Riemannian Stochastic Optimization for Sufficient Dimension Reduction
Pith reviewed 2026-06-28 19:41 UTC · model grok-4.3
The pith
Minimizers of the population MAVE risk approximate the same Grassmannian target as OPG, allowing the empirical MAVE criterion to be recast as smooth maximization on the Stiefel manifold.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
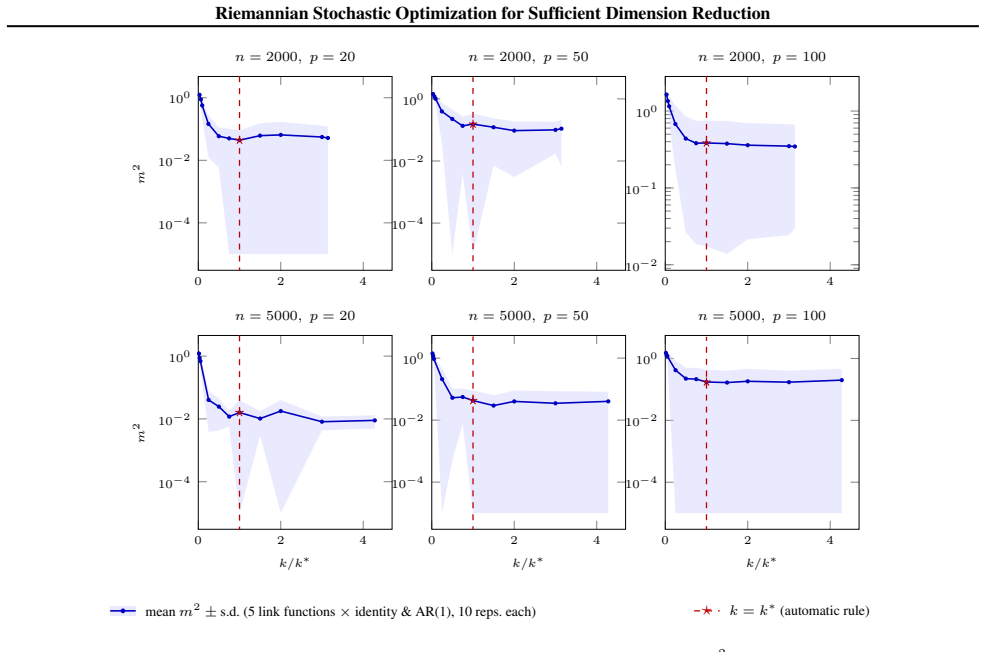
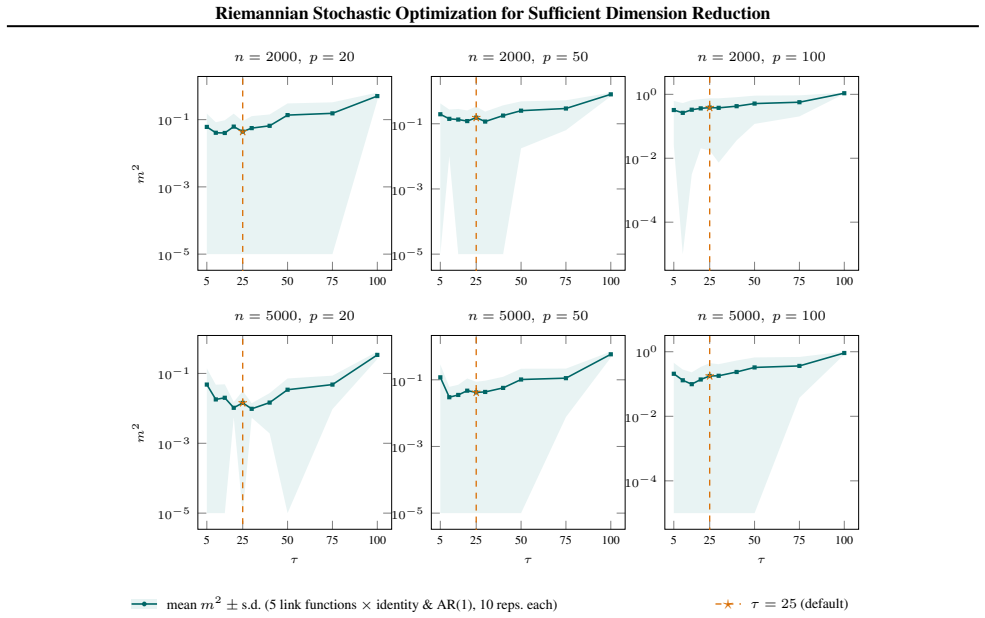
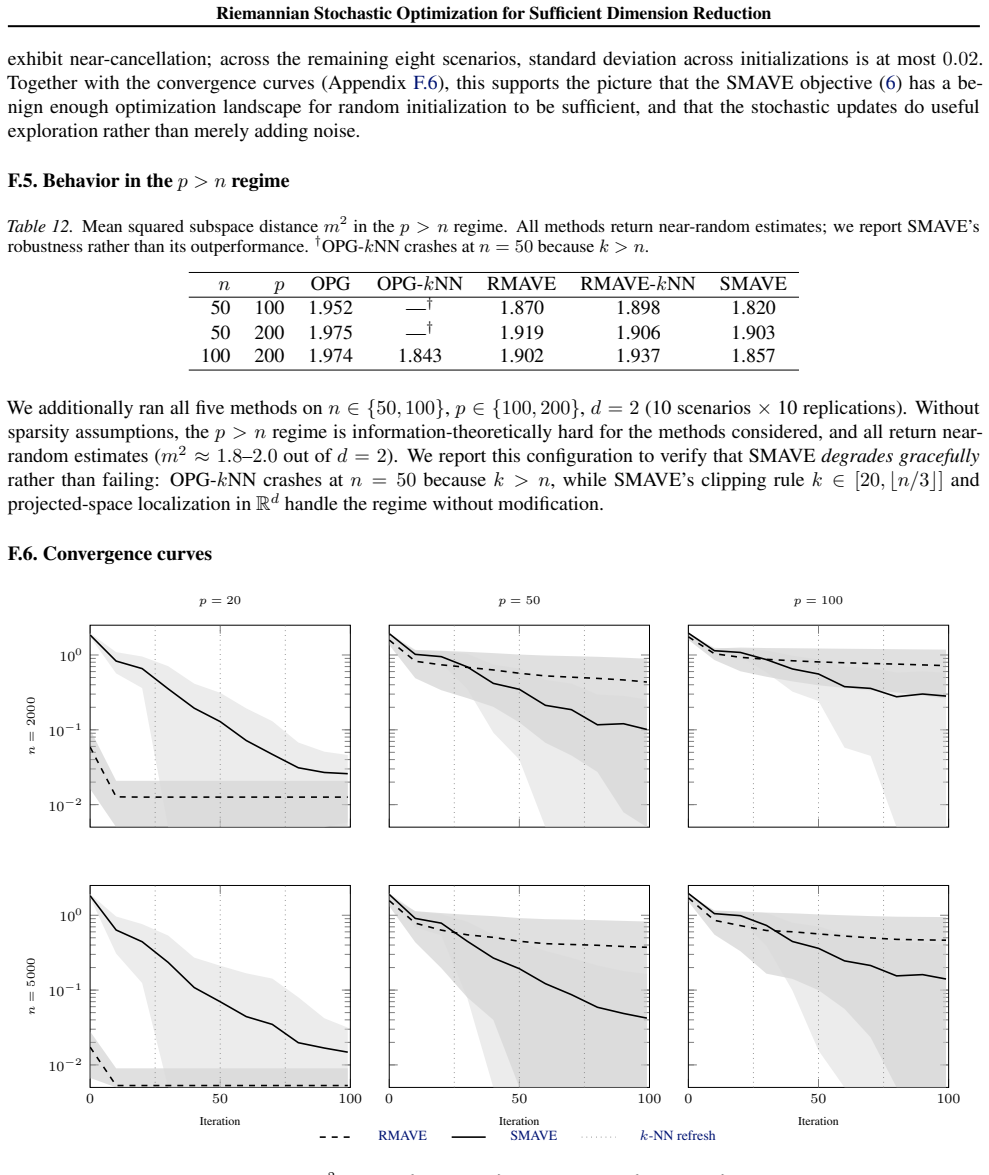
Minimizers of the population Minimum Average Variance Estimation (MAVE) risk approximate the same Grassmannian target as the Outer Product of Gradients (OPG). The empirical MAVE criterion can therefore be recast as a smooth maximization on the Stiefel manifold with closed-form Riemannian gradient. The resulting SMAVE algorithm pairs sparse projected-space nearest-neighbor localization with Riemannian stochastic gradient ascent; a simplified version converges almost surely at the standard non-convex stochastic first-order rate.
What carries the argument
Riemannian stochastic gradient ascent on the Stiefel manifold applied to the recast empirical MAVE objective, using its closed-form Riemannian gradient and sparse nearest-neighbor localization performed in the current projected coordinates.
If this is right
- SMAVE achieves almost-sure convergence to a stationary point of the Stiefel formulation.
- Its non-asymptotic convergence rate matches the usual scaling for non-convex stochastic first-order methods.
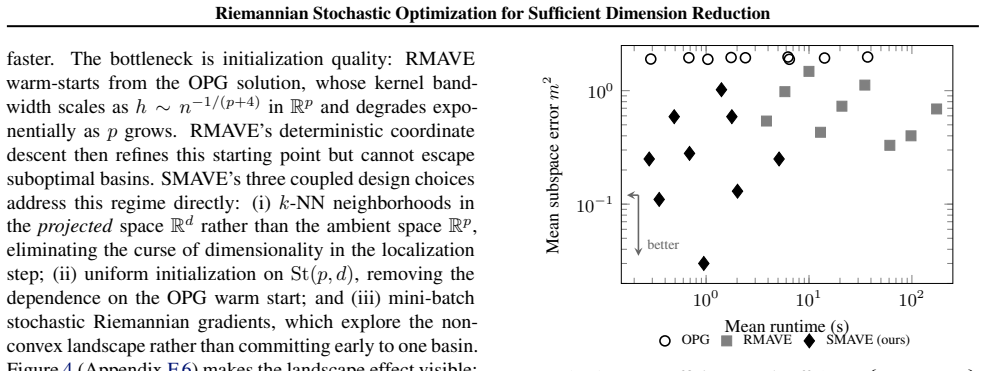
- At moderate-to-high ambient dimension SMAVE matches or exceeds RMAVE subspace recovery accuracy.
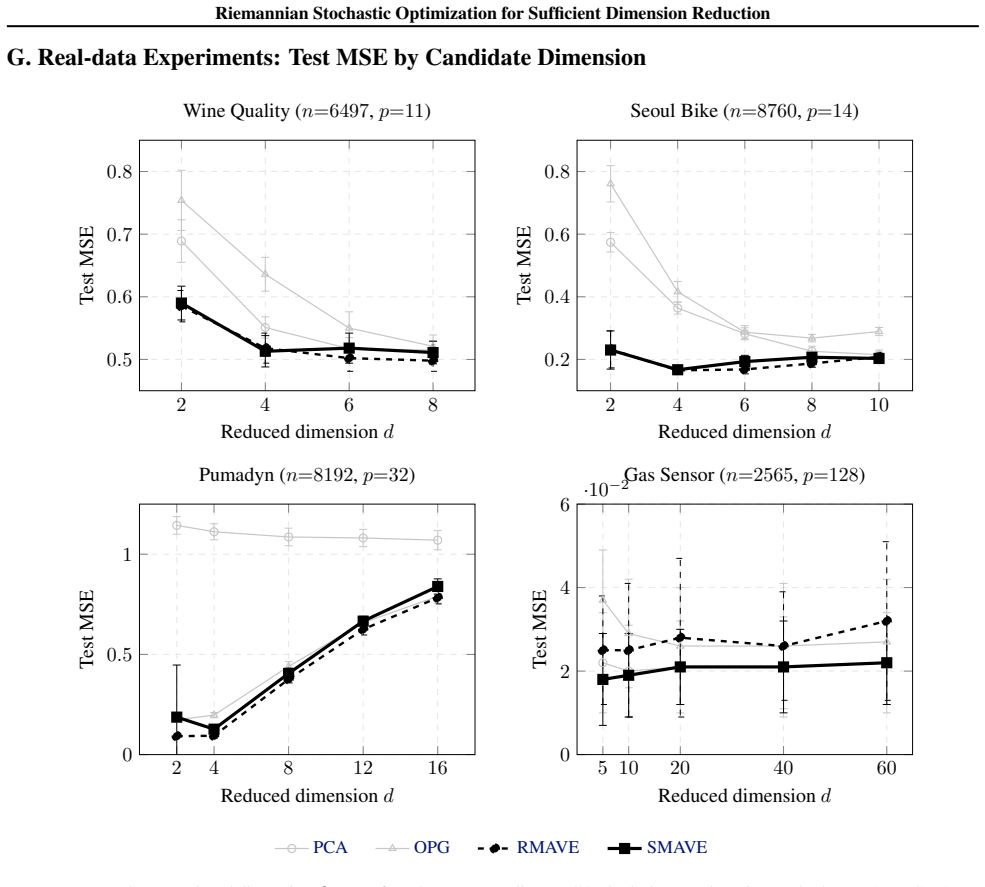
- On real data SMAVE improves uniformly over OPG and matches or beats RMAVE while requiring orders-of-magnitude less runtime.
Where Pith is reading between the lines
- The same manifold recasting could be applied to other gradient-based SDR estimators whose population targets coincide with OPG.
- The stochastic, local-neighbor structure opens the door to streaming or online versions of sufficient dimension reduction.
- Because the Riemannian gradient is closed-form, second-order or variance-reduced extensions become straightforward on the same manifold.
Load-bearing premise
The population minimizers of the MAVE risk recover essentially the same subspace as the OPG estimator.
What would settle it
A data-generating process in which the population MAVE risk is minimized at a subspace measurably different from the OPG subspace.
Figures
read the original abstract
Sufficient dimension reduction (SDR) makes high-dimensional regression tractable by projecting the covariates onto a low-dimensional subspace that preserves the conditional mean of the response. Existing gradient-based estimators either operate in the ambient space and suffer from the curse of dimensionality, or localize in the reduced space at a per-outer-iteration cost at least quadratic in the sample size. We show that minimizers of the population Minimum Average Variance Estimation (MAVE) risk approximate the same Grassmannian target as the Outer Product of Gradients (OPG), and recast the empirical criterion as a smooth maximization on the Stiefel manifold with closed-form Riemannian gradient. The resulting algorithm, SMAVE, combines sparse projected-space nearest-neighbor localization with Riemannian stochastic gradient ascent. A simplified version comes with almost-sure convergence and a non-asymptotic rate matching the standard non-convex stochastic first-order scaling. Empirically, SMAVE matches or improves on RMAVE's synthetic subspace recovery at moderate-to-high ambient dimension, and on four real datasets it uniformly improves over OPG and is competitive with or outperforms RMAVE at orders of magnitude lower runtime.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SMAVE, a Riemannian stochastic gradient method for sufficient dimension reduction. It asserts that population-level minimizers of the MAVE risk approximate the same Grassmannian subspace as OPG, recasts the empirical MAVE objective as a smooth maximization problem on the Stiefel manifold with a closed-form Riemannian gradient, introduces sparse nearest-neighbor localization, and provides almost-sure convergence plus non-asymptotic rates for a simplified version that match standard non-convex stochastic first-order scaling. Empirical results claim competitive or superior subspace recovery at lower runtime than RMAVE and OPG on synthetic and real data.
Significance. If the MAVE-OPG equivalence holds under verifiable conditions and the convergence analysis is complete, the work supplies a scalable manifold-based SDR estimator with explicit rates and practical speed-ups, addressing the quadratic cost of localized methods while retaining gradient-based interpretability.
major comments (3)
- [Abstract / population equivalence section] Abstract and the section establishing the population equivalence: the central claim that population MAVE risk minimizers approximate the same Grassmannian target as OPG is asserted without the model conditions (link function, conditional variance, covariate distribution) or derivation steps; this equivalence is load-bearing for the Stiefel-manifold recasting, the closed-form Riemannian gradient, and all subsequent convergence guarantees.
- [Convergence analysis for simplified SMAVE] Section on the simplified algorithm and convergence: the almost-sure convergence and non-asymptotic rate are stated to match standard stochastic scaling, but the proof must explicitly connect the Riemannian gradient (derived from the MAVE-OPG equivalence) to the standard non-convex analysis; without those steps the rate claim cannot be verified.
- [Synthetic experiments] Empirical section (synthetic experiments): the reported subspace recovery improvements over RMAVE at moderate-to-high ambient dimension rely on the manifold formulation; if the equivalence does not hold exactly, the performance comparison may not isolate the contribution of the Riemannian stochastic optimizer.
minor comments (2)
- [Method section] Notation for the Stiefel manifold projection and the sparse nearest-neighbor localization should be defined once with explicit dimensions before first use.
- [Real-data experiments] The abstract mentions four real datasets but does not list their names or dimensions; this information belongs in the main text or a table for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract / population equivalence section] Abstract and the section establishing the population equivalence: the central claim that population MAVE risk minimizers approximate the same Grassmannian target as OPG is asserted without the model conditions (link function, conditional variance, covariate distribution) or derivation steps; this equivalence is load-bearing for the Stiefel-manifold recasting, the closed-form Riemannian gradient, and all subsequent convergence guarantees.
Authors: We agree the population equivalence is foundational and load-bearing. The manuscript derives the result in the dedicated section, but we will revise to state the model conditions (link function, conditional variance, covariate distribution) explicitly at the beginning of the section and expand the derivation with all intermediate steps for transparency. revision: yes
-
Referee: [Convergence analysis for simplified SMAVE] Section on the simplified algorithm and convergence: the almost-sure convergence and non-asymptotic rate are stated to match standard stochastic scaling, but the proof must explicitly connect the Riemannian gradient (derived from the MAVE-OPG equivalence) to the standard non-convex analysis; without those steps the rate claim cannot be verified.
Authors: We agree the proof requires explicit connection between the Riemannian gradient (obtained via the MAVE-OPG equivalence) and the standard non-convex stochastic first-order framework. The revised manuscript will insert these bridging steps in the convergence section so that the almost-sure convergence and non-asymptotic rates are directly verifiable from the manifold gradient. revision: yes
-
Referee: [Synthetic experiments] Empirical section (synthetic experiments): the reported subspace recovery improvements over RMAVE at moderate-to-high ambient dimension rely on the manifold formulation; if the equivalence does not hold exactly, the performance comparison may not isolate the contribution of the Riemannian stochastic optimizer.
Authors: The experiments are conducted under the conditions where the population equivalence is shown to hold. The reported gains arise from the sparse nearest-neighbor localization combined with Riemannian stochastic ascent on the Stiefel manifold. We will add a short clarifying paragraph in the experimental section that restates the operating conditions and explains how they justify the comparison; this addresses the isolation concern without altering the empirical results. revision: partial
Circularity Check
No circularity; MAVE-OPG equivalence presented as independent derivation with standard convergence rates
full rationale
The abstract states 'We show that minimizers of the population Minimum Average Variance Estimation (MAVE) risk approximate the same Grassmannian target as the Outer Product of Gradients (OPG)', then uses this to recast the empirical criterion on the Stiefel manifold. This is framed as a shown result internal to the paper rather than a self-definition, fitted parameter renamed as prediction, or load-bearing self-citation. The non-asymptotic rate is explicitly matched to 'standard non-convex stochastic first-order scaling', grounding the guarantees in external theory. No equations or steps in the provided text reduce the central claims to their own inputs by construction, and the reader's assessment of score 1.0 is consistent with an independent derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The empirical MAVE criterion admits a smooth formulation on the Stiefel manifold with closed-form Riemannian gradient.
Reference graph
Works this paper leans on
-
[1]
and Spokoiny, Vladimir G
Dalalyan, Arnak S. and Spokoiny, Vladimir G. , title =. Annals of Statistics , volume =. 2008 , doi =
2008
-
[2]
, title =
Cochran, William G. , title =
-
[3]
Proceedings of the 40th International Conference on Machine Learning , pages =
Kernel Sufficient Dimension Reduction and Variable Selection for Compositional Data via Amalgamation , author =. Proceedings of the 40th International Conference on Machine Learning , pages =. 2023 , editor =
2023
-
[4]
2023 , publisher=
An introduction to optimization on smooth manifolds , author=. 2023 , publisher=
2023
-
[5]
2018 , publisher=
Density estimation for statistics and data analysis , author=. 2018 , publisher=
2018
-
[6]
Proceedings of the 2016 Asian Conference on Machine Learning , volume =
Sufficient Dimension Reduction via Direct Estimation of the Gradients of Logarithmic Conditional Densities , author =. Proceedings of the 2016 Asian Conference on Machine Learning , volume =. 2016 , series =
2016
-
[7]
International Statistical Review , volume =
Ma, Yanyuan and Zhu, Liping , title =. International Statistical Review , volume =. 2013 , doi =
2013
-
[8]
Proceedings of the 42nd International Conference on Machine Learning , pages =
Deep Principal Support Vector Machines for Nonlinear Sufficient Dimension Reduction , author =. Proceedings of the 42nd International Conference on Machine Learning , pages =. 2025 , editor =
2025
-
[9]
The Annals of Statistics , volume=
Deep nonlinear sufficient dimension reduction , author=. The Annals of Statistics , volume=. 2024 , publisher=
2024
-
[10]
Advances in neural information processing systems , volume=
Solving interpretable kernel dimensionality reduction , author=. Advances in neural information processing systems , volume=
-
[11]
and Leng, C
Fukumizu, K. and Leng, C. , title =. Journal of the American Statistical Association , volume =. 2014 , doi =
2014
-
[12]
and Johnson, Charles R
Horn, Roger A. and Johnson, Charles R. , title =
-
[13]
and Jordan, Michael I
Fukumizu, Kenji and Bach, Francis R. and Jordan, Michael I. , title =. Annals of Statistics , volume =. 2009 , doi =
2009
-
[14]
Annals of Statistics , volume =
Hristache, Marian and Juditsky, Anatoli and Spokoiny, Vladimir , title =. Annals of Statistics , volume =. 2001 , doi =
2001
-
[15]
Investigating Smooth Multiple Regression by the Method of Average Derivatives , journal =
H. Investigating Smooth Multiple Regression by the Method of Average Derivatives , journal =
-
[16]
Journal of the American Statistical Association , volume =
Li, Bing and Wang, Shuang , title =. Journal of the American Statistical Association , volume =
-
[17]
Local Rademacher complexities , author=. Ann. Statist. , volume=. 2005 , publisher=
2005
-
[18]
Principles of nonparametric learning , pages=
Distribution and density estimation , author=. Principles of nonparametric learning , pages=. 2002 , publisher=
2002
-
[19]
Journal of Statistical Computation and Simulation , volume=
Minimum average deviance estimation for sufficient dimension reduction , author=. Journal of Statistical Computation and Simulation , volume=. 2018 , publisher=
2018
-
[20]
Annals of statistics , volume=
A Constructive Approach to the Estimation of Dimension Reduction Directions , author=. Annals of statistics , volume=
-
[21]
Machine learning , volume=
Extremely randomized trees , author=. Machine learning , volume=. 2006 , publisher=
2006
-
[22]
Test , volume=
Comments on: A random forest guided tour , author=. Test , volume=. 2016 , publisher=
2016
-
[23]
Journal of artificial intelligence research , volume=
SMOTE: synthetic minority over-sampling technique , author=. Journal of artificial intelligence research , volume=
-
[24]
1996 , publisher=
A probabilistic theory of pattern recognition , author=. 1996 , publisher=
1996
-
[25]
Advances in neural information processing systems , volume=
Mondrian forests: Efficient online random forests , author=. Advances in neural information processing systems , volume=
-
[26]
1997 , publisher=
Foundations of modern probability , author=. 1997 , publisher=
1997
-
[27]
SIAM Journal on Optimization , volume=
Projection-like retractions on matrix manifolds , author=. SIAM Journal on Optimization , volume=. 2012 , publisher=
2012
-
[28]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
On error and compression rates for prototype rules , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[29]
Advances in Neural Information Processing Systems , volume=
Rates of convergence for nearest neighbor classification , author=. Advances in Neural Information Processing Systems , volume=
-
[30]
2006 , publisher=
A distribution-free theory of nonparametric regression , author=. 2006 , publisher=
2006
-
[31]
The annals of statistics , pages=
Optimal global rates of convergence for nonparametric regression , author=. The annals of statistics , pages=. 1982 , publisher=
1982
-
[32]
BAGAN: Data Augmentation with Balancing GAN
Bagan: Data augmentation with balancing gan , author=. arXiv preprint arXiv:1803.09655 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
Exploratory Undersampling for Class-Imbalance Learning , year=
Liu, Xu-Ying and Wu, Jianxin and Zhou, Zhi-Hua , journal=. Exploratory Undersampling for Class-Imbalance Learning , year=
-
[34]
and Galar, M
Triguero, I. and Galar, M. and Vluymans, S. and Cornelis, C. and Bustince, H. and Herrera, F. and Saeys, Y. , booktitle=. Evolutionary undersampling for imbalanced big data classification , year=
-
[35]
Electronic Journal of Statistics , number =
Clayton Scott , title =. Electronic Journal of Statistics , number =. 2012 , doi =
2012
-
[36]
Proceedings of the 30th International Conference on Machine Learning , pages =
On the Statistical Consistency of Algorithms for Binary Classification under Class Imbalance , author =. Proceedings of the 30th International Conference on Machine Learning , pages =. 2013 , editor =
2013
-
[37]
International Conference on Machine Learning , pages=
Class-weighted classification: Trade-offs and robust approaches , author=. International Conference on Machine Learning , pages=. 2020 , organization=
2020
-
[38]
Introduction to Statistical Learning Theory , author =
-
[39]
Classification in general finite dimensional spaces with the
Gadat, S\'. Classification in general finite dimensional spaces with the. Ann. Statist. , FJOURNAL =. 2016 , NUMBER =
2016
-
[40]
, title =
Tsybakov, Alexandre B. , title =. 2008 , publisher =
2008
-
[41]
Choice of neighbor order in nearest-neighbor classification , author=. Ann. Statist. , volume=
-
[42]
2021 , publisher=
Mathematical foundations of infinite-dimensional statistical models , author=. 2021 , publisher=
2021
-
[43]
An exponential inequality for the distribution function of the kernel density estimator, with applications to adaptive estimation , JOURNAL =
Gin\'. An exponential inequality for the distribution function of the kernel density estimator, with applications to adaptive estimation , JOURNAL =. 2009 , NUMBER =
2009
-
[44]
Nonparametric discrimination: Consistency properties , author=
Discriminatory analysis. Nonparametric discrimination: Consistency properties , author=. Int. Stat. Rev. , volume=. 1951 , publisher=
1951
-
[45]
Local nearest neighbour classification with applications to semi-supervised learning , author=. Ann. Statist. , volume=. 2020 , publisher=
2020
-
[46]
Theory of classification: a survey of some recent advances , JOURNAL =
Boucheron, St\'. Theory of classification: a survey of some recent advances , JOURNAL =. 2005 , PAGES =
2005
-
[47]
Dudley, R. M. , TITLE =. J. Funct. Anal. , FJOURNAL =. 1967 , PAGES =
1967
-
[48]
Hierarchical nearest-neighbor Gaussian process models for large geostatistical datasets , author=. J. Amer. Statist. Assoc. , volume=. 2016 , publisher=
2016
-
[49]
Bousquet, Olivier , TITLE =. C. R. Math. Acad. Sci. Paris , FJOURNAL =. 2002 , NUMBER =
2002
-
[50]
The Annals of Statistics , pages=
Risk Bounds for Statistical Learning , author=. The Annals of Statistics , pages=. 2006 , publisher=
2006
-
[51]
Journal of Combinatorial Theory, Series A , volume=
Sphere packing numbers for subsets of the Boolean n-cube with bounded Vapnik-Chervonenkis dimension , author=. Journal of Combinatorial Theory, Series A , volume=. 1995 , publisher=
1995
-
[52]
The Annals of Probability , volume=
About the constants in Talagrand's concentration inequalities for empirical processes , author=. The Annals of Probability , volume=. 2000 , publisher=
2000
-
[53]
2023 , publisher=
Mathematical analysis of machine learning algorithms , author=. 2023 , publisher=
2023
-
[54]
Lecture Notes (Princeton University) , year=
Probability in high dimension , author=. Lecture Notes (Princeton University) , year=
-
[55]
Logistic lasso regression with nearest neighbors for gradient-based dimension reduction
Logistic lasso regression with nearest neighbors for gradient-based dimension reduction , author=. arXiv preprint arXiv:2407.08485 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[56]
1991 , publisher=
Probability in Banach Spaces: isoperimetry and processes , author=. 1991 , publisher=
1991
-
[57]
Consistency of a recursive nearest neighbor regression function estimate , author=. J. Multivariate Anal. , volume=. 1980 , publisher=
1980
-
[58]
The strong uniform consistency of nearest neighbor density estimates , author=. Ann. Statist. , pages=. 1977 , publisher=
1977
-
[59]
Dalalyan and Anatoly Juditsky and Vladimir Spokoiny , title =
Arnak S. Dalalyan and Anatoly Juditsky and Vladimir Spokoiny , title =. Journal of Machine Learning Research , year =
-
[60]
Empirical Risk Minimization under Random Censorship , author=. J. Mach. Learn. Res. , volume=
-
[61]
Smooth regression analysis , author=. Sankhy. 1964 , publisher=
1964
-
[62]
Theory Probab
On estimating regression , author=. Theory Probab. Appl. , volume=. 1964 , publisher=
1964
-
[63]
Sums of functions of nearest neighbor distances, moment bounds, limit theorems and a goodness of fit test , author=. Ann. Probab. , pages=. 1983 , publisher=
1983
-
[64]
On the measure of Voronoi cells , author=. J. Appl. Probab. , FJOURNAL =. 2017 , publisher=
2017
-
[65]
Bernoulli , volume=
Integral approximation by kernel smoothing , author=. Bernoulli , volume=. 2016 , publisher=
2016
-
[66]
International Conference on Artificial Intelligence and Statistics , pages=
Nearest neighbour based estimates of gradients: Sharp nonasymptotic bounds and applications , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2021 , organization=
2021
-
[67]
On the strong universal consistency of nearest neighbor regression function estimates , author=. Ann. Statist. , pages=. 1994 , publisher=
1994
-
[68]
Rate of convergence of k -nearest-neighbor classification rule , author=. J. Mach. Learn. Res. , volume=. 2017 , publisher=
2017
-
[69]
Electron
A nearest neighbor estimate of the residual variance , author=. Electron. J. Stat. , volume=. 2018 , publisher=
2018
-
[70]
2008 , publisher=
Optimization algorithms on matrix manifolds , author=. 2008 , publisher=
2008
-
[71]
Advances in Neural Information Processing Systems , volume=
Riemannian SVRG: Fast stochastic optimization on Riemannian manifolds , author=. Advances in Neural Information Processing Systems , volume=
-
[72]
SIAM journal on Matrix Analysis and Applications , volume=
The geometry of algorithms with orthogonality constraints , author=. SIAM journal on Matrix Analysis and Applications , volume=. 1998 , publisher=
1998
-
[73]
Journal of the American Statistical Association , volume=
Sliced inverse regression for dimension reduction , author=. Journal of the American Statistical Association , volume=. 1991 , publisher=
1991
-
[74]
Journal of the American Statistical Association , volume=
Sliced inverse regression for dimension reduction: Comment , author=. Journal of the American Statistical Association , volume=. 1991 , publisher=
1991
-
[75]
Decision support systems , volume=
Modeling wine preferences by data mining from physicochemical properties , author=. Decision support systems , volume=. 2009 , publisher=
2009
-
[76]
Computer Communications , volume=
Using data mining techniques for bike sharing demand prediction in metropolitan city , author=. Computer Communications , volume=. 2020 , publisher=
2020
-
[77]
Energy and Buildings , volume=
On-line learning of indoor temperature forecasting models towards energy efficiency , author=. Energy and Buildings , volume=. 2014 , publisher=
2014
-
[78]
International Journal of Neural Systems , volume=
Assessing rbf networks using delve , author=. International Journal of Neural Systems , volume=. 2000 , publisher=
2000
-
[79]
Sensors and Actuators B: Chemical , volume=
Reservoir computing compensates slow response of chemosensor arrays exposed to fast varying gas concentrations in continuous monitoring , author=. Sensors and Actuators B: Chemical , volume=. 2015 , publisher=
2015
-
[80]
Communications in statistics-Theory and methods , volume=
SAVE: a method for dimension reduction and graphics in regression , author=. Communications in statistics-Theory and methods , volume=. 2000 , publisher=
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.