UniPinRec: Unifying Generative Retrieval and Ranking at Pinterest Scale
Pith reviewed 2026-06-28 20:28 UTC · model grok-4.3
The pith
A single transformer model with shared user-history encoding and task-specific heads can replace separate retrieval and ranking models in production.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
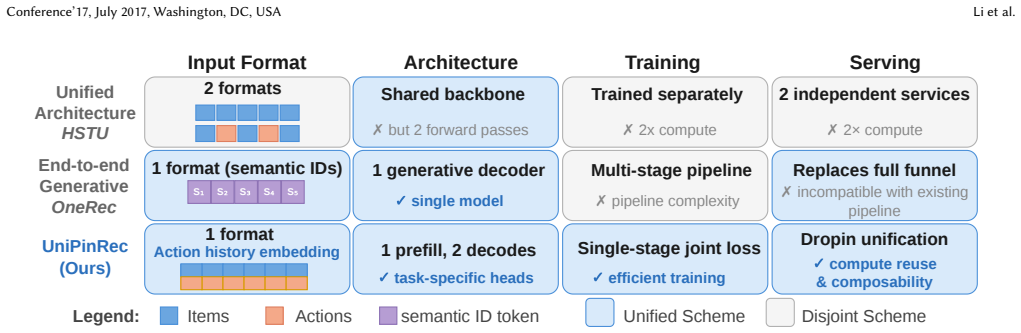
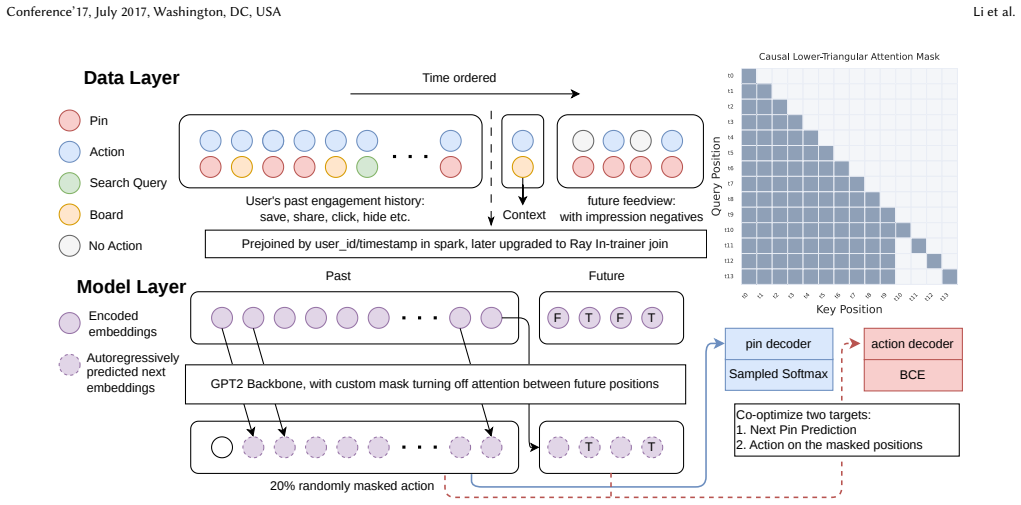
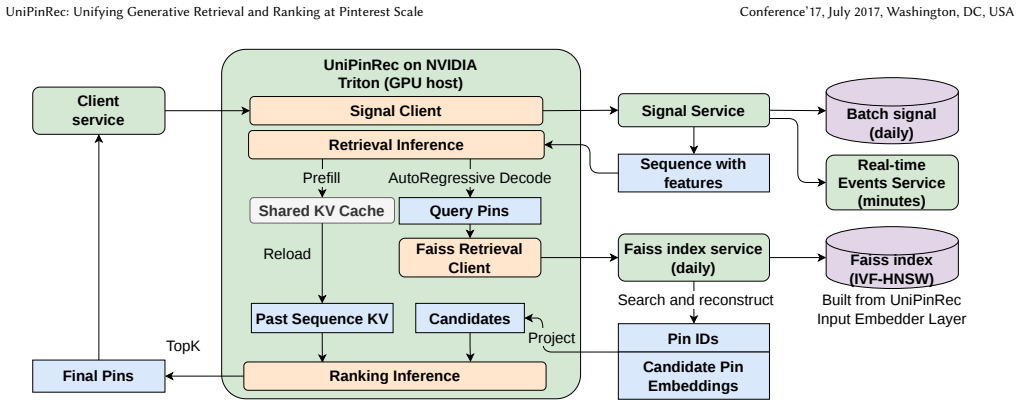
UniPinRec shows that full-stack unification of retrieval and ranking is possible by encoding user action sequences once in a shared transformer, then routing the resulting representations through task-specific heads—one performing ANN dot-product retrieval and the other performing cross-attention ranking—while using Masked Action Modeling, blended training examples, and KV cache sharing to satisfy both objectives in a single training run and serving path, yielding measurable efficiency gains and a modest engagement lift when run at Pinterest scale.
What carries the argument
Shared transformer encoder producing candidate-independent representations that branch into task-specific heads for dot-product retrieval and cross-attention ranking, enabled by Masked Action Modeling.
If this is right
- One model and one training stage replace two independent pipelines, removing duplicated parameters and compute.
- Cross-stage KV cache sharing lowers total FLOPs relative to serving two separate models.
- The system integrates into existing serving infrastructure without requiring new infrastructure.
- Online A/B tests record roughly 1% higher engagement, 11.1% lower latency, and 63.6% higher QPS.
Where Pith is reading between the lines
- The same blending and cache-sharing pattern could extend to additional recommendation stages such as re-ranking or exploration if their input representations overlap.
- Blended training examples may allow new objectives like diversity or freshness to be added by simply changing the paired slates without retraining separate models.
- If user-action sequences remain the dominant signal, the approach could reduce the total number of distinct models maintained across an entire recommendation stack.
Load-bearing premise
The shared transformer plus the three supporting techniques can meet both retrieval and ranking accuracy targets at production scale without any degradation that would erase the claimed efficiency savings.
What would settle it
A side-by-side offline evaluation showing whether the unified model’s retrieval recall or ranking NDCG falls below the levels achieved by the prior separate models on the same user-action data.
Figures
read the original abstract
Modern recommendation systems predominantly train retrieval and ranking as separate models despite both increasingly relying on large transformers encoding the same user behavior data, duplicating parameters, compute, and serving cost. Prior work unifies the model architecture but not the full pipeline: input formats, training procedures, and serving stacks remain fragmented across stages. We present UniPinRec, which achieves full-stack unification of retrieval and ranking at Pinterest: one input format, one model, one training stage, deployed within existing serving infrastructure. A shared transformer encodes the user action sequence into candidate-independent representations that branch into retrieval (ANN dot-product) and ranking (cross-attention) via task-specific heads. Three ideas make this work: (1) Masked Action Modeling (MAM) eliminates interleaving, enabling weight sharing without doubling context length; (2) Blended training examples pair action sequences with feedview impression slates to satisfy both objectives jointly; (3) Cross-stage KV cache sharing reuses user-history computation from retrieval for ranking, reducing total FLOPs versus serving two independent models. Deployed in the Pinterest core surfaces, UniPinRec delivers approximately +1% online engagement lift while cutting end-to-end serving latency by 11.1% and lifting QPS by 63.6%. To our knowledge, this is the first full-stack unification of retrieval and ranking, covering inputs, model, training and serving, deployed in a production recommendation system.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents UniPinRec, a full-stack unification of retrieval and ranking for Pinterest-scale recommendation systems. It uses a single shared transformer that encodes user action sequences into candidate-independent representations, branching to retrieval via ANN dot-product and ranking via cross-attention with task-specific heads. Three enabling techniques are described: Masked Action Modeling (MAM) to avoid context doubling, blended training examples pairing action sequences with impression slates, and cross-stage KV cache sharing for serving efficiency. The system is deployed in core surfaces and reports approximately +1% online engagement lift, 11.1% end-to-end latency reduction, and 63.6% QPS increase.
Significance. If the reported production metrics are supported by controlled evidence, the work demonstrates that unifying input formats, model architecture, training, and serving infrastructure across retrieval and ranking stages can simultaneously improve engagement and reduce compute/serving costs in large-scale transformer-based recsys without apparent negative transfer.
major comments (1)
- Abstract: the central claims of +1% engagement lift, 11.1% latency reduction, and 63.6% QPS increase are presented as deployment outcomes, yet the provided manuscript supplies no experimental details, baselines, ablation studies, or error analysis to support them; this is load-bearing for assessing whether the unification actually delivers the stated gains without offsetting degradation.
Simulated Author's Rebuttal
We thank the referee for the review and the opportunity to address the concern regarding experimental support for the reported production metrics. We respond to the major comment below.
read point-by-point responses
-
Referee: [—] Abstract: the central claims of +1% engagement lift, 11.1% latency reduction, and 63.6% QPS increase are presented as deployment outcomes, yet the provided manuscript supplies no experimental details, baselines, ablation studies, or error analysis to support them; this is load-bearing for assessing whether the unification actually delivers the stated gains without offsetting degradation.
Authors: The full manuscript contains a dedicated 'Online Experiments' section describing the A/B test setup (including cohort sampling, test duration, and statistical testing) used to measure the engagement lift, as well as production serving benchmarks for the latency and QPS improvements relative to the prior two-model baseline. We agree that the abstract would benefit from a brief pointer to this evaluation methodology. However, comprehensive ablation studies and error analyses are not feasible to publish at Pinterest scale without compromising production stability or revealing proprietary infrastructure details. We will revise the abstract to reference the experiments section and add a short summary paragraph on the evaluation protocol. revision: partial
Circularity Check
No significant circularity
full rationale
The paper describes a production-scale engineering system for unifying retrieval and ranking stages via a shared transformer, MAM, blended examples, and KV-cache reuse. All load-bearing claims are architectural descriptions or measured online A/B metrics (+1% engagement, latency/QPS improvements) rather than any derivation, fitted parameter, or prediction that reduces to its own inputs by construction. No equations, self-citations, or uniqueness theorems are invoked in a load-bearing way that would create circularity; the results are externally falsifiable deployment outcomes.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Prabhat Agarwal, Anirudhan Badrinath, Laksh Bhasin, Jaewon Yang, Edoardo Botta, Jiajing Xu, and Charles Rosenberg. 2025. PinRec: Outcome-Conditioned, Multi-Token Generative Retrieval for Industry-Scale Recommendation Systems. arXiv preprint arXiv:2504.10507(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Prabhat Agarwal, Minhazul Islam SK, Nikil Pancha, Kurchi Subhra Hazra, Jiajing Xu, and Chuck Rosenberg. 2024. OmniSearchSage: Multi-Task Multi-Entity Embeddings for Pinterest Search. InCompanion Proceedings of the ACM Web Conference 2024 (WWW ’24). ACM, 121–130. doi:10.1145/3589335.3648309
-
[3]
Anirudhan Badrinath, Alex Yang, Kousik Rajesh, Prabhat Agarwal, Jaewon Yang, Haoyu Chen, Jiajing Xu, and Charles Rosenberg. 2025. OmniSage: Large Scale, Multi-Entity Heterogeneous Graph Representation Learning. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V.2 (Toronto ON, Canada)(KDD ’25). Association for Computin...
-
[4]
Josh Beal, Eric Kim, Jinfeng Rao, Rex Wu, Dmitry Kislyuk, and Charles Rosenberg
-
[5]
arXiv:2603.03544 [cs.CV] https://arxiv.org/abs/2603.03544
PinCLIP: Large-scale Foundational Multimodal Representation at Pinterest. arXiv:2603.03544 [cs.CV] https://arxiv.org/abs/2603.03544
-
[6]
Yang Cao, Changhao Zhang, Xiaoshuang Chen, Kaiqiao Zhan, and Ben Wang
-
[7]
InProceedings of the ACM Web Conference 2025 (WWW)
xMTF: A Formula-Free Model for Reinforcement-Learning-Based Multi- Task Fusion in Recommender Systems. InProceedings of the ACM Web Conference 2025 (WWW)
2025
-
[8]
Jiahui Chen, Xiaoze Jiang, Zhibo Wang, Quanzhi Zhu, Junyao Zhao, Feng Hu, Kang Pan, Ao Xie, Maohua Pei, Zhiheng Qin, Hongjing Zhang, Zhixin Zhai, Xiaobo Guo, Runbin Zhou, Kefeng Wang, Mingyang Geng, Cheng Chen, Jingshan Lv, Yupeng Huang, Xiao Liang, and Han Li. 2025. UniSearch: Rethinking Search System with a Unified Generative Architecture.arXiv preprint...
-
[9]
Xiangyi Chen, Kousik Rajesh, Matthew Lawhon, Zelun Wang, Hanyu Li, Haomiao Li, Saurabh Vishwas Joshi, Pong Eksombatchai, Jaewon Yang, Yi-Ping Hsu, Jiajing Xu, and Charles Rosenberg. 2025. PinFM: Foundation Model for User Activity Sequences at a Billion-scale Visual Discovery Platform. InProceedings of the 19th ACM Conference on Recommender Systems (RecSys...
-
[10]
Lee, Khush- hall Chandra Mahajan, Ning Jiang, Kai Ren, Jinhui Li, and Wen-Yun Yang
Zhimin Chen, Chenyu Zhao, Ka Chun Mo, Yunjiang Jiang, Jane H. Lee, Khush- hall Chandra Mahajan, Ning Jiang, Kai Ren, Jinhui Li, and Wen-Yun Yang. 2026. Massive Memorization with Hundreds of Trillions of Parameters for Sequen- tial Transducer Generative Recommenders. InProceedings of the International Conference on Learning Representations (ICLR)
2026
-
[11]
Sunhao Dai, Jiakai Tang, Jiahua Wu, Kun Wang, Yuxuan Zhu, Bingjun Chen, Bangyang Hong, Yu Zhao, Cong Fu, Kangle Wu, Yabo Ni, Anxiang Zeng, Wenjie Wang, Xu Chen, Jun Xu, and See-Kiong Ng. 2025. OnePiece: Bringing Context Engineering and Reasoning to Industrial Cascade Ranking System.arXiv preprint arXiv:2509.18091(2025)
-
[12]
Jiaxin Deng, Shiyao Wang, Kuo Cai, Lejian Ren, Qigen Hu, Weifeng Ding, Qiang Luo, and Guorui Zhou. 2025. OneRec: Unifying Retrieve and Rank with Generative Recommender and Iterative Preference Alignment.arXiv preprint arXiv:2502.18965(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [13]
-
[14]
Vianne R. Gao, Chen Xue, Marc Versage, Xie Zhou, Zhongruo Wang, Chao Li, Yeon Seonwoo, Nan Chen, Zhen Ge, Gourab Kundu, Weiqi Zhang, Tian Wang, Qingjun Cui, and Trishul Chilimbi. 2025. SynerGen: Contextualized Genera- tive Recommender for Unified Search and Recommendation.arXiv preprint arXiv:2509.21777(2025)
-
[15]
Ruidong Han, Bin Yin, Shangyu Chen, He Jiang, Fei Jiang, Xiang Li, Chi Ma, Mincong Huang, Xiaoguang Li, Chunzhen Jing, Yueming Han, Menglei Zhou, Lei Yu, Chuan Liu, and Wei Lin. 2025. MTGR: Industrial-Scale Generative Rec- ommendation Framework in Meituan. InProceedings of the 34th ACM Interna- tional Conference on Information and Knowledge Management (CI...
-
[16]
Horace He et al. 2024. Flex Attention: A Programming Model for Generating Optimized Attention Kernels.arXiv preprint arXiv:2412.05496(2024). https: //arxiv.org/abs/2412.05496
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Lars Hertel, Neil Daftary, Fedor Borisyuk, Aman Gupta, and Rahul Mazumder
-
[18]
InCompanion Proceedings of the ACM Web Confer- ence 2025 (WWW)
Efficient User History Modeling with Amortized Inference for Deep Learn- ing Recommendation Models. InCompanion Proceedings of the ACM Web Confer- ence 2025 (WWW)
2025
-
[19]
Yanhua Huang, Yuqi Chen, Xiong Cao, Rui Yang, Mingliang Qi, Yinghao Zhu, Qingchang Han, Yaowei Liu, Zhaoyu Liu, Xuefeng Yao, Yuting Jia, Leilei Ma, Yinqi Zhang, Taoyu Zhu, Liujie Zhang, Lei Chen, Weihang Chen, Min Zhu, Ruiwen Xu, and Lei Zhang. 2025. Towards Large-scale Generative Ranking. CoRRabs/2505.04180 (2025). doi:10.48550/ARXIV.2505.04180 arXiv:2505.04180
-
[20]
Jordan, and Ion Stoica
Philipp Moritz, Robert Nishihara, Stephanie Wang, Alexey Tumanov, Richard Liaw, Eric Liang, Melih Elibol, Zongheng Yang, William Paul, Michael I. Jordan, and Ion Stoica. 2018. Ray: A Distributed Framework for Emerging AI Applications. In13th USENIX Symposium on Operating Systems Design and Implementation (OSDI 18). 561–577
2018
-
[21]
David Pardoe, Neil Daftary, Miro Furtado, Aditya Aiyer, Yu Wang, Liuqing Li, Tao Song, Lars Hertel, Young Jin Yun, Senthil Radhakrishnan, Zhiwei Wang, Tommy Li, Khai Tran, Ananth Nagarajan, Ali Naqvi, Yue Zhang, Renpeng Fang, Avi Romascanu, Arjun Kulothungun, Deepak Kumar, Praneeth Boda, Fedor Borisyuk, and Ruoyan Wang. 2026. CADET: Context-Conditioned Ad...
-
[22]
Zhengyang Su, Isay Katsman, Yueqi Wang, Ruining He, Lukasz Heldt, Raghu- nandan Keshavan, Shao-Chuan Wang, Xinyang Yi, Mingyan Gao, Onkar Dalal, Lichan Hong, Ed Chi, and Ningren Han. 2026. STATIC: Vectorizing the Trie: Effi- cient Constrained Decoding for LLM-based Generative Retrieval on Accelerators. arXiv preprint arXiv:2602.22647(2026)
- [23]
-
[24]
Yijia Sun, Shanshan Huang, Zhiyuan Guan, Qiang Luo, Ruiming Tang, Kun Gai, and Guorui Zhou. 2026. GRank: Towards Target-Aware and Streamlined Industrial Retrieval with a Generate-Rank Framework. InProceedings of the ACM Web Conference 2026 (WWW)
2026
-
[25]
Jiarui Wang, Huichao Chai, Yuanhang Zhang, Zongjin Zhou, Wei Guo, Xingkun Yang, Qiang Tang, Bo Pan, Jiawei Zhu, Ke Cheng, Yuting Yan, Shulan Wang, Yingjie Zhu, Zhengfan Yuan, Jiaqi Huang, Yuhan Zhang, Xiaosong Sun, Zhinan Zhang, Hong Zhu, Yongsheng Zhang, Tiantian Dong, Zhong Xiao, Deliang Liu, Chengzhou Lu, Yuan Sun, Zhiyuan Chen, Xinming Han, Zaizhu Liu...
-
[26]
Xue Xia, Pong Eksombatchai, Nikil Pancha, Dhruvil Deven Badani, Po-Wei Wang, Neng Gu, Saurabh Vishwas Joshi, Nazanin Farahpour, Zhiyuan Zhang, and An- drew Zhai. 2023. TransAct: Transformer-based Realtime User Action Model for Recommendation at Pinterest. InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, KDD 2023, Lon...
-
[27]
Xue Xia, Saurabh Joshi, Kousik Rajesh, Kangnan Li, Yangyi Lu, Nikil Pancha, Dhruvil Badani, Jiajing Xu, and Pong Eksombatchai. 2025. TransAct V2: Lifelong User Action Sequence Modeling on Pinterest Recommendation. InProceedings of the 34th ACM International Conference on Information and Knowledge Management (Seoul, Republic of Korea)(CIKM ’25). Associatio...
-
[28]
Bencheng Yan, Shilei Liu, Zhiyuan Zeng, Zihao Wang, Yizhen Zhang, Yujin Yuan, Langming Liu, Jiaqi Liu, Di Wang, Wenbo Su, Pengjie Wang, Jian Xu, and Bo Zheng. 2026. Unlocking Scaling Law in Industrial Recommendation Systems with a Three-step Paradigm based Large User Model. InProceedings of the 19th ACM International Conference on Web Search and Data Mini...
2026
- [29]
-
[30]
Nowak, Xiaoli Gao, and Hamid Eghbalzadeh
Liu Yang, Fabian Paischer, Kaveh Hassani, Jiacheng Li, Shuai Shao, Zhang Gabriel Li, Yun He, Xue Feng, Nima Noorshams, Sem Park, Bo Long, Robert D. Nowak, Xiaoli Gao, and Hamid Eghbalzadeh. 2024. Unifying Generative and Dense Retrieval for Sequential Recommendation.arXiv preprint arXiv:2411.18814(2024)
-
[31]
Xiao Yang, Peifeng Yin, Abe Engle, Jinfeng Zhuang, and Ling Leng. 2025. MTMD: A Multi-Task Multi-Domain Framework for Unified Ad Lightweight Ranking at Pinterest. InProceedings of the AdKDD Workshop at the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining
2025
-
[32]
Yufei Ye, Wei Guo, Jin Yao Chin, Hao Wang, Hong Zhu, Xi Lin, Yuyang Ye, Yong Liu, Ruiming Tang, Defu Lian, and Enhong Chen. 2025. FuXi-𝛼: Scaling Recommendation Model with Feature Interaction Enhanced Transformer. In Proceedings of the ACM Web Conference 2025 (WWW)
2025
- [33]
-
[34]
Jun Yuan, Guohao Cai, and Zhenhua Dong. 2024. A Parameter Update Balanc- ing Algorithm for Multi-task Ranking Models in Recommendation Systems. In Proceedings of the 2024 IEEE International Conference on Data Mining (ICDM)
2024
-
[35]
Jiaqi Zhai, Lucy Liao, Xing Liu, Yueming Wang, Rui Li, Xuan Cao, Leon Gao, Zhaojie Gong, Fangda Gu, Michael He, Yinghai Lu, and Yu Shi. 2024. Actions Speak Louder than Words: Trillion-Parameter Sequential Transducers for Gener- ative Recommendations. InProceedings of the 41st International Conference on Machine Learning (ICML)
2024
-
[36]
Jun Zhang, Yi Li, Yue Liu, Changping Wang, Yuan Wang, Yuling Xiong, Xun Liu, Haiyang Wu, Qian Li, Enming Zhang, Jiawei Sun, Xin Xu, Zishuai Zhang, Ruoran Liu, Suyuan Huang, Zhaoxin Zhang, Zhengkai Guo, Shuojin Yang, Meng-Hao Guo, Huan Yu, Jie Jiang, and Shi-Min Hu. 2025. GPR: Towards a Generative Pre-trained One-Model Paradigm for Large-Scale Advertising ...
-
[37]
Luankang Zhang, Kenan Song, Yi Quan Lee, Wei Guo, Hao Wang, Yawen Li, Huifeng Guo, Yong Liu, Defu Lian, and Enhong Chen. 2025. Killing Two Birds with One Stone: Unifying Retrieval and Ranking with a Single Generative Rec- ommendation Model. InProceedings of the 48th International ACM SIGIR Confer- ence on Research and Development in Information Retrieval(...
- [38]
-
[39]
Yanyan Zou, Junbo Qi, Lunsong Huang, Yu Li, Kewei Xu, Jiabao Gao, Binglei Zhao, Xuanhua Yang, Sulong Xu, and Shengjie Li. 2026. GenRec: A Preference- Oriented Generative Framework for Large-Scale Recommendation. InProceedings of the 49th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR). 10
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.