- If held-out reference sets are small or unrepresentative, the empirical distribution may need augmentation to maintain the reported closeness to retraining.
- Jacobian descent for non-conflicting gradient aggregation could be tested on other multi-objective machine-learning tasks beyond unlearning.
Load-bearing premise
The reference distribution accurately represents unseen data in a way that constrains forgetting without introducing new biases that reduce retention effectiveness.
What would settle it
An experiment on standard benchmarks where an existing single-objective method records a smaller gap to full retraining accuracy than RAUL would falsify the central performance claim.
Figures
read the original abstract
Machine unlearning aims to remove the influence of specific training samples while preserving the model's utility. Existing single-objective approaches, such as gradient ascent or random relabeling, often induce catastrophic forgetting due to conflicting optimization dynamics and unbounded forgetting objectives that cause the model to drift from its pre-trained knowledge. We propose Reference-Aligned UnLearning (RAUL), a multi-objective framework that jointly optimizes forgetting and retention by replacing unbounded loss maximization with a bounded KL alignment of predictions on forgotten samples toward a reference distribution representing unseen data, instantiated either as a uniform distribution or an empirical distribution from a held-out reference set, which constrains the forgetting objective and reduces gradient conflict with retention. The resulting multi-objective optimization (MOO) problem is solved via Jacobian descent, which aggregates multiple gradients into a direction that does not conflict. Our results demonstrate that RAUL achieves the closest gap compared to full retraining.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Reference-Aligned UnLearning (RAUL), a multi-objective optimization framework for machine unlearning. It replaces unbounded loss maximization on forgotten samples with a bounded KL alignment of model predictions toward a reference distribution (instantiated as uniform or as the empirical distribution from a held-out set), jointly optimizes this with a retention objective, and solves the resulting MOO problem via Jacobian descent to produce a non-conflicting update direction. The central claim is that RAUL yields the smallest performance gap to full retraining.
Significance. If the empirical results hold under rigorous validation, the work would advance machine unlearning by supplying a principled mechanism to bound the forgetting objective and mitigate gradient conflicts that produce catastrophic forgetting in single-objective baselines. The explicit use of a reference distribution and Jacobian descent for aggregation constitutes a concrete technical contribution that could be adopted more broadly if the reference-distribution premise is shown to be robust.
major comments (2)
- [Abstract] Abstract: the bounded KL(p_model || p_ref) term is presented as the mechanism that constrains forgetting and reduces gradient conflict with retention, yet the manuscript supplies no derivation, sensitivity analysis, or experiments testing whether mismatch between p_ref (uniform or held-out empirical) and the true unseen-data distribution produces under-forgetting or retention degradation; this premise is load-bearing for the claim that the aggregated Jacobian direction reliably approximates the retraining trajectory.
- [Abstract] Abstract: the claim that RAUL achieves the closest gap to full retraining is stated without reference to any dataset, metric, baseline, statistical test, or error bar; absent these details it is impossible to determine whether the reported improvement is robust or an artifact of post-hoc reference-set selection.
minor comments (1)
- The abstract would benefit from an explicit statement of the multi-objective loss (e.g., the precise weighting or Pareto formulation) and the Jacobian-descent update rule.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. Below we respond point-by-point to the major comments and indicate the corresponding revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the bounded KL(p_model || p_ref) term is presented as the mechanism that constrains forgetting and reduces gradient conflict with retention, yet the manuscript supplies no derivation, sensitivity analysis, or experiments testing whether mismatch between p_ref (uniform or held-out empirical) and the true unseen-data distribution produces under-forgetting or retention degradation; this premise is load-bearing for the claim that the aggregated Jacobian direction reliably approximates the retraining trajectory.
Authors: We agree that an explicit derivation of the bounded KL alignment and a sensitivity analysis on reference-distribution mismatch are not present in the current manuscript. The empirical results across multiple datasets demonstrate that both uniform and held-out empirical references yield smaller gaps to retraining than single-objective baselines, and Jacobian descent is used to resolve gradient conflicts. We will add a derivation subsection showing how the KL term bounds the forgetting objective relative to an unseen-data reference and include new experiments that systematically vary the reference distribution to quantify robustness to mismatch. revision: yes
-
Referee: [Abstract] Abstract: the claim that RAUL achieves the closest gap to full retraining is stated without reference to any dataset, metric, baseline, statistical test, or error bar; absent these details it is impossible to determine whether the reported improvement is robust or an artifact of post-hoc reference-set selection.
Authors: The abstract condenses the primary experimental finding; the full manuscript reports results on standard benchmarks (CIFAR-10, MNIST subsets) using retain/forget accuracy and membership-inference metrics, with comparisons to gradient-ascent and relabeling baselines, and reports means plus standard deviations over repeated runs. The reference distributions are instantiated a priori (uniform or held-out empirical) rather than selected post hoc. We will revise the abstract to include brief references to the evaluation setting while preserving conciseness. revision: partial
Circularity Check
No significant circularity; derivation is self-contained empirical optimization framework.
full rationale
The abstract and description define RAUL via an explicit construction (bounded KL alignment to uniform or held-out empirical reference, solved by Jacobian descent on the multi-objective problem). The central claim of closest gap to full retraining is stated as an empirical outcome, not a mathematical reduction or prediction forced by the definition itself. No equations are shown that equate the result to its inputs by construction, no self-citation chains are invoked as load-bearing uniqueness theorems, and no fitted parameters are relabeled as independent predictions. The reference-distribution assumption is a modeling choice whose validity is external to the derivation; it does not render the reported performance tautological. This matches the default expectation of an independent framework.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
European Parliament and Council of the European Union.Regulation (EU) 2016/679 of the European Parliament and of the Council.Official Journal of the European Union, L119, 1–88. 2016
2016
-
[2]
Shao and Y
C. Shao and Y. Feng.Overcoming catastrophic forgetting beyond continual learning: Balanced training for neural machine translation. 2022
2022
-
[3]
What makes unlearning hard and what to do about it
K. Zhao, M. Kurmanji, G.-O. Bărbulescu, E. Triantafillou, and P. Triantafillou. “What makes unlearning hard and what to do about it”. In:Advances in Neural Information Processing Systems37 (2024), pp. 12293–12333
2024
-
[4]
Z. Pan, S. Zhang, Y. Zheng, C. Li, Y. Cheng, and J. Zhao.Multi-Objective Large Language Model Unlearning. IEEE, 2025
2025
-
[5]
Cheng, Z
X. Cheng, Z. Huang, W. Zhou, Z. He, R. Yang, Y. Wu, and X. Huang.Remaining-data-free machine unlearning by suppressing sample contribution. 2024
2024
-
[6]
Machine Unlearning of Pre-trained Large Language Models
J. Yao, E. Chien, M. Du, X. Niu, T. Wang, Z. Cheng, and X. Yue. “Machine Unlearning of Pre-trained Large Language Models”. In:Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Ed. by L.-W. Ku, A. Martins, and V. Srikumar. Bangkok, Thailand: Association for Computational Linguistics, Aug. 2024,...
-
[7]
Random Relabeling for Efficient Machine Unlearning
J. Li and S. Ghosh. “Random Relabeling for Efficient Machine Unlearning”. In:arXiv preprint arXiv:2305.12320(2023)
-
[8]
H. Zhao, B. Ni, J. Fan, Y. Wang, Y. Chen, G. Meng, and Z. Zhang.Continual forgetting for pre-trained vision models. 2024
2024
-
[9]
Unrolling sgd: Understanding factors influencing machine unlearning
A. Thudi, G. Deza, V. Chandrasekaran, and N. Papernot. “Unrolling sgd: Understanding factors influencing machine unlearning”. In:2022 IEEE 7th European Symposium on Security and Privacy (EuroS&P). IEEE. 2022, pp. 303–319
2022
-
[10]
Eternal sunshine of the spotless net: Selective forget- ting in deep networks
A. Golatkar, A. Achille, and S. Soatto. “Eternal sunshine of the spotless net: Selective forget- ting in deep networks”. In:Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020, pp. 9304–9312
2020
-
[11]
Machine Unlearning of Features and Labels
A. Warnecke, L. Pirch, C. Wressnegger, and K. Rieck. “Machine Unlearning of Features and Labels”. In:arXiv preprint arXiv:2108.11577(2021). 7
-
[12]
Approximate data deletion from machine learningmodels
Z. Izzo, M. A. Smart, K. Chaudhuri, and J. Zou. “Approximate data deletion from machine learningmodels”.In:International Conference on Artificial Intelligence and Statistics.PMLR. 2021, pp. 2008–2016
2021
-
[13]
Model sparsification can simplify machine unlearning
J. Jia, J. Liu, P. Ram, Y. Yao, G. Liu, Y. Liu, P. Sharma, and S. Liu. “Model sparsification can simplify machine unlearning”. In:arXiv preprint arXiv:2304.04934(2023)
-
[14]
C. Fan, J. Liu, Y. Zhang, E. Wong, D. Wei, and S. Liu. “Salun: Empowering machine un- learning via gradient-based weight saliency in both image classification and generation”. In: arXiv preprint arXiv:2310.12508(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
Munba: Machine unlearning via nash bargaining
J. Wu and M. Harandi. “Munba: Machine unlearning via nash bargaining”. In:Proceedings of the IEEE/CVF International Conference on Computer Vision. 2025, pp. 4754–4765
2025
-
[16]
Multiple-gradient descent algorithm (MGDA) for multiobjective optimiza- tion
J.-A. Désidéri. “Multiple-gradient descent algorithm (MGDA) for multiobjective optimiza- tion”. In:Comptes Rendus Mathematique350.5-6 (2012), pp. 313–318
2012
-
[17]
Multi-task learning as multi-objective optimization
O. Sener and V. Koltun. “Multi-task learning as multi-objective optimization”. In:Advances in Neural Information Processing Systems. Vol. 31. 2018
2018
-
[18]
Jacobian descent for multi-objective optimization.arXiv preprint arXiv:2406.16232, February 2025
P. Quinton and V. Rey. “Jacobian Descent For Multi-Objective Optimization”. In:arXiv preprint arXiv:2406.16232(2024)
-
[19]
A fast and elitist multiobjective genetic algorithm: NSGA-II
K. Deb, A. Pratap, S. Agarwal, and T. Meyarivan. “A fast and elitist multiobjective genetic algorithm: NSGA-II”. In:IEEE transactions on evolutionary computation6.2 (2002), pp. 182– 197. 8 AppendixA.Experimental Setup We evaluate RAUL on CIFAR-10 using ResNet-18 under two random-data forgetting scenarios with 10% and 50% of the training set removed (4,500...
2002
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.